contractor for Apple Inc Author - Netty in Action Apache Software Foundation Member Netty / Vert.x Core-Developer and all things NIO Java and Scala Twitter: @normanmaurer Github: https://github.com/normanmaurer
concurrent connections != high-scale If you only need to handle a few hundred connections use Blocking IO! Make use of a profiler to find issues, and not best-guess... Always test before and after changes, and not forget to warmup!
Use static instances where ever possible Ask yourself do I really need to create the instance BUT, only cache/pool where it makes sense as long-living objects may have bad impact on GC as well “Rule of thumb: use static if it's immutable and used often. If its mutable only pool / cache if allocation costs are high!”
a n n e l I d l e ( c t x , n e w I d l e S t a t e E v e n t ( I d l e S t a t e . R E A D E R _ I D L E , r e a d e r I d l e C o u n t + + , c u r r e n t T i m e - l a s t R e a d T i m e ) ) ; c h a n n e l I d l e ( c t x , I d l e S t a t e E v e n t . R E A D E R _ I D L E _ E V E N T ) ;
or G1 if you want high- troughput Size different areas depending on your application / access pattern “Stop-the-world GC is your worst enemy if you want to push data hard”
Deallocate from heap buffers is cheap “Free up memory of direct buffers is expensive” “Unfortunately zero-out the byte array of heap buffers is not for free too”
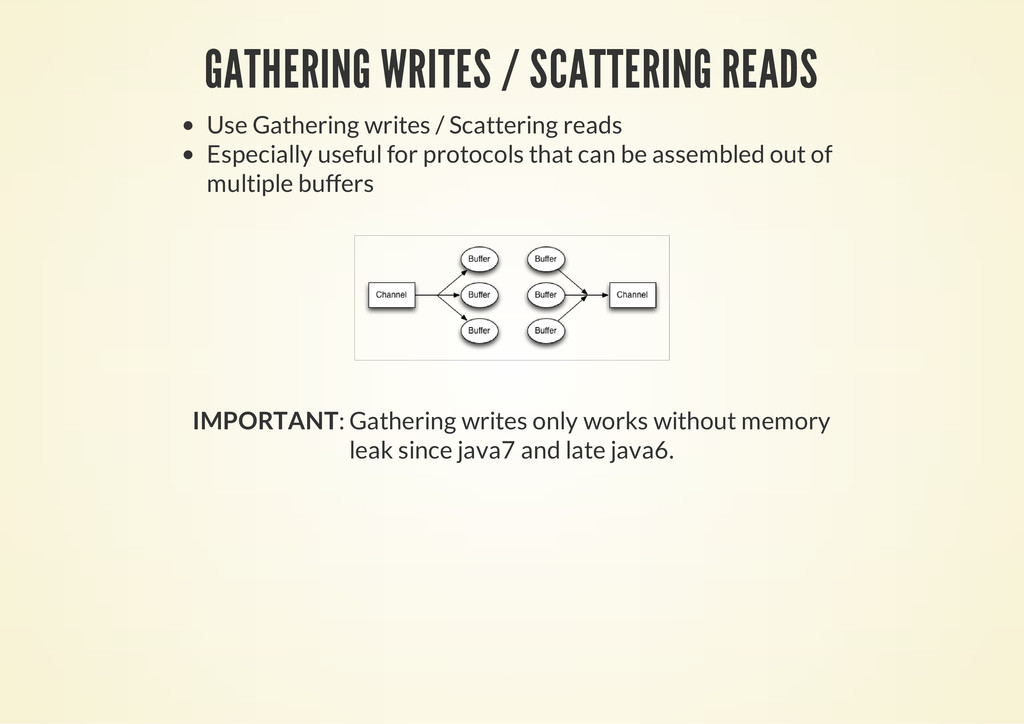
reads Especially useful for protocols that can be assembled out of multiple buffers IMPORTANT: Gathering writes only works without memory leak since java7 and late java6.
with OOM interestedOps(..) update to the rescue! This will push the "burden" to the network stack https://github.com/netty/netty/issues/1024 “But not call interestedOps(...) too often, its expensive!”
Selector by default Only do if you could not write the complete buffer Remove OP_WRITE from interestedOps() after you was able to write “Remember most of the times the Channel is writable!”
o i d s u s p e n d R e a d ( ) { k e y . i n t e r e s t O p s ( k e y . i n t e r e s t O p s ( ) & ~ O P _ R E A D ) ; } p u b l i c v o i d s u s p e n d R e a d ( ) { i n t o p s = k e y . i n t e r e s t O p s ( ) ; i f ( ( o p s & O P _ R E A D ) ! = 0 ) { k e y . i n t e r e s t O p s ( o p s & ~ O P _ R E A D ) ; } }
v o l a t i l e S e l e c t o r s e l e c t o r ; p u b l i c v o i d m e t h o d ( ) . . . . { s e l e c t o r . s e l e c t ( ) ; . . . . } p r i v a t e v o l a t i l e S e l e c t o r s e l e c t o r ; p u b l i c v o i d m e t h o d ( ) . . . . { S e l e c t o r s e l e c t o r = t h i s . s e l e c t o r ; s e l e c t o r . s e l e c t ( ) ; . . . . }
one message before response This minimize send / receive operations Popular protocols which support Pipelining: HTTP, SMTP, IMAP “ If you write your own protocol think about Pipelining! ”
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}