論文紹介 DISN: Deep Implicit Surface Network for High quality Single-view 3D Reconstruction / DISN: Deep Implicit Surface Network for High quality Single-view 3D Reconstruction
Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction[1] • 1枚の画像からニューラルネットワークで3次元形状を構築 • 2018, 19年頃に似たコンセプトの論文が発表 • Occupancy Networks[2] [1] Weiyue Wang, et al., DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction, NeurIPS, 2019 [2]Mescheder, et al., Occupancy Networks: Learning 3D Reconstruction in Function Space, CVPR, 2019
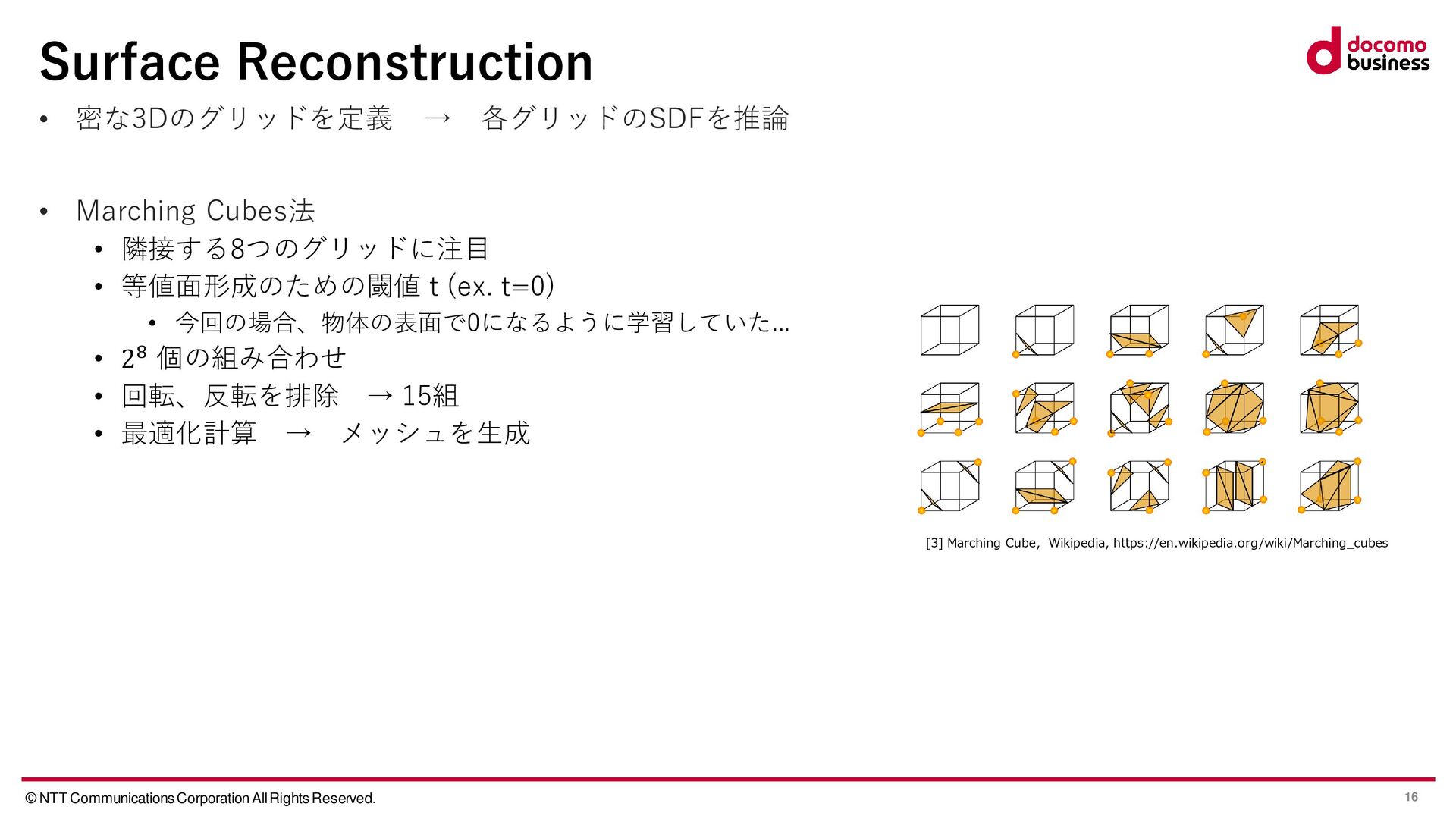
[1] Weiyue Wang, et al., DISN: Deep Implicit Surface Network for High-quality Single-view 3D Reconstruction, NeurIPS, 2019 • [2] Mescheder, et al., Occupancy Networks: Learning 3D Reconstruction in Function Space, CVPR, 2019 • [3] Marching Cube, Wikipedia, https://en.wikipedia.org/wiki/Marching_cubes
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© NTT Communications Corporation All Rights Reserved. 19 実験結果 [1]](https://files.speakerdeck.com/presentations/b9c946231af64ec9beb86ff4c4c5e47c/slide_17.jpg){kind=link}
![© NTT Communications Corporation All Rights Reserved. 20 定性評価 [1]](https://files.speakerdeck.com/presentations/b9c946231af64ec9beb86ff4c4c5e47c/slide_18.jpg){kind=link}
{kind=link}