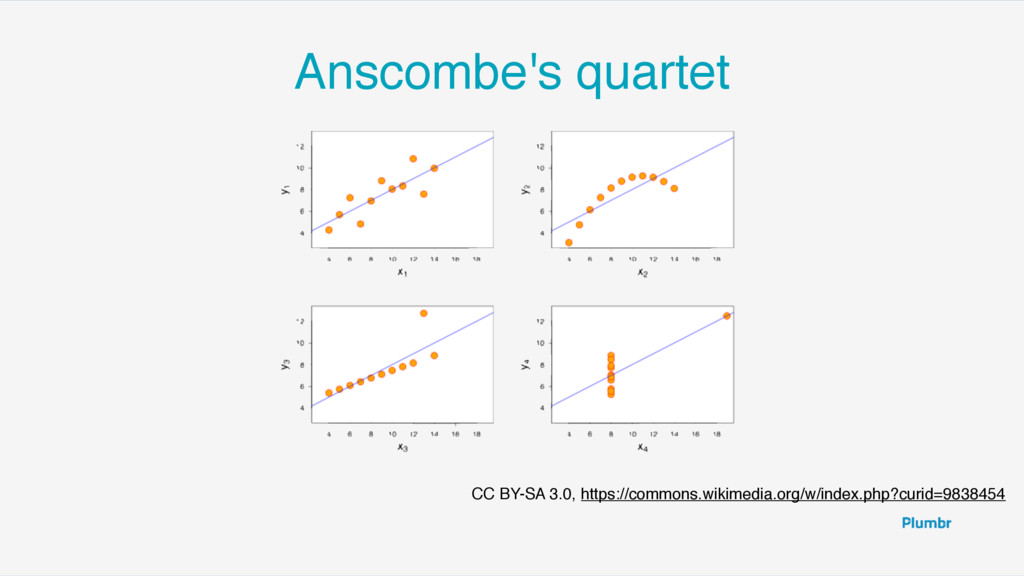
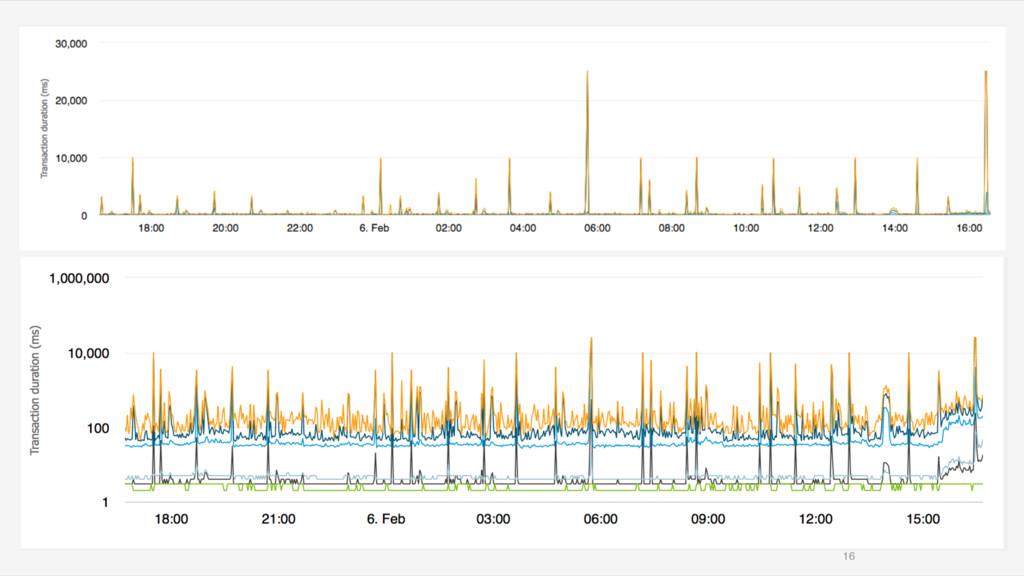
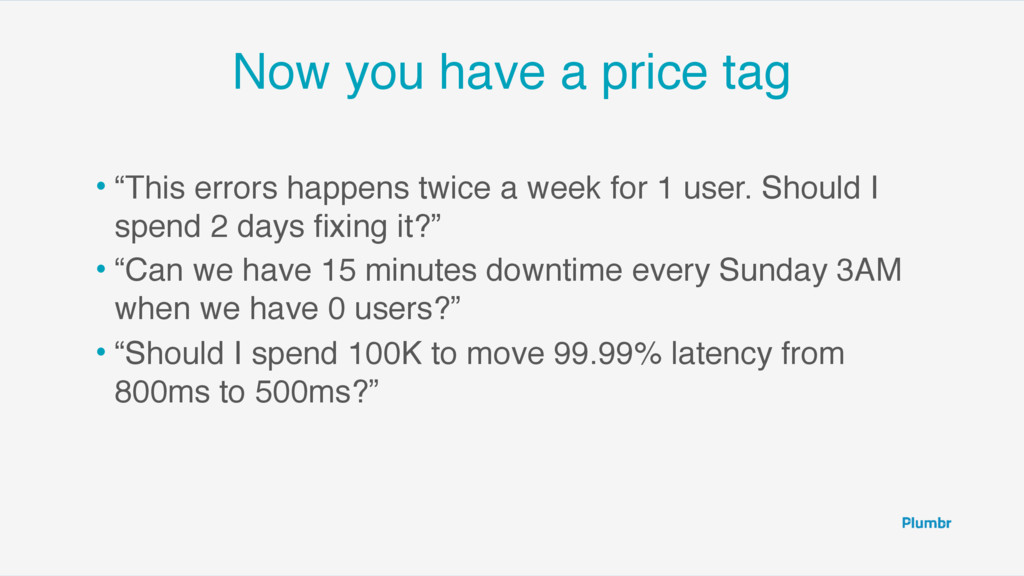
What is the main metric you monitor to judge the health of your system? Average CPU load? The slowest query in DB? We have talked with many teams, both developers and operations, about what they monitor and what metric they collect to assess the health of their product. Too many times we heard about CPU monitoring, log aggregation, average response times etc. Only in rare cases end-user satisfaction and it’s impact to business was measured. From this talk attendees will learn: * why you should invite business people to help define important monitoring metrics * why monitoring only technical gauges is not enough * the most misleading metric: the average value and the power of percentiles
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}