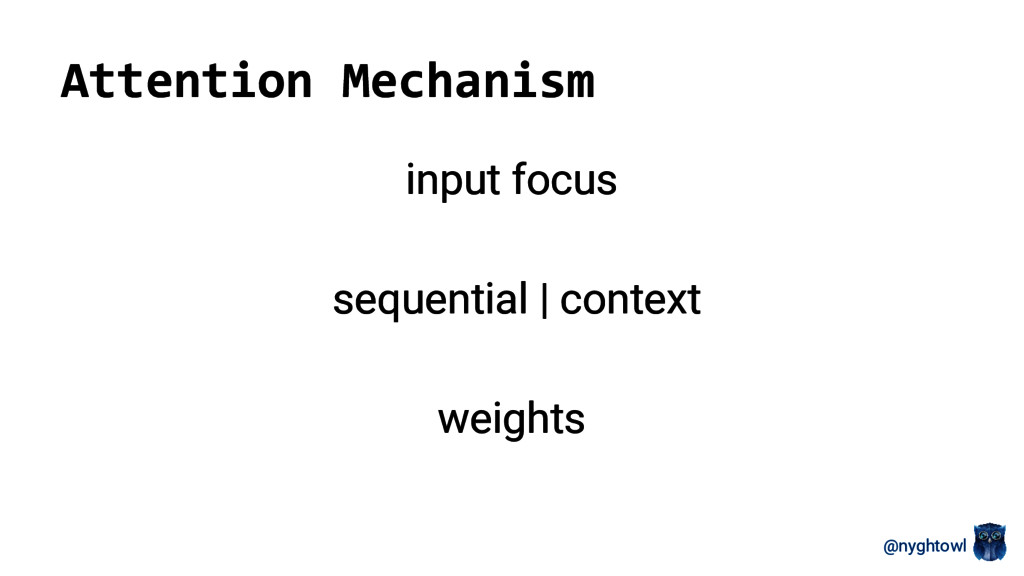
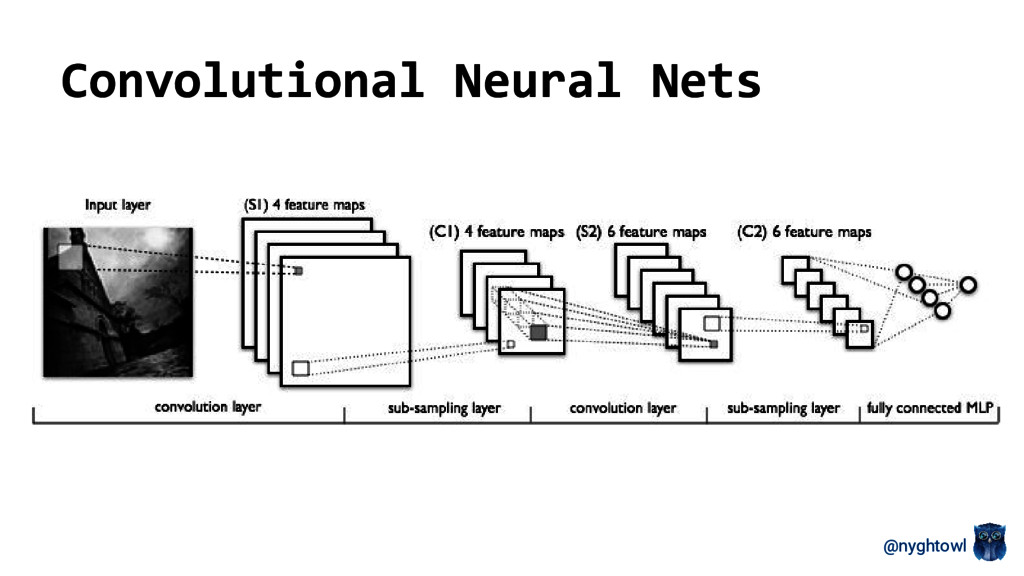
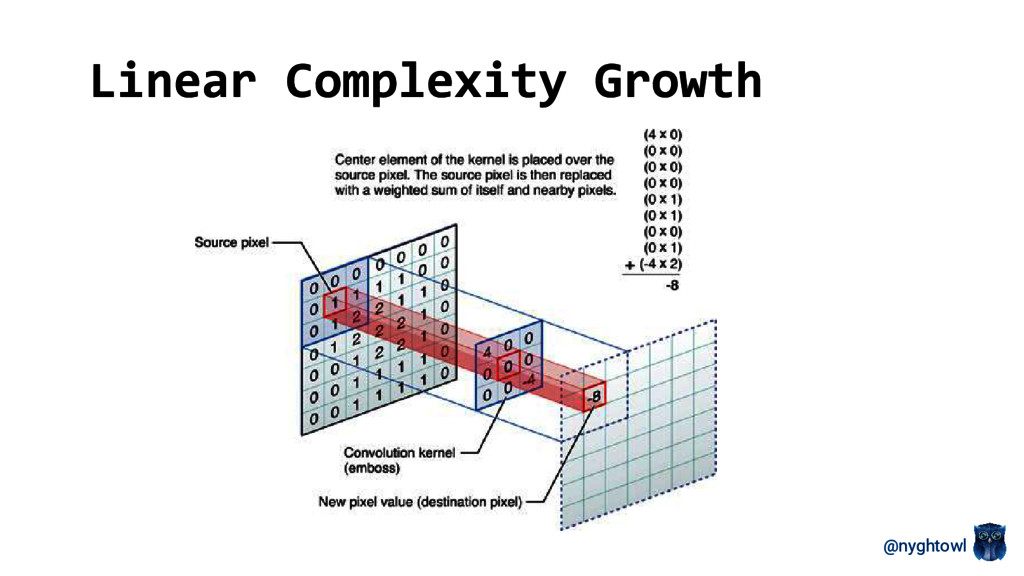
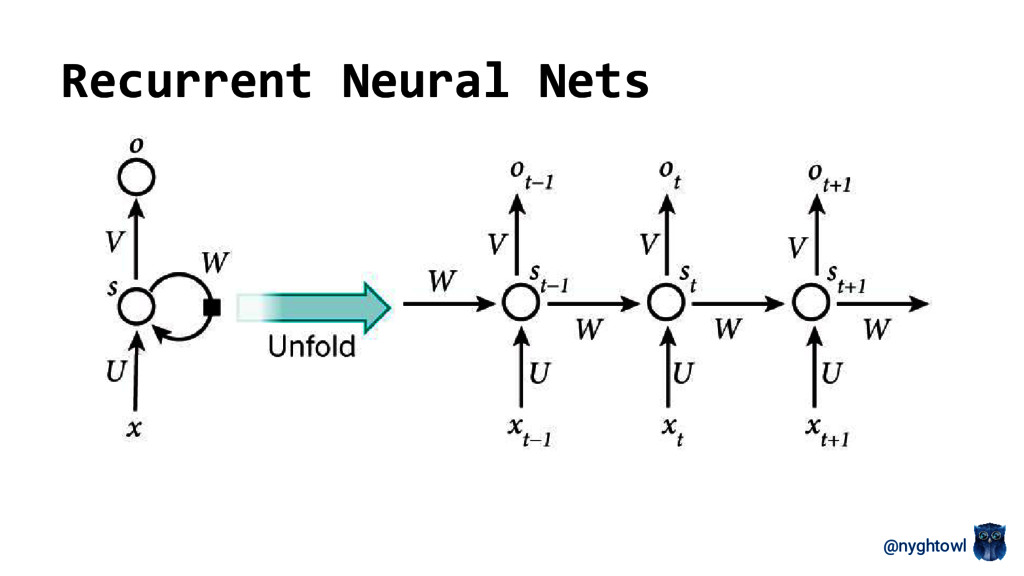
Neural networks have regained popularity over the last decade because they are demonstrating real world value in different applications (e.g. targeted advertising, recommender engines, Siri, self driving cars, facial recognition). Several model types are currently explored in the field with recurrent neural networks (RNN) and convolution neural networks (CNN) taking the top focus. The attention model, a recently developed RNN variant, has started to play a larger role in both natural language processing and image analysis research.
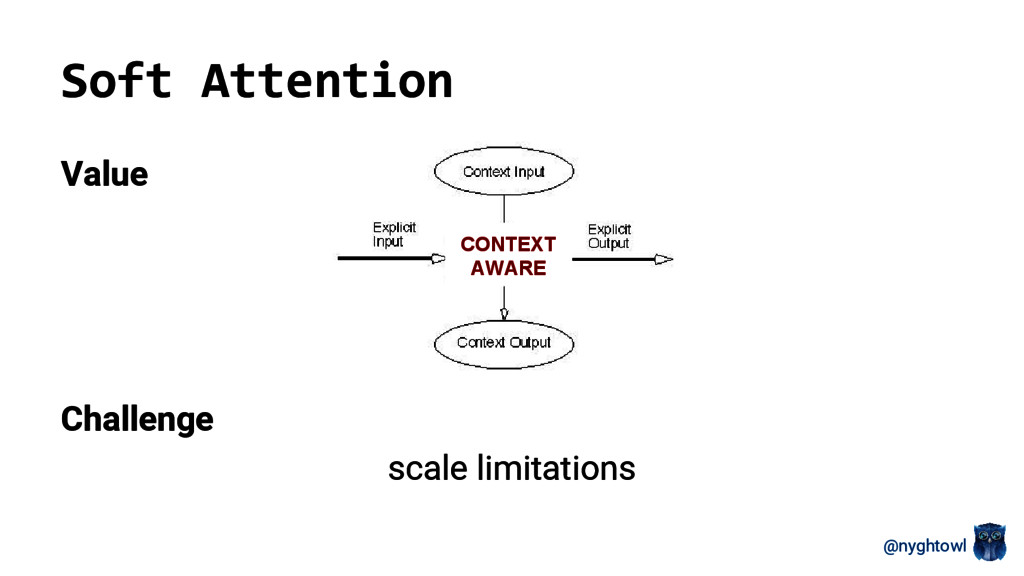
This talk will cover the fundamentals of the attention model structure and how its applied to visual and speech analysis. I will provide an overview of the model functionality and math including a high-level differentiation between soft and hard types. The goal is to give you enough of an understanding of what the model is, how it works and where to apply it.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}