Sanjeev Khudanpur Recurrent neural network based language model In 11th Annual Conference of the International Speech Communication Association, pp.1045– 1048, 2010
word in textual data • Special language domain: • Sentence must be described by parse trees • Morphology of words, syntax and semantics • There are some significant progress in language model • Measure by ability of models to better predict sequential data 3
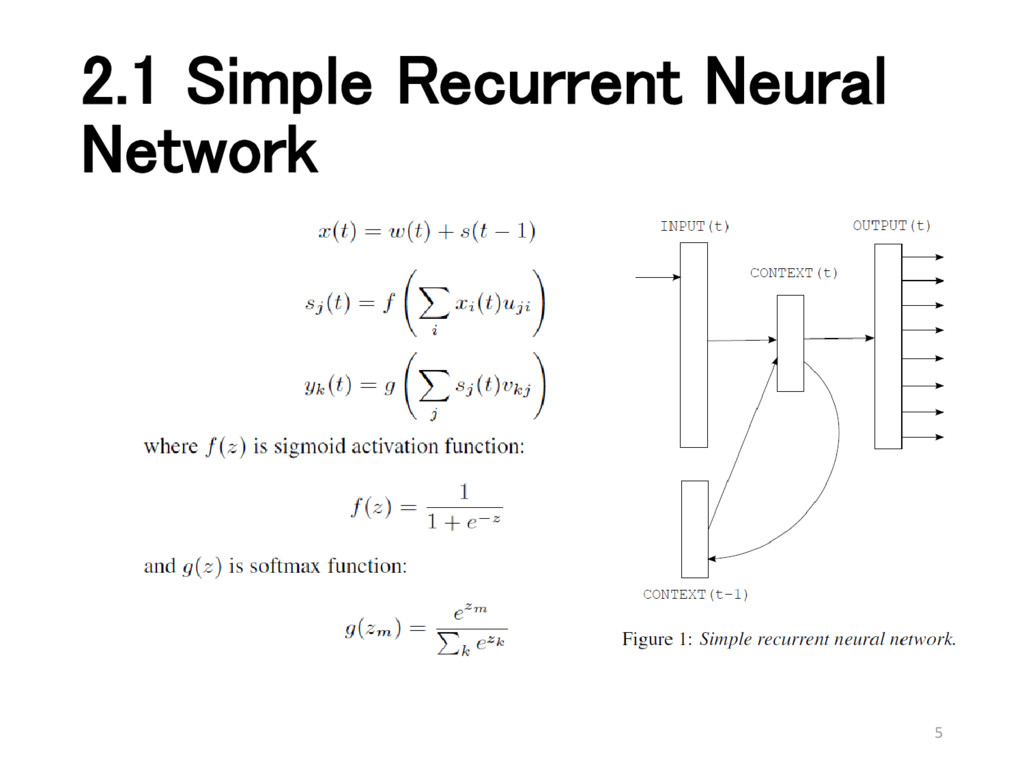
in several epochs • Weights are initialized to small values • Train network by standard backpropagation algorithm with stochastic gradient descent • Error vector:
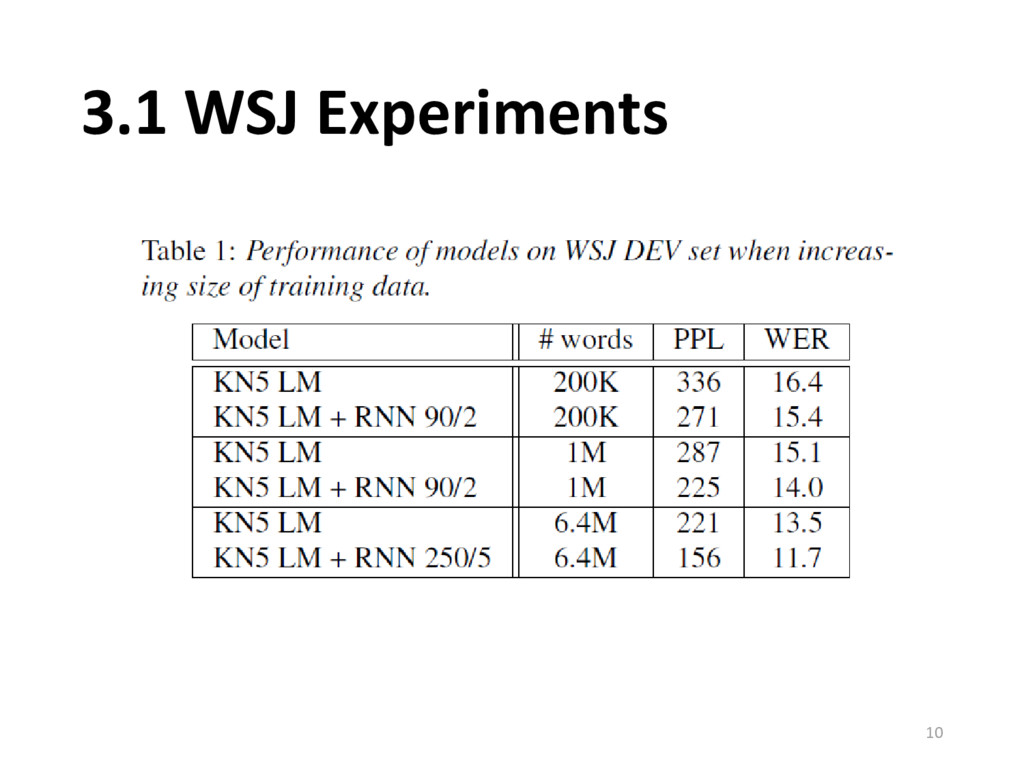
NYT section of English Gigaword • Training 6.4M words (300K sentences) • Perplexity evaluated on 230K words • Kneser-Ney smoothed 5-gram as KN5 • RNN 90/2 • Hidden layer size is 90 • Threshold for merging words to rare token is 2 9
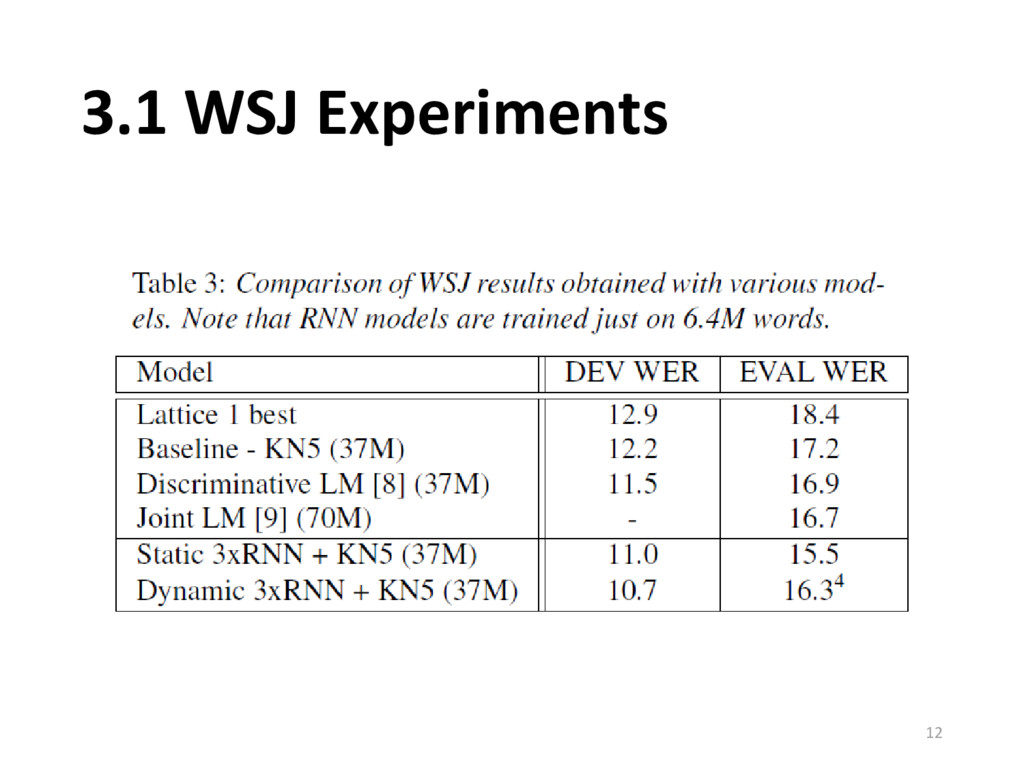
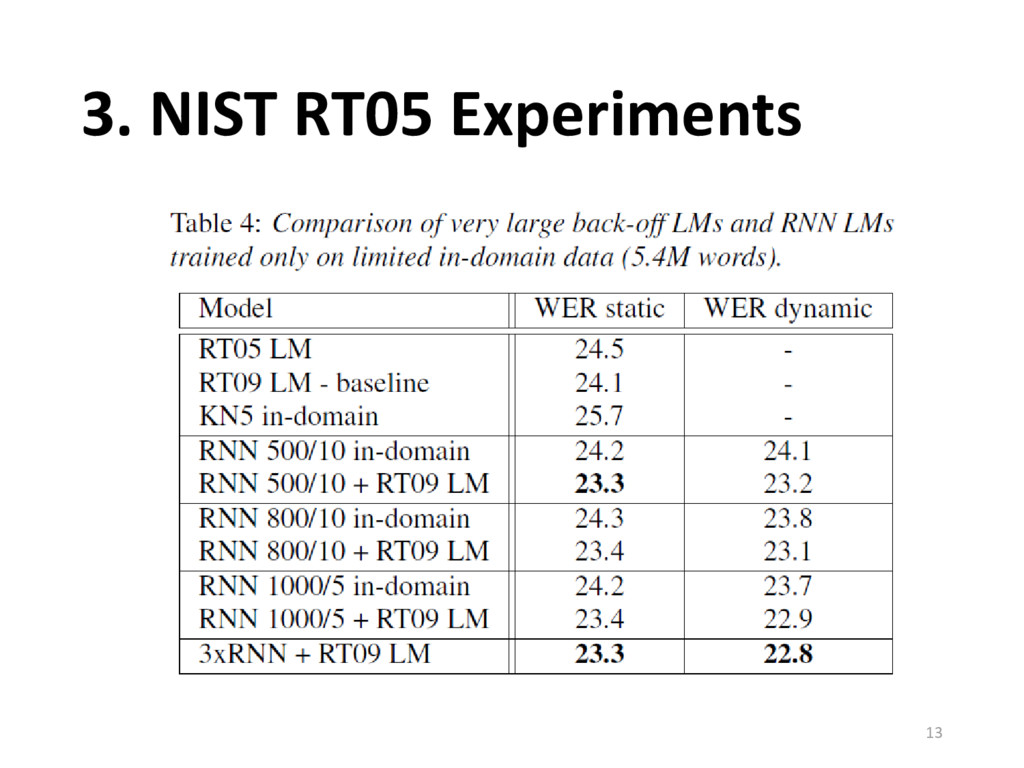
18% with the same data • Around 12% when backoff model is trained with data 5 times than RNN model • NIST RT05 can outperform big backoff models 14 Vietnamese Morphological Analysis 2017/05/17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}