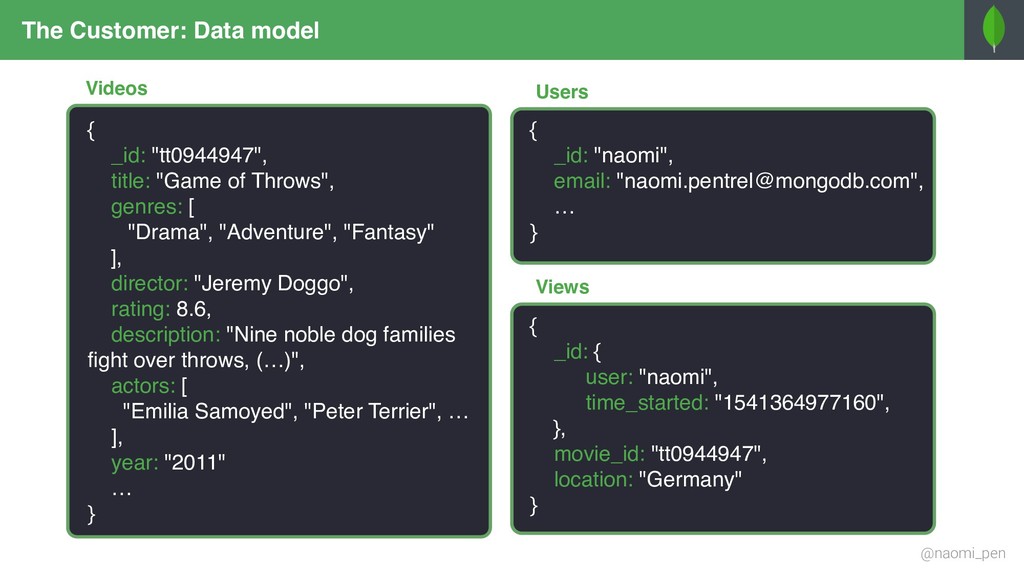
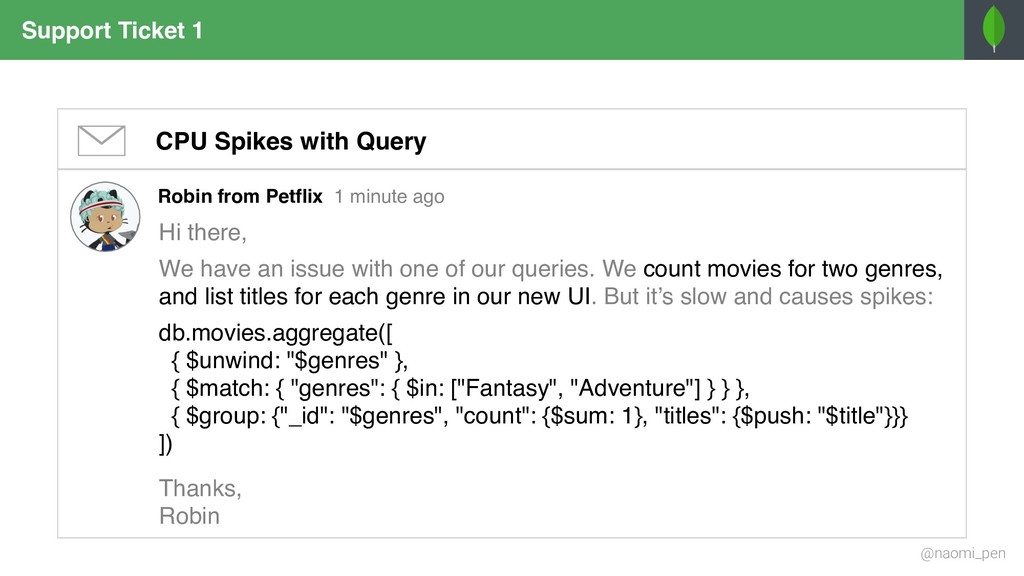
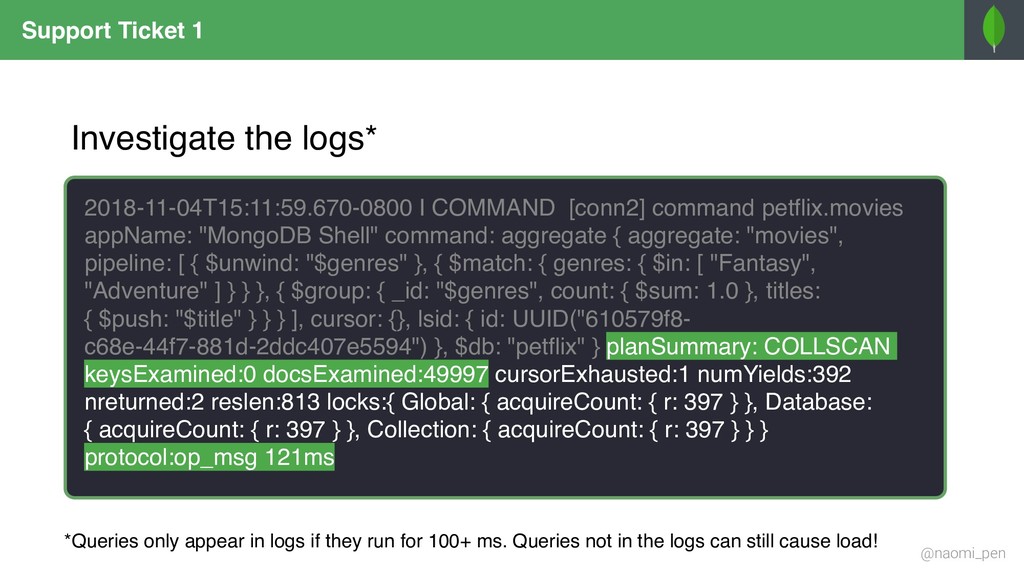
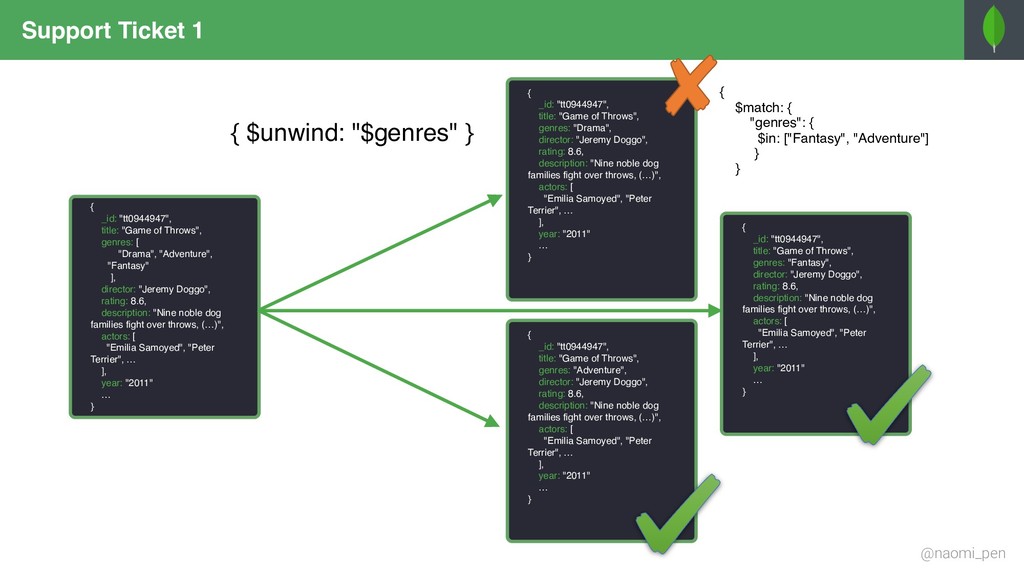
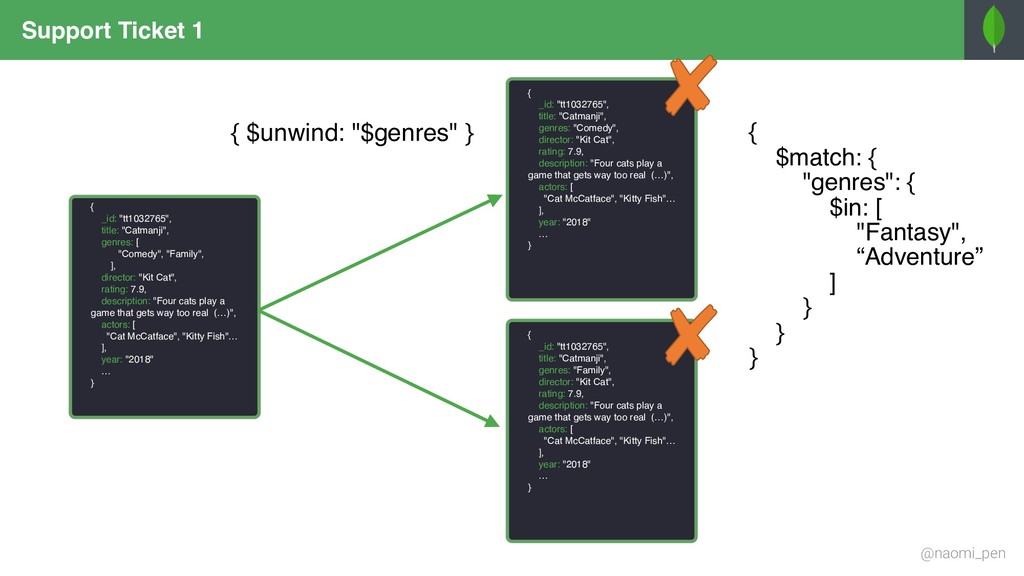
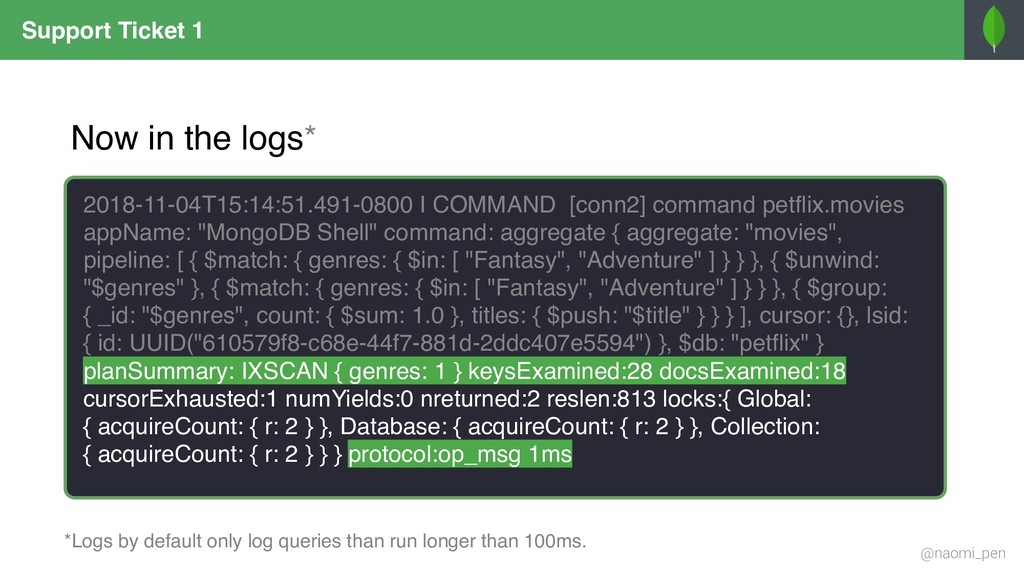
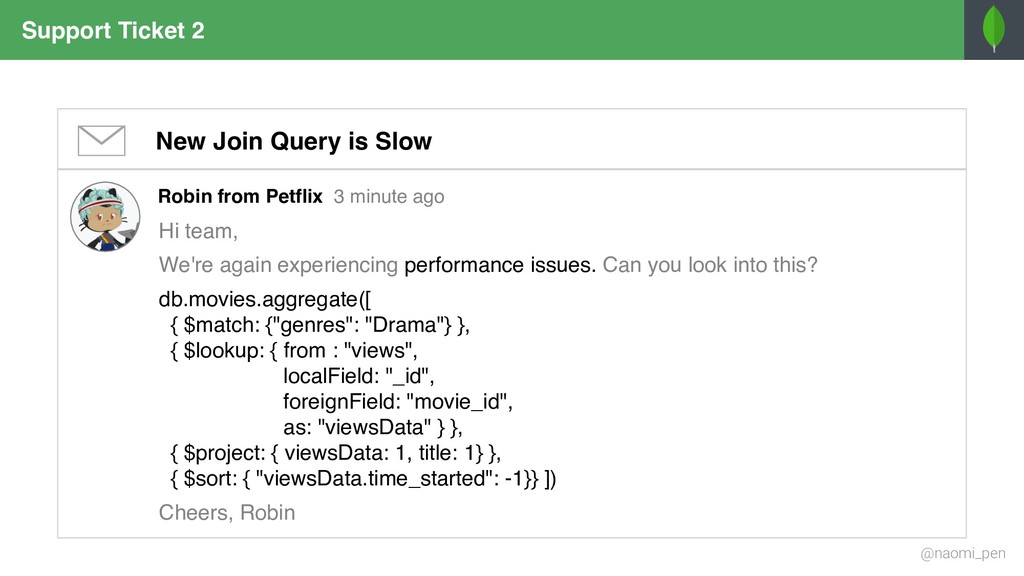
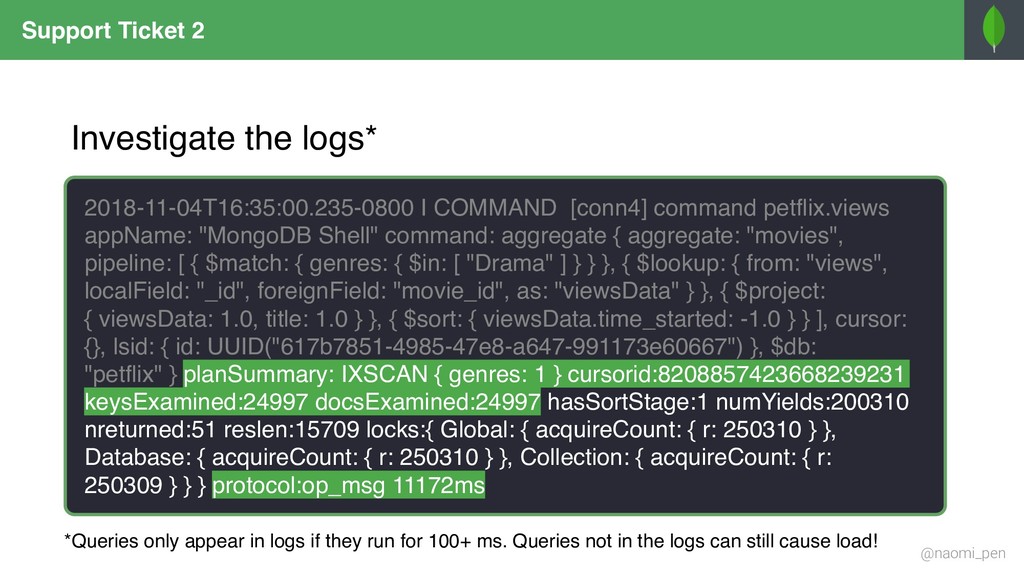
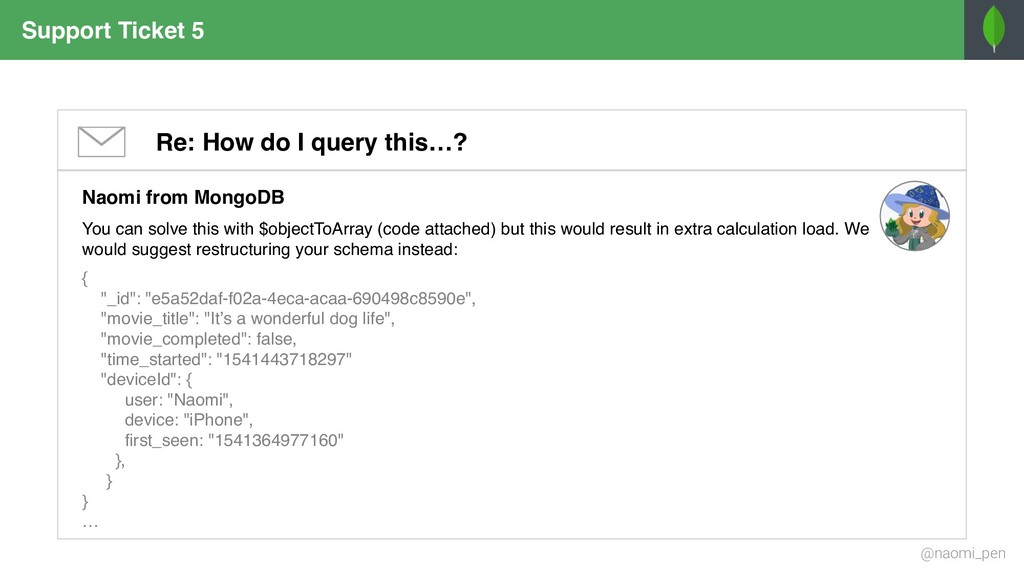
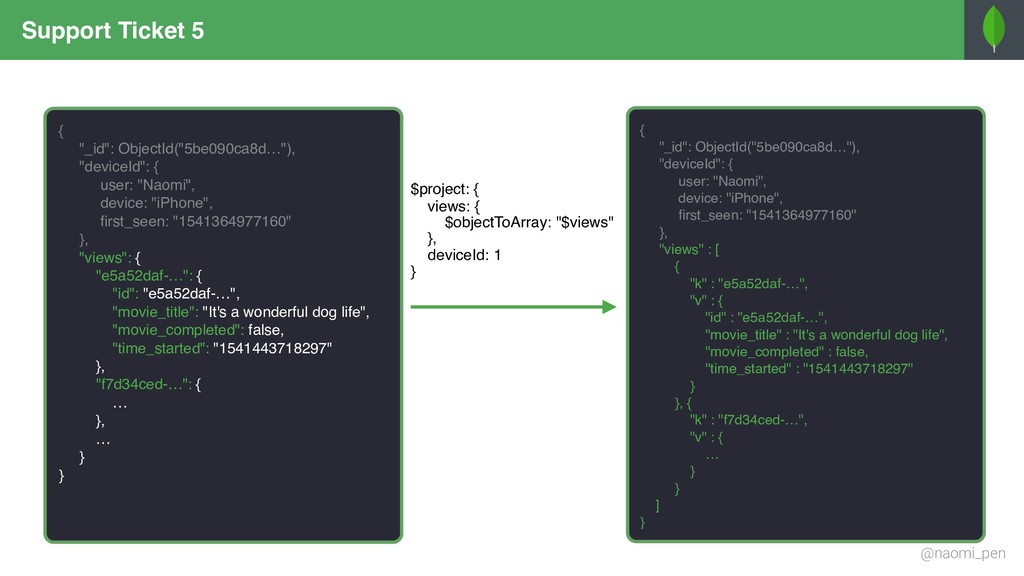
"tt0944947", title: "Game of Throws", genres: [ "Drama", "Adventure", "Fantasy" ], director: "Jeremy Doggo", rating: 8.6, description: "Nine noble dog families fight over throws, (…)", actors: [ "Emilia Samoyed", "Peter Terrier", … ], year: "2011" … } { _id: "tt0944947", title: "Game of Throws", genres: "Drama", director: "Jeremy Doggo", rating: 8.6, description: "Nine noble dog families fight over throws, (…)", actors: [ "Emilia Samoyed", "Peter Terrier", … ], year: "2011" … } { _id: "tt0944947", title: "Game of Throws", genres: "Adventure", director: "Jeremy Doggo", rating: 8.6, description: "Nine noble dog families fight over throws, (…)", actors: [ "Emilia Samoyed", "Peter Terrier", … ], year: "2011" … } { _id: "tt0944947", title: "Game of Throws", genres: "Fantasy", director: "Jeremy Doggo", rating: 8.6, description: "Nine noble dog families fight over throws, (…)", actors: [ "Emilia Samoyed", "Peter Terrier", … ], year: "2011" … } { $match: { "genres": { $in: ["Fantasy", "Adventure"] } }
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}