Netty is one of the best known and most widely used (if not the most widely used) asynchronous network application frameworks for the JVM.
This talk will show you how Netty itself works and explain why some design choices were made. Beside this it will include war stories about
the many JVM-related challenges the Netty community has faced during Netty development and explain what action were taken to workaround these.
Reactive Summit 2016:
https://reactivesummit2016.sched.org/event/8B6M/netty-one-framework-to-rule-them-all
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
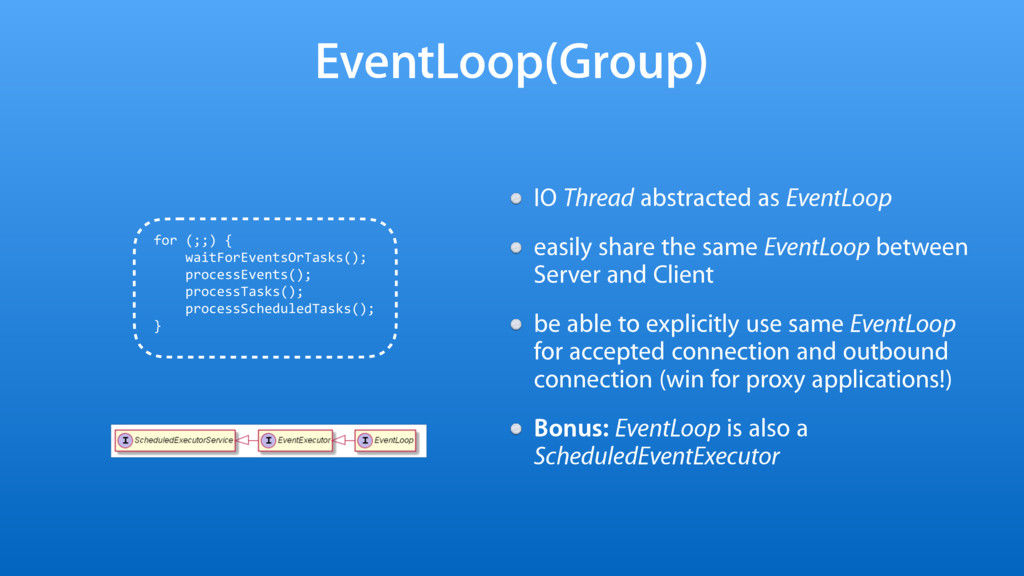{kind=link}
{kind=link}
{kind=link}
{kind=link}
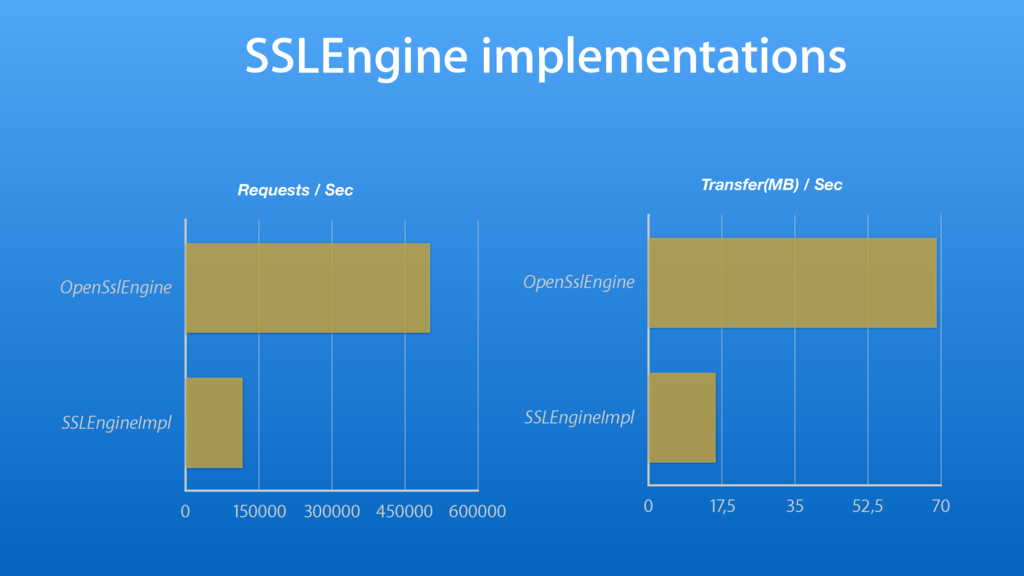{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}