• Fresh state, evolving context, history, and vectors 2. Fluss as table-level stream-batch uni fi cation • From Kafka x Iceberg integration to Fluss-native Streamhouse 3. Fluss in the AI era • Real-time context, externalized state, and Lance support 4. Demo: IoT streaming with Fluss and Lance • Raw events, latest-state table, Lance tiering, and MinIO 5. Conclusion & Discussion • Key takeaways
to unify in the AI era? • Not just writing streaming data into a lakehouse • Not just adding another vector database • Not just letting a model query some data The real goal is this: Continuously changing data, state, context, and semantic representations should become one evolving data object. Because intelligent systems are not only reading history. They are acting on current state, recent changes, and semantic context. If these live in separate systems with separate freshness, schema, and update semantics, we get drift: the online decision sees one world, the batch analytics sees another, and the vector index may represent a third. For Data Agents or intelligent systems, that is exactly where trust breaks.
yesterday? • How did a metric change over time? • What should a human investigate? Intelligent systems ask • What is the entity state now? • What changed recently? • What context should guide the next action? The workload shifts from historical analysis to continuously changing operational context.
system knows what is true now. 2. Evolving context Recent events and entity changes stay available. 3. Historical reconstruction Decisions can be explained and replayed. 4. Semantic retrieval Vectors and similar cases can be connected back to the data path.
open-source, lakehouse-native streaming storage. It collapses the message broker, online KV store, stream-processing state backend, and lakehouse cold store into a single coherent foundation, making the Lakehouse truly real-time.
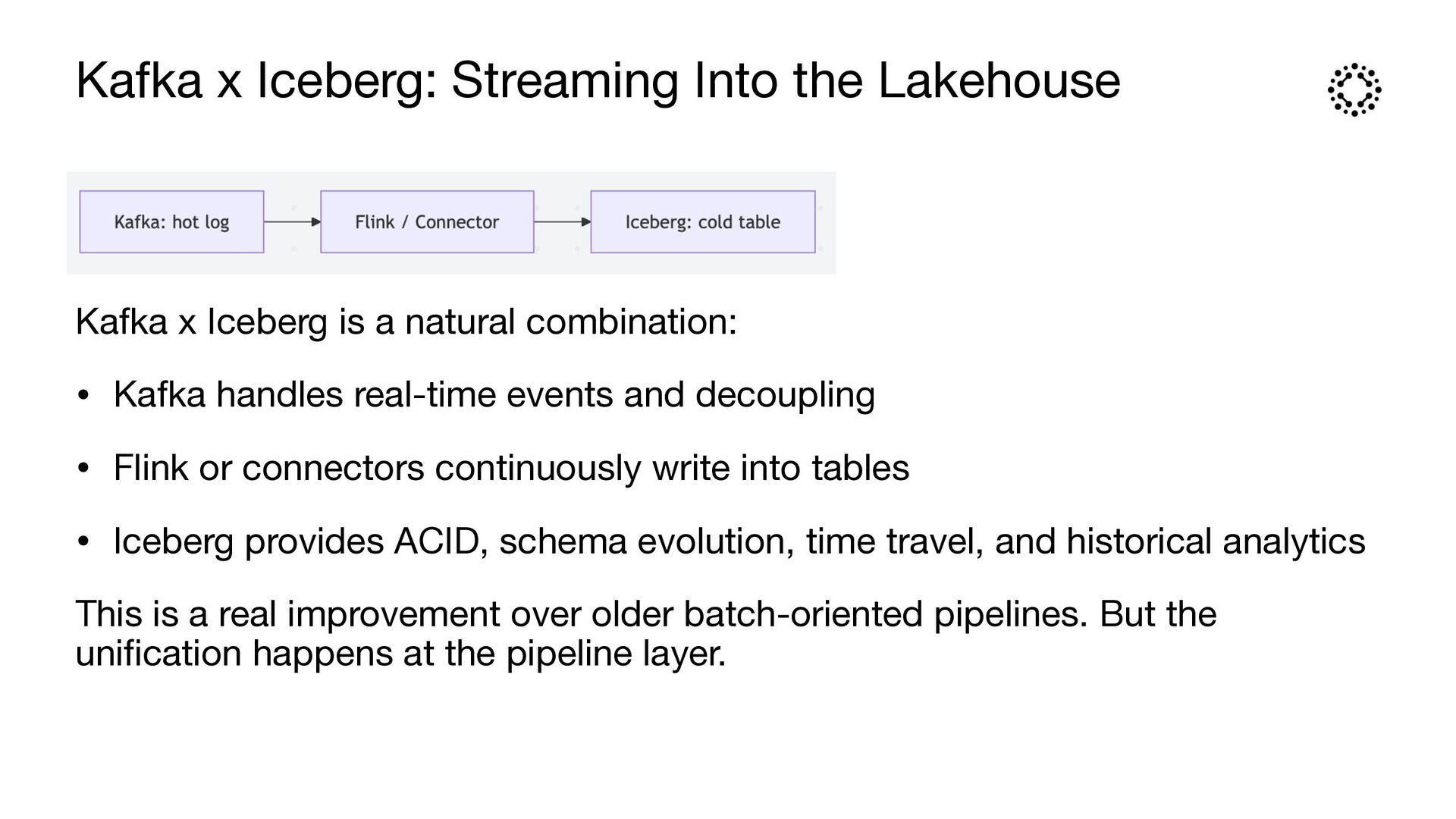
is a natural combination: • Kafka handles real-time events and decoupling • Flink or connectors continuously write into tables • Iceberg provides ACID, schema evolution, time travel, and historical analytics This is a real improvement over older batch-oriented pipelines. But the uni fi cation happens at the pipeline layer.
runs for a long time, hot and cold paths often split again: • Low-latency dashboards read from Kafka or serving stores • Historical analytics read from Iceberg • Back fi lls may bypass Kafka and write directly into Iceberg • Real-time metrics and o ff l ine metrics get separate implementations The same business metric quietly gains one streaming-shaped implementation and one batch-shaped implementation.
starts from a di ff erent question: What if streaming storage itself behaved like a table? In a Fluss-native architecture: • Real-time data stays hot, mutable, and queryable in Fluss • Historical data is tiered into lakehouse formats such as Iceberg, Paimon, or Lance • Hot and cold are di ff erent freshness layers of the same logical table
wrap a log and call it a table. It makes table semantics part of real-time storage: • Updates are part of the model • Schema is part of the model • Partitioning and bucketing are part of the model • Changelogs, primary keys, and materialized state are part of the model • After tiering, the same semantics continue into the lakehouse layer So uni fi cation is not maintained by discipline. It is supported by the structure of the system.
a traditional lakehouse: • Bronze lands raw data • Silver cleans and enriches it • Gold aggregates it • Each layer often has batch boundaries and recomputation points In a Fluss-native Streamhouse: • Bronze, Silver, and Gold can all be continuously updated tables • Upstream changes propagate as changelogs • Late data, corrections, and schema changes can fl ow naturally across layers In short: data does not arrive at Silver or Gold. It fl ows through them.
last year, Fluss has evolved in three major directions: • Stateless compute and externalized state • Compute becomes lighter • State becomes durable, stable, and queryable • Recovery, scaling, and logic upgrades become easier • Complex data types and zero-copy schema evolution • Data models can naturally become richer • Schema changes do not require large rewrites • Vectors and Lance • Embeddings no longer have to live in a separate silo • Structured data, streaming signals, and vector representations can live closer to the same foundation
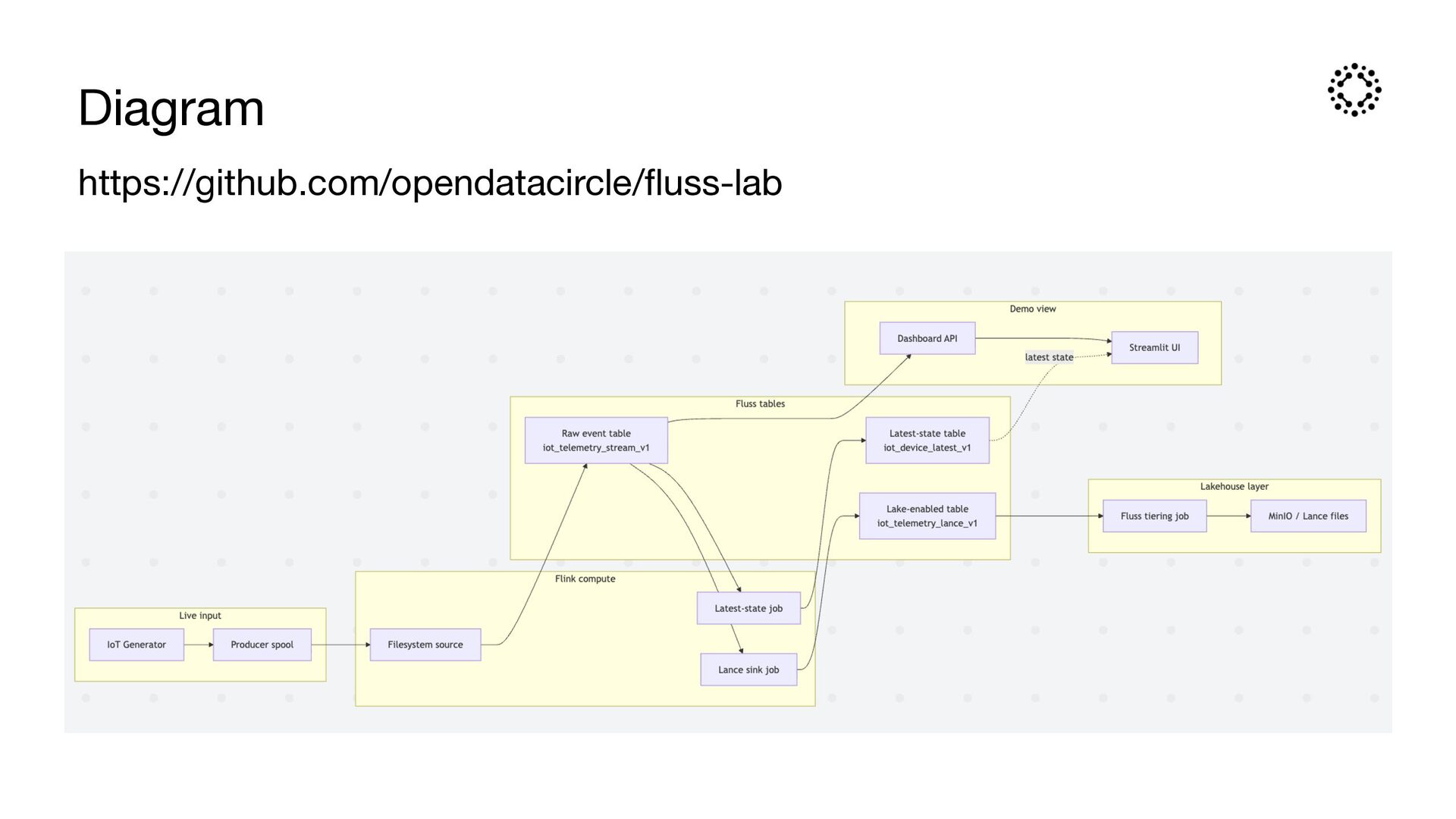
need three access patterns at the same time: • Row access: retrieve the latest state by key, such as user pro fi le or device state • Column access: scan features and history for analytics or training • Vector access: semantic similarity search for RAG, recommendations, and content discovery Lance matters because it brings vector and multi-modal data into the lakehouse context. The Fluss + Lance direction is powerful: real-time events enter Fluss, while semantic representations and historical context can be tiered into Lance for vector search and multi-modal analysis.
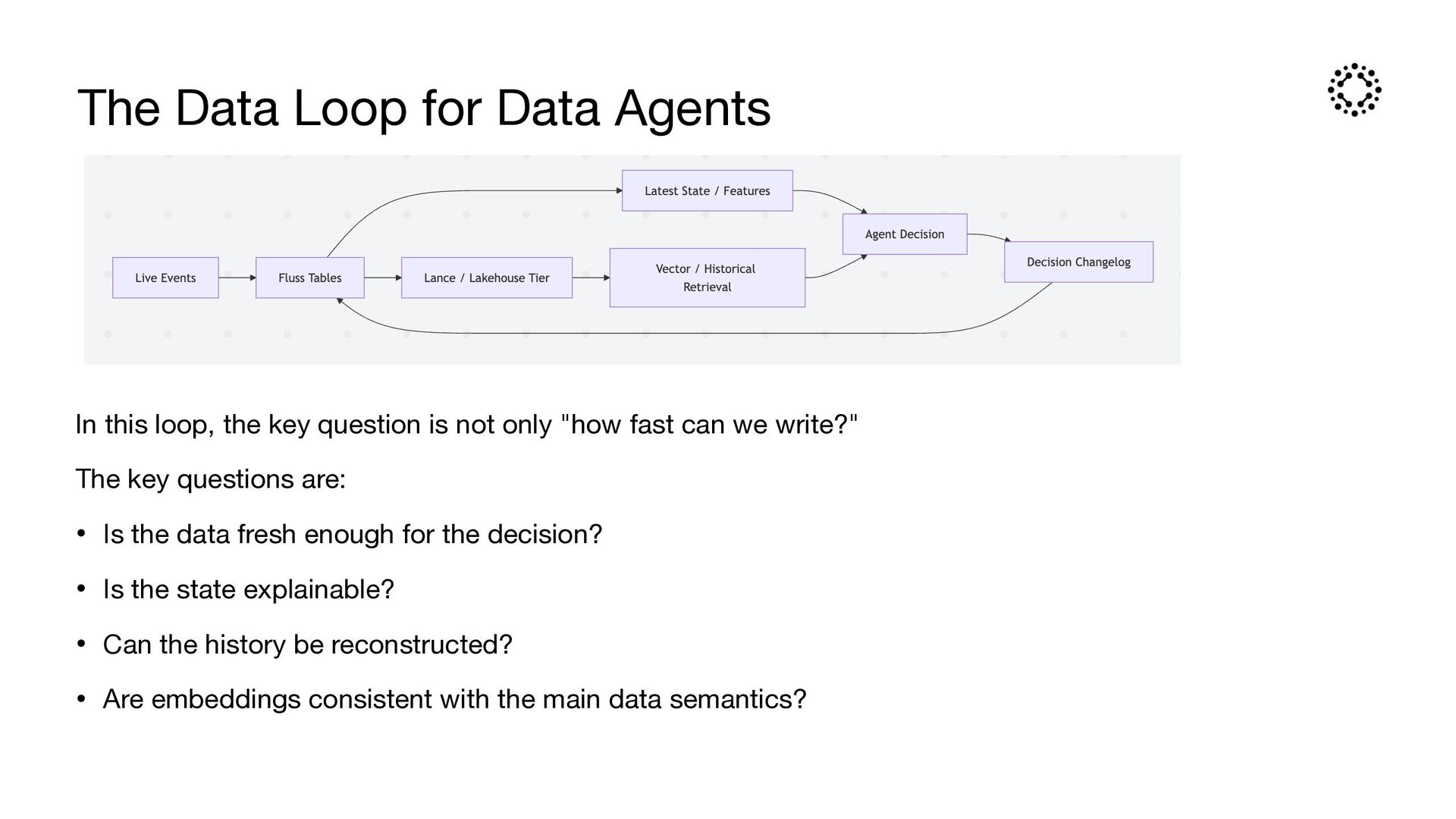
key question is not only "how fast can we write?" The key questions are: • Is the data fresh enough for the decision? • Is the state explainable? • Can the history be reconstructed? • Are embeddings consistent with the main data semantics?
makes real-time data durable, queryable, and lakehouse-ready. 1. Table-level stream-batch uni fi cation 2. One logical table across hot and cold freshness layers 3. Durable state outside compute 4. Real-time context for intelligent systems 5. Lance support for vector-aware lakehouse workloads 6. Less drift between online decisions, historical analytics, and semantic retrieval
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}