▸ General purpose network framework ▸ Low-level ▸ Tries to hide many optimisations from the end- user so they not need to care about all of it ▸ “easy to use” Optimize all the things
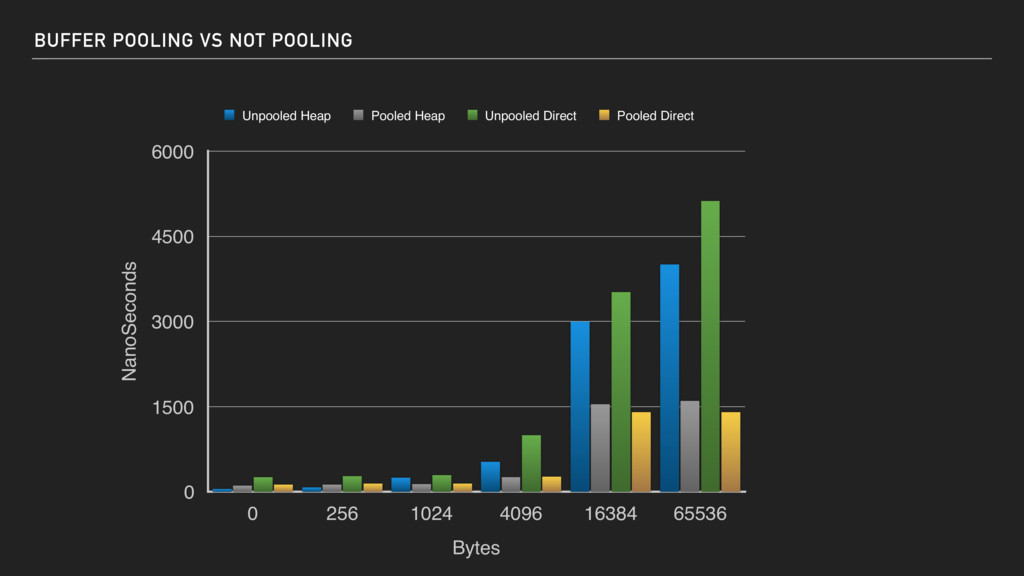
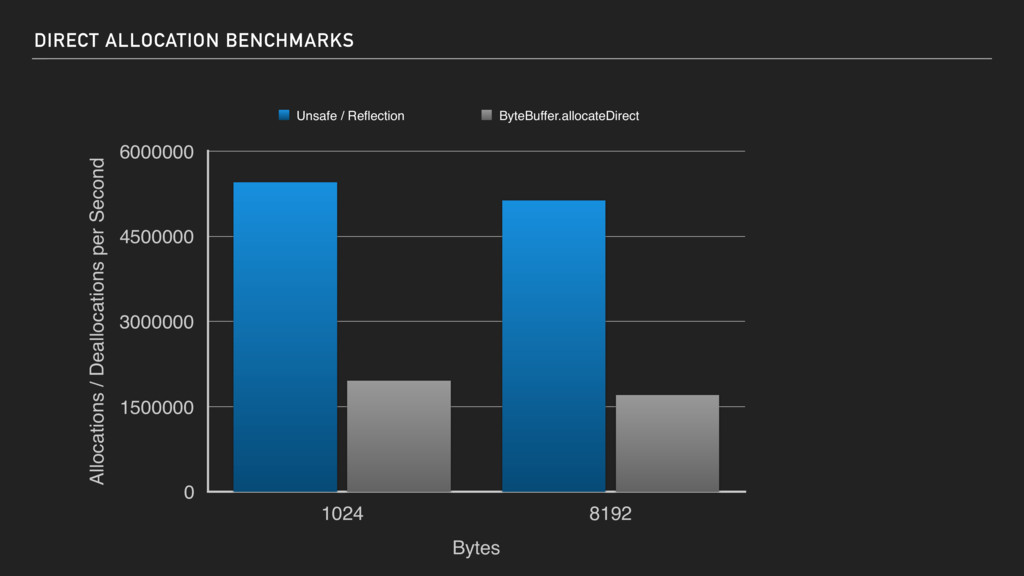
Use JNI to allocate the direct ByteBuffer ▸ Unfortunately too slow as calling JNI is “expensive” ▸ Use Unsafe to allocate direct memory and use reflect to create ByteBuffer from the memory ▸ Works very well but needs to use Unsafe and reflection (which breaks on Java9+) ▸ Need explicit to release direct memory as GC will not take care!
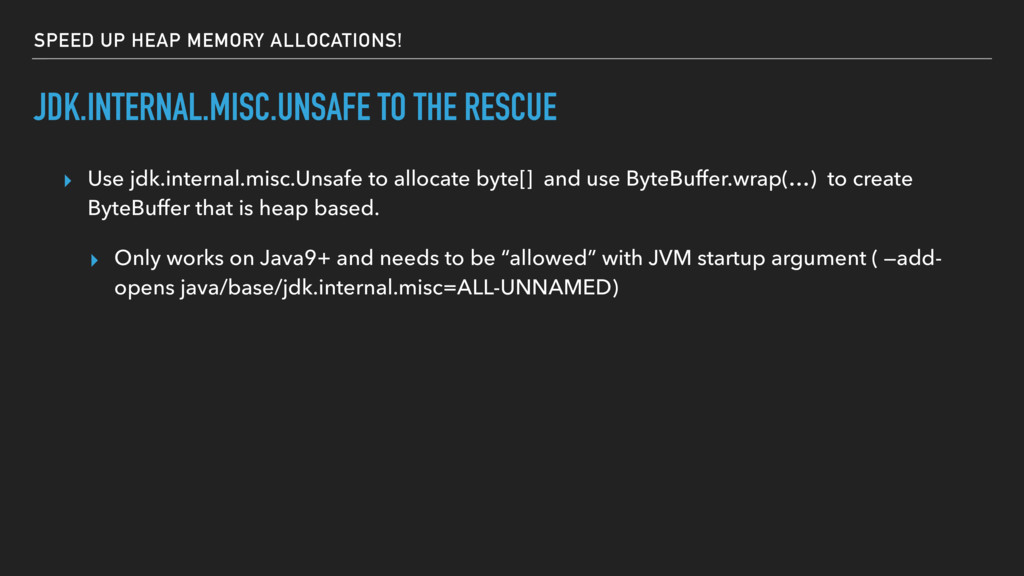
Use jdk.internal.misc.Unsafe to allocate byte[] and use ByteBuffer.wrap(…) to create ByteBuffer that is heap based. ▸ Only works on Java9+ and needs to be “allowed” with JVM startup argument ( —add- opens java/base/jdk.internal.misc=ALL-UNNAMED)
general but sometimes we can do better ▸ Netty has tight control over its Threads that are used by the EventLoop ▸ Use own Thread subclass that allows us to store “local” data within an array for faster access ▸ No good way to ensure some cleanup is done when a ThreadLocal for a thread is destroyed ▸ JDK ThreadLocal uses HashMap internally BENCHMARK MODE CNT SCORE ERROR UNITS FASTTHREADLOCAL THRPT 20 115409.952 ± 3511.358 OPS/S JDKTHREADLOCAL. THRPT 20 70654.729 ± 325.362 OPS/S
DefaultThreadFactory provided by Netty or use FastThreadLocalThread ▸ Replace ThreadLocal with FastThreadLocal ▸ Win! ▸ Gotchas ? There are always some :( ▸ Using FastThreadLocal from a “NON” FastThreadLocalThread gives a ca 20% perf drop Doh! Why are there always gotchas!?!?
with Java is slow :( ▸ Its becoming better and better tho ▸ Most people will tell you that you should never terminate SSL in Java :/ Why we can’t have nice things ?!?
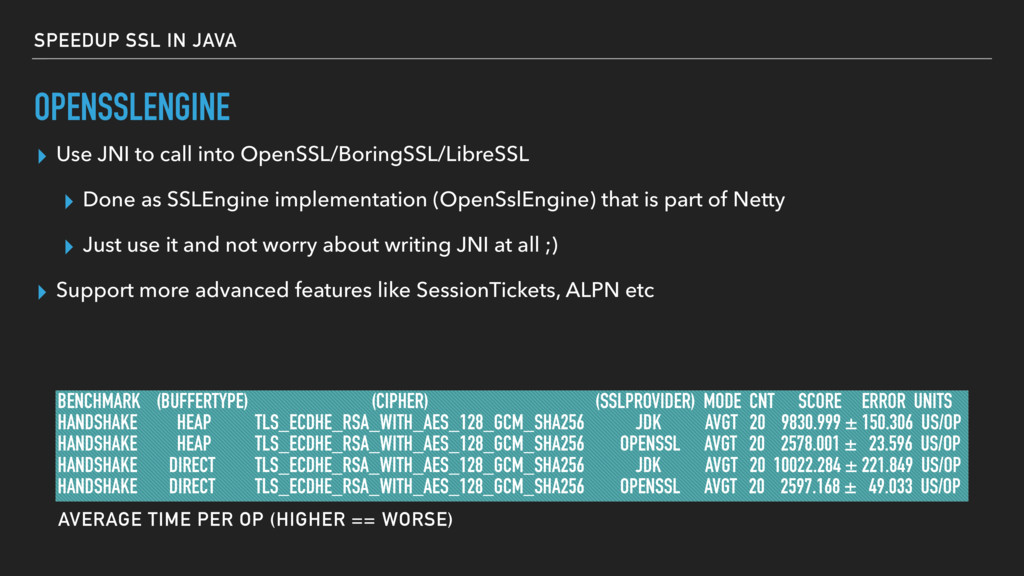
OpenSSL/BoringSSL/LibreSSL ▸ Done as SSLEngine implementation (OpenSslEngine) that is part of Netty ▸ Just use it and not worry about writing JNI at all ;) ▸ Support more advanced features like SessionTickets, ALPN etc BENCHMARK (BUFFERTYPE) (CIPHER) (SSLPROVIDER) MODE CNT SCORE ERROR UNITS HANDSHAKE HEAP TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 JDK AVGT 20 9830.999 ± 150.306 US/OP HANDSHAKE HEAP TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 OPENSSL AVGT 20 2578.001 ± 23.596 US/OP HANDSHAKE DIRECT TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 JDK AVGT 20 10022.284 ± 221.849 US/OP HANDSHAKE DIRECT TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256 OPENSSL AVGT 20 2597.168 ± 49.033 US/OP OPENSSLENGINE AVERAGE TIME PER OP (HIGHER == WORSE)
even worse is collecting the object ▸ The worst == finalize() ▸ Possible solutions: ▸ ThreadLocal (FastThreadLocal) ▸ Object-Pooling (Recycler) ▸ Just don’t allocate ?!?
Thread-safe ▸ Optimized for offer and poll from within the same Thread ▸ Because its the most likely thing to happen within Netty ▸ Used in multiple places in Netty: ▸ ByteBuf instances ▸ Tasks that are scheduled from outside the EventLoop
▸ Object header overhead ▸ Everything (beside primitive types) will be stored as reference ▸ Possible workarounds: ▸ Extend objects when possible (for internal classes) ▸ Use alternatives that operate on primitives
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![BYTE[] ALLOCATION BENCHMARK Nanoseconds per Allocation 0 3000 6000 9000](https://files.speakerdeck.com/presentations/0733c4c46d424c49820e7bd7dd01da06/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}