Presentation at the Kultivate Linked Data Workshop at HEFCE in London on Monday 12th December 2011. See http://pres.spindle.org.uk/2011/kultivate/ for more information.
http: or https: — you want things to be able to consume your data, right? • It differentiates between “documents” and “things described by those documents” • It’s not going to change • It’s the same place humans go for a page about that thing
avoid ambiguity • Allows differentiation between “resources” and “things described by resources” • Lots of common properties can be used to describe either the document or the thing • It doesn’t really matter what you pick as your fragment identifier
be familiar territory for many of you) • We’ve got our own internal, stable, catalogue reference — in our case a UUID, but the exact nature isn’t too important • We’ve got a web server to publish it on
it all): http://foobarbooks.org/items/ • Our local identifier (our catalogue reference): 52279a4d-1707-45e7-b19d-f5571218e9dd • The fragment (which differentiates information about the book): #item
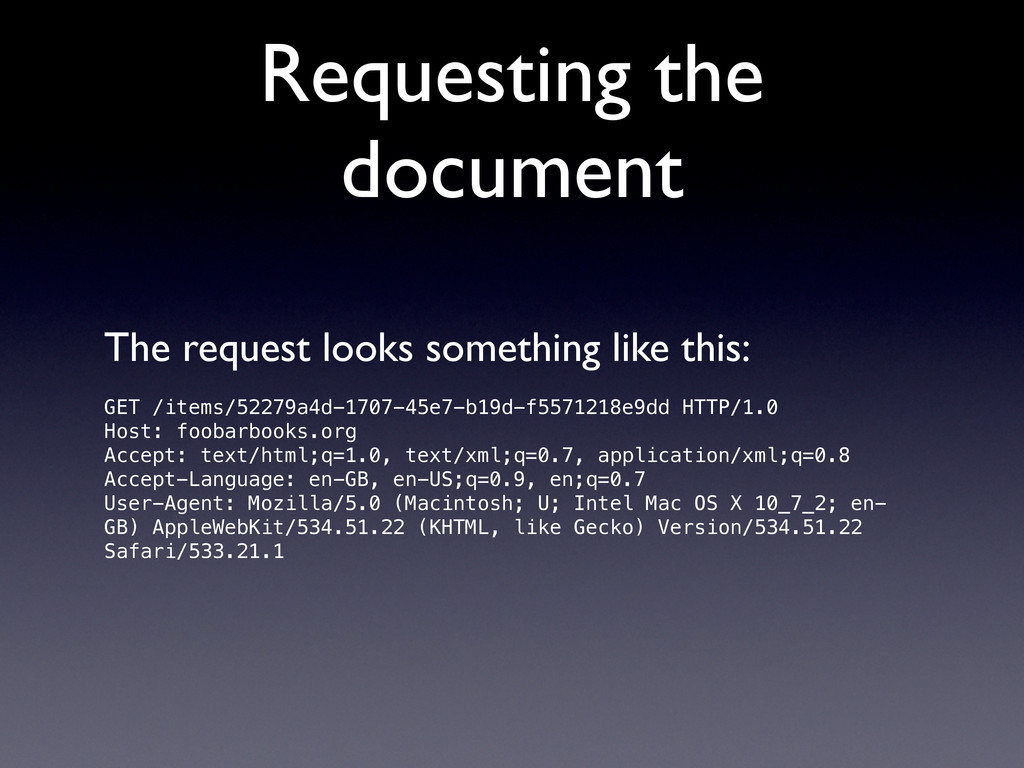
http://foobarbooks.org/items/52279a4d-1707-45e7-b19d-f5571218e9dd#item …into your address bar 2. Your browser requests… /items/52279a4d-1707-45e7-b19d-f5571218e9dd …from the server at foobarbooks.org on TCP/IP port 80 (that’s where HTTP lives)
to explicitly include the “.html” • “.cgi, or even .html, is something which will change. You may not be using HTML for that page in 20 years time, but you might want today's links to it to still be valid.” • Why not just configure the server to not need the filename extension?
using RDF • RDF is useful because it identifies everything using URIs, even the classes and properties • This means that (a) anybody can play, and (b) there’s not much risk of conflict
find it ugly, but it’s the one RDF serialisation everything can process • So, we’ll create 52279a4d-1707-45e7-b19d- f5571218e9dd.rdf • This is why putting .html into our item URI would be problematic — without special knowledge, consumers would only retrieve the HTML document!
data to the HTML document which would mean some consumers don’t have to request the RDF/ XML • You could help consumers which don’t understand Content Negotiation by adding a <link> element to your HTML • You could publish data in other formats: JSON, Turtle, CSV, MARC…
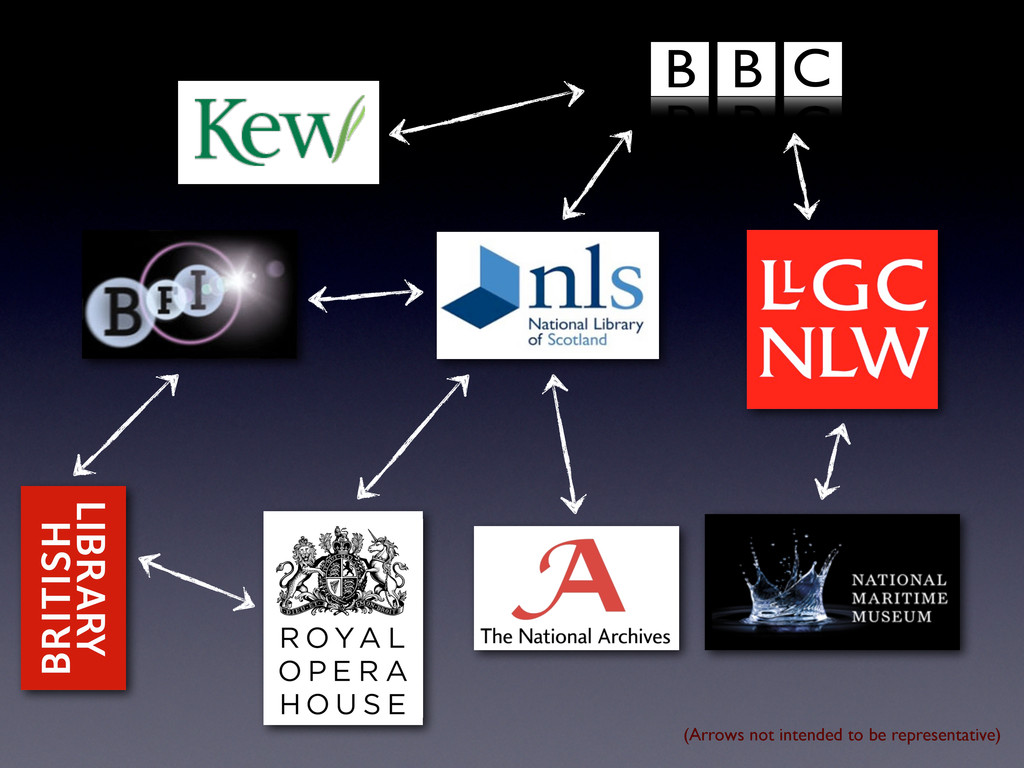
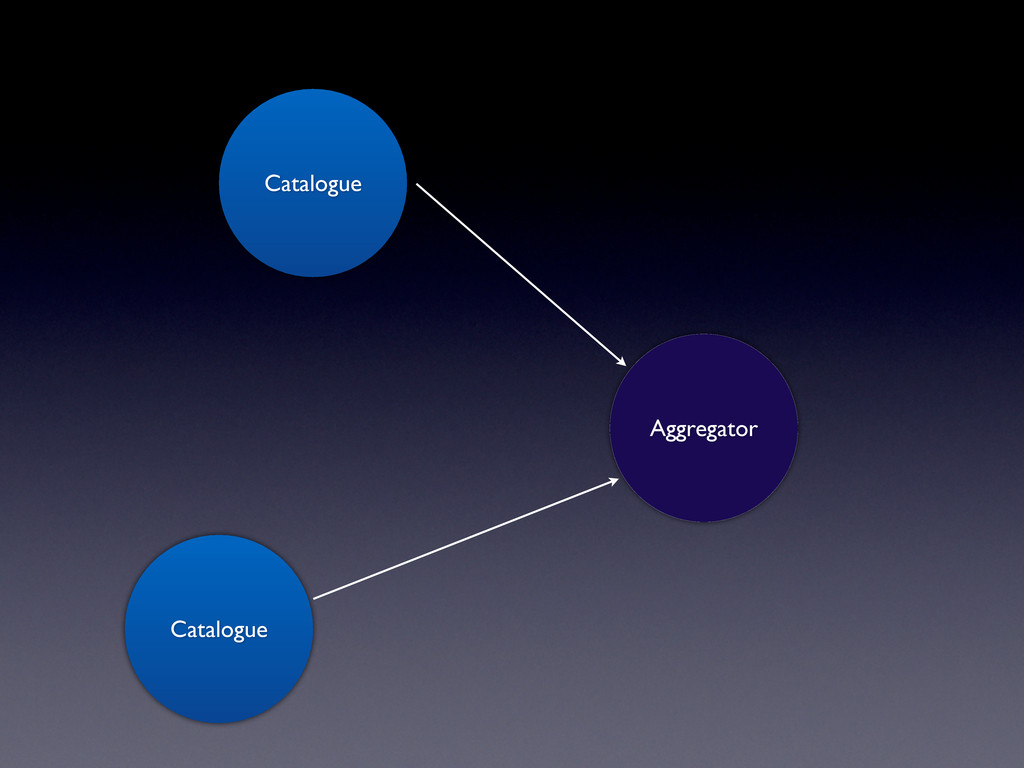
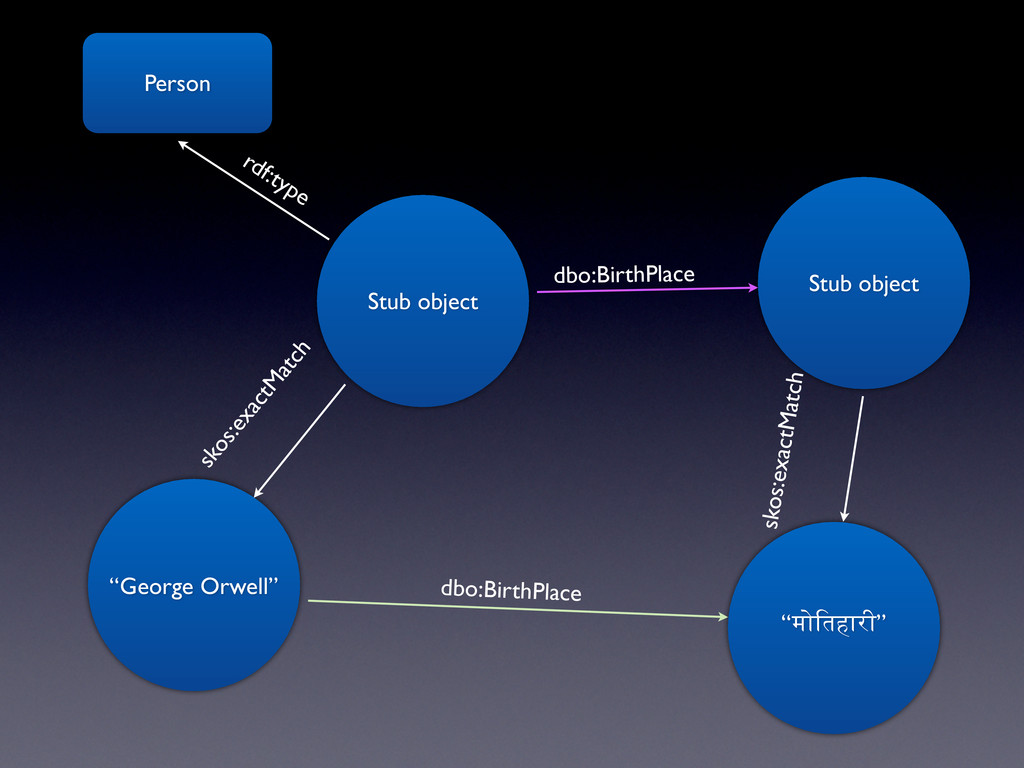
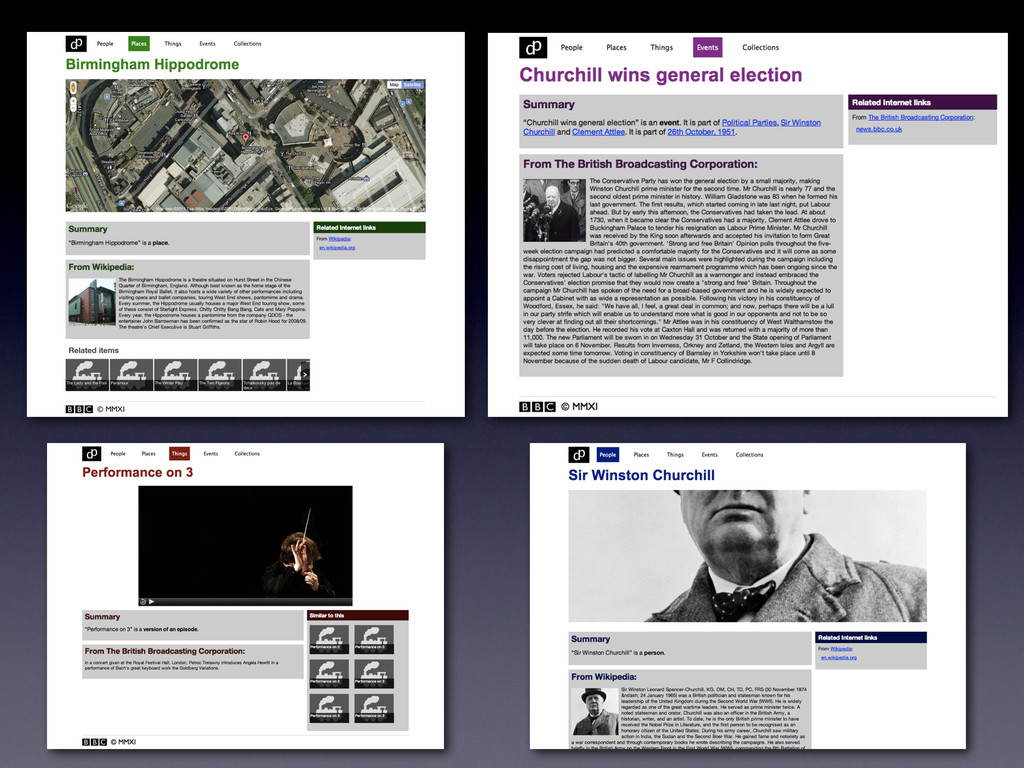
Linked Data • Caching it (to make it easier for consuming applications) • Breaking it down into people, places, events, collections and… things • Finding the overlaps
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}