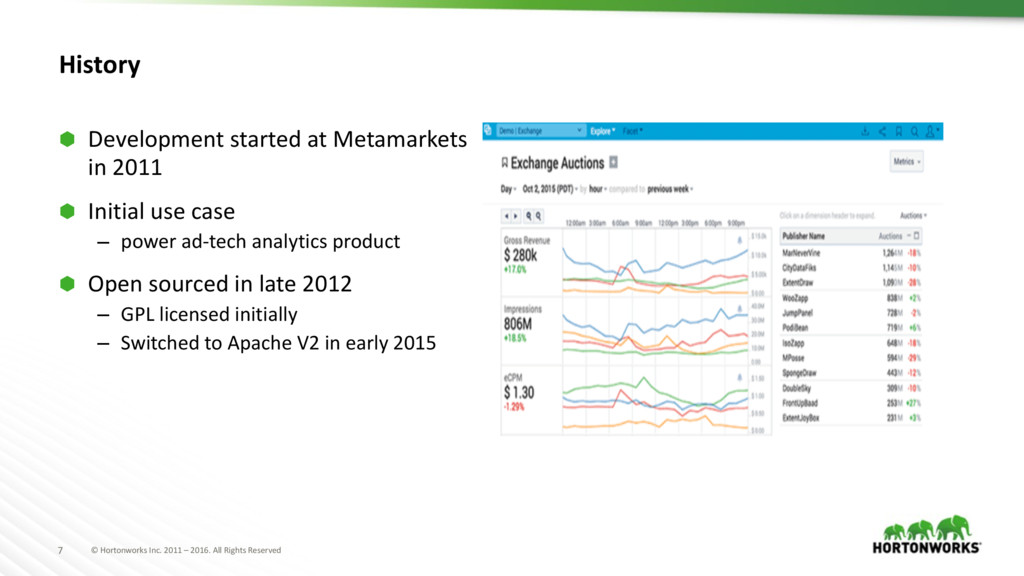
History ⬢ Development started at Metamarkets in 2011 ⬢ Initial use case – power ad-tech analytics product ⬢ Open sourced in late 2012 – GPL licensed initially – Switched to Apache V2 in early 2015
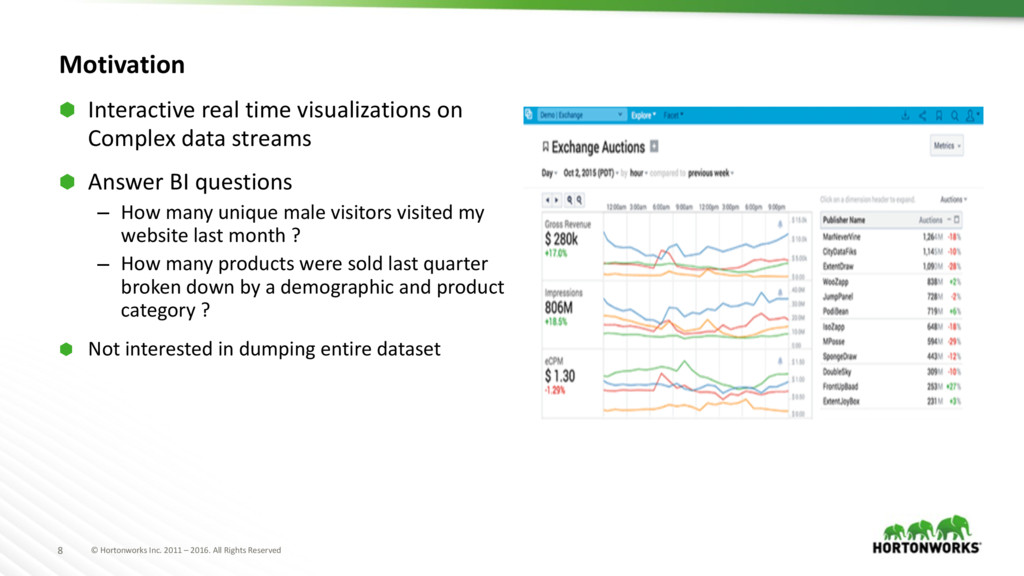
Motivation ⬢ Interactive real time visualizations on Complex data streams ⬢ Answer BI questions – How many unique male visitors visited my website last month ? – How many products were sold last quarter broken down by a demographic and product category ? ⬢ Not interested in dumping entire dataset
Solutions Evaluated ⬢ NoSql – Pre-aggregate all dimensional combinations – Store results in a NoSql store ⬢ Results – Fast queries – Arbitrary queries not possible – Not continuously updated – Pre processing scales exponentially – Example: 500K records – 11 dimensions: 4.5 hours on 15 node hadoop cluster – 14 dimensions: 9 hours on 25 node hadoop cluster
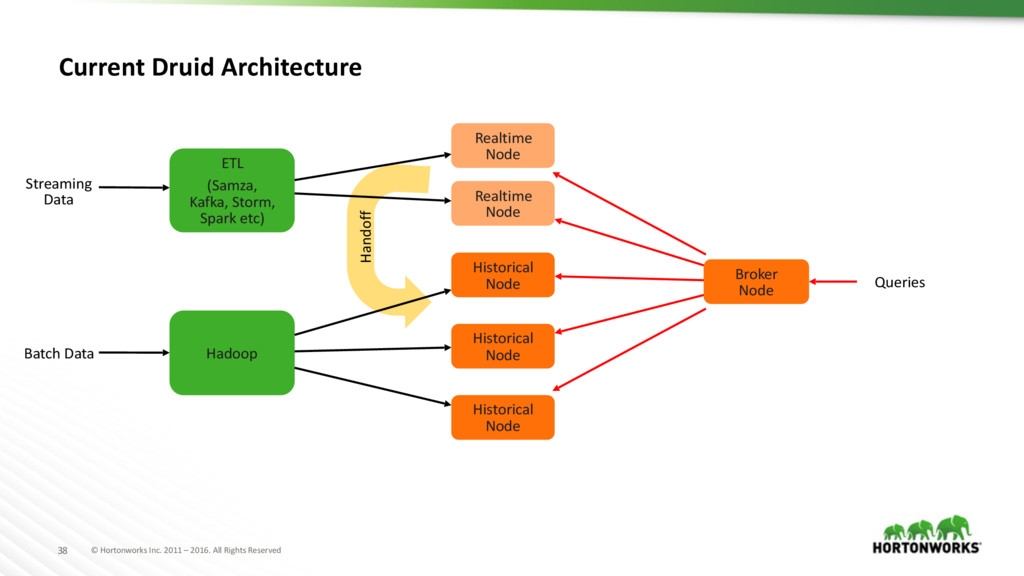
What is Druid ? ⬢ Column-oriented distributed datastore ⬢ Sub-Second query latency ⬢ Arbitrary slicing and dicing of data ⬢ Realtime streaming ingestion ⬢ Automatic Data Summarization ⬢ Approximate algorithms (hyperLogLog, theta) ⬢ Scalable to petabytes of data ⬢ Highly available
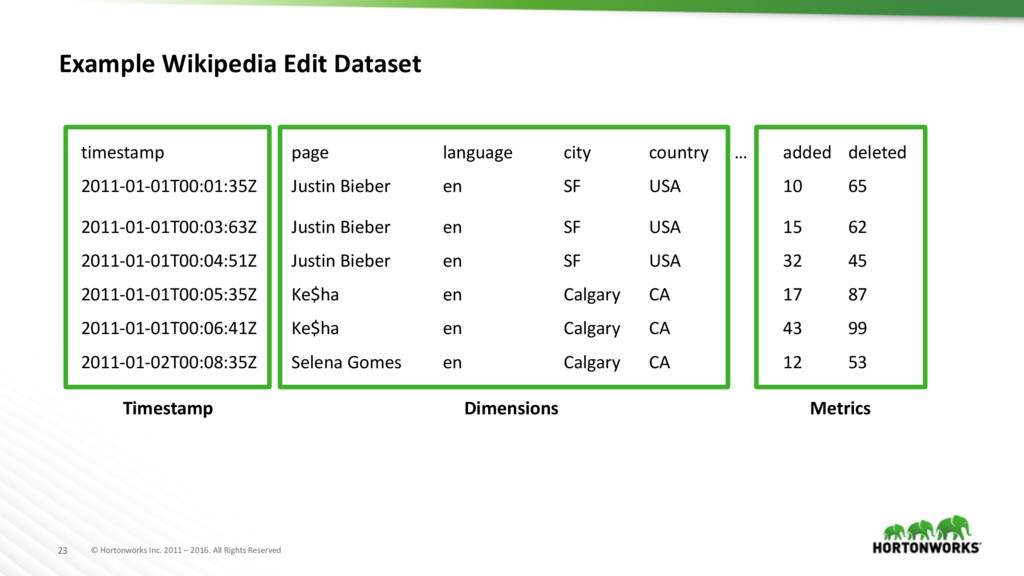
Example Wikipedia Edit Dataset timestamp page language city country … added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T00:05:35Z Ke$ha en Calgary CA 17 87 2011-01-01T00:06:41Z Ke$ha en Calgary CA 43 99 2011-01-02T00:08:35Z Selena Gomes en Calgary CA 12 53 Timestamp Dimensions Metrics
Data Partitioning timestamp page language city country … added deleted 2011-01-01T00:00:00Z Justin Bieber en SF USA 10 65 2011-01-01T01:00:00Z Justin Bieber en SF USA 15 62 2011-01-01T01:00:00Z Ke$ha en Calgary CA 17 87 2011-01-01T02:00:00Z Ke$ha en Calgary CA 43 99 2011-01-01T02:00:00Z Selena Gomes en Calgary CA 12 53 Segment 2011-01-01T00/2011-01-01T01 Segment 2011-01-01T01/2011-01-01T02 Segment 2011-01-01T02/2011-01-01T03 ⬢ multiple shards for same interval ⬢ hash based ⬢ dimension values based
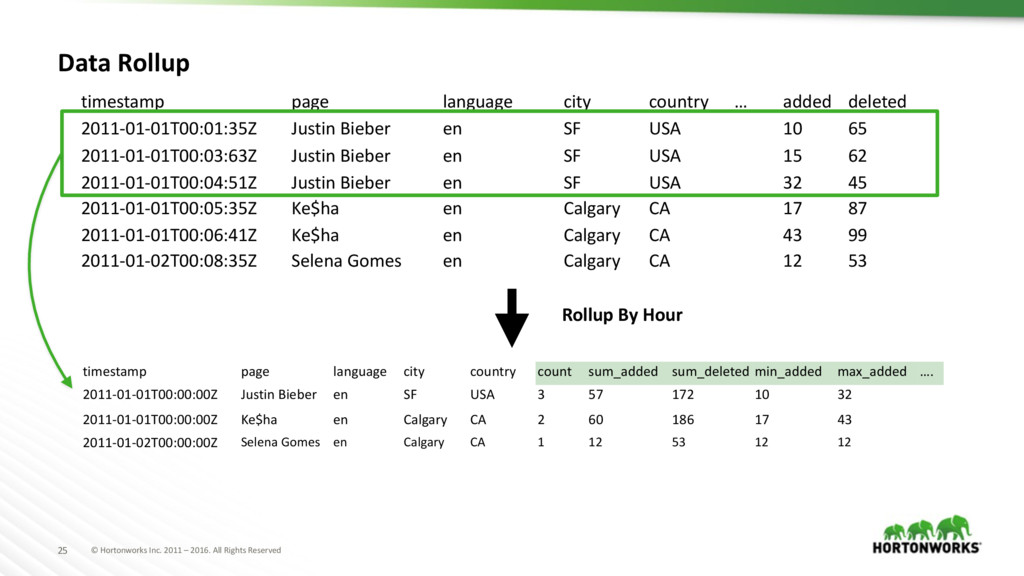
Data Rollup timestamp page language city country … added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T00:05:35Z Ke$ha en Calgary CA 17 87 2011-01-01T00:06:41Z Ke$ha en Calgary CA 43 99 2011-01-02T00:08:35Z Selena Gomes en Calgary CA 12 53 timestamp page language city country count sum_added sum_deleted min_added max_added …. 2011-01-01T00:00:00Z Justin Bieber en SF USA 3 57 172 10 32 2011-01-01T00:00:00Z Ke$ha en Calgary CA 2 60 186 17 43 2011-01-02T00:00:00Z Selena Gomes en Calgary CA 1 12 53 12 12 Rollup By Hour
Dictionary Encoding ⬢ Create and store Ids for each value ⬢ e.g. page column ⬢ Values - Justin Bieber, Ke$ha, Selena Gomes ⬢ Encoding - Justin Bieber : 0, Ke$ha: 1, Selena Gomes: 2 ⬢ Column Data - [0 0 0 1 1 2] ⬢ city column - [0 0 0 1 1 1] timestamp page language city country … added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T00:05:35Z Ke$ha en Calgary CA 17 87 2011-01-01T00:06:41Z Ke$ha en Calgary CA 43 99 2011-01-02T00:08:35Z Selena Gomes en Calgary CA 12 53
Bitmap Indices ⬢ Store Bitmap Indices for each value ⬢ Justin Bieber -> [0, 1, 2] -> [1 1 1 0 0 0] ⬢ Ke$ha -> [3, 4] -> [0 0 0 1 1 0] ⬢ Selena Gomes -> [5] -> [0 0 0 0 0 1] ⬢ Queries filter evaluated by bitmap OR and AND operations ⬢ Justin Bieber or Ke$ha -> [1 1 1 0 0 0] OR [0 0 0 1 1 0] -> [1 1 1 1 1 0] ⬢ language = en and country = CA -> [1 1 1 1 1 1] AND [0 0 0 1 1 1] -> [0 0 0 1 1 1] ⬢ Indexes compressed with Concise or Roaring encoding timestamp page language city country … added deleted 2011-01-01T00:01:35Z Justin Bieber en SF USA 10 65 2011-01-01T00:03:63Z Justin Bieber en SF USA 15 62 2011-01-01T00:04:51Z Justin Bieber en SF USA 32 45 2011-01-01T00:01:35Z Ke$ha en Calgary CA 17 87 2011-01-01T00:01:35Z Ke$ha en Calgary CA 43 99 2011-01-01T00:01:35Z Selena Gomes en Calgary CA 12 53
Community ⬢ User google group - [email protected] ⬢ Dev google group - [email protected] ⬢ Github - druid-io/druid ⬢ IRC - #druid-dev on irc.freenode.net
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}