Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
文献紹介:Pointwise法を利用したベトナム語単語分割
Search
Van Hai
July 08, 2015
330
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
文献紹介:Pointwise法を利用したベトナム語単語分割
Van Hai
July 08, 2015
More Decks by Van Hai
See All by Van Hai
文献紹介:Recurrent Neural Network based Language Model
nguyenvanhai
0
120
文献紹介:HMM Parameter Learning for Japanese Morphological Analyzer
nguyenvanhai
0
120
文献紹介:An Effective Neural Network Model for Graph-based Dependency Parsing.pdf
nguyenvanhai
0
180
文献紹介:Finding Synonyms Using Automatic Word Alignment and Measures of Distributional Similarity
nguyenvanhai
0
130
文献紹介:A Supervised Learning Approach to Automatic Synonym Identification based on Distributional Features
nguyenvanhai
0
200
文献紹介:Revisiting Word Embedding for Contrasting Meaning
nguyenvanhai
0
320
文献紹介:ベトナム語ツリーバンク
nguyenvanhai
0
350
文献紹介:ベトナム語の品詞付与 JVnTagger
nguyenvanhai
0
450
201506.pdf
nguyenvanhai
0
270
Featured
See All Featured
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
35k
Measuring Dark Social's Impact On Conversion and Attribution
stephenakadiri
2
240
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.7k
Building Flexible Design Systems
yeseniaperezcruz
330
40k
Testing 201, or: Great Expectations
jmmastey
46
8.2k
The Limits of Empathy - UXLibs8
cassininazir
1
550
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
340
Understanding Cognitive Biases in Performance Measurement
bluesmoon
32
3k
Into the Great Unknown - MozCon
thekraken
41
2.6k
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
400
GitHub's CSS Performance
jonrohan
1033
470k
Transcript
Pointwise法を利用したベトナ ム語単語分割 L u Tuấ ấn Anh, Yamamoto Kazuhide ư
Natural Language Processing Laboratory Department of Electrical Engineering 長岡技術科学大学 自然言語処理研究室 B4 Nguyen Van Hai 文献紹介
2 Outline • 機械学習によりベトナム語を単語分割する。 • Pointwise法を利用したベトナム語単語分割、 – n-gram声調 – n-gram声調の種類
– 辞書の特徴
3 Introduction • ベトナム語でスペースを用いて音節を分ける • 声調を結合して単語を作成する。 – ” 例: đ
t n c” ấ ướ ” 「国」は đ t” ấ ” 「土」と n c” ướ 「水」から作成する。 • 単語はいくつかの音節が下線でつながって表され る。 • 単語はスペースによって分けられる。
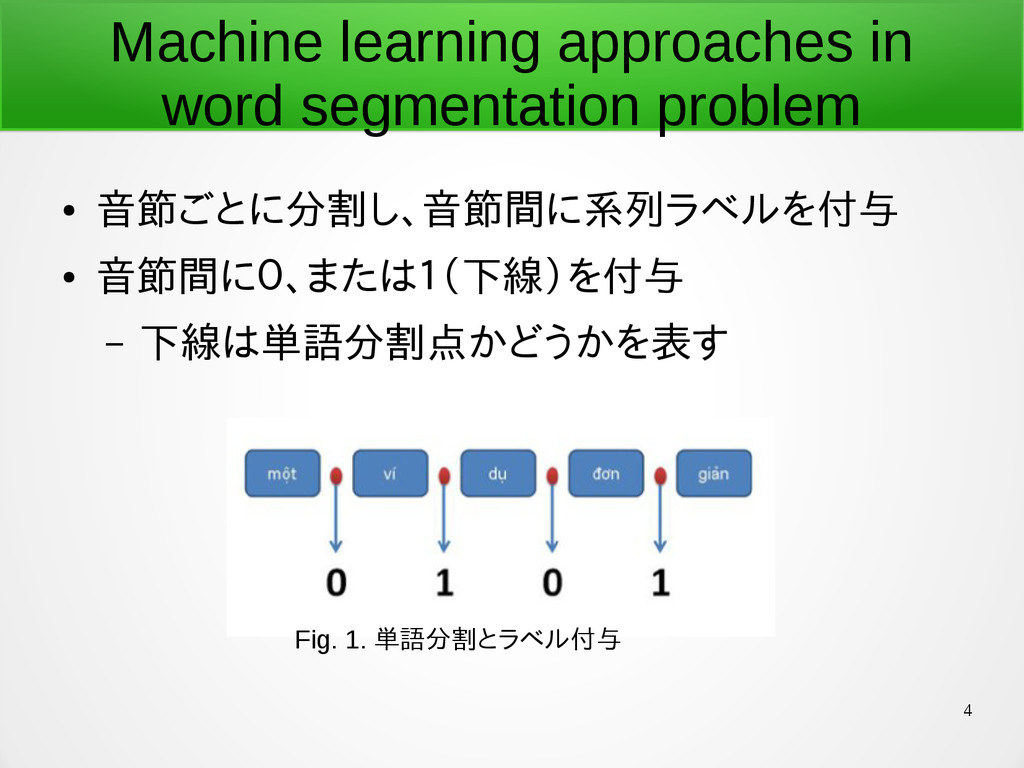
4 Machine learning approaches in word segmentation problem • 音節ごとに分割し、音節間に系列ラベルを付与
• 音節間に0、または1(下線)を付与 – 下線は単語分割点かどうかを表す Fig. 1. 単語分割とラベル付与
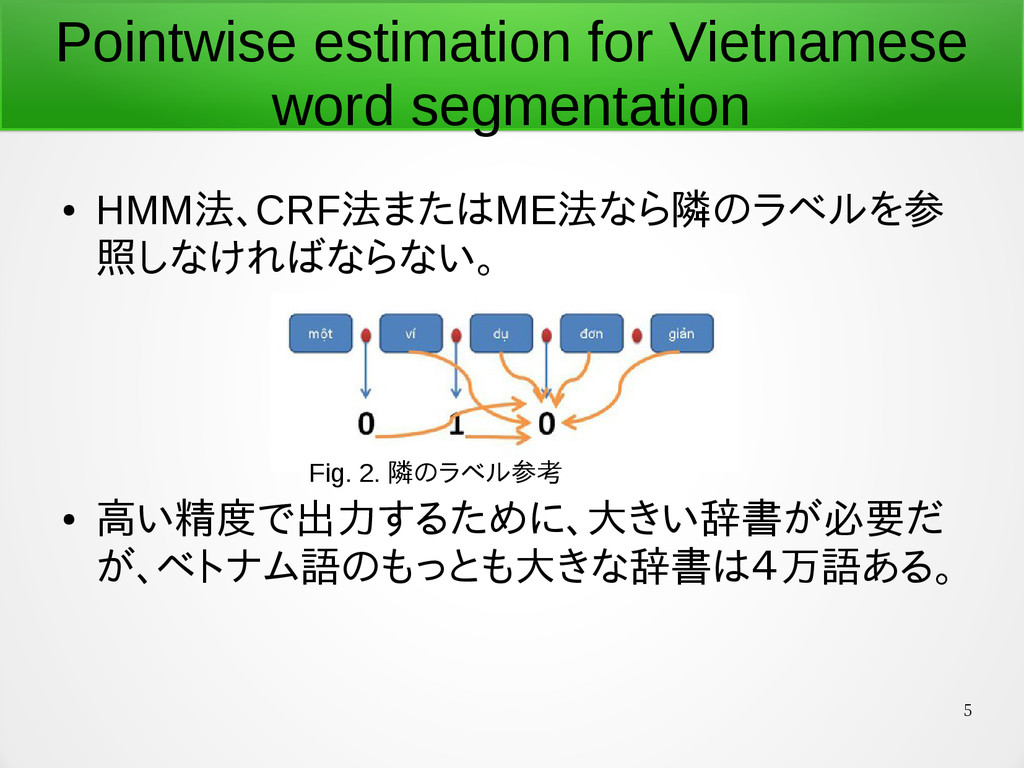
5 Pointwise estimation for Vietnamese word segmentation • HMM法、CRF法またはME法なら隣のラベルを参 照しなければならない。
• 高い精度で出力するために、大きい辞書が必要だ が、ベトナム語のもっとも大きな辞書は4万語ある。 Fig. 2. 隣のラベル参考
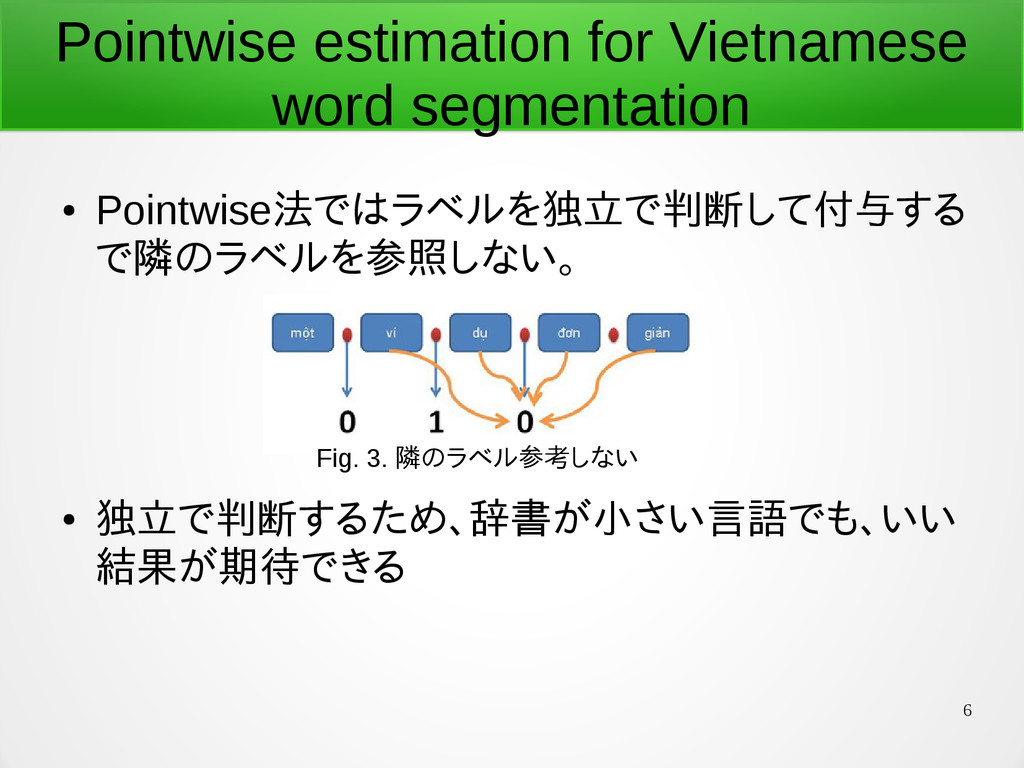
6 Pointwise estimation for Vietnamese word segmentation • Pointwise法ではラベルを独立で判断して付与する で隣のラベルを参照しない。
• 独立で判断するため、辞書が小さい言語でも、いい 結果が期待できる Fig. 3. 隣のラベル参考しない
7 Pointwise estimation for Vietnamese word segmentation • Pointwiseの特徴は以下の3種類である –
音節n-gam:窓幅W。ベトナム語の70%は2音節 の単語、14%は3音節の単語なので、W=3を利用 している。 – 音節n-gramの種類: • 大文字(U):音節の始めは大文字 • 普通字(L):音節の始めは普通の文字 • 数字(N):音節の始めは数字
8 Pointwise estimation for Vietnamese word segmentation • 他の種類(O):外国語と上記の2つの種類以 外
Fig. 4. N-gram音節とN-gram音節の種類、W=2
9 Pointwise estimation for Vietnamese word segmentation • 辞書情報を利用しラベル付与:対象から見て –
真ん中(I):左右の単語が辞書に存在する – 右側(R):右側の単語が辞書に存在する – 左側(L):左側の単語が辞書に存在する ” 以下の例にとって評価位置は ví d ” ụ ” で、 I|ví d ” ụ Fig. 5. 辞書の特徴
10 Training data • 訓練データは一部のアノテーションで良い “ 例: 1 ví_d đ
n_gi n .” ụ ơ ả アノテーション済 – “1 ví_d đ n gi n .” ụ ơ ả “ それで ví_d ” ụ は分割させたが “đ n gi n” ơ ả は分割させない • 時間とお金がかかり、人によって違う意味で理解される “Ông già đi nhanh quá” は • “Ông_già đi nhanh quá” • “Ông già_đi nhanh quá”.
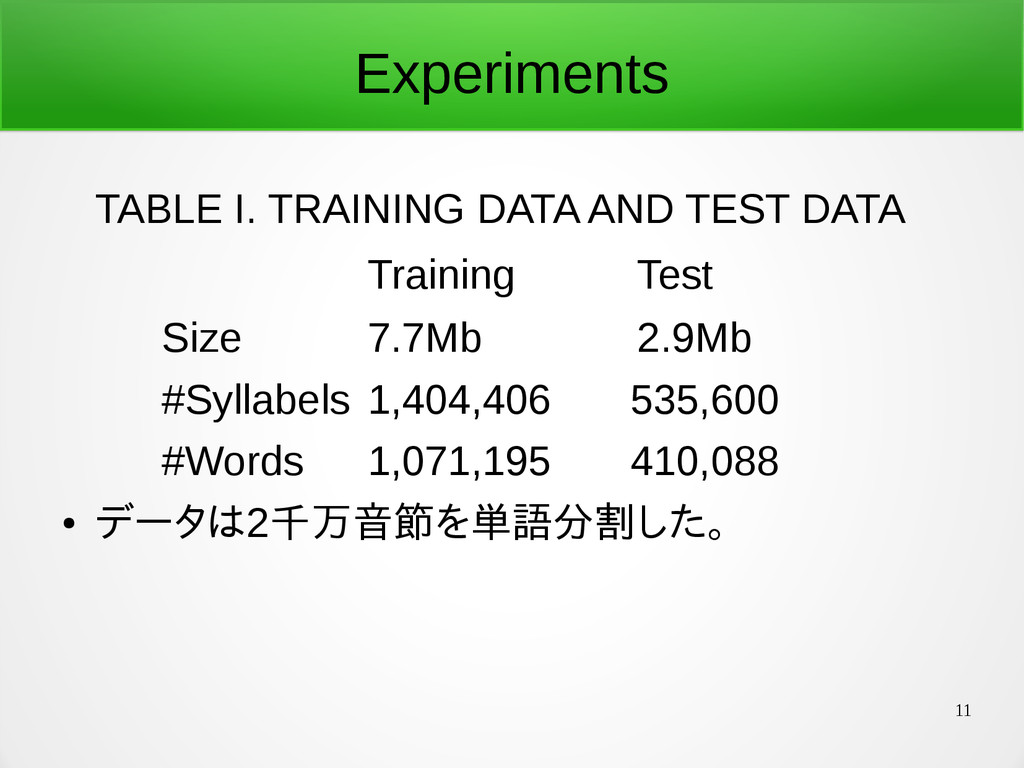
11 Experiments TABLE I. TRAINING DATA AND TEST DATA Training
Test Size 7.7Mb 2.9Mb #Syllabels 1,404,406 535,600 #Words 1,071,195 410,088 • データは2千万音節を単語分割した。
12 Experiments TABLE II. RESULTS OF TWO METHOD DongDu Accuracy
98.2% Time 26.2 (s) RAM 15.1Mb • ベトナム語の中で、一番精度が高いツールと比べて dongduの精度の方が1%高くなって8倍スピードが早 い
13 Extension • 新データを作成 – 例えばAコーパスはn音節持っている – そのコーパスは10分割すると、それぞれn/10音 節となる –
1部を手で単語分割して学習する – 次にdongduによる単語分割をし、チェックする 何回か繰り返すと精度が高くなる
14 Conclusion • Pointwise方法により、ベトナム語単語分割を行っ た • 実験結果から他の方法に比べてdongduの精度が 高くてスピードも早い
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}