tri n m t số ố s n ph m thiề ốt yề ốu về ề x lý ứ ể ộ ả ẩ ử tiề ống nói và văn b n tiề ống Vi t ” ả ệ Dr. Phan Xuan Hieu 長岡技術科学大学 自然言語処理研究室 Nguyen Van Hai 文献紹介
(i = 0;1) is_number(i) (i= -1:0:1) contain_numbers(i) contain_hyphen contain_comma i の単語は数字を含むことや全角をチェックする dict(i) (i= 0,1) 品詞を付与することできる is_full_repretative(0) is_partial_repretative(0) 繰り返しの単語をチェックする prf(0) sff(0) 頭音節 sự 「 sự h ng d n ướ ẫ 」 毛音節 hóa 「 công nghi p ệ hóa 」
{kind=link}
{kind=link}
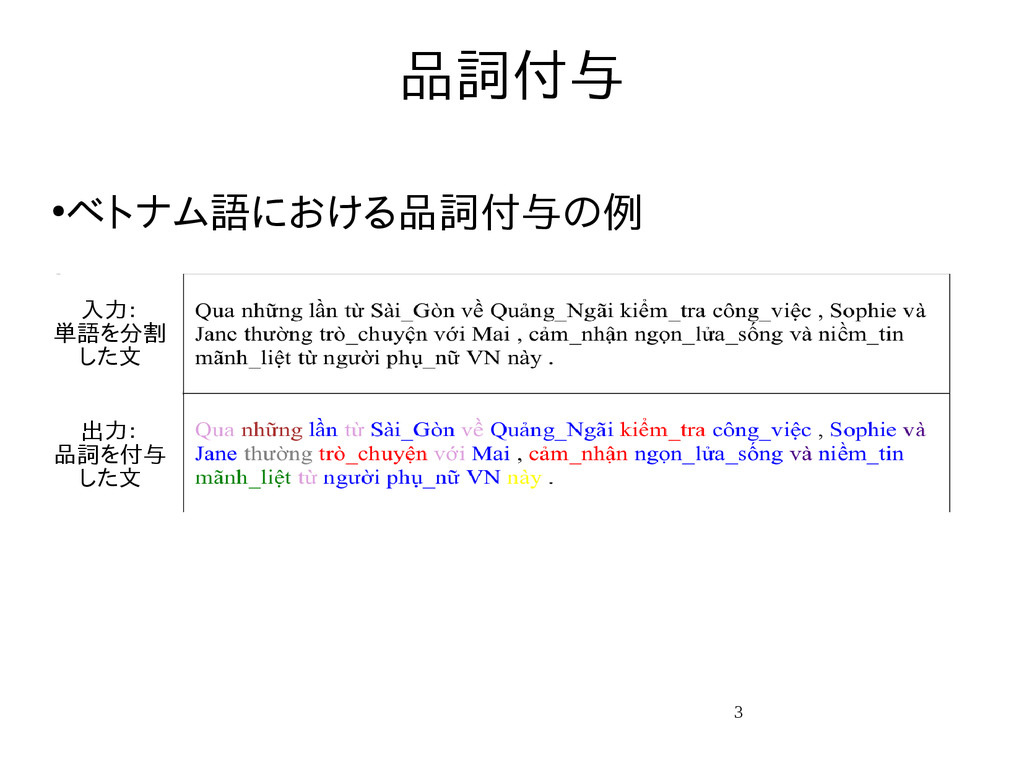{kind=link}
{kind=link}
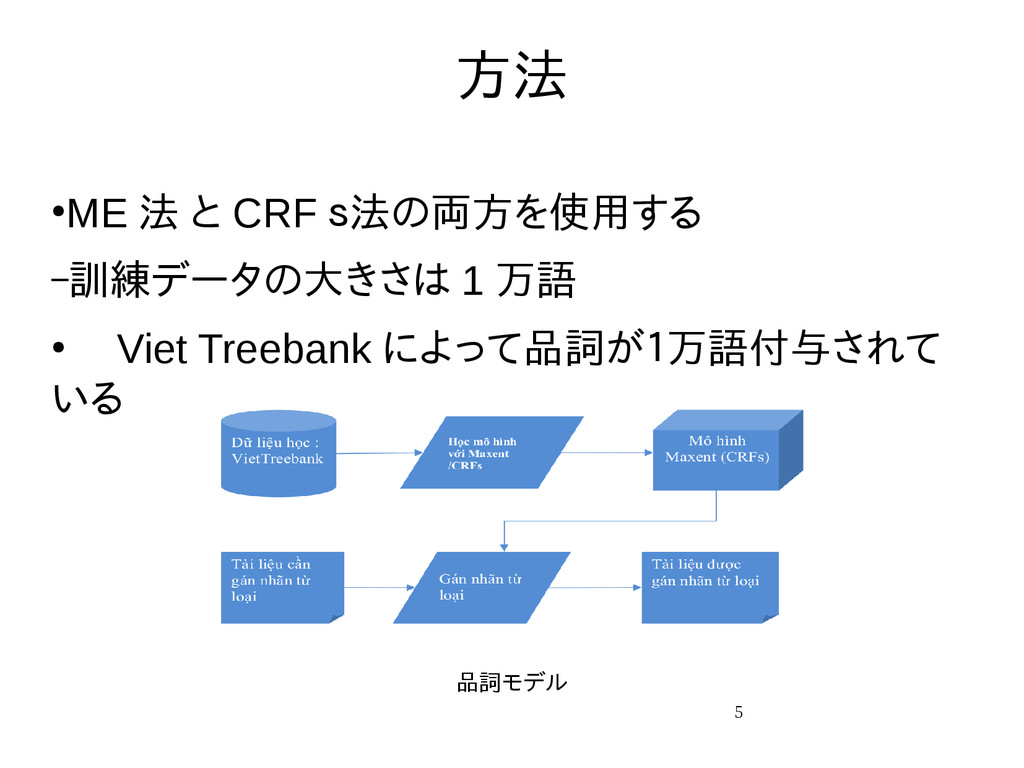{kind=link}
{kind=link}
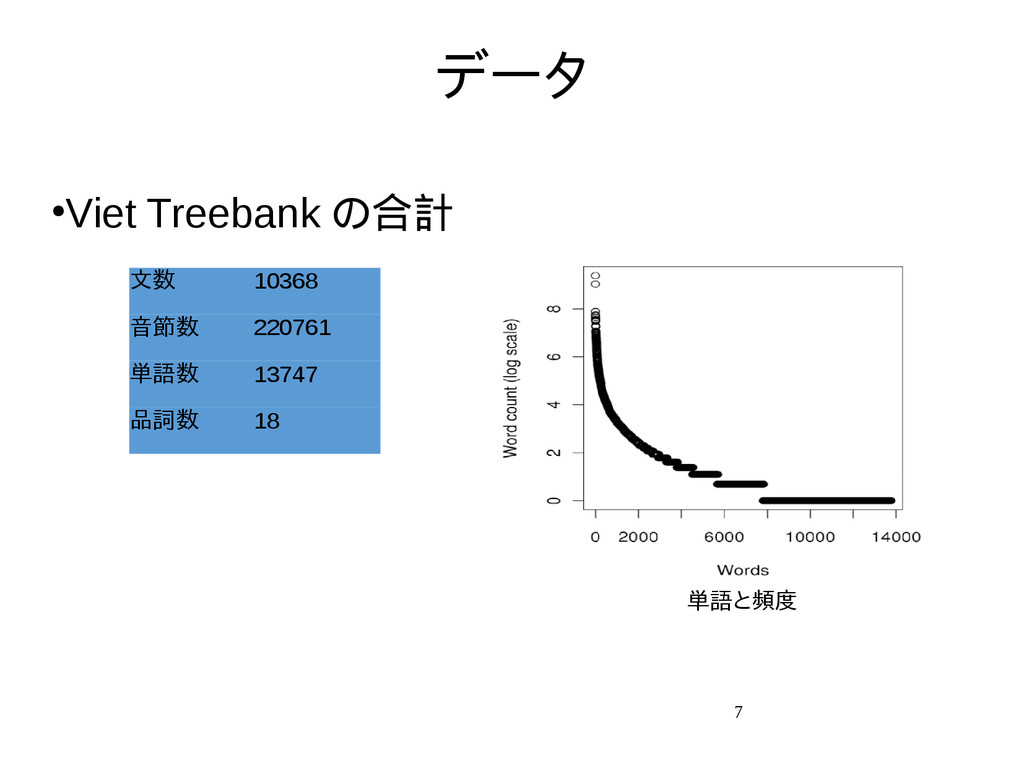{kind=link}
{kind=link}
{kind=link}
{kind=link}
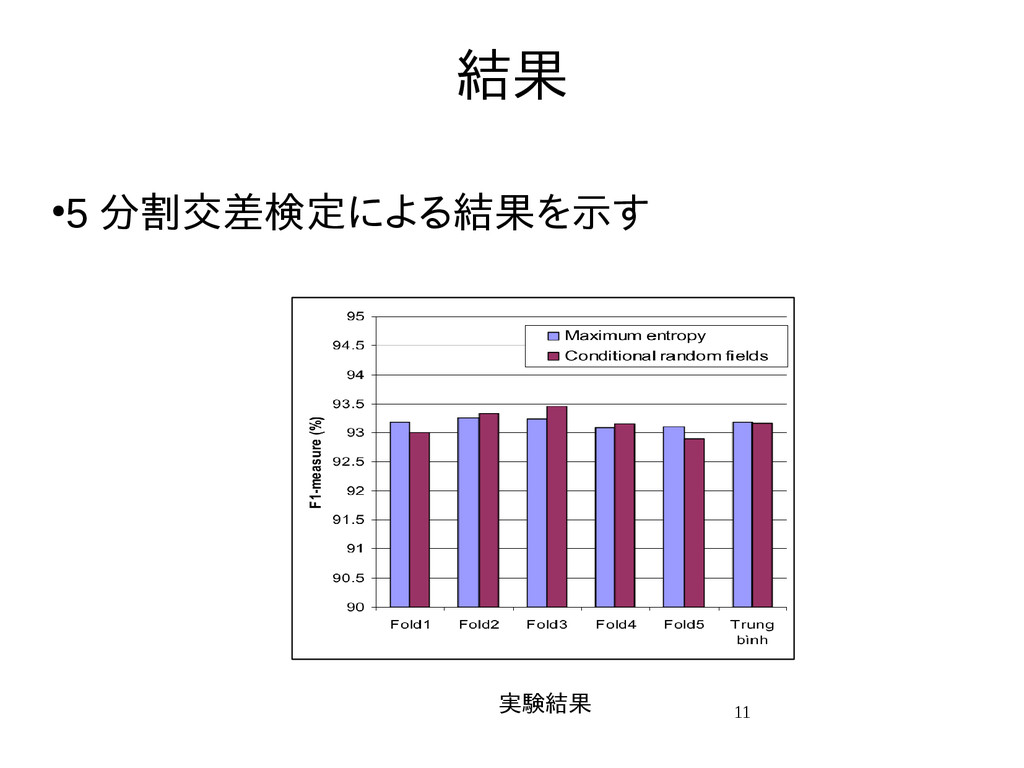{kind=link}
{kind=link}