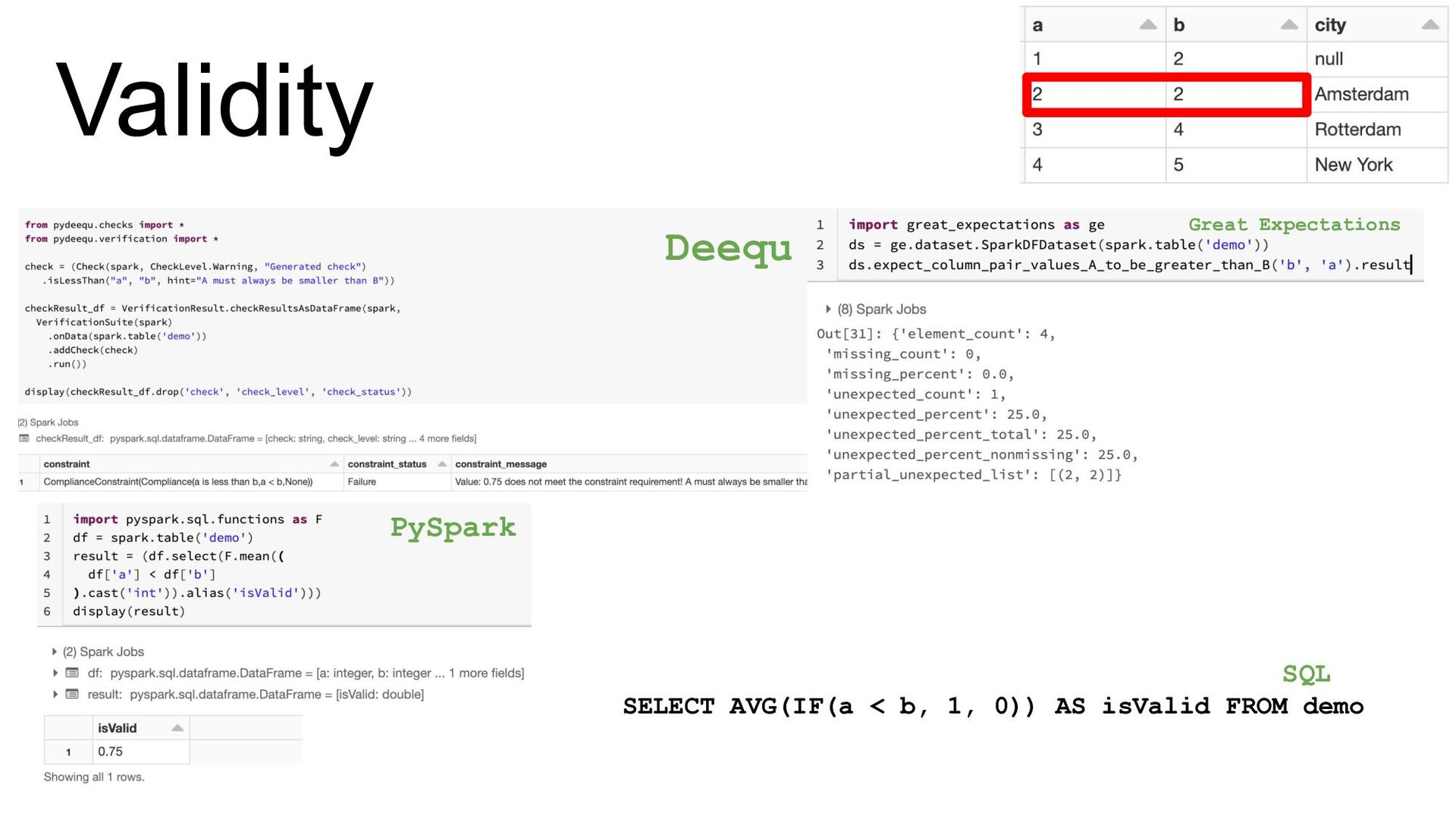
Few solutions exist in the open-source community either in the form of libraries or complete stand-alone platforms, which can be used to assure certain data quality, especially when continuous imports happen. Organizations may consider picking up one of the available options – Apache Griffin, Deequ, DDQ, and Great Expectations. In this presentation, we’ll compare these different open-source products across different dimensions, like maturity, documentation, extensibility, and features like data profiling and anomaly detection.
https://www.youtube.com/watch?v=EQtaRqNUNd8
{kind=link}
{kind=link}
{kind=link}
{kind=link}
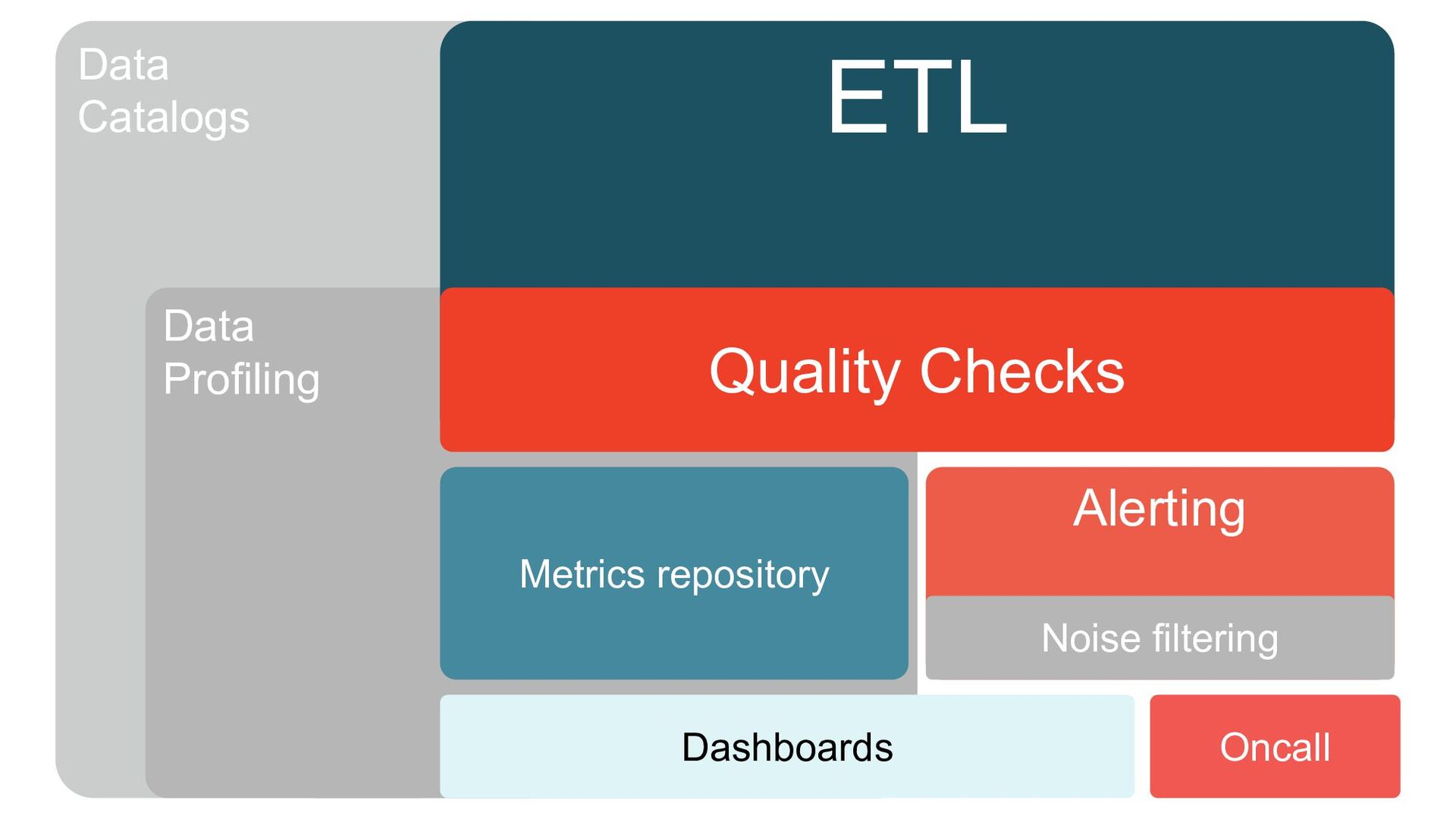{kind=link}
{kind=link}
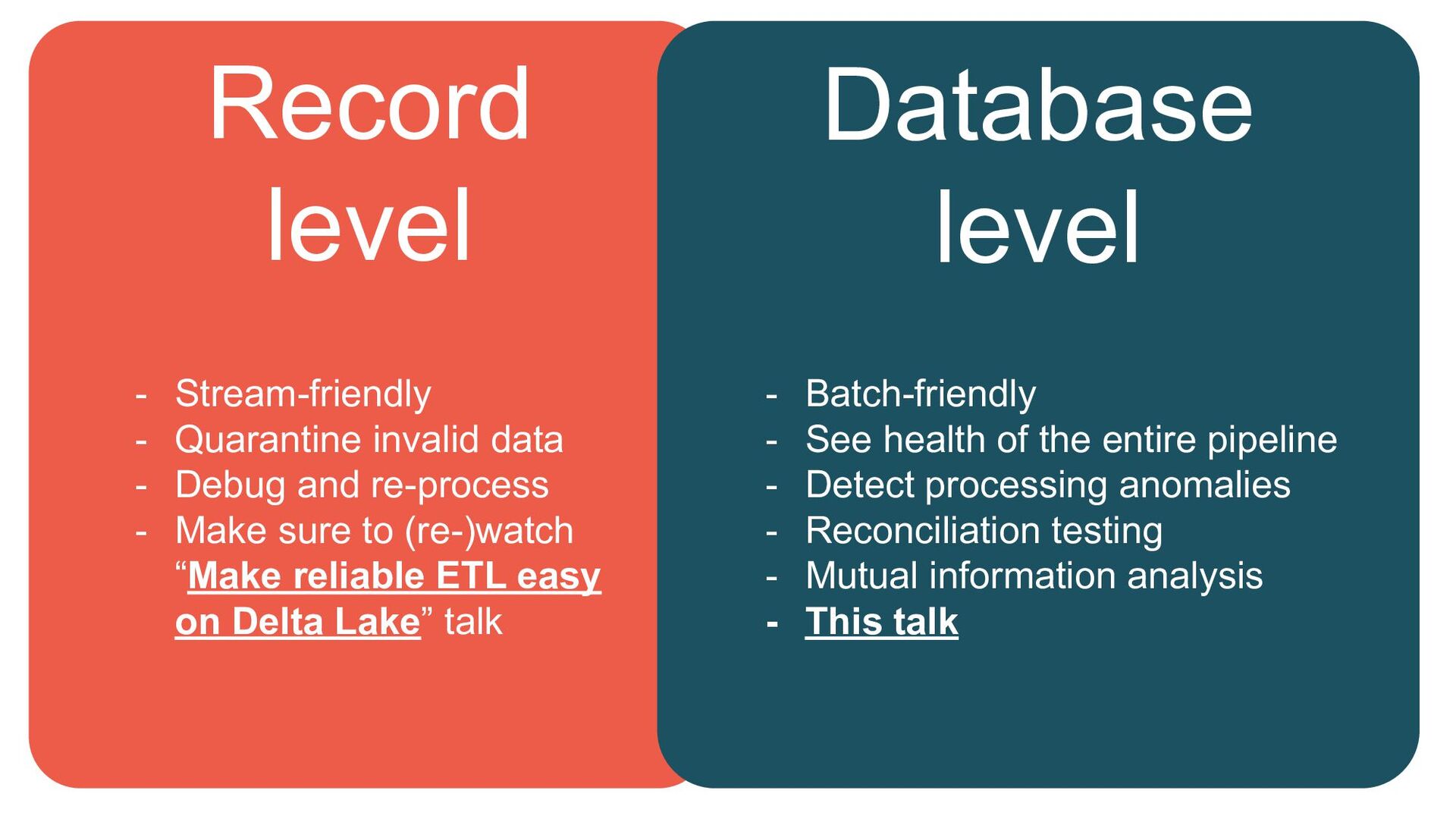{kind=link}
{kind=link}
{kind=link}
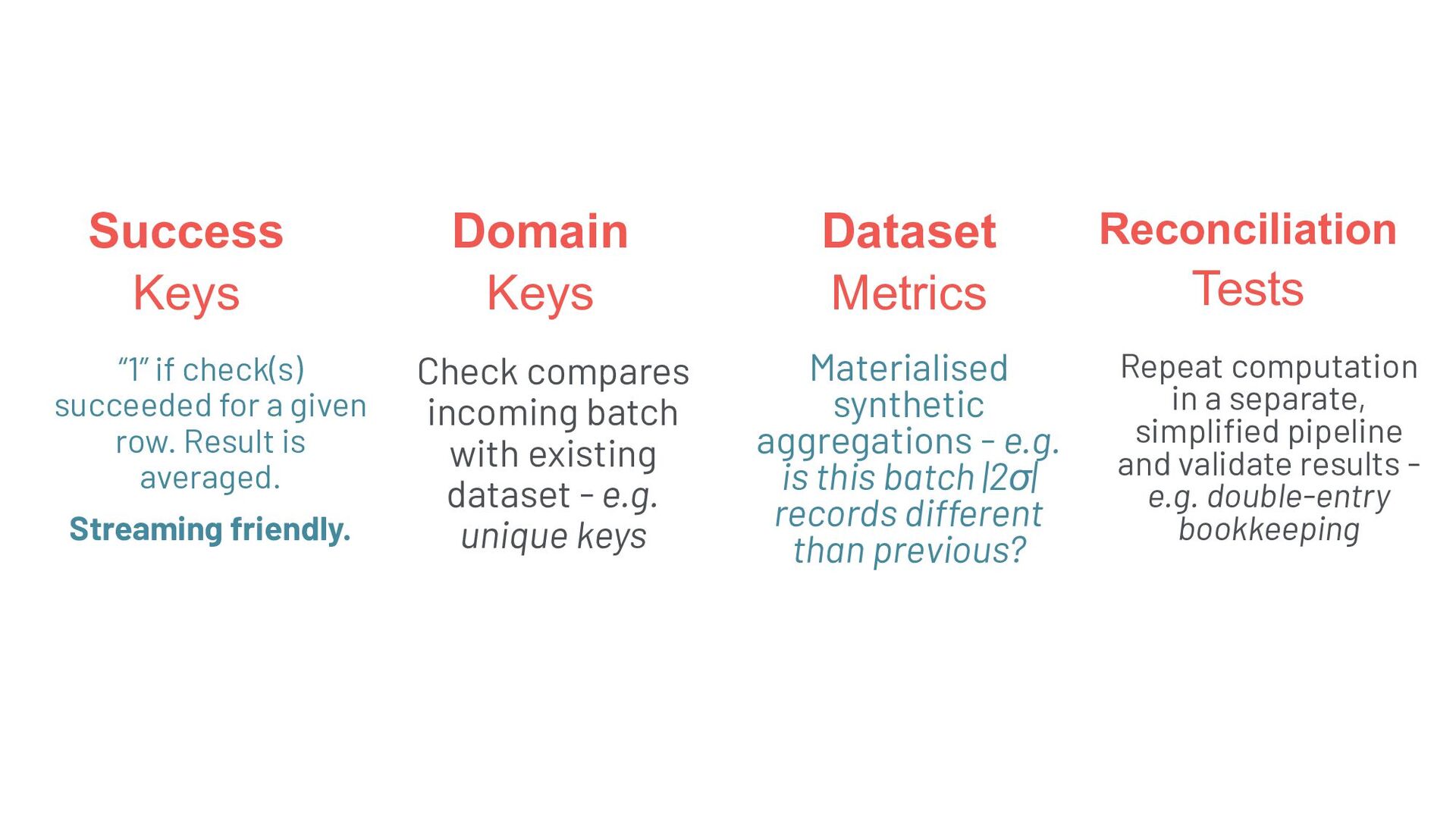{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
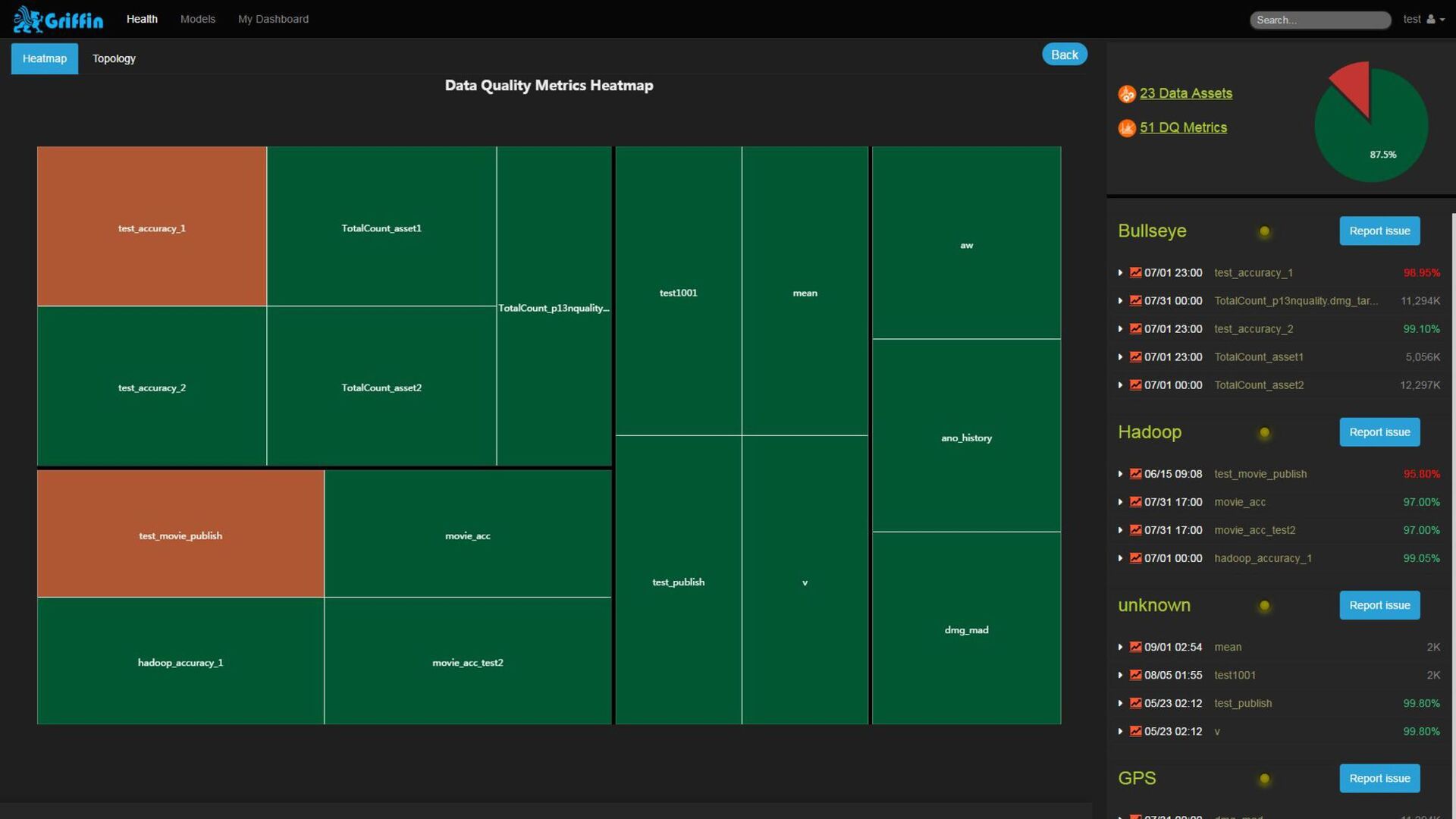{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}