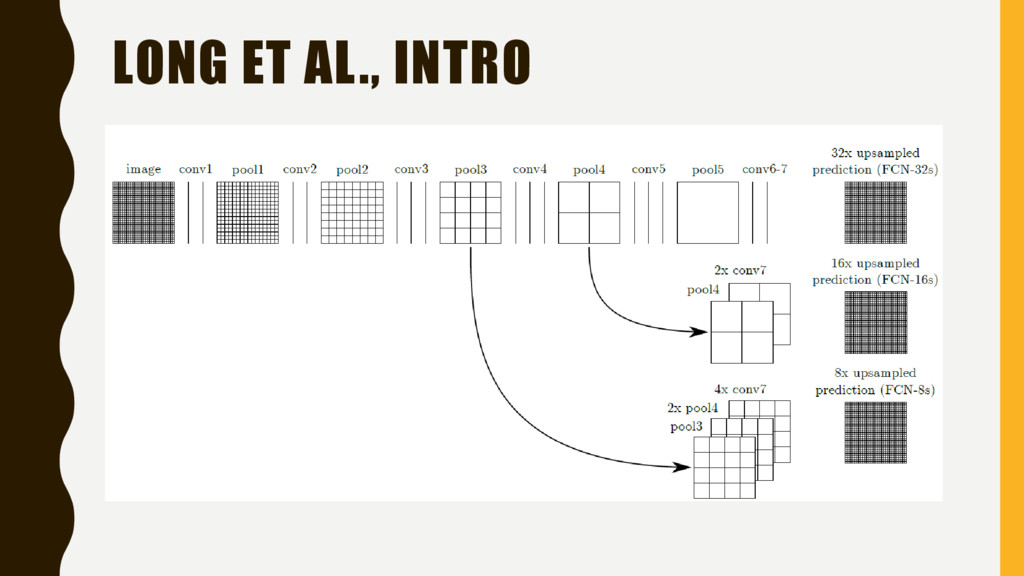
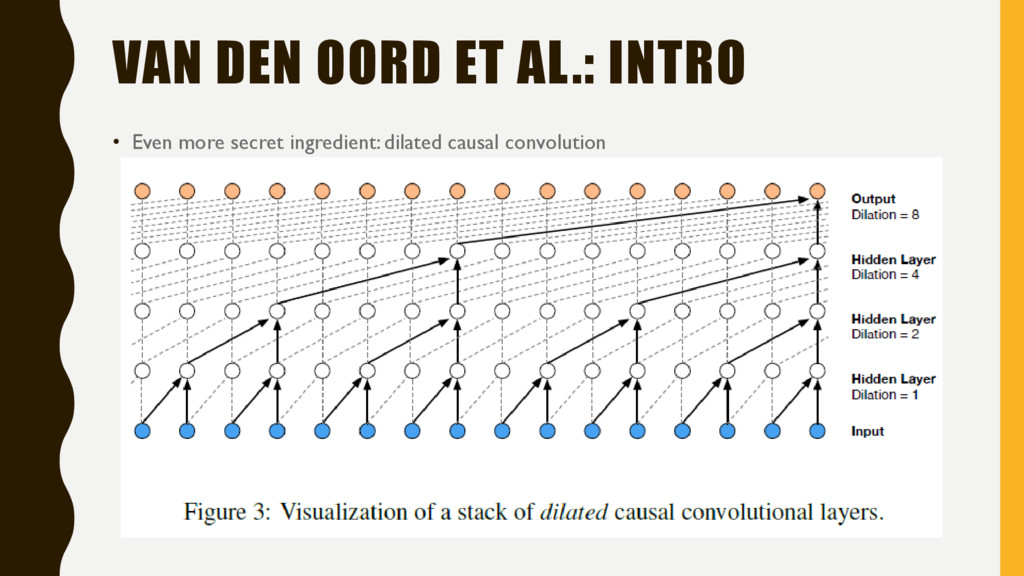
obtain “dense” predictions, i.e., predictions for every pixel in the output? 1. Shift and stitch, or equivalently ‘a trous’ / dilated convolution 2. Upsampling, AKA backwards convolution or deconvolution
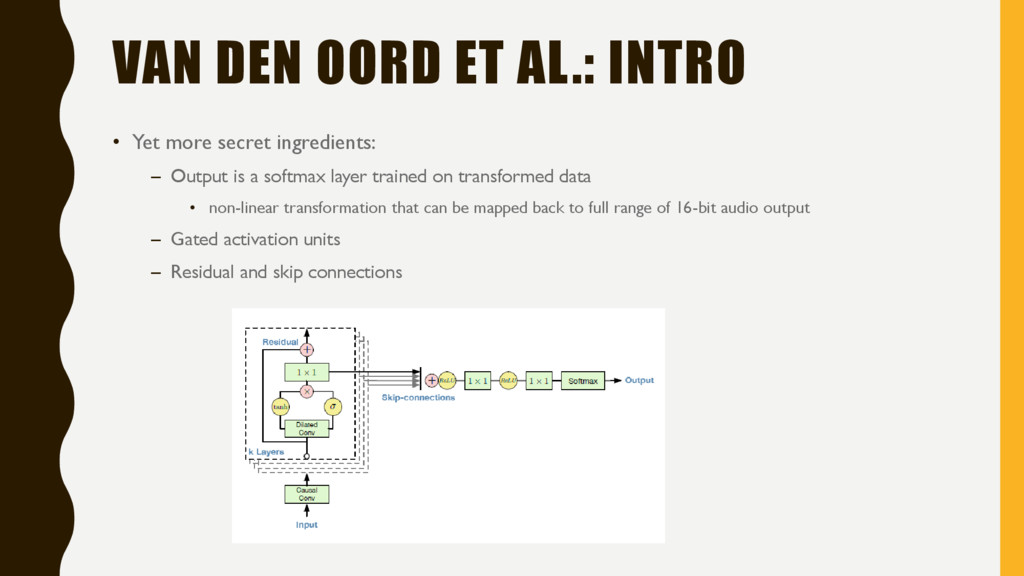
ingredients: – Output is a softmax layer trained on transformed data • non-linear transformation that can be mapped back to full range of 16-bit audio output – Gated activation units – Residual and skip connections
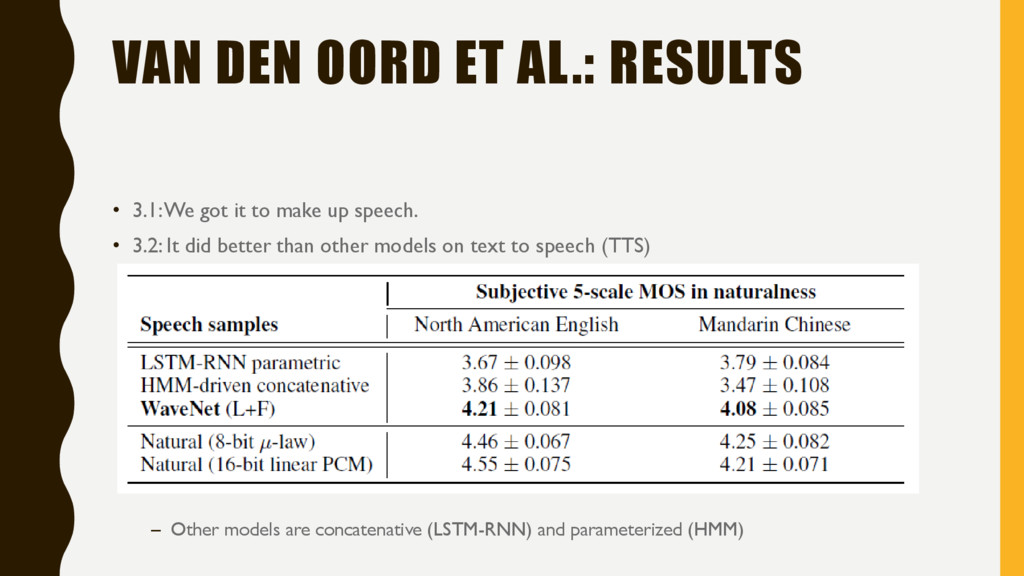
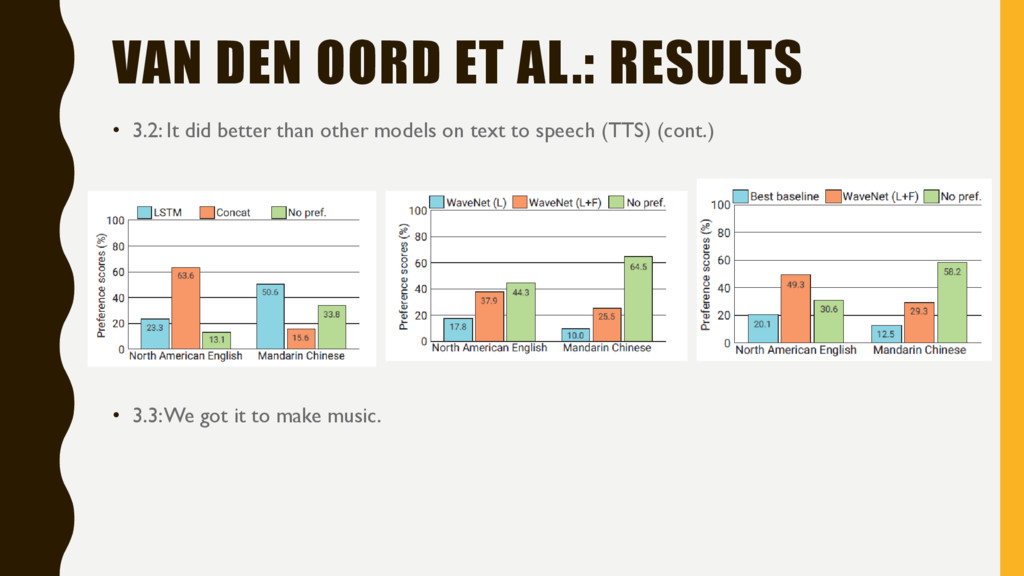
it to make up speech. • 3.2: It did better than other models on text to speech (TTS) – Other models are concatenative (LSTM-RNN) and parameterized (HMM)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}