While every cell in your body has (nearly) the same DNA, different cells do radically different things! Neurons in your brain and muscle cells in your heart use different genes to perform their specialized tasks. New technologies have emerged to measure which genes are expressed in individual cells, and the throughput of these technologies has created data analysis and storage problems that make the Human Genome Project look like, so 90s. Unlike then, biologists have leveraged the open-source data science community and quickly adopted common machine learning techniques. Many open questions remain: How can we recover the sparse signal generated by the low detection limits of the technology? What clustering algorithm should we use to determine how many cell types there are? What classifier should we use to predict cell identity? What dimensionality reduction algorithm should we use to get coherent groups of genes acting together in concert? The field is undergoing a period of rapid expansion and iteration.In this talk I will review the strides already made by the biological community in defining data and analysis standards, the challenges that remain, and the implications of the new wave of “big data” biology in human health.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
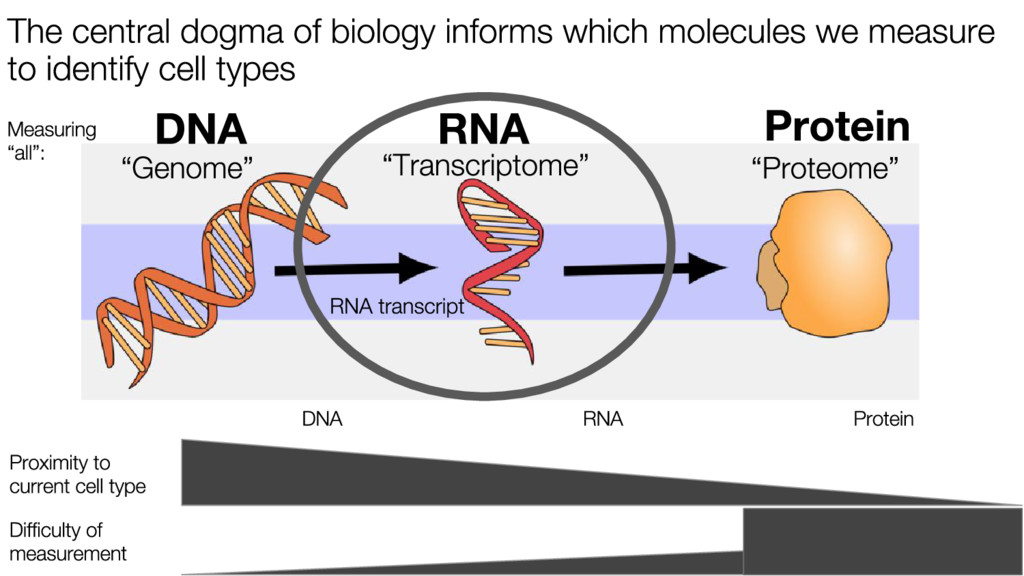{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
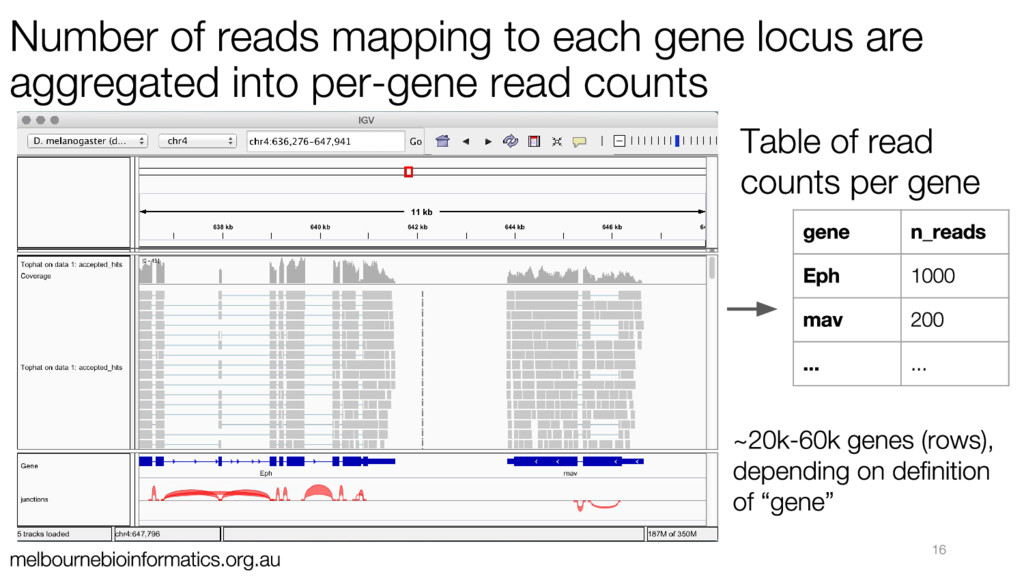{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
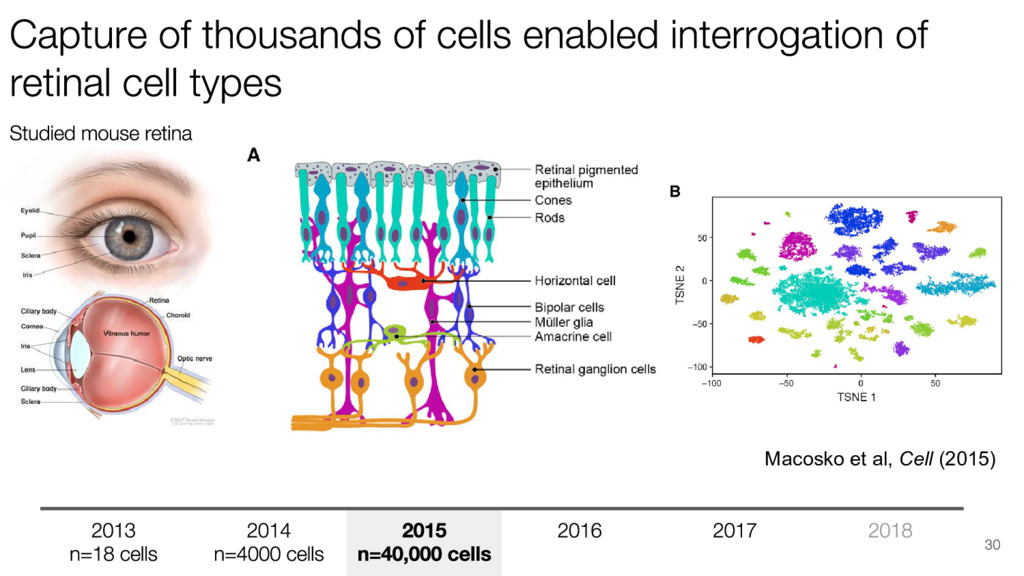{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![twitter, github: @olgabot www: olgabotvinnik.com email: [email protected]](https://files.speakerdeck.com/presentations/9b328854cff2466a9a4782430db8e1d6/slide_60.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}