Learning Approach to Automatic Synonym Identification based on Distributional Features Masato Higiwara Graduate School of Information Science Nagoya University Proceedings of the ACL-08: HLT Student Research Workshop (Companion Volume), p1-6, Columbus, June 2008.
semantic relatedness of word in NLP tasks. • This paper use a novel approach to synonym identification based on supervised learning and distributional features. • The F1 of this evaluation experiment increase over 120%, compared with the conventional classification.
words by the commonality of context. • Syntactic pattern such as “such X as Y” and “Y and other X”, and extract hyponym relation of X and Y. • This paper , they re-formalize synonym acquisition as a classification which classifies word pairs into synonym/non-synonym.
of words. • RASP Toolkit 2 (Briscoe et at., 2006) is used to extract word relations. • RASP outputs the extracted dependency structure as n-ray relations as follows:
stemmed word and context. • Using co-occurrences extracted, they define distribution features • The feature value is calculated as the sum of two corresponding pointwise mutual information weight.
words and relations which are on the dependency path. • In the experiment, they limited the maximim length of syntactic path to five. • Define and calculate the pattern based feature, which corresponds to the syntactic pattern.
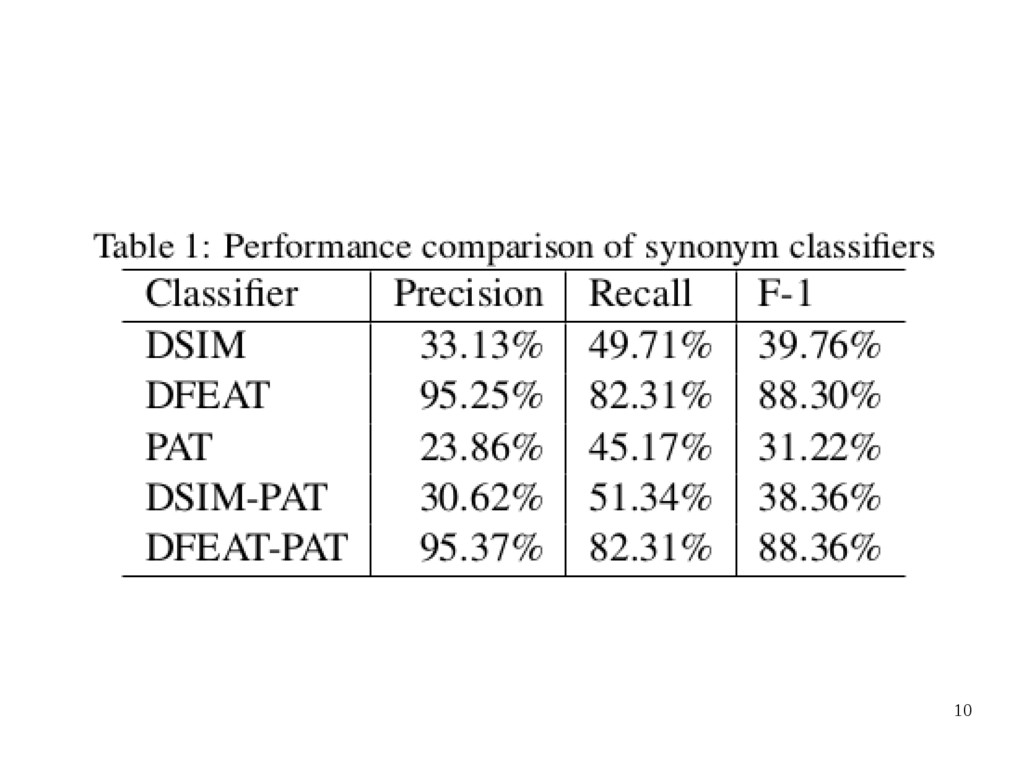
(DFEAT) • Pattern-based Features (PAT) • Distributional Similarity and Pattern-based Features (DSIM-PAT) • Distributional Features and Pattern-based Features (DEFEAT-PAT)
section (1994) of consisting 46,000 documents, 922,000 sentences, and 30 million words. – Apply feature selection and reduce the dimensionality. • Supervised learning – The example set E end up with 2,148 positive and 13,855 negative examples. – Divide to conduct five-fold cross calidation. SVM was adopted for ml and RBF as the kernel.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}