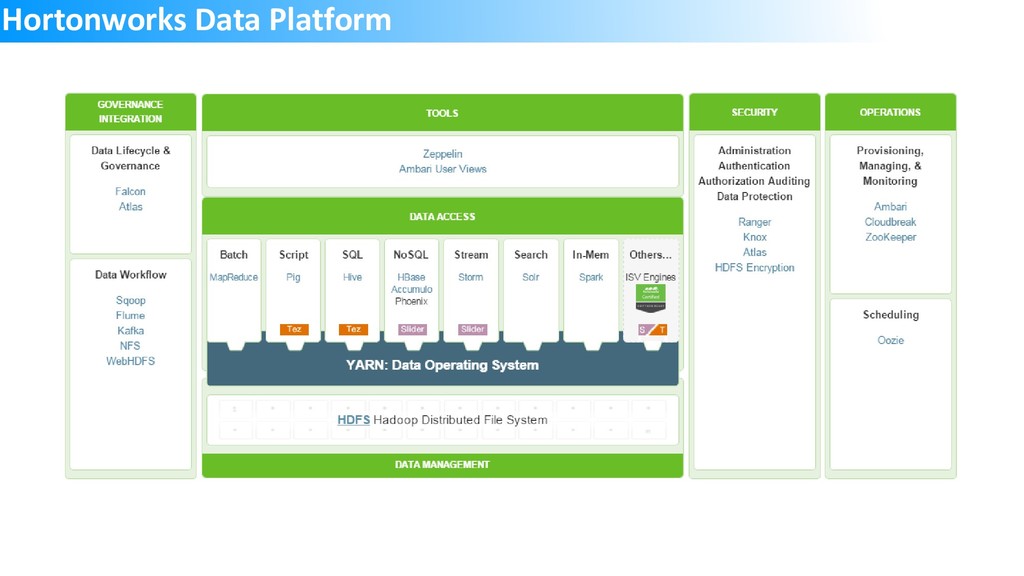
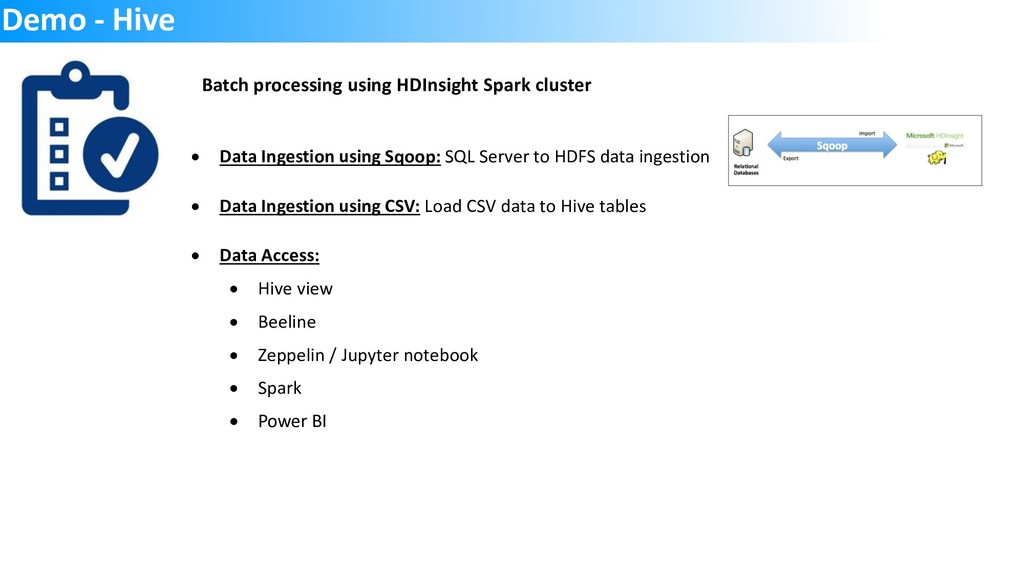
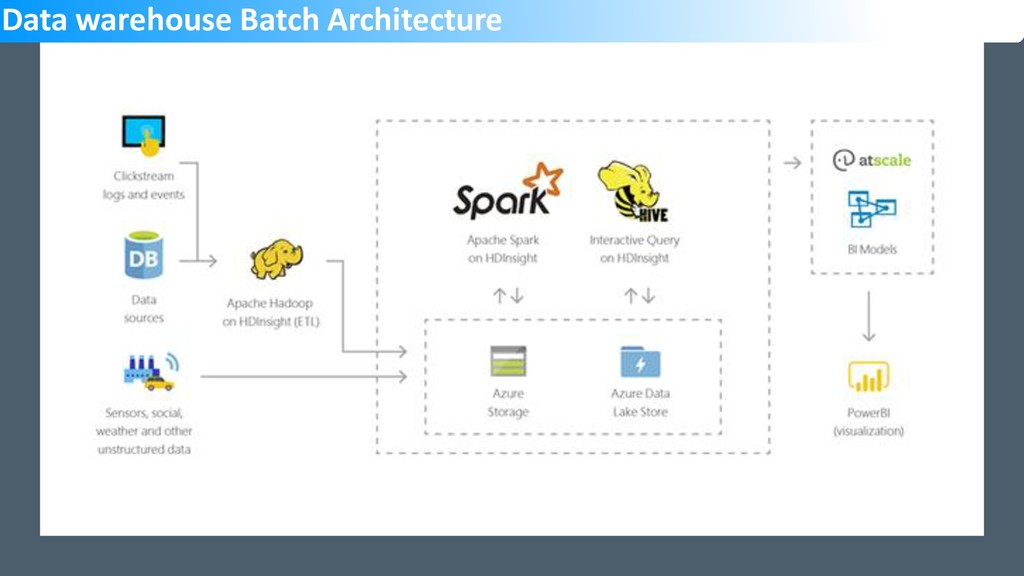
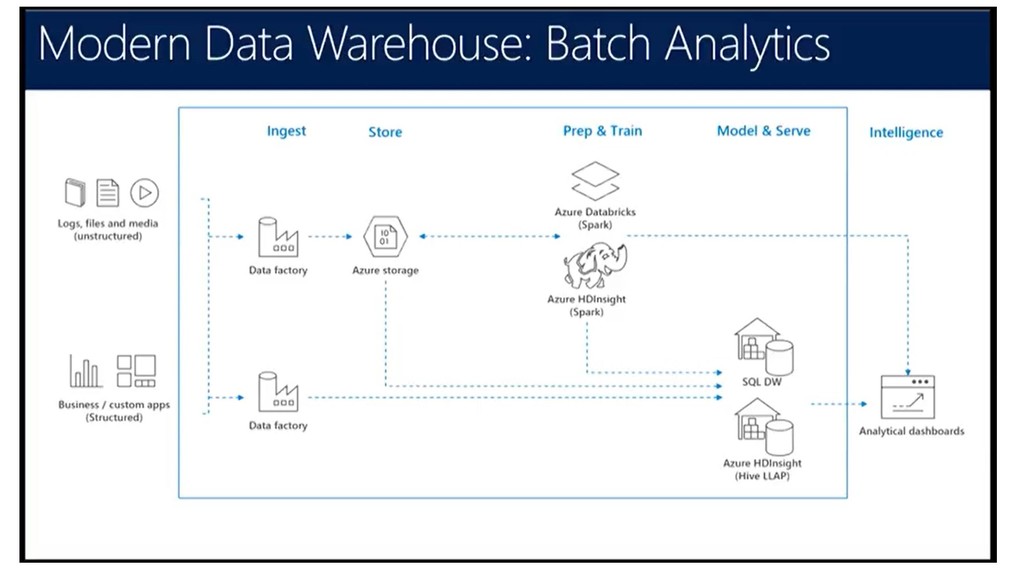
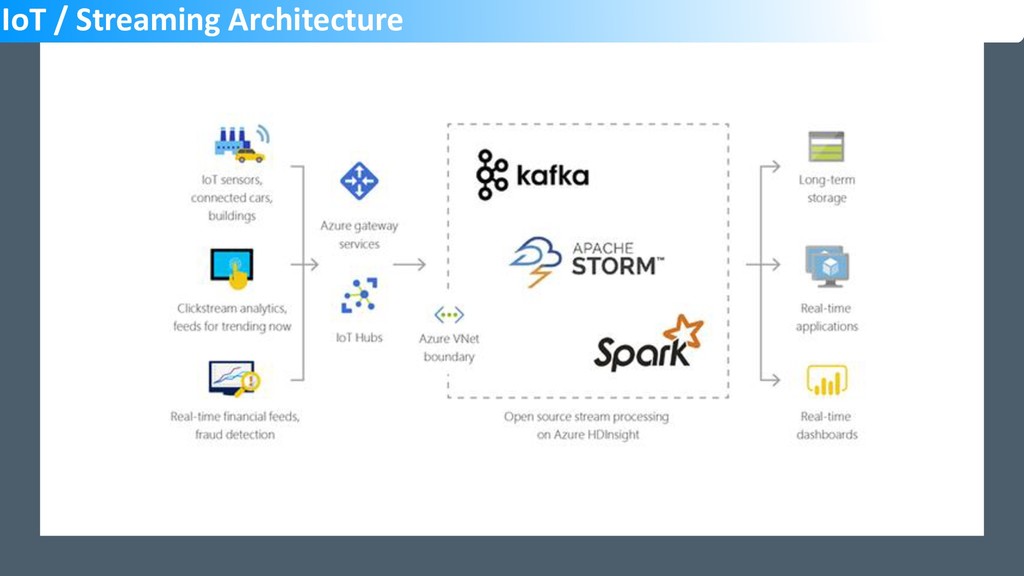
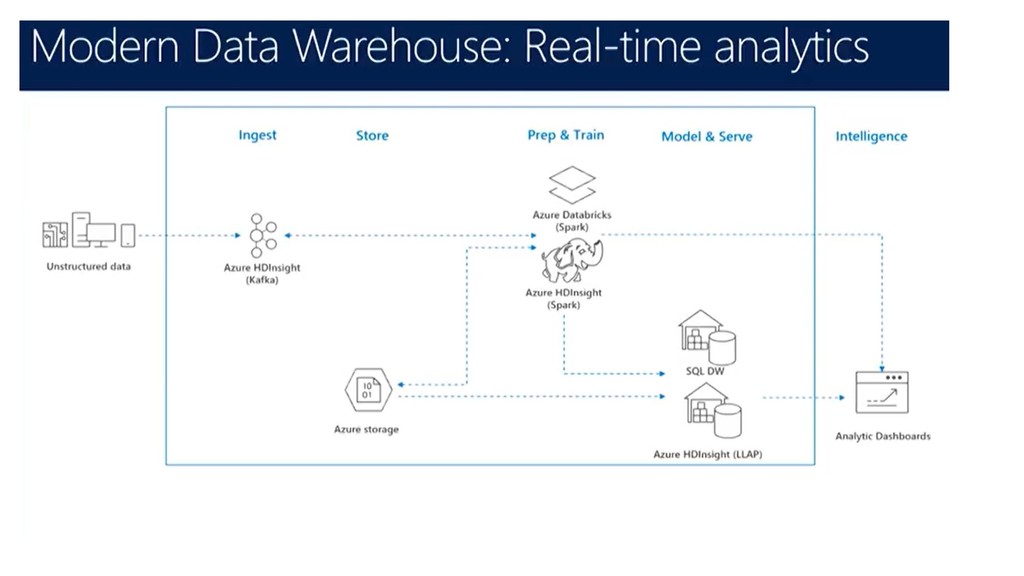
The slide deck from the Singapore DataCamp 2019 event held on 2nd March. The session and the demo were used to showcase HDInsight offering and the capabilities from OSS tools like Sqoop, Hive etc. Spark was used to query data from Hive and also CSV files using Jupyter notebook. Finally, PowerBI was used to build visualization with data sourced from HDInsight cluster using DirectQuery and Spark
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}