Cells: Past, Present and Future - A co-evolution of algorithms and data in biology
Presentation on recent history of single-cell analysis and the co-evolution of algorithms and technological ability and scale. Presented at the Women in Machine Learning and Data Science Meetup in San Francisco, CA.
Chan Zuckerberg Biohub Women in Machine Learning and Data Science August 29th, 2017 twitter, github: @olgabot www: olgabotvinnik.com email: [email protected] These slides: bit.ly/olga-wimlds-2017
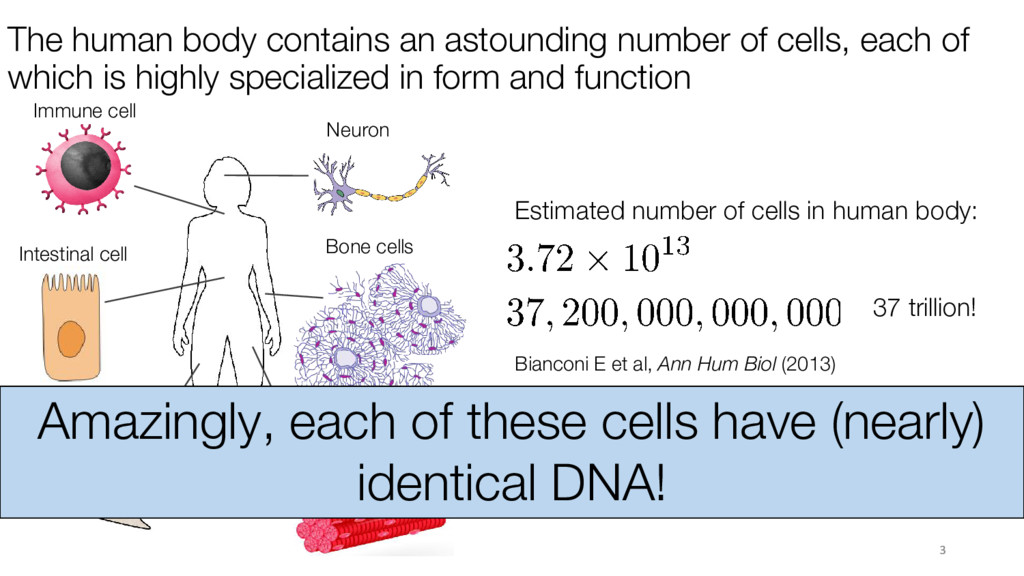
of which is highly specialized in form and function Bianconi E et al, Ann Hum Biol (2013) Estimated number of cells in human body: 37 trillion! Neuron Immune cell Skin cells Muscle cell Bone cells Amazingly, each of these cells have (nearly) identical DNA! Intestinal cell
cellular state DNA RNA Protein “Genome” “Transcriptome” “Proteome” RNA transcript Measuring “all”: DNA RNA Protein Difficulty of measurement Proximity to current cell state
cell populations Principal Component Analysis (PCA) - Linear dimensionality reduction algorithm (“smusher”) - Assumptions aren’t appropriate for single-cell data because: - <10% of molecules are captured - Data is mostly zeros (very sparse) - Data doesn’t follow a Gaussian (Normal/“Bell curve”) distribution 2013 n=18 cells 2014 2015 2016 2017 2018
cells 2014 n=4000 cells 2015 2016 2017 2018 Circular projection - Nonlinear dimensionality reduction algorithm (“smusher”) - Forces the data into a circular configuration, which may not necessarily be consistent with the biology
identify ~30 retinal cell types t-Distributed Stochastic Neighbor Embedding (tSNE) - Nonlinear “smusher” - Stochastic = every plot is randomly initialized and differs from run to run - Used as input to a density-based clustering algorithm, but is problematic as the location and exact composition of each blob changes between iterations 2013 n=18 cells 2014 n=4000 cells 2015 n=40,000 cells 2016 2017 2018 Macosko et al, Cell (2015) 20
cells 2014 n=4000 cells 2015 n=40,000 cells 2016 n=250k cells 2017 2018 ICA = Independent Component Analysis Many cells enabled use of (1) Compressed sensing to impute missing data, and (2) ICA to find coordinately regulated genes Robust PCA is a compressed sensing algorithm which decomposes a matrix into a sum of low rank and sparse matrices
2010 SB Mathematics SB Biological Engineering UC Santa Cruz 2012 MS Biomolecular Engineering and Bioinformatics UC San Diego 2017 PhD Bioinformatics and Systems Biology Today: Bioinformatics Scientist, Data Science Platform Chan Zuckerberg Biohub
Type Identifier ? Mystery Cell Cell Type “Neuron” High Low Gene expression Transcriptional profile RNA-Seq Don’t have enough labeled data to create a robust classifier
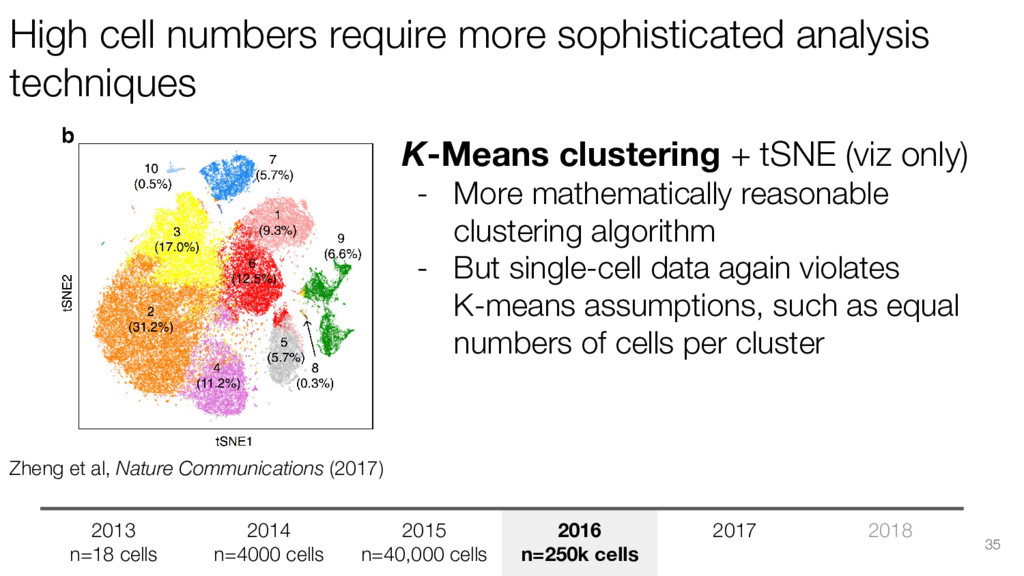
cells 2014 n=4000 cells 2015 n=40,000 cells 2016 n=250k cells 2017 2018 Zheng et al, Nature Communications (2017) K-Means clustering + tSNE (viz only) - More mathematically reasonable clustering algorithm - But single-cell data again violates K-means assumptions, such as equal numbers of cells per cluster 35
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}