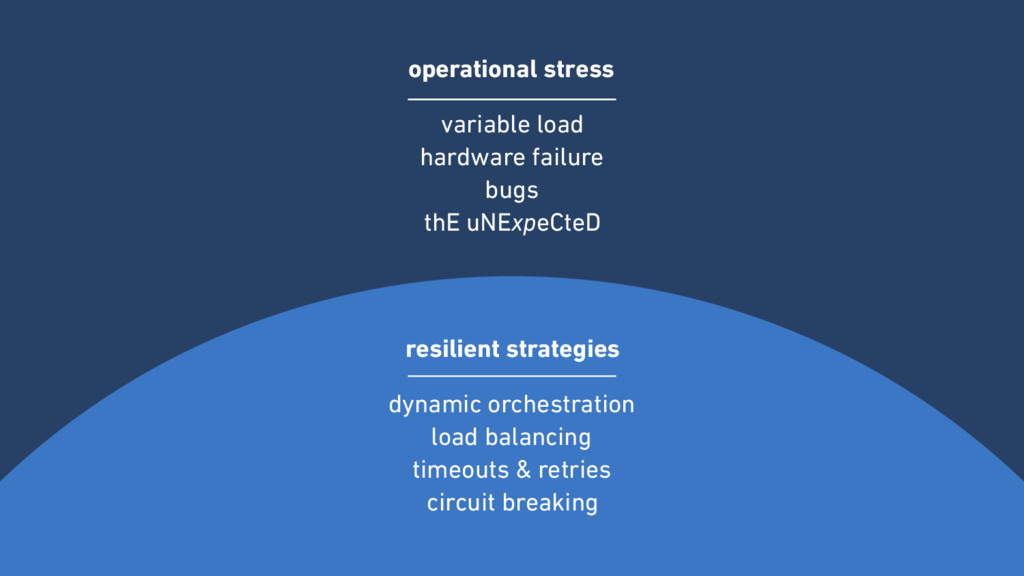
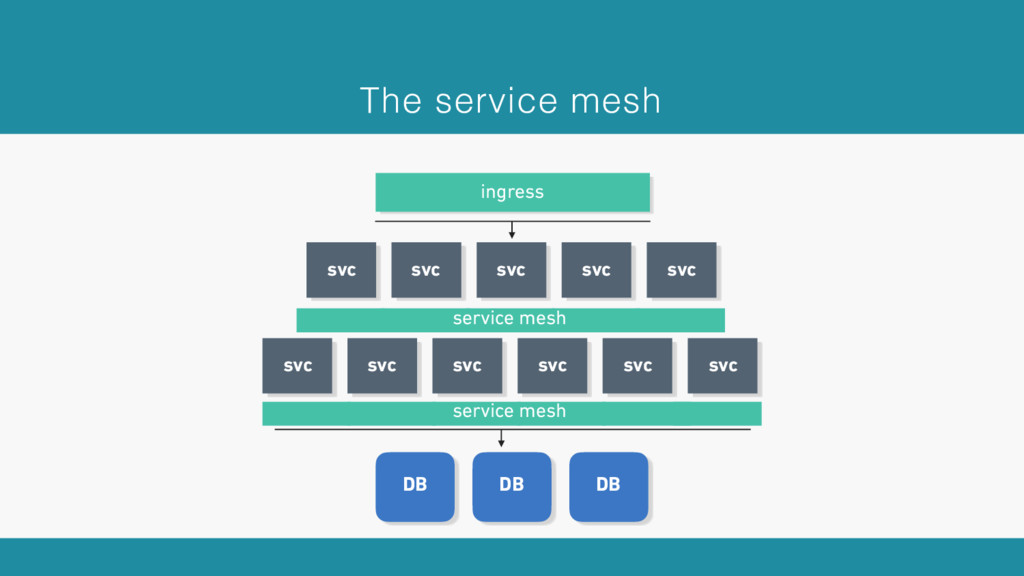
Modern application architecture is becoming cloud native: containerized, “microserviced,” and orchestrated with systems like Kubernetes, Mesos, and Docker Swarm. While this environment is resilient to many failures of both hardware and software, complex, high-traffic applications require more than this to be truly resilient—especially as internal, service-to-service communication becomes a critical component of application behavior and resilient applications require resilient interservice communication.
Oliver Gould explains why companies like PayPal, Ticketmaster, and Monzo are adopting the service mesh model, a user space infrastructure layer designed to manage service-to-service communication in a cloud-native environment, including handling partial failures and unexpected load while reducing tail latencies and degrading gracefully in the presence of component failure.
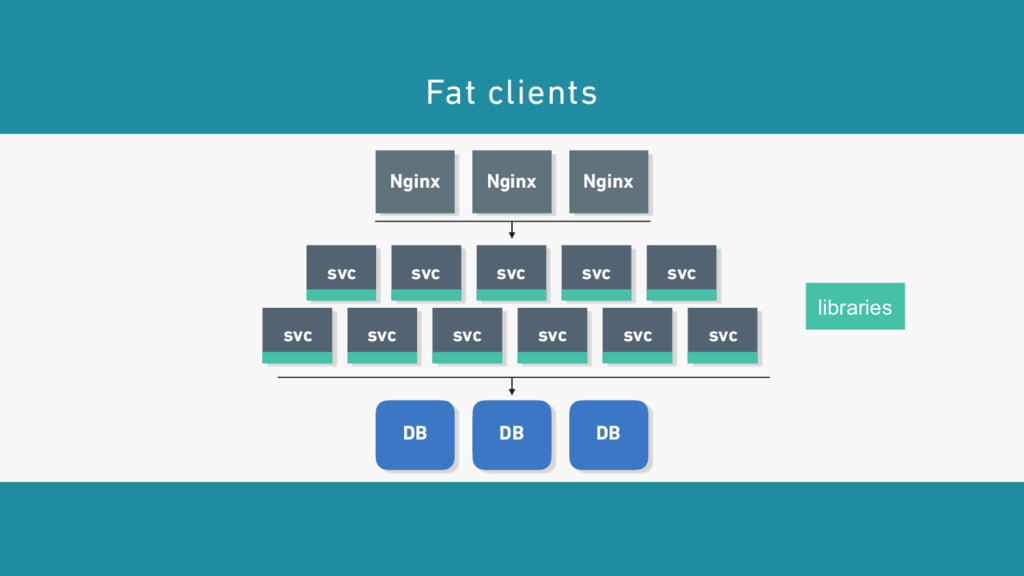
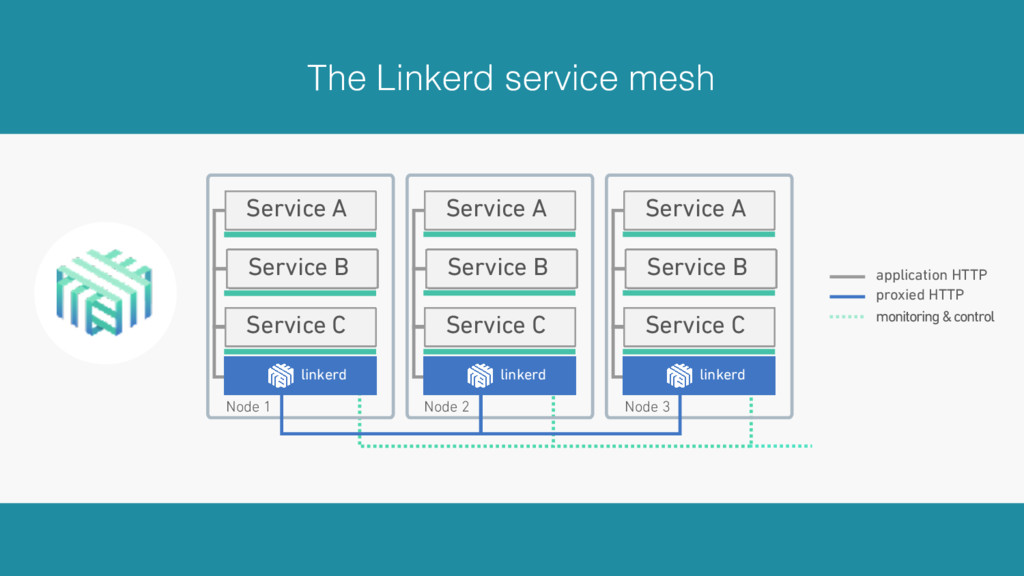
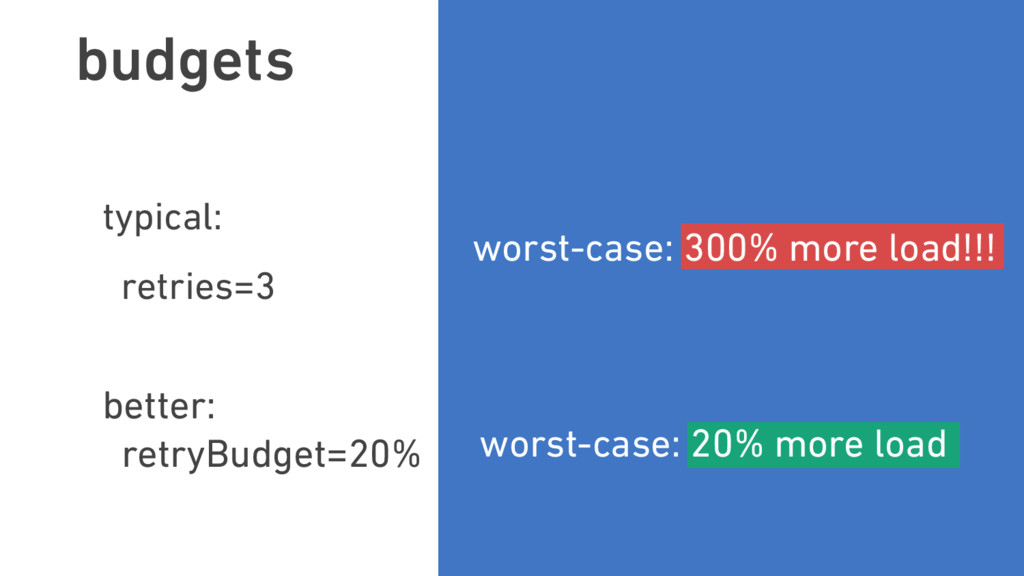
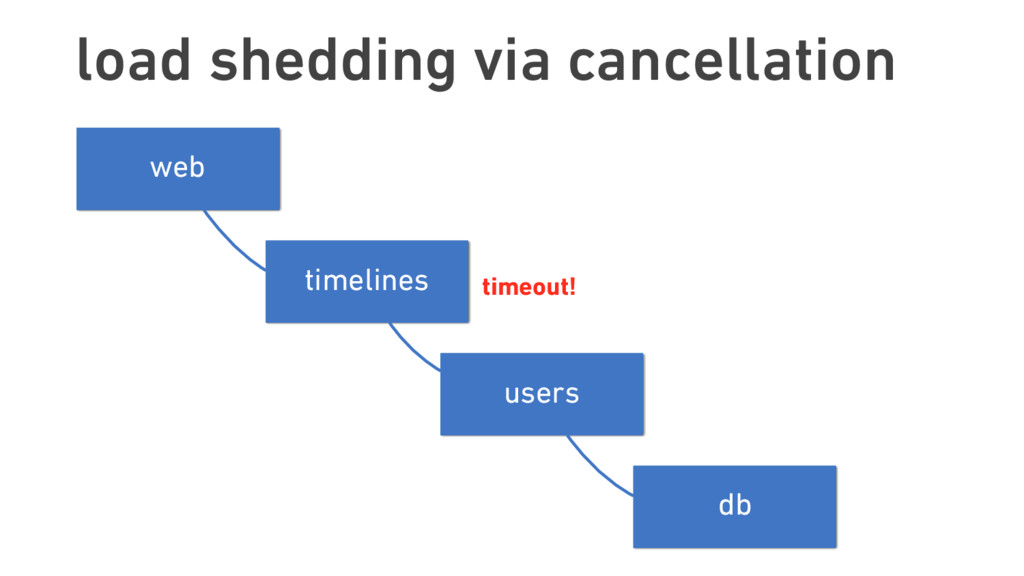
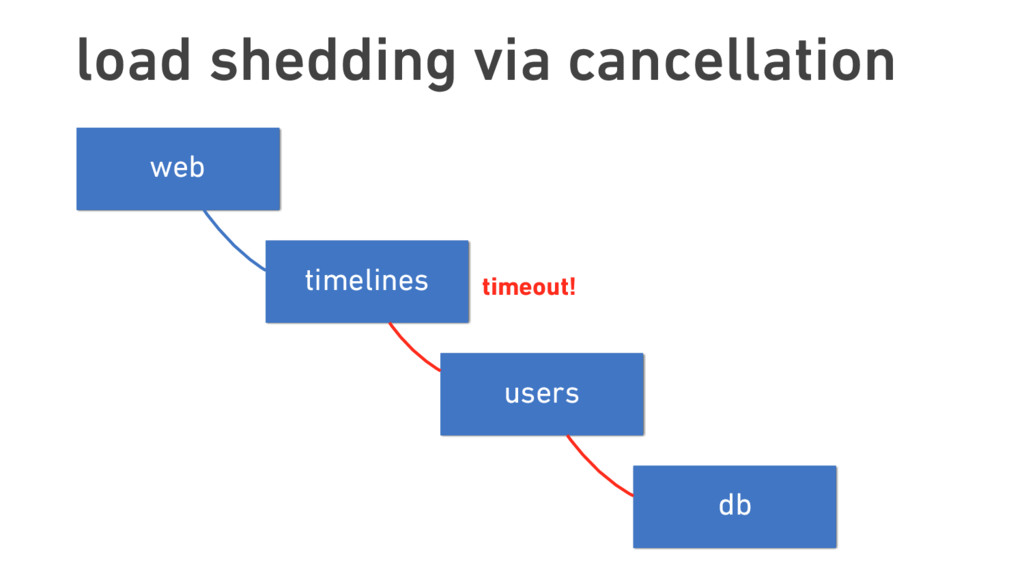
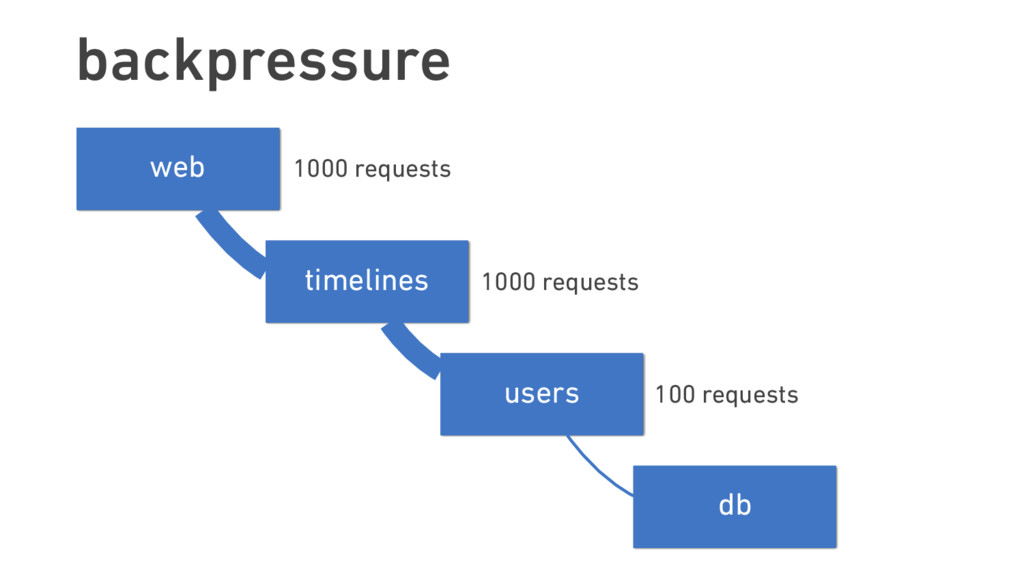
Oliver traces the roots of service mesh models to microservice “sidecars” like Netflix’s Prana and Airbnb’s SmartStack. He also offers an overview of linkerd, a lightweight, Apache 2-licensed service mesh implementation used in production today at banks, AI startups, government labs, and more, detailing linkerd’s modern, multilayered approach for handling failure (and its pernicious cousin, latency), including latency-aware load balancing, failure accrual, deadline propagation, retry budgets, and nacking. Oliver also describes linkerd’s unified model for request naming, which extends its model for failure handling across service cluster and data center boundaries, allowing for a variety of traffic-shifting strategies such as ad hoc staging clusters, blue-green deploys, and cross-data center failover.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![datacenter [1] physical [2] link [3] network [4] transport linkerd-tcp](https://files.speakerdeck.com/presentations/3ef90f1a64bf48cfa952d36ecff5e704/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
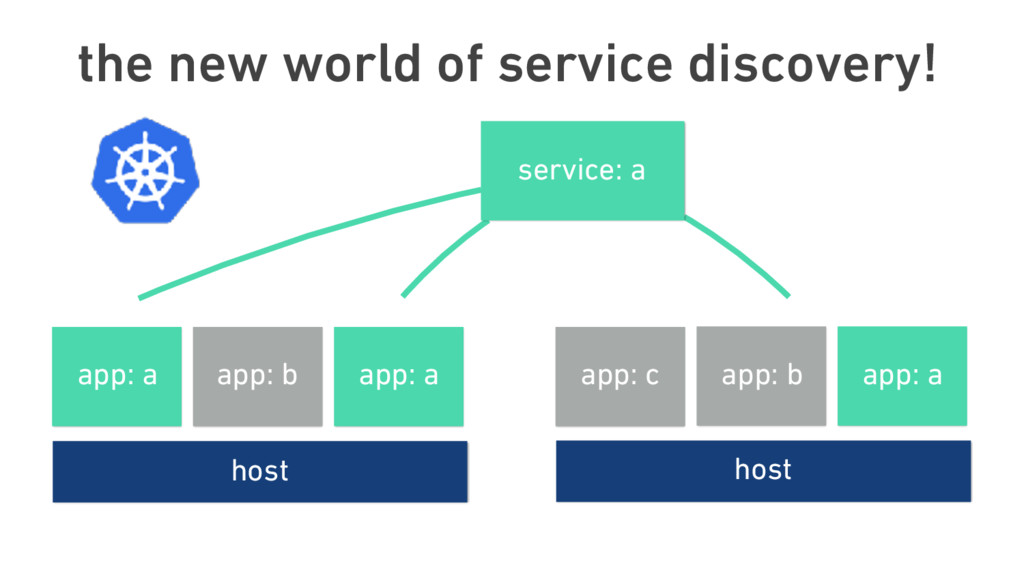{kind=link}
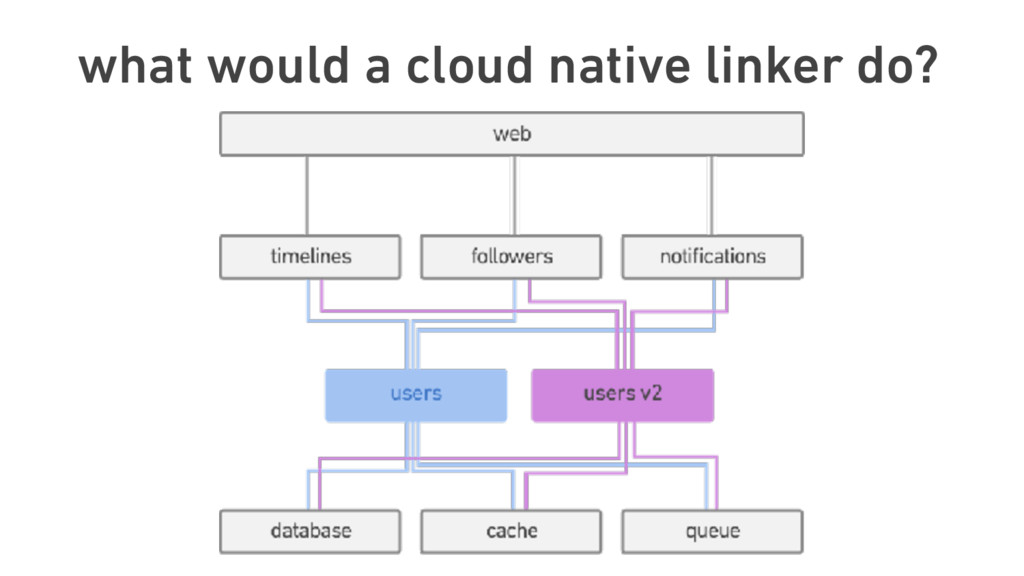{kind=link}
{kind=link}
{kind=link}
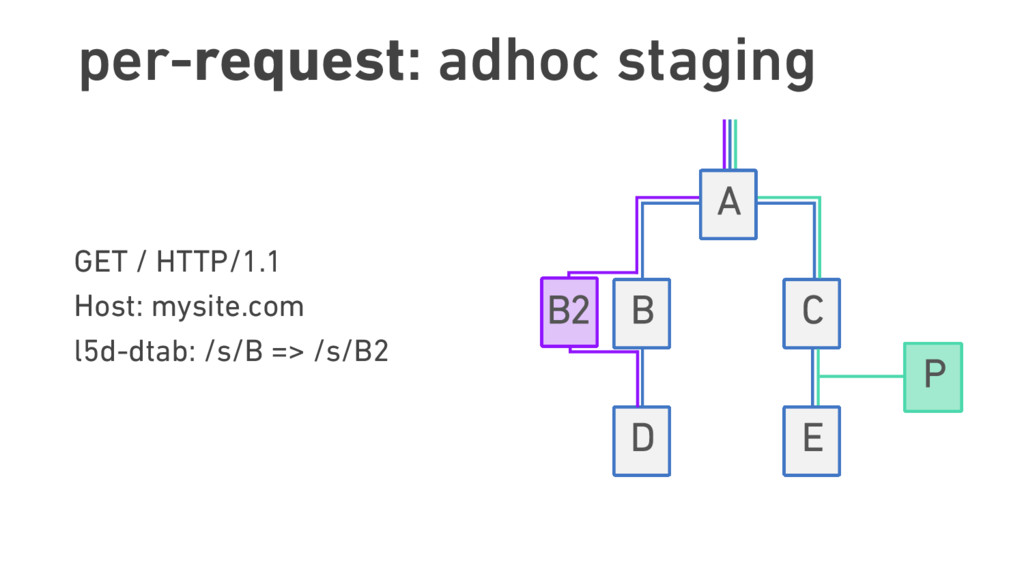{kind=link}
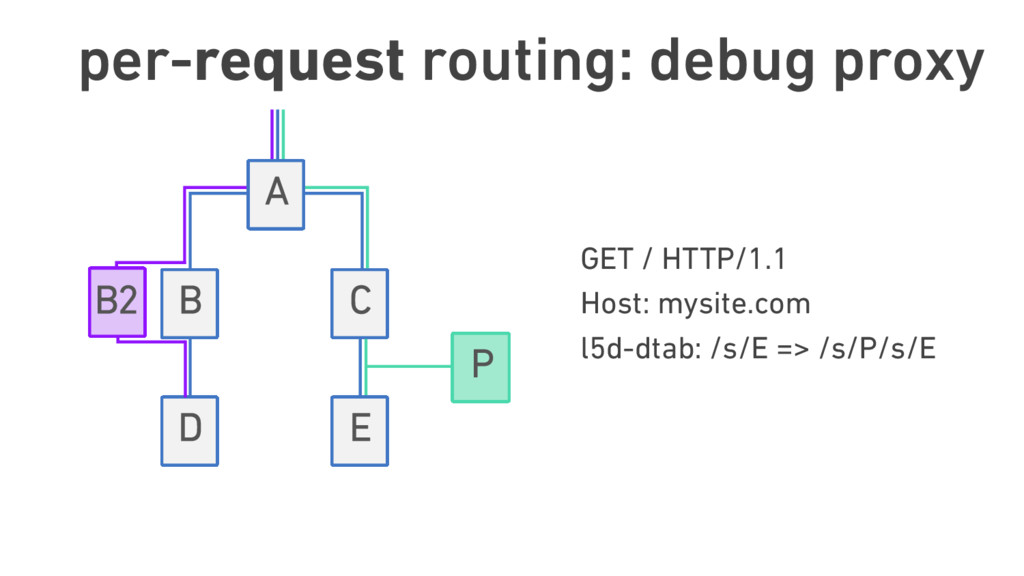{kind=link}
{kind=link}
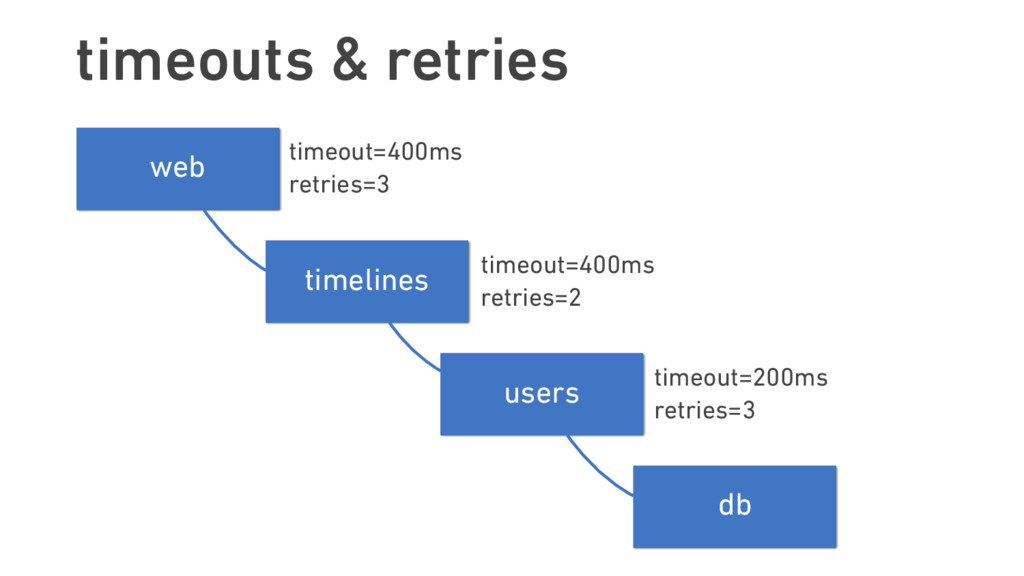{kind=link}
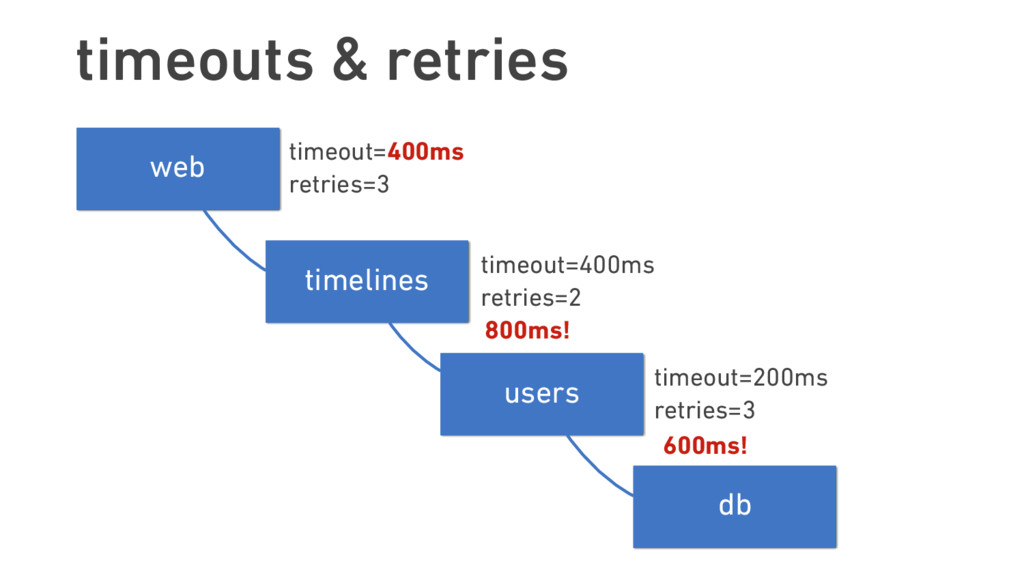{kind=link}
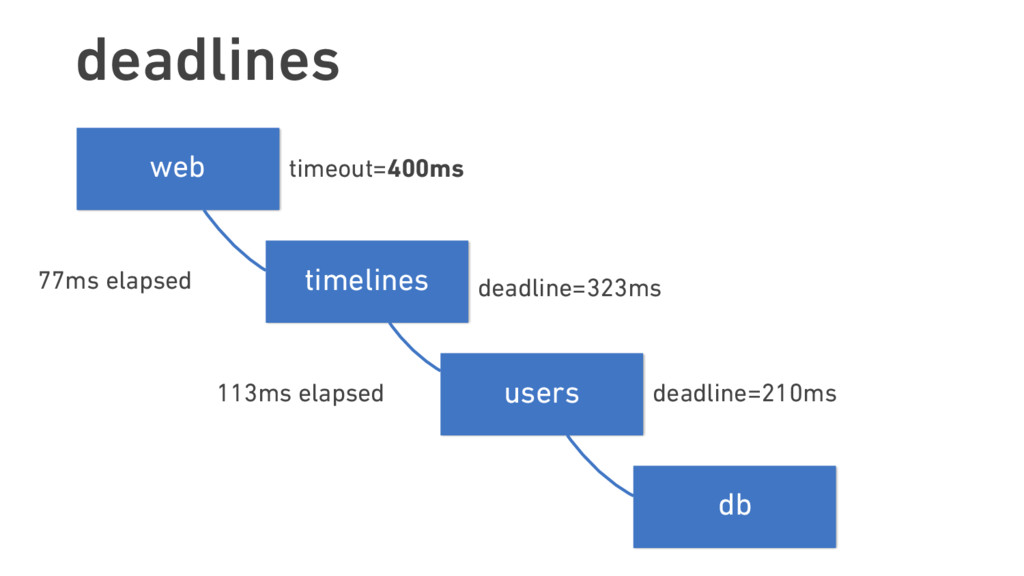{kind=link}
{kind=link}
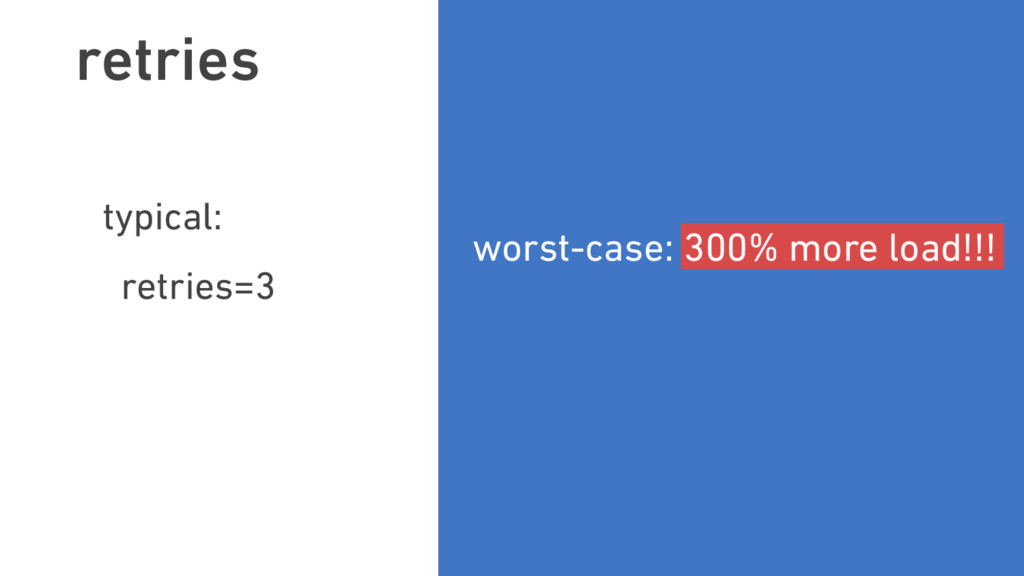{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}