In this talk, we’ll compare different data privacy techniques & protection of personally identifiable information and their effects on statistical usefulness, re-identification risks, data schema, format preservation, read & write performance.
We’ll cover different offense and defense techniques. You’ll learn what k-anonymity and quasi-identifier are. Think of discovering the world of suppression, perturbation, obfuscation, encryption, tokenization, and watermarking with elementary code examples, in case no third-party products cannot be used. We’ll see what approaches might be adopted to minimize the risks of data exfiltration.
Some of the abovementioned techniques are barely an inconvenience to implement, but difficult to support in the long run. We’ll show on which occasions Databricks Delta can help to make your datasets privacy-ready.
https://www.youtube.com/watch?v=jSp9eMANz0I
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
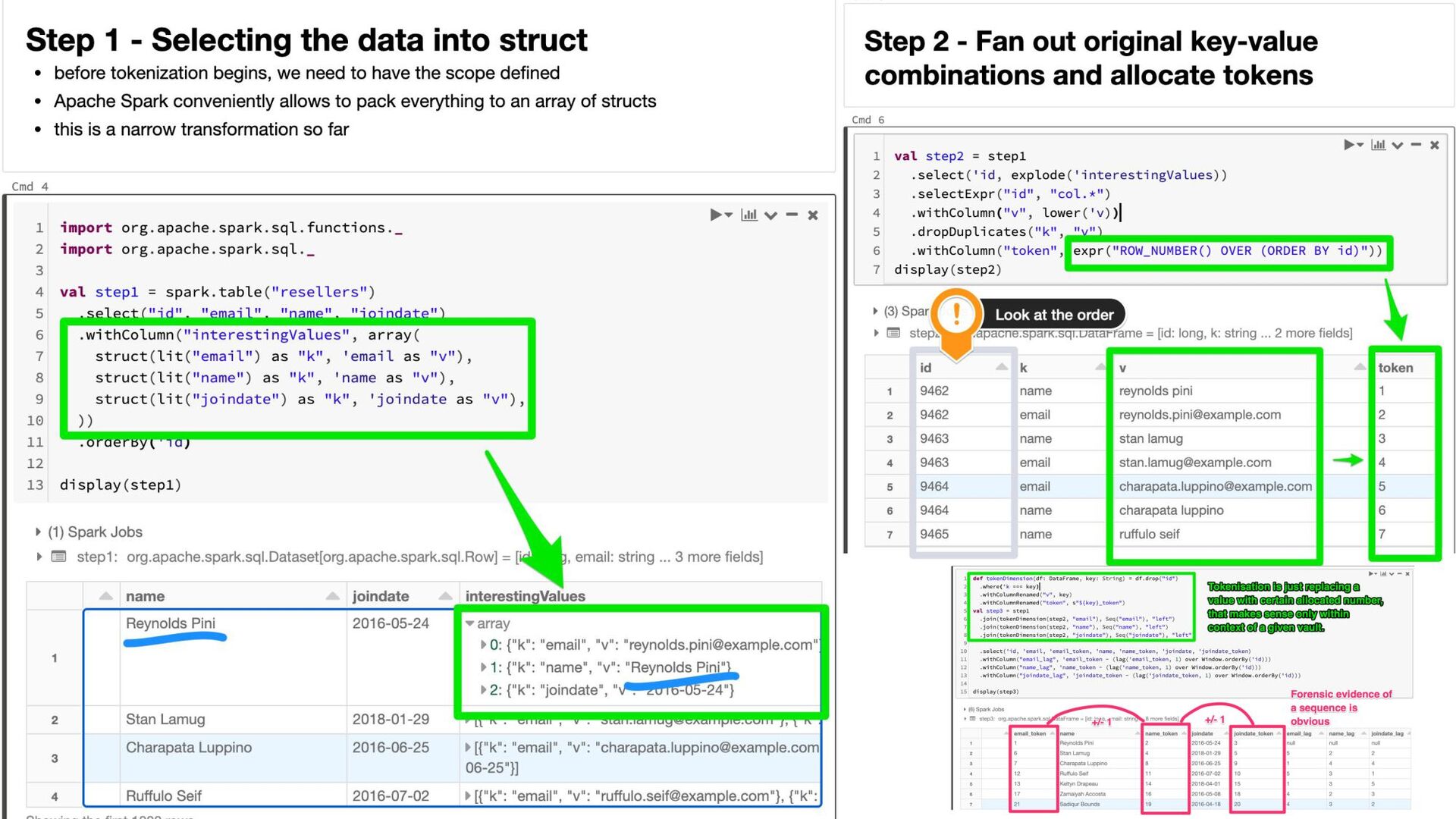{kind=link}
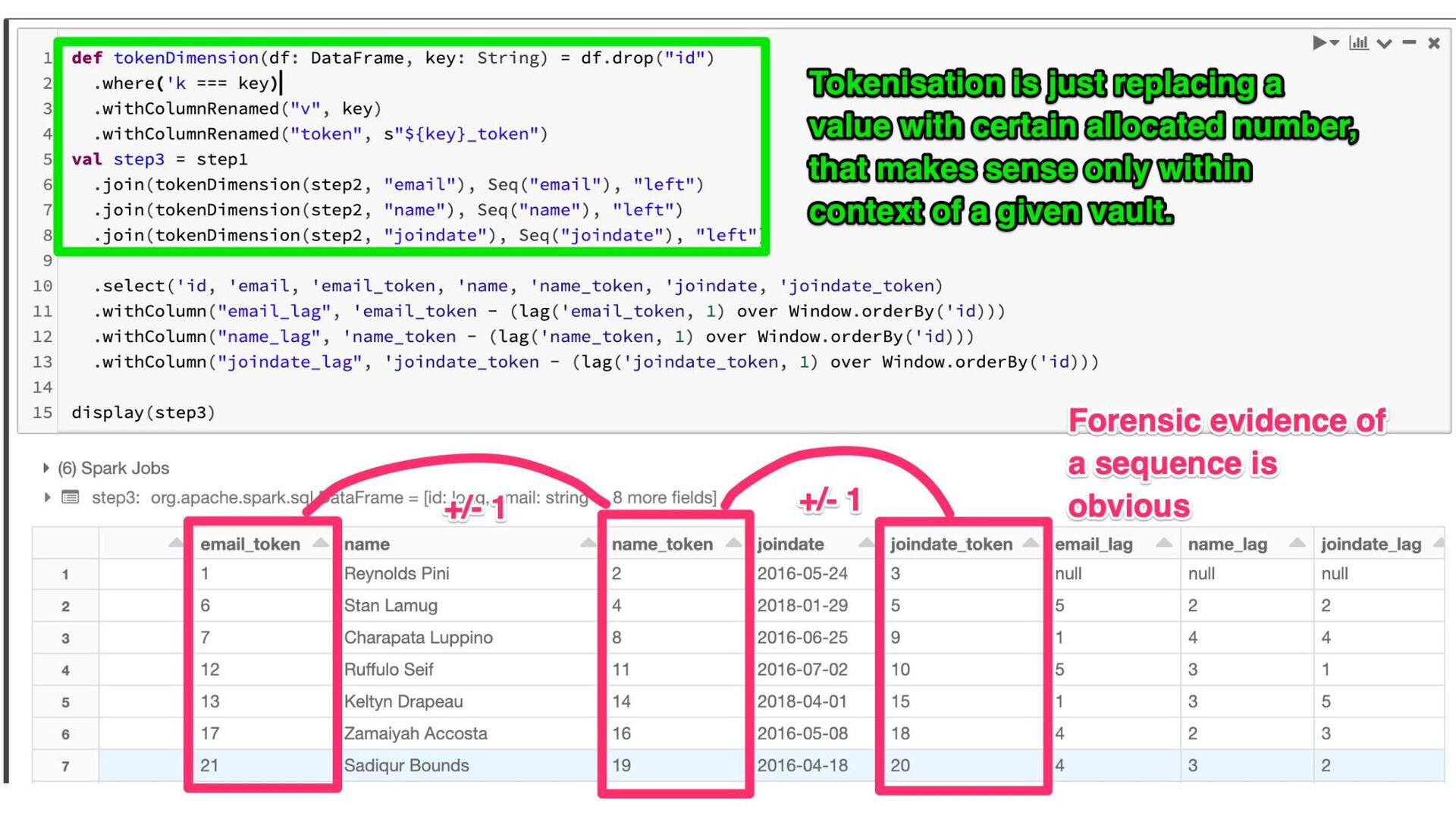{kind=link}
![val normalize = (x: Column) => lower(x) def fanoutOriginals(columns: Seq[String],](https://files.speakerdeck.com/presentations/7f1f2d28c36c4ebdad2910a60cb1faf6/slide_22.jpg){kind=link}
![import java.lang.Thread import java.util.ConcurrentModificationException import org.apache.spark.sql.expressions.Window def allocateNewTokens(columns: Seq[String], df:](https://files.speakerdeck.com/presentations/7f1f2d28c36c4ebdad2910a60cb1faf6/slide_23.jpg){kind=link}
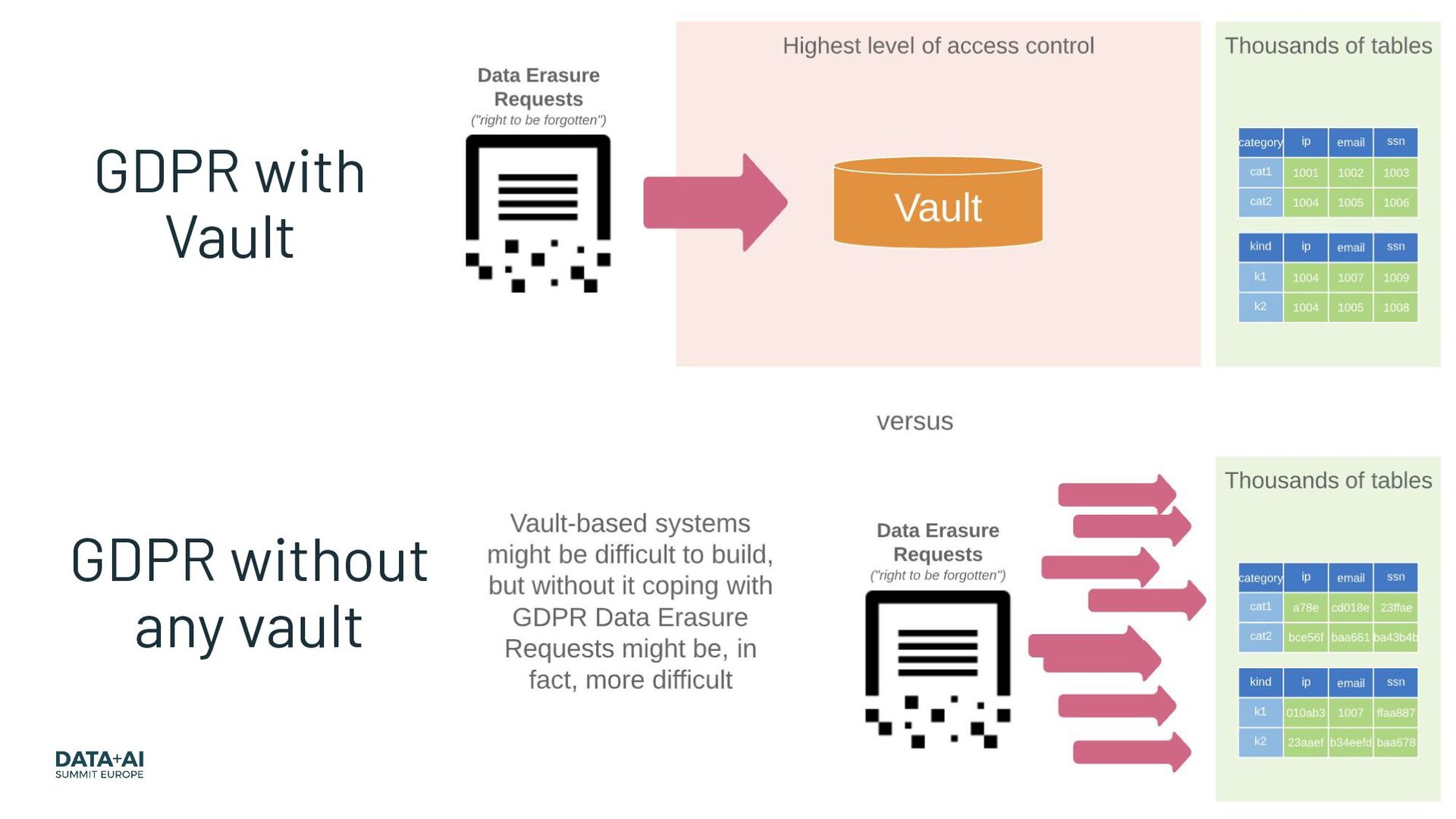{kind=link}
{kind=link}
{kind=link}
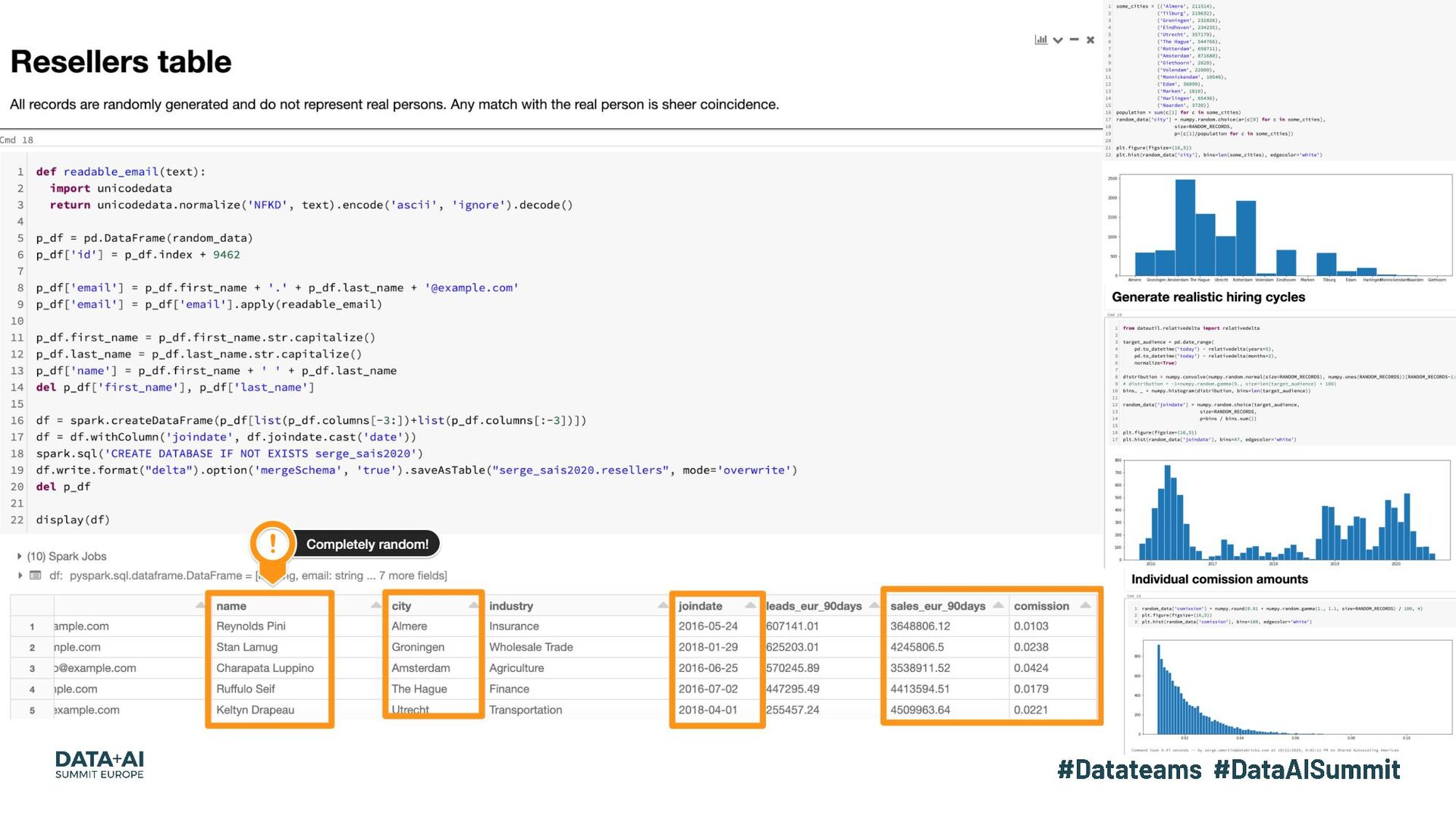{kind=link}
{kind=link}
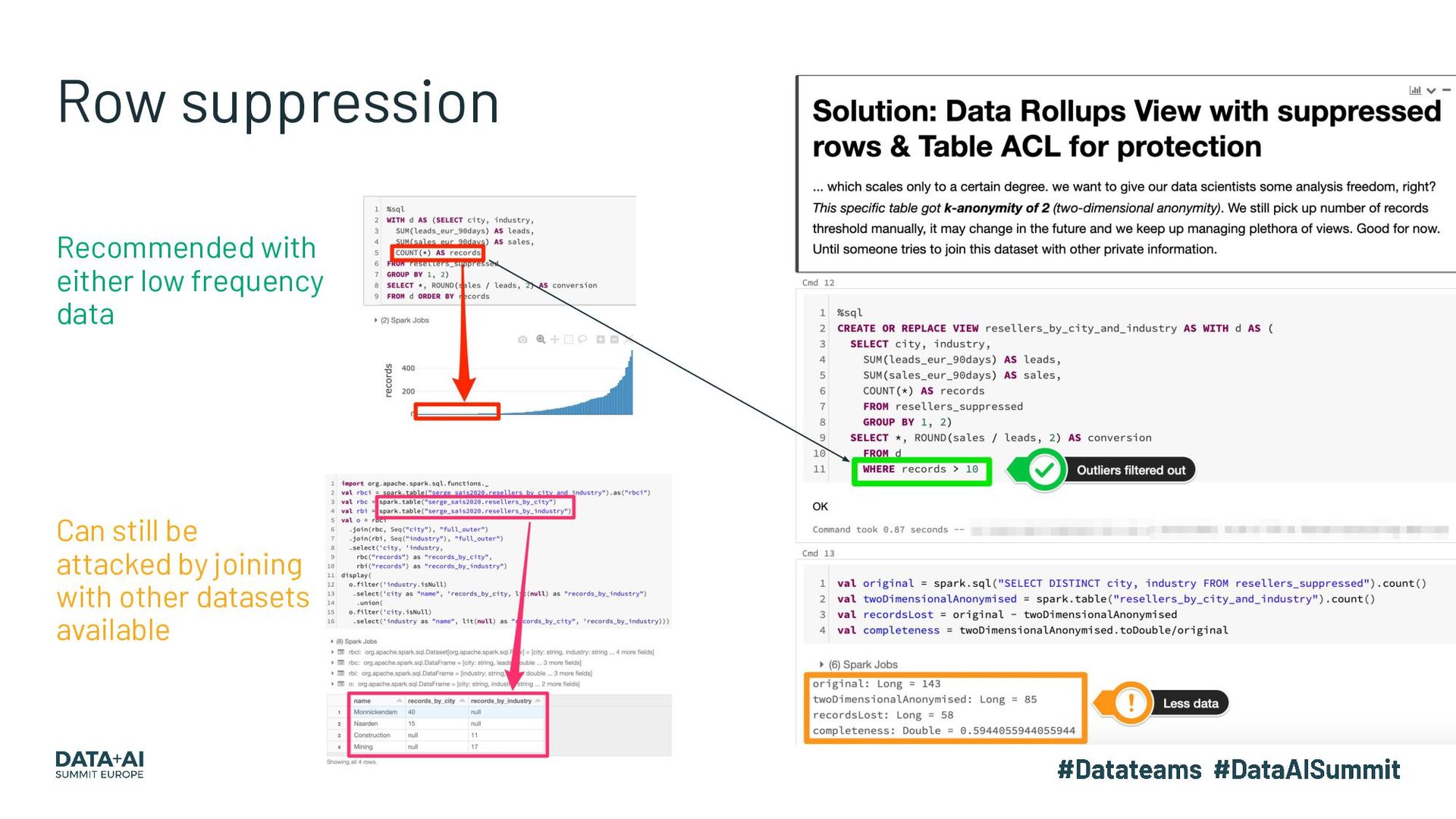{kind=link}
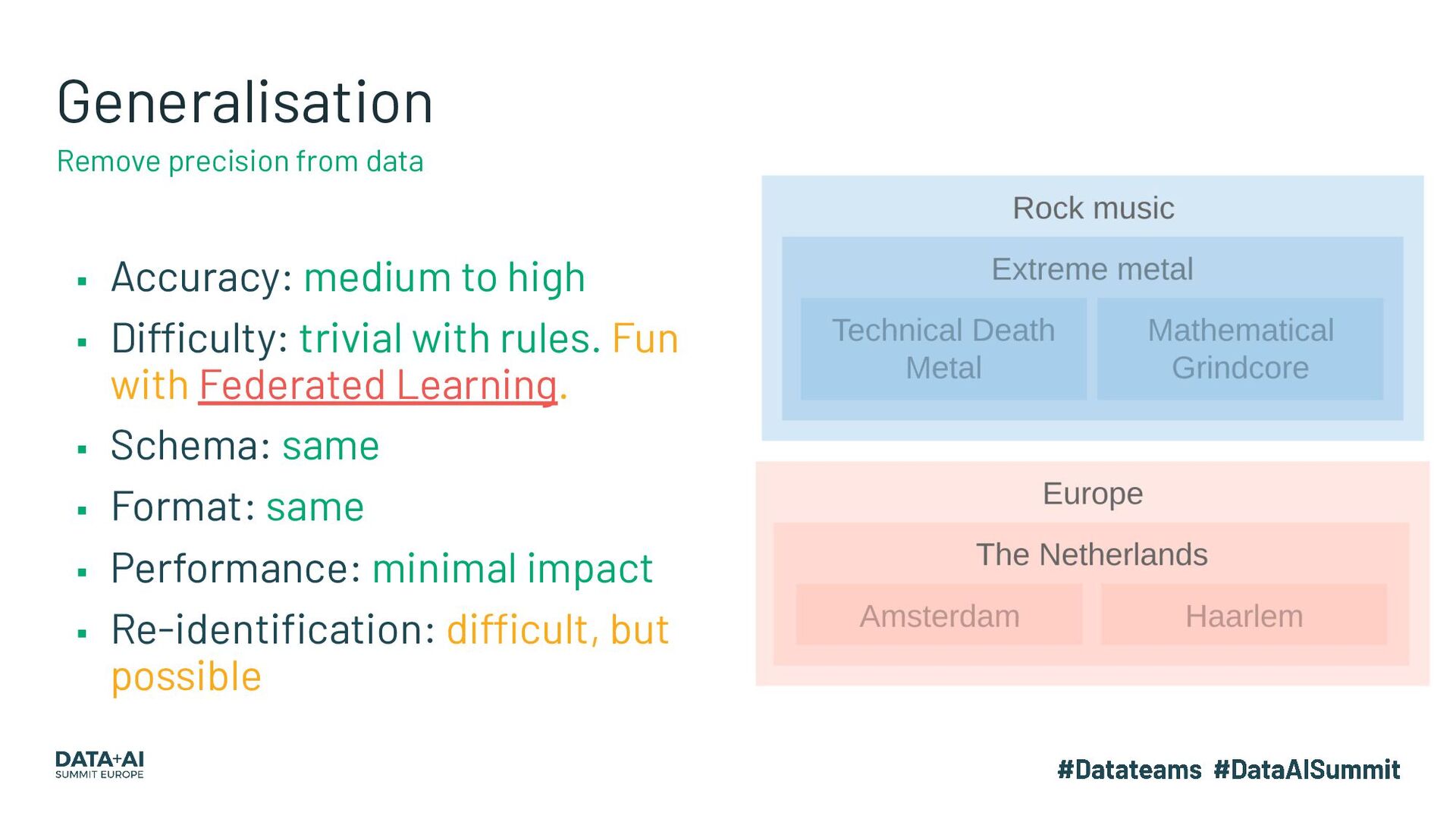{kind=link}
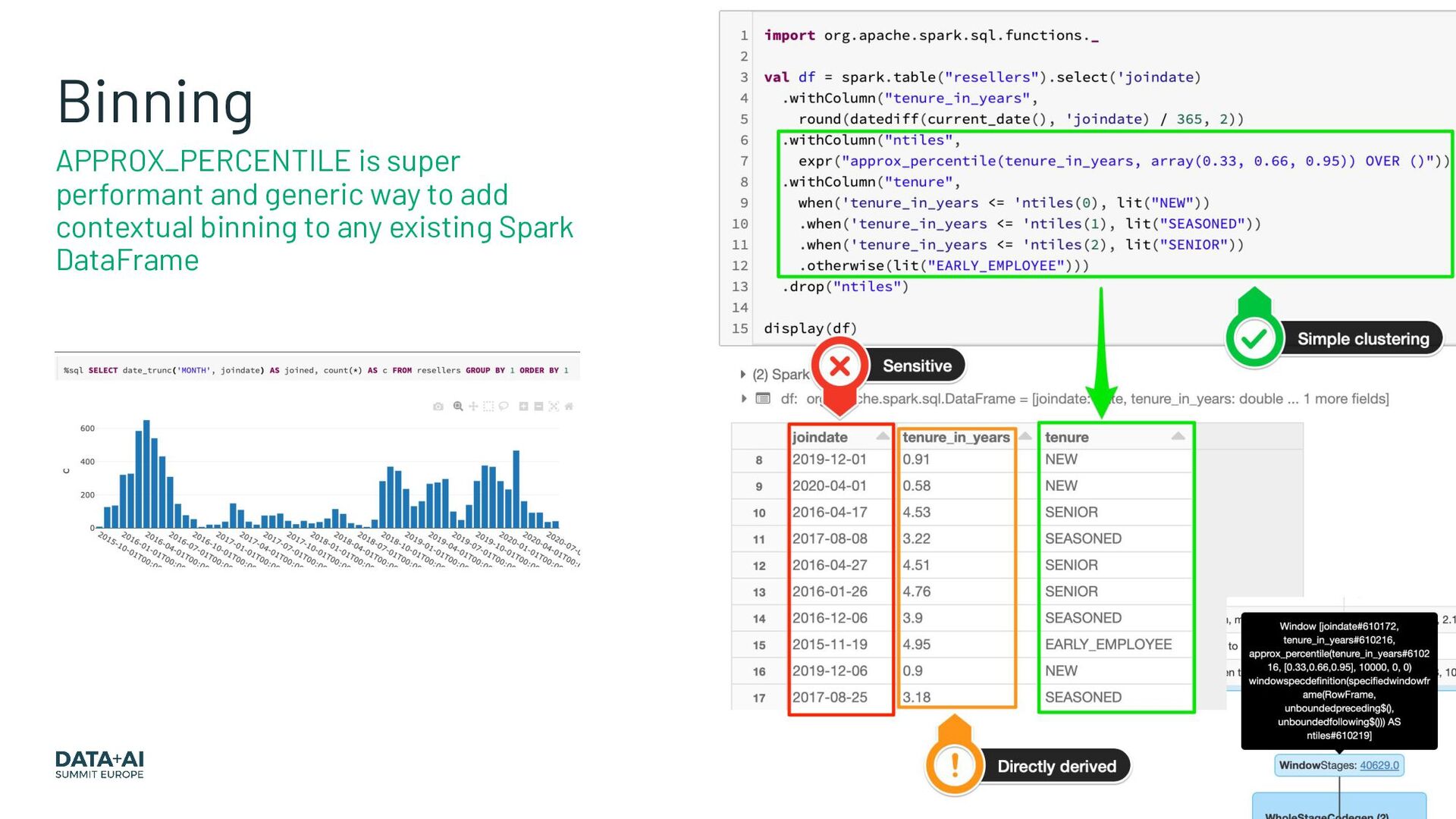{kind=link}
{kind=link}
{kind=link}
{kind=link}
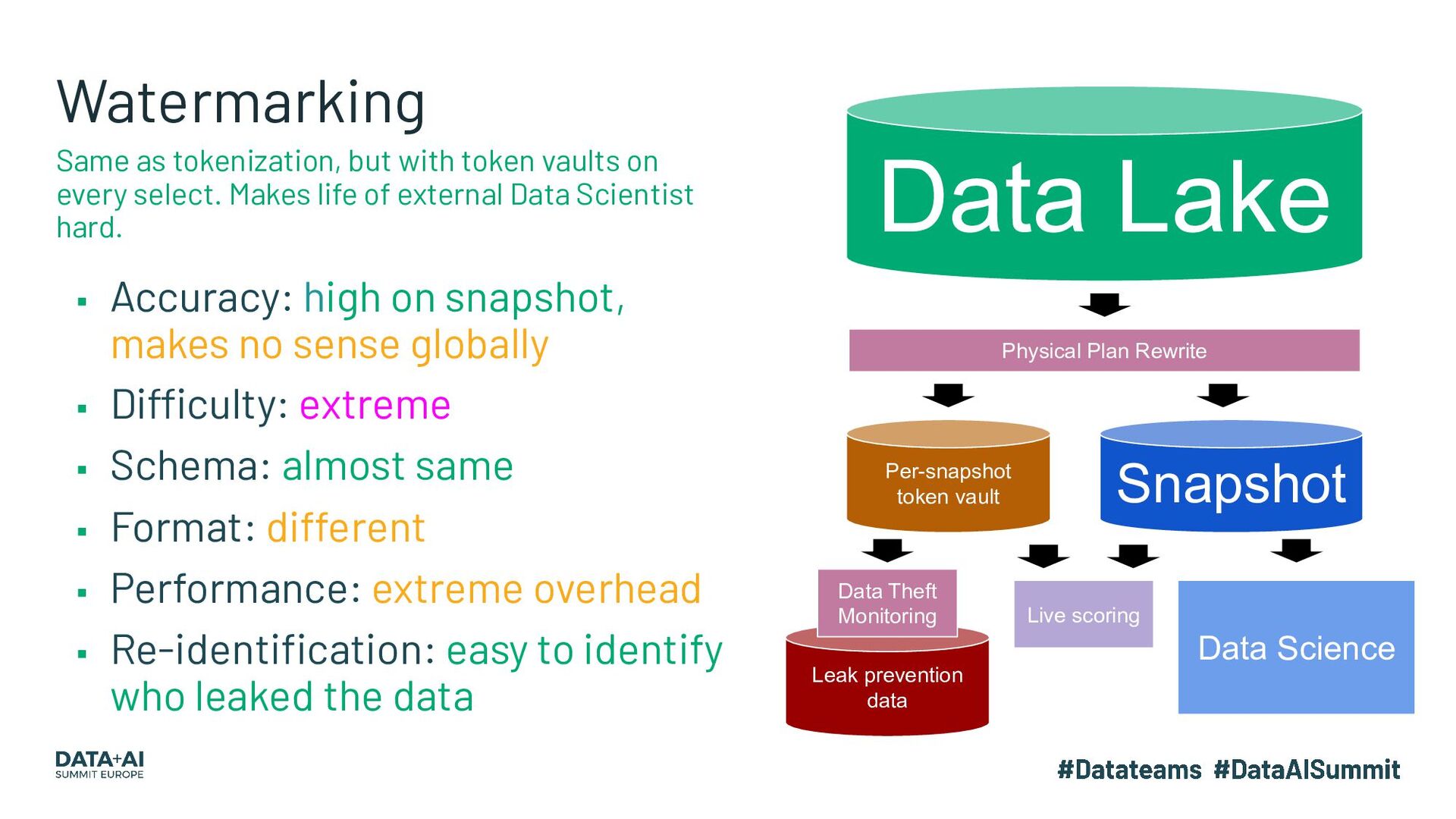{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}