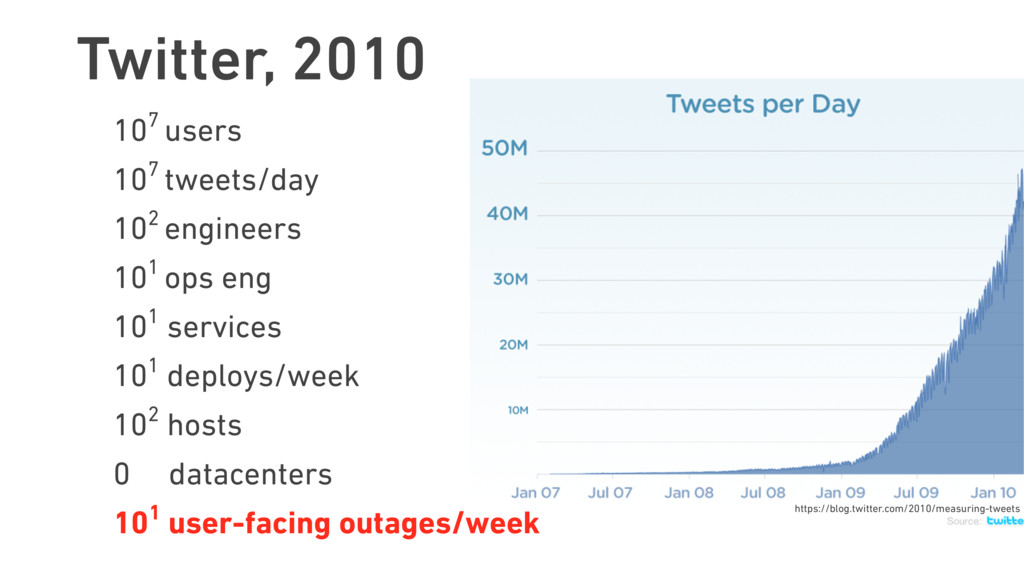
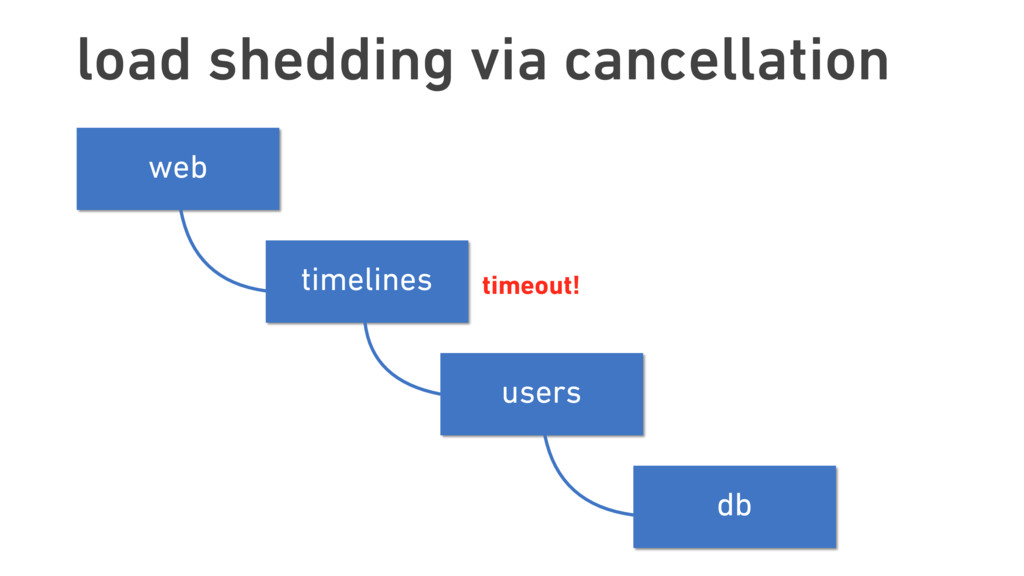
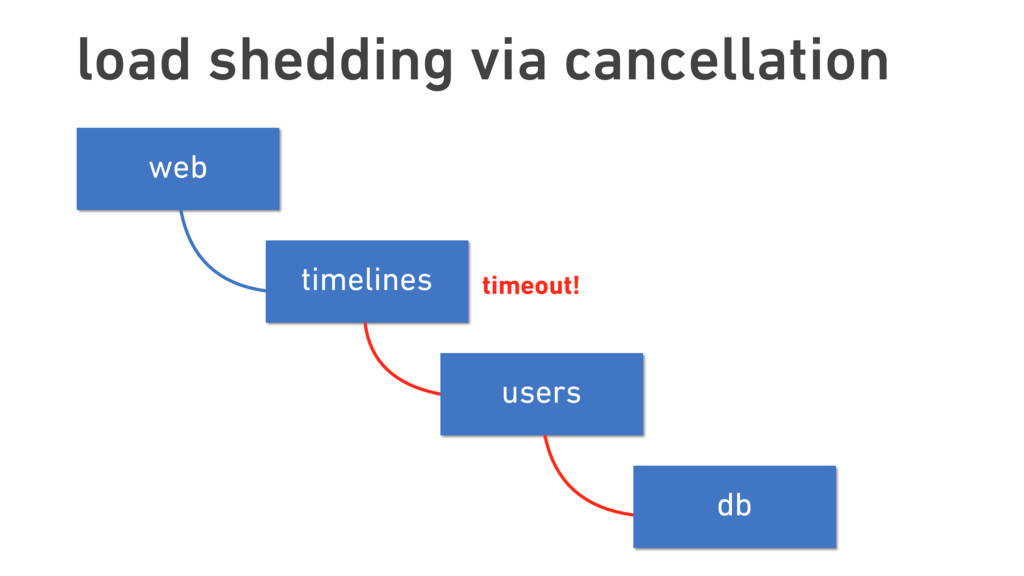
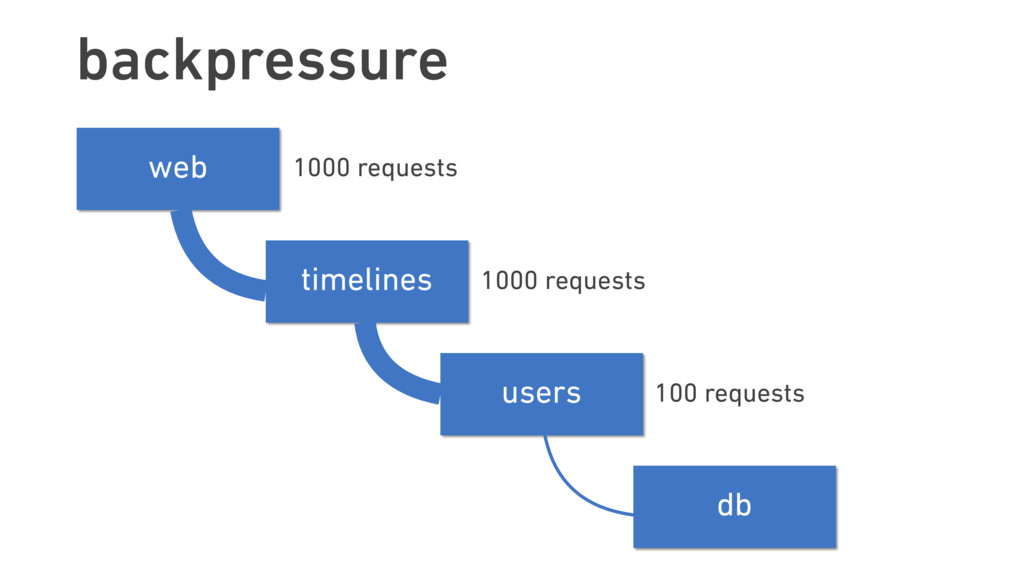
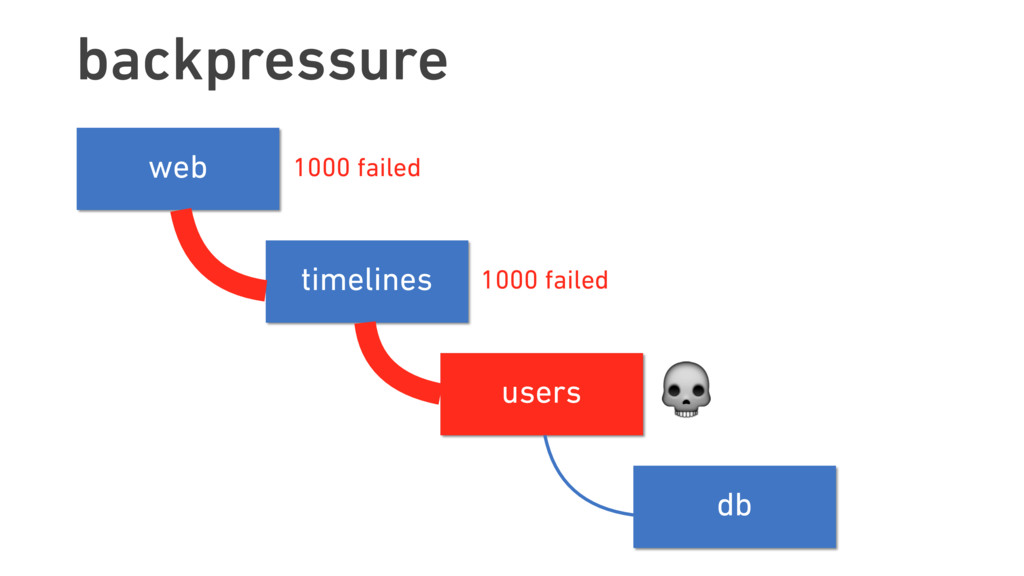
Twitter was once known for its ever-present error page, the “Fail Whale.” Thousands of staff-years later, this iconic image has all but faded from memory. This transformation was only possible due to Twitter’s treatment of failure as something not just to be expected, but to be embraced.
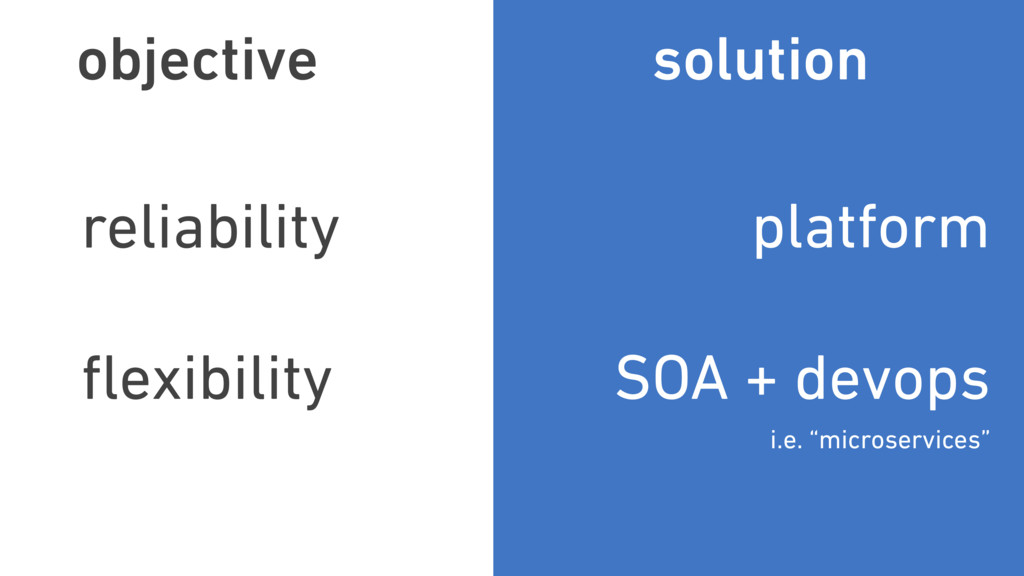
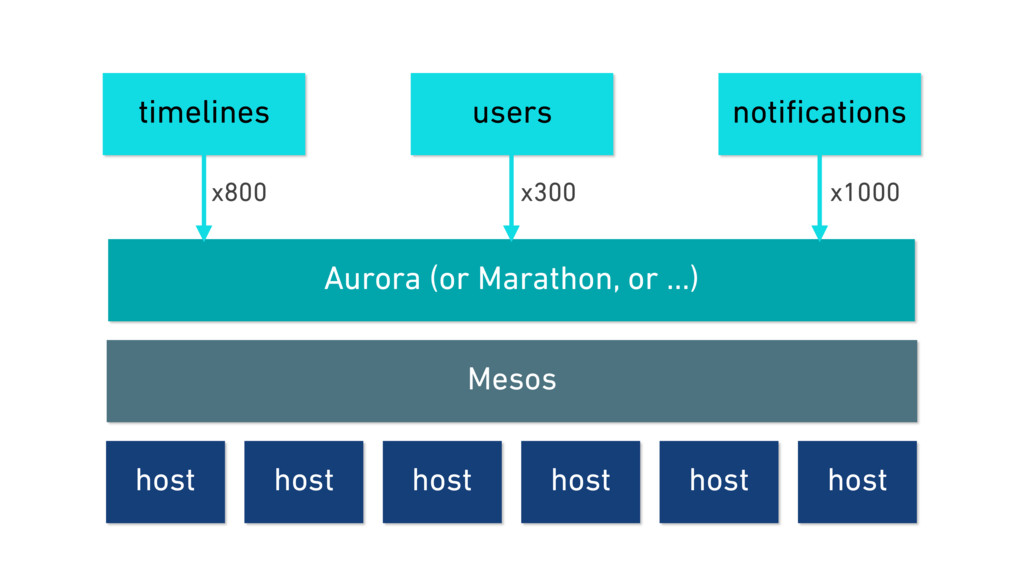
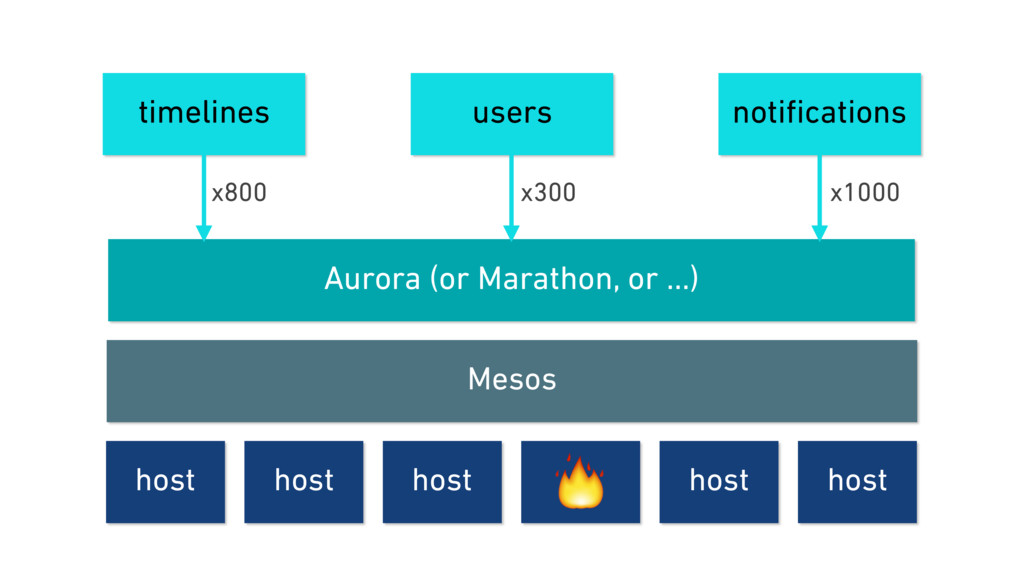
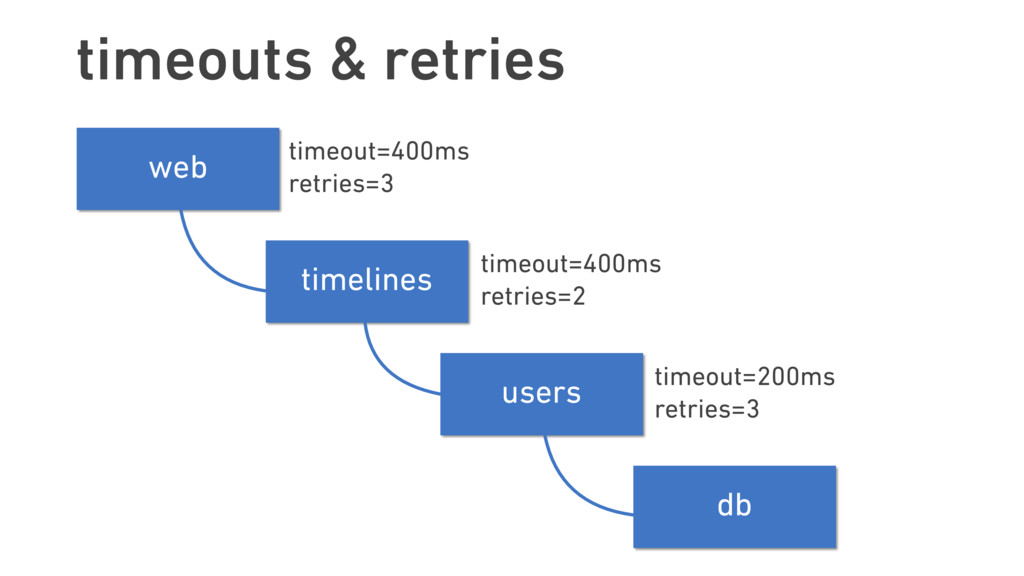
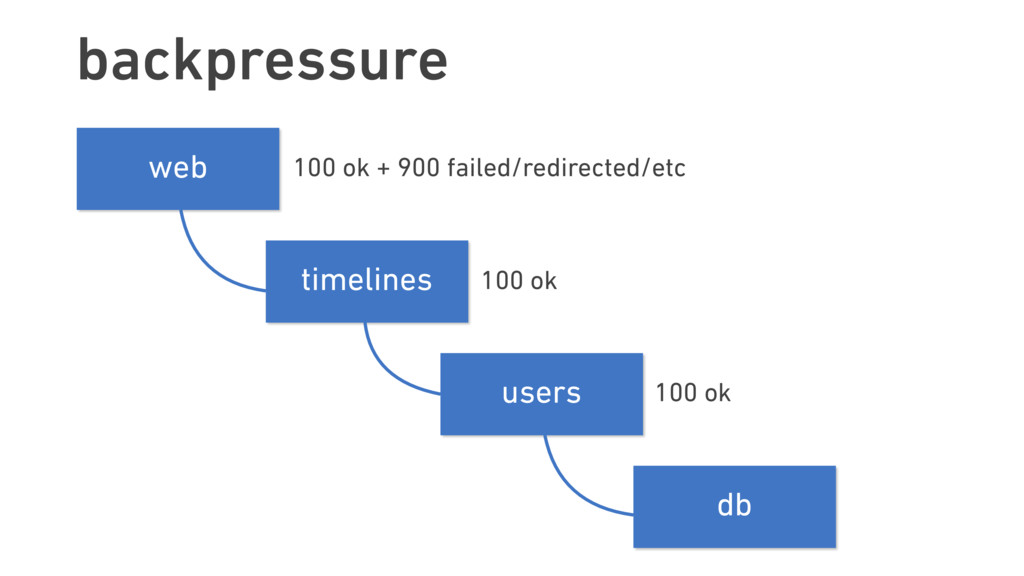
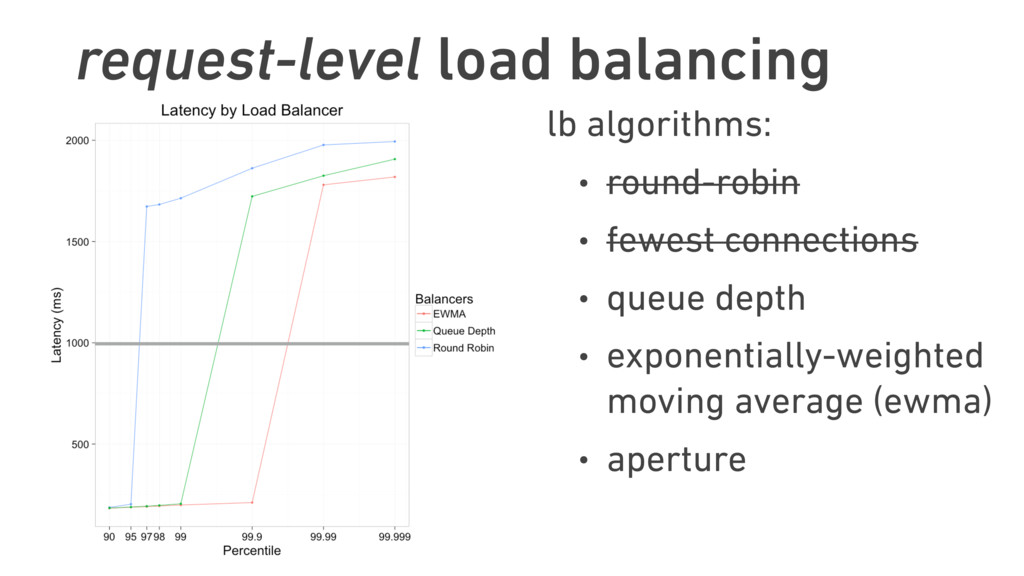
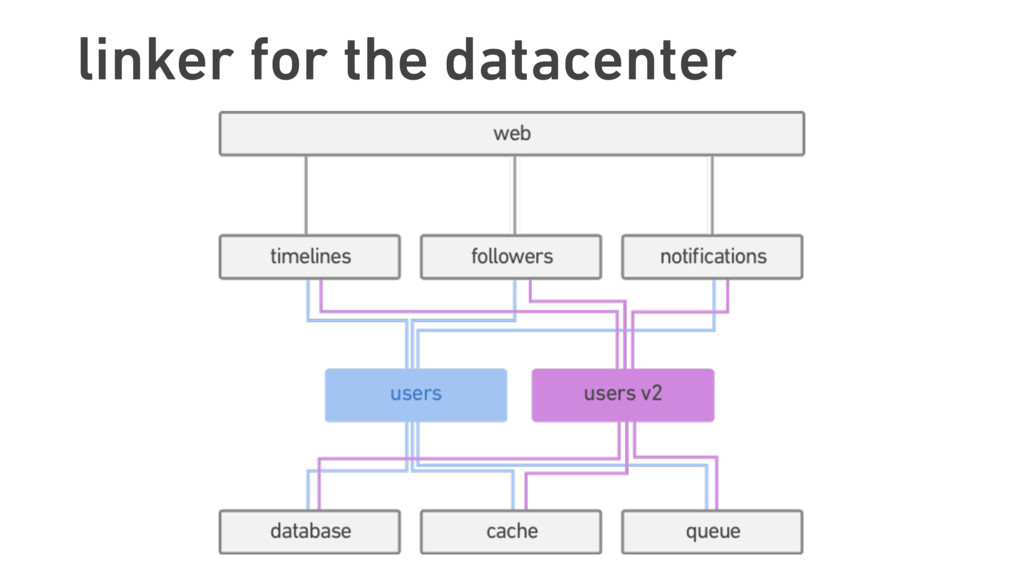
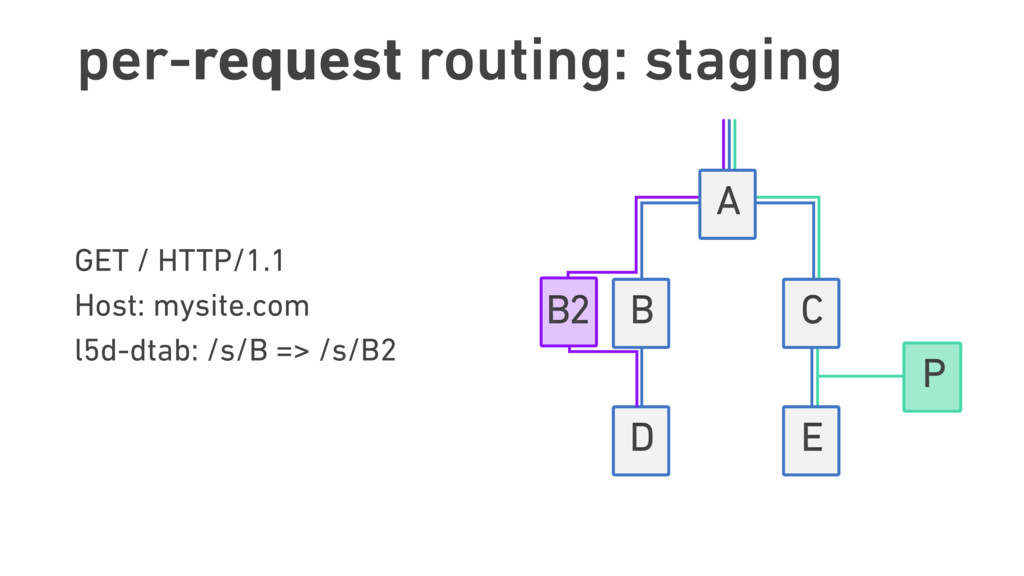
In this talk, we discuss the technical insights that enabled Twitter to fail, safely and often. We will show how Finagle, the high-scale RPC library used at Twitter, Pinterest, SoundCloud, and other companies, provides a uniform model for handling failure at the communications layer. We’ll describe Finagle’s multi-layer mechanism for handling failure (and its pernicious cousin, latency), including latency-aware load balancing, failure accrual, deadline propagation, retry budgets, and negative acknowledgement. Finally, we’ll describe Finagle’s unified model for naming, inspired by the concepts of symbolic naming and dynamic linking in operating systems, which allows it to extend failure handling across service cluster and datacenter boundaries. We will end with a roadmap for improvements upon this model and mechanisms for applying it to non-Finagle applications.
From QConSF 2016.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![datacenter [1] physical [2] link [3] network [4] transport kubernetes,](https://files.speakerdeck.com/presentations/a03d90a34c67499191aca1d4c9ada013/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
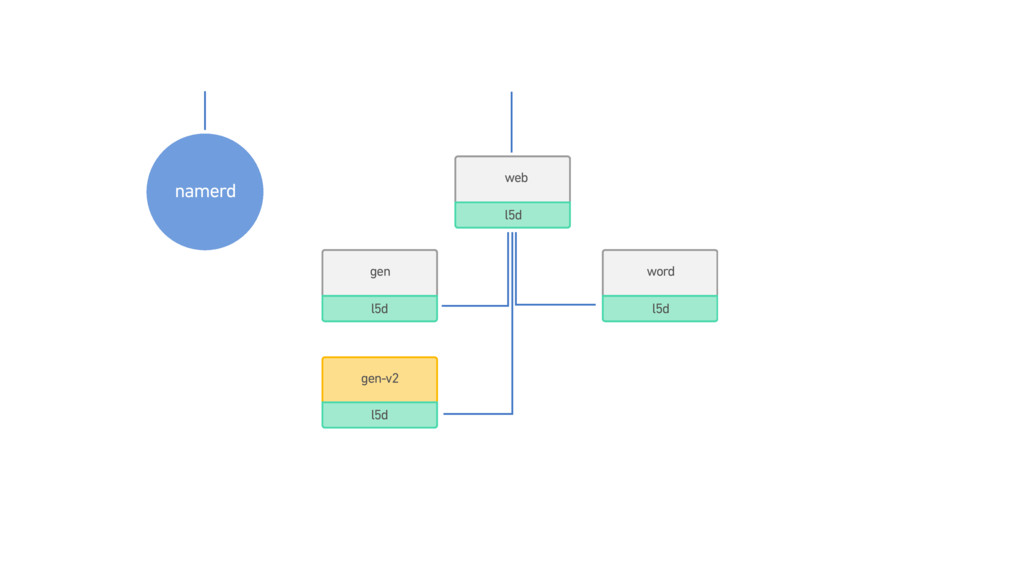{kind=link}
{kind=link}
{kind=link}
![more at linkerd.io slack: slack.linkerd.io email: [email protected] twitter: • @olix0r](https://files.speakerdeck.com/presentations/a03d90a34c67499191aca1d4c9ada013/slide_54.jpg){kind=link}