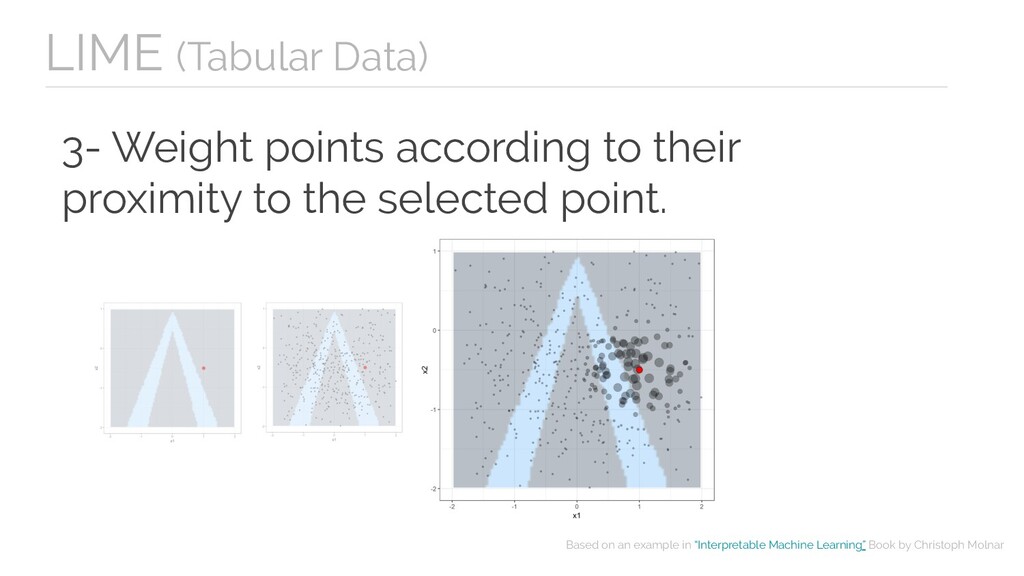
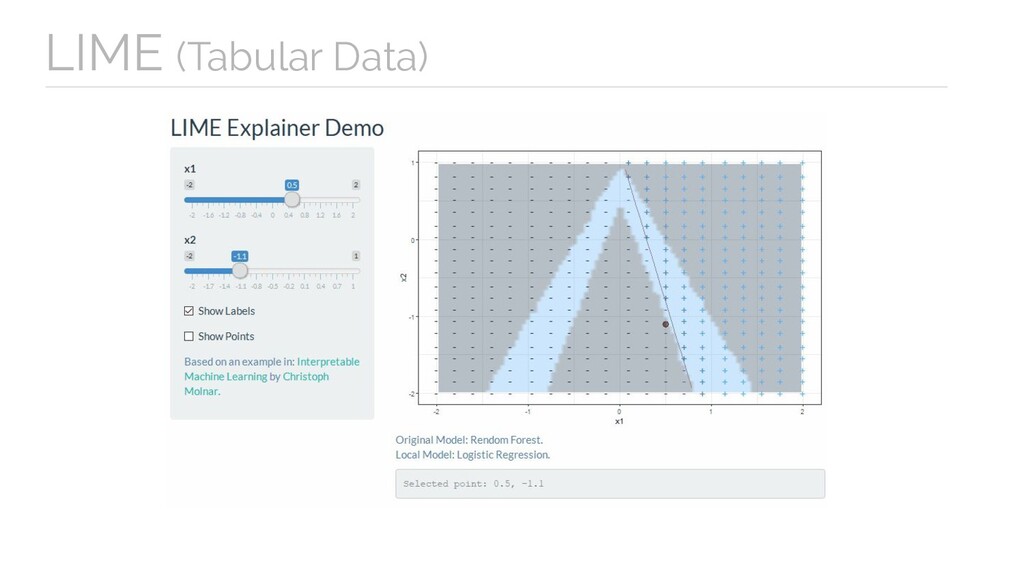
fidelity measure. - Can use other features than the original model. - The definition of proximity is not totally resolved in tabular data. - Instability of explanations.
- Can use other features than the original model. Cons - Instability of explanations. LIME - The definition of proximity is not totally resolved in tabular data.
prediction and the average prediction is fairly distributed among the feature values of the instance. - Computationally expensive. - Can be misinterpreted. SHAPLEY VALUES - Uses all features (not ideal for explanations that contain few features).
prediction and the average prediction is fairly distributed among the feature values of the instance. - Computationally expensive. - Can be misinterpreted. SHAPLEY VALUES - Uses all features (not ideal for explanations that contain few features).
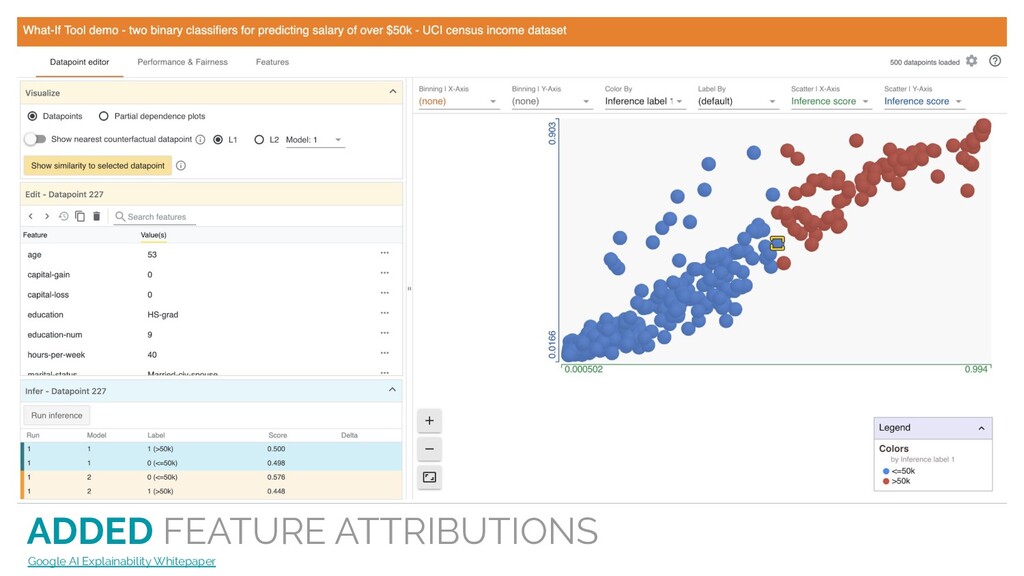
much the feature affected the prediction for that particular example). LIMITATIONS Google AI Explainability Whitepaper Limitations of Interpretable Machine Learning Methods
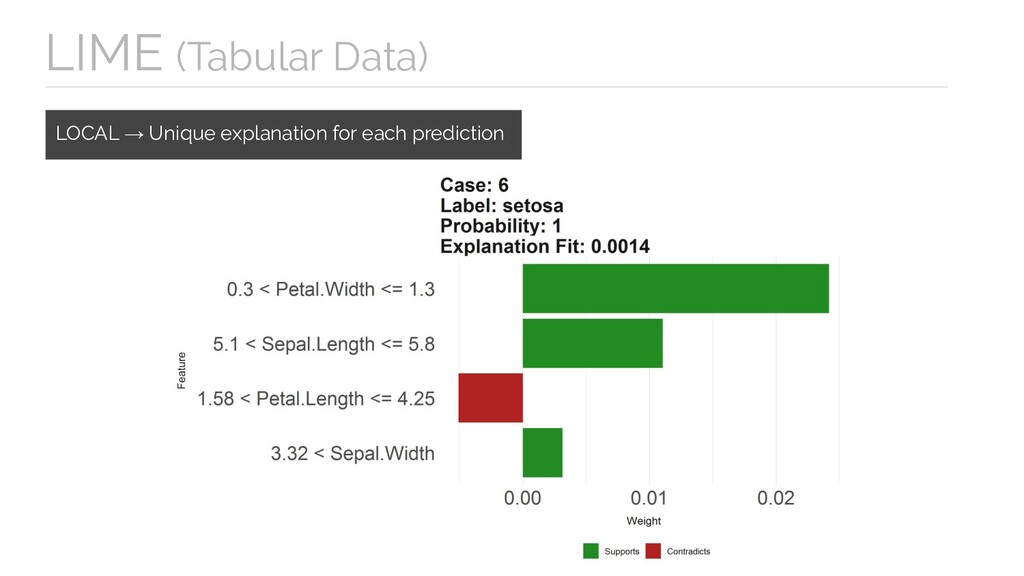
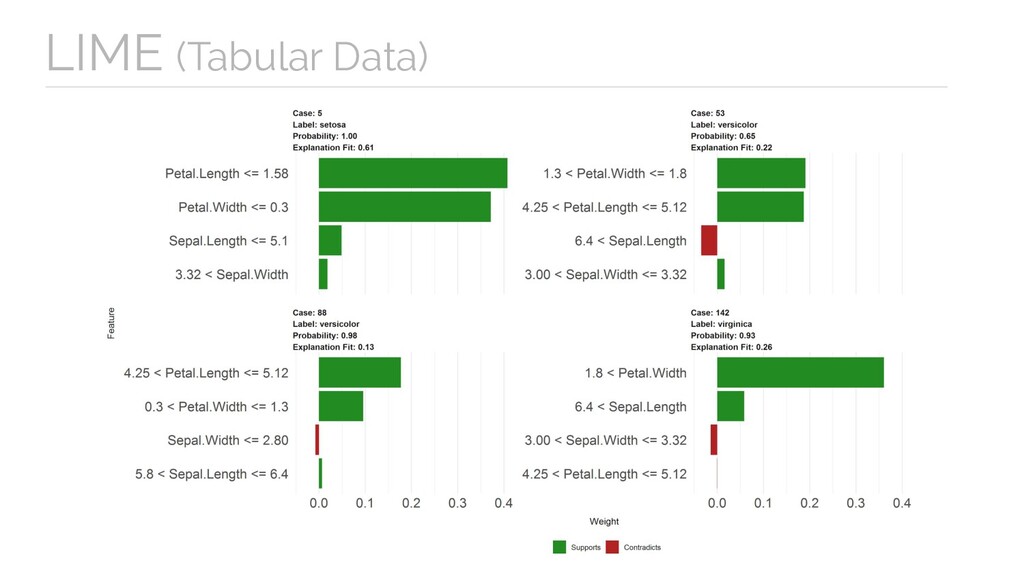
Machine Learning Methods Explanations are subject to adversarial attacks as predictions in complex models. Explanations are LOCAL (Each attribution only shows how much the feature affected the prediction for that particular example).
much the feature affected the prediction for that particular example). LIMITATIONS Google AI Explainability Whitepaper Limitations of Interpretable Machine Learning Methods Explanations are subject to adversarial attacks as predictions in complex models. Explanations alone cannot tell if your model is fair, unbiased, or of sound quality.
much the feature affected the prediction for that particular example). LIMITATIONS Google AI Explainability Whitepaper Limitations of Interpretable Machine Learning Methods Explanations are subject to adversarial attacks as predictions in complex models. Explanations alone cannot tell if your model is fair, unbiased, or of sound quality. Different methods are just complementary tools to be combined with the practitioners’ best judgement.
feature affected the prediction for that particular example). LIMITATIONS Explanations are subject to adversarial attacks as predictions in complex models. Explanations alone cannot tell if your model is fair, unbiased, or of sound quality. Different methods are just complementary tools to be combined with other approaches and the practitioners’ best judgement. https:/ /cloud.google.com/ml-engine/docs/ai-explanations/limitations Google AI Explainability Whitepaper Limitations of Interpretable Machine Learning Methods
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AI-POWERED [----] ML-ENABLED [----] MORE AND MORE](https://files.speakerdeck.com/presentations/de2985cef01c4059aaa45a3481b34396/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}