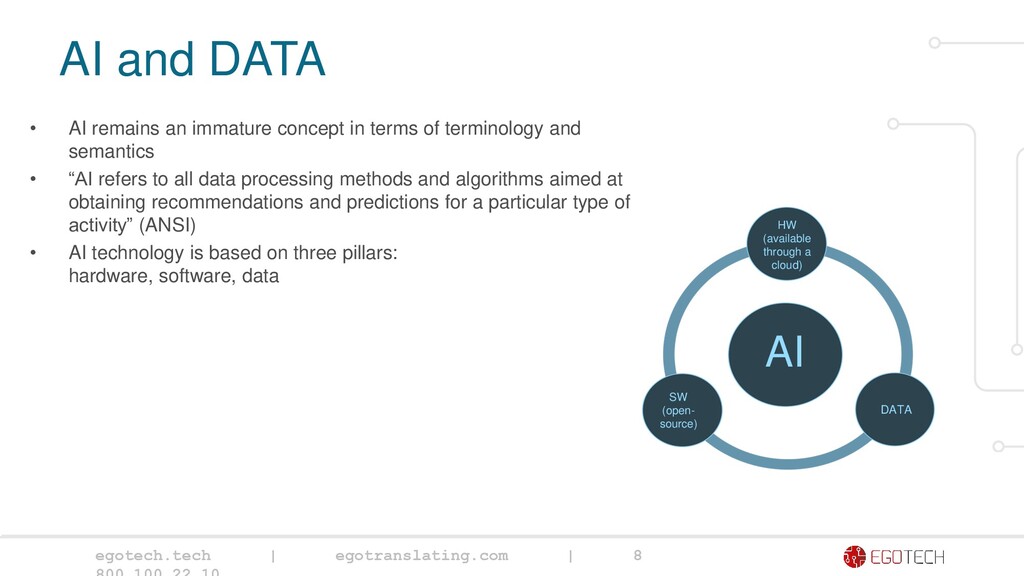
remains an immature concept in terms of terminology and semantics • “AI refers to all data processing methods and algorithms aimed at obtaining recommendations and predictions for a particular type of activity” (ANSI) • AI technology is based on three pillars: hardware, software, data Data volumes are growing exponentially 90 percent of all the data was generated in 2018- 2019 According to the HSE forecast, 80 percent of data will be unstructured by 2025 SW (open- source) DATA HW (available through a cloud) AI
Velocity, Variety) Volume Velocity Variety Data Quality: • Unavailable data • Incomplete data • Invalid data Valuable data refers to the data that have been collected, cleaned and normalized Data > Information > Knowledge
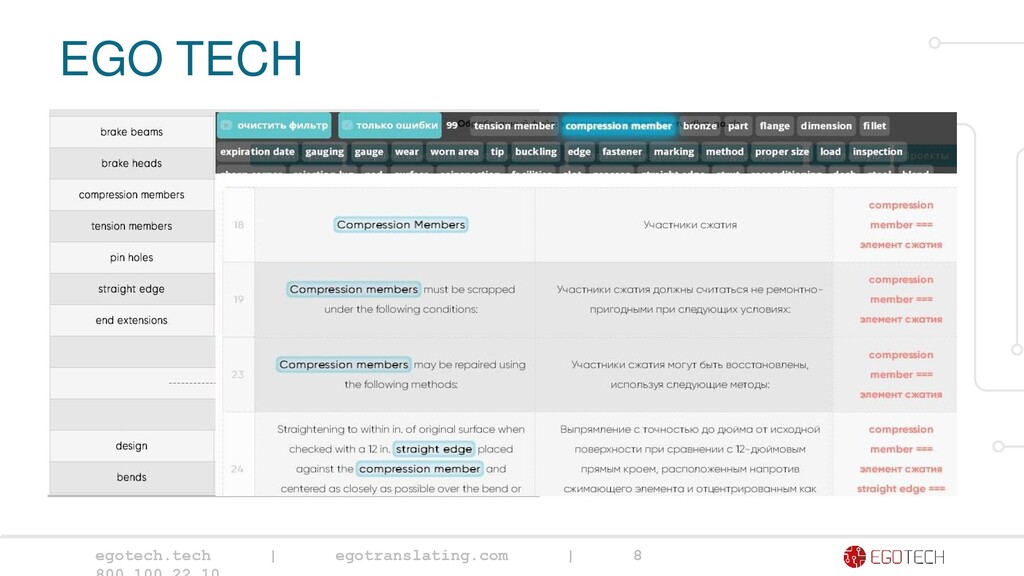
translation: unstructured multilingual textual data Volumes: from 1 GB Formats: tmx Problems: • accuracy, • completeness • anonymization Language data processing: • Collection • Normalization • Cleaning: Deduplication Incomplete meanings Invalid meanings Key issue of data processing for translation: terminology The necessity for work with the language especially with the Russian language (inflected) бензол = benzol; benzene. benzene ≠ бензин
data Language data in translation Volume >1 TB >1 GB Processing Continuous processing – customizing the ETL (extract- transform-load) process Real time data management necessity Formats Connecting with various formats (DBMS, BPS, workflow systems and etc.); converting to a common format for processing The .tmx format is specific for each CAT system (formats incompatibility when different CAT systems are used; converting is not always correct); the same is true for glossary import formats Digital Big non-digitized information Quality Duplicates: Ivanov I.I./I.I. Ivanov Different translation of one and the same segment/term Missing values Missing translations and partially missing translations Incorrect meanings Incorrect terminology Spelling
Machine Translation is a type of AI for the translation industry. Cleaned and normalized data form the basis for neural network learning. Uncleaned and unprocessed data – ‘garbage in, garbage out’ Requirements: volume from 100,000 sentences, correct terminology, completeness, anonymization. Currently available MT algorithms: recurrent neural networks (RNN). Adaptive MT (trained on topic/subject-specific corpora) – since 2018. Minimal corpus volume: 50,000 segments, adequate training: from 500,000 segments 80 percent of working time of an MT expert: DB cleaning and normalization
neural network 1. Source corpus 530,000 sentences, processing loss: 50 percent, translation quality improvement: from 35.18 to 50.98 according to the BLEU metric 2. Source corpus: 120,000 sentences, cleaned corpus: 50,000 sentences Result: improper, too small dataset Performance: Non-customized model/customized model: increased processing velocity and improved quality by a 1.3 factor
• Big data tagging and cleaning is impossible without human involvement (HITL). • A tagger is a profession of the future. • China is a data factory. • Textual data tagging is a new stage in the NLP development. “So far, the whole Artificial Intelligence has been based on human labour. Machines are not clever enough to learn on their own,” Liang Zhu, CEO of AInnovation, a Beijing-based AI company. EGO Translating Company: • Data cleaning for the optimized operation of the translation industry. • Specific formats: bilingual databases • A key quality aspect is correct terminology • QA platform for language data processing • 50+ data processing experts
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}