Slidedeck used during the Azure UG meetup in Singapore on 17th May 2019. Demonstrates usage of Spark for running big data workloads on HDInsight cluster. Spark SQL, Dataset API along with Hive support was demonstrated
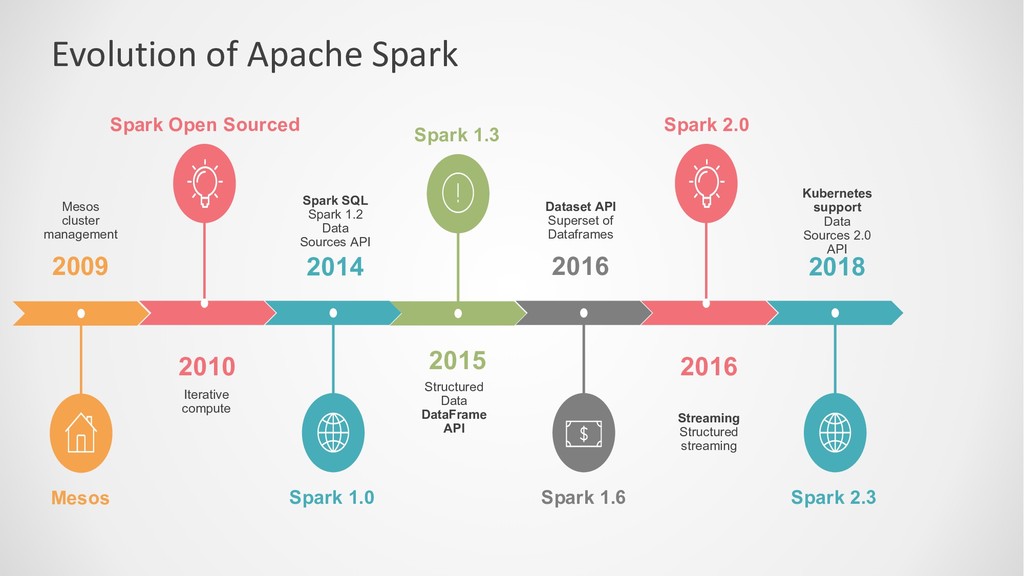
management 2014 Spark SQL Spark 1.2 Data Sources API 2015 Structured Data DataFrame API 2016 Dataset API Superset of Dataframes Mesos Spark Open Sourced Spark 1.0 Spark 1.3 Spark 1.6 2016 Streaming Structured streaming Spark 2.0 2018 Kubernetes support Data Sources 2.0 API Spark 2.3
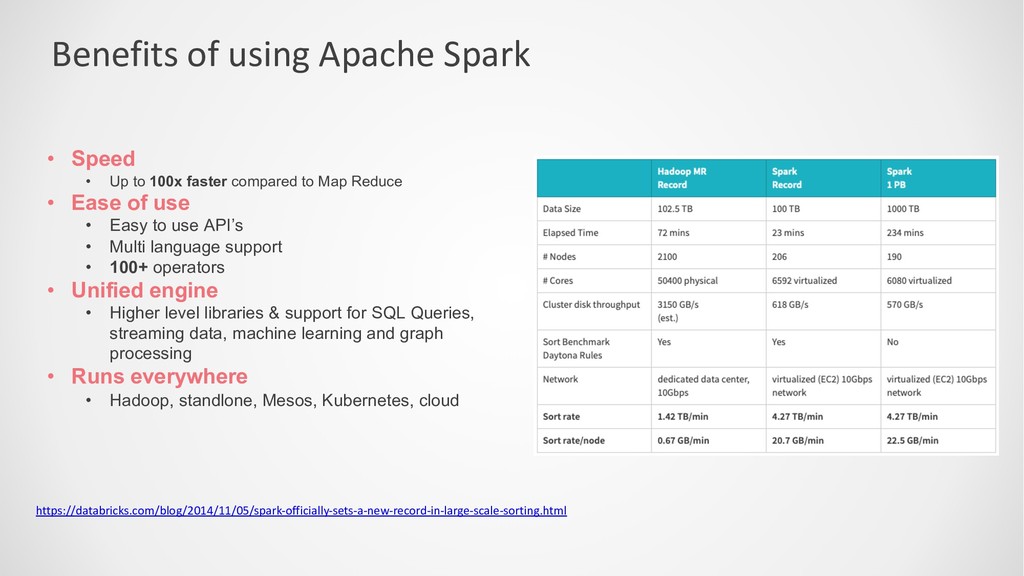
100x faster compared to Map Reduce • Ease of use • Easy to use API’s • Multi language support • 100+ operators • Unified engine • Higher level libraries & support for SQL Queries, streaming data, machine learning and graph processing • Runs everywhere • Hadoop, standlone, Mesos, Kubernetes, cloud https://databricks.com/blog/2014/11/05/spark-officially-sets-a-new-record-in-large-scale-sorting.html
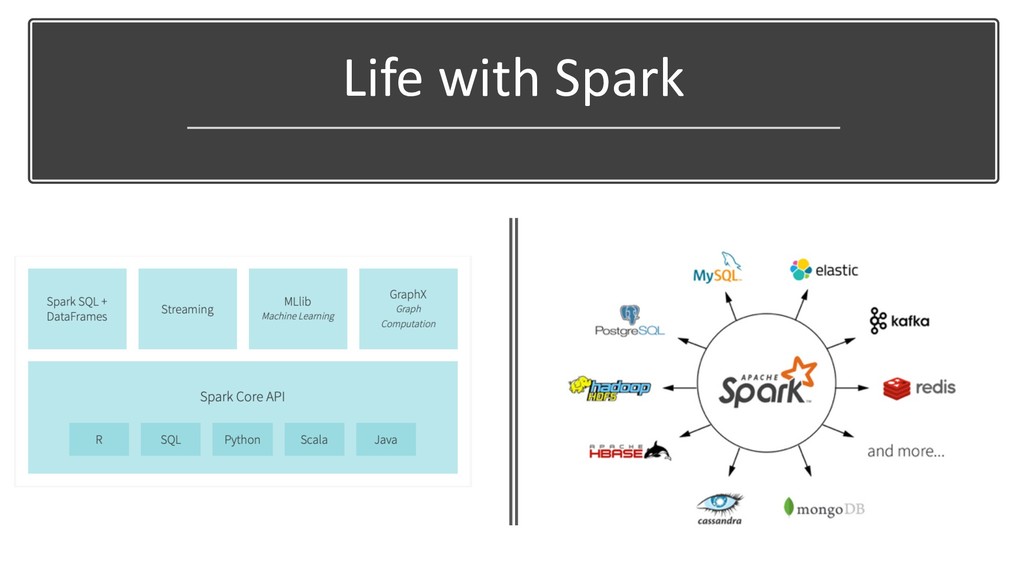
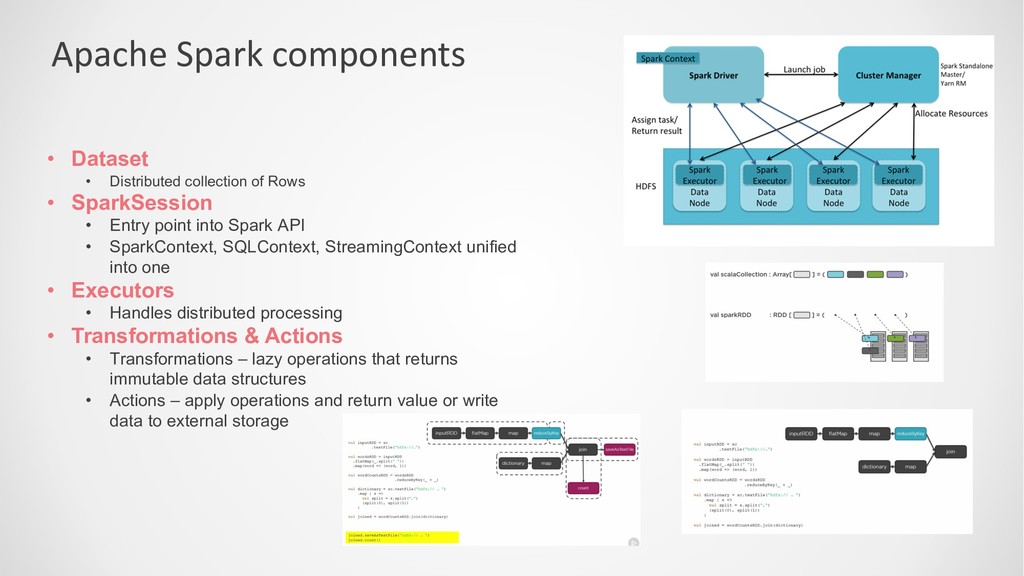
• SparkSession • Entry point into Spark API • SparkContext, SQLContext, StreamingContext unified into one • Executors • Handles distributed processing • Transformations & Actions • Transformations – lazy operations that returns immutable data structures • Actions – apply operations and return value or write data to external storage
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}