Loukachevitch Lomonosov Moscow State University Moscow, Russia Developer of large Russian resources such as RuWordNet, RuThes, organizer of Russian NLP evaluations
WordNet and wordnets for different languages – ImageNet was constructed over WordNet • Domain knowledge • Medical ontologies and thesauries (UMLS, MESH, Gene Onotology) are very influentional in medical NLP and bioNLP • Industrial knowledge graphs • Necessity of large resources
relations – pets are allowed»=> dogs are allowed (hypernym) – Restaurant in Japan => restaurant in Asia (holonym) – Restaurant in Japan ≠ restaurant in China (co-hyponym) – Good restaurant ≠ bad restaurant (antonym) • Question-answering systems – When did Donald Trump visit Alabama? • Trump visited Huntsville on September 23 • Trump visited Missisipi on June 21 • Dialog state tracking(DST) –first component of a dialog system • Asked for a „cheap pub in the east” the system should not recommend an „expensive restaurant in the pub”
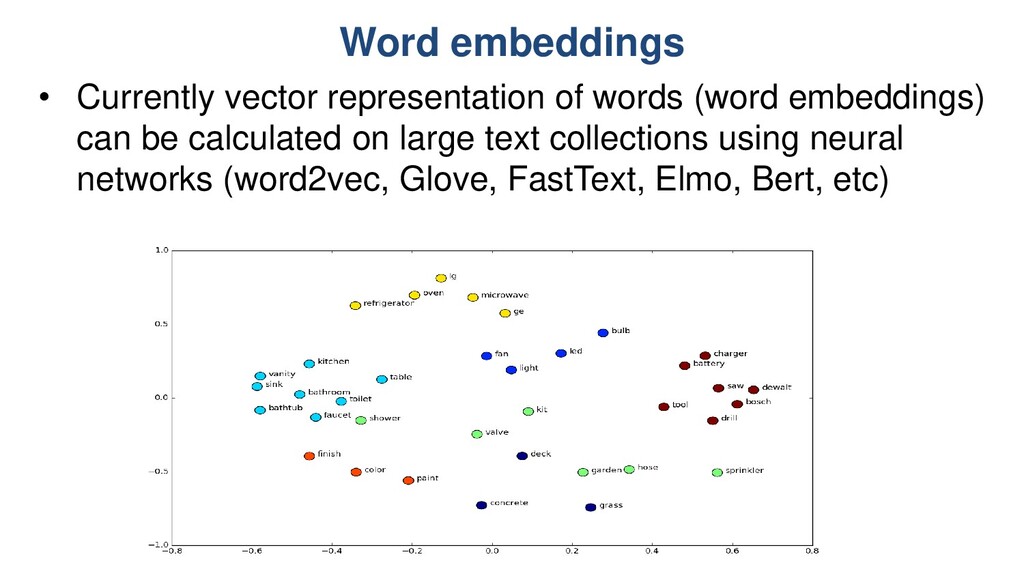
embeddings? – Modern word embeddings can capture word relatedness – But they mix all types of semantic relations together • Development and maintaining of large lexical and domain specific resources is needed – Faster creation of specialized resources (for example, in information security domain) – Adding novel words and terms in existing resources • What are current achievements in automated methods of lexical relation extraction and taxonomy construction
patterns with modifications • Distributional approaches based on word embeddings – Supervised learning on embeddings – Projection Learning • Combined approaches
vector, based on the word embeddings: – Concatenation [Baroni et al., 2012] – Difference [Roller et al., 2014] • Train a classifier to predict the semantic relation between x and y: Achieved very good results: more 70% Accuracy • But [Levy et al., 2015]: “lexical memorization”: overfitting to the most common relation of a specific word – Training: (cat, animal), (dog, animal), (cow, animal), ... all labeled as hypernymy – Model: (x, animal) is a hypernym pair, regardless of x y x x y
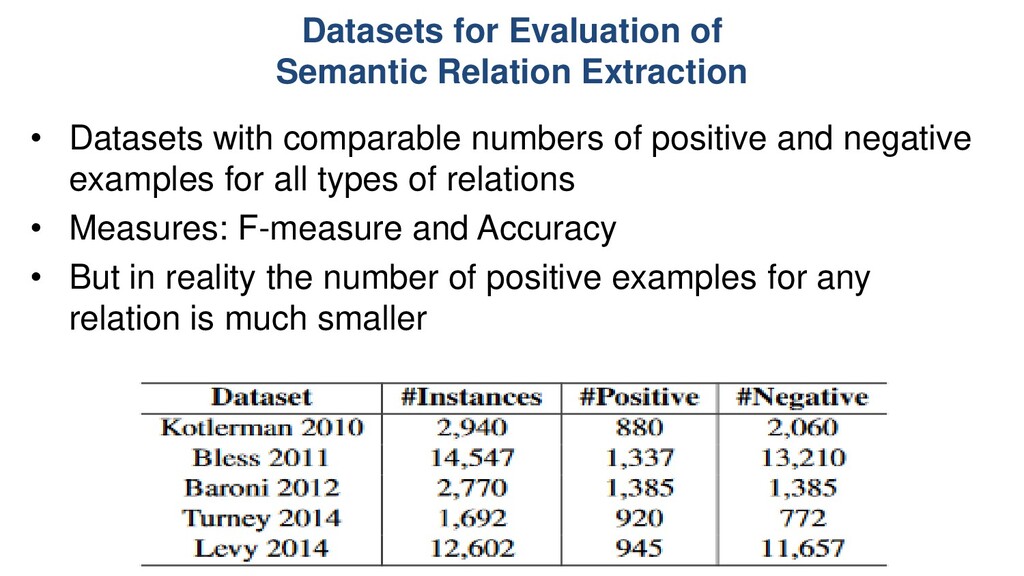
comparable numbers of positive and negative examples for all types of relations • Measures: F-measure and Accuracy • But in reality the number of positive examples for any relation is much smaller
To find hypernyms for a given hyponym X. To return ordered list of hypernym candidates for X from a given text collection. • Data: Target word X, large text collection, vocabulary of possible hypenyms (word occurred more than 5 times in the given collection), blacklist of too general words
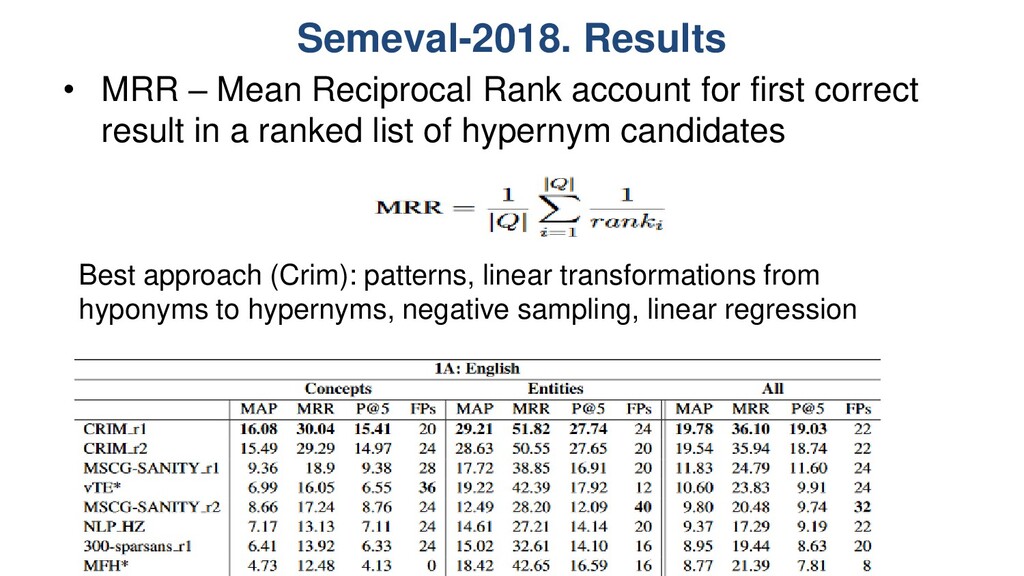
first correct result in a ranked list of hypernym candidates Best approach (Crim): patterns, linear transformations from hyponyms to hypernyms, negative sampling, linear regression
Hearst patterns (47 patterns) • Simple distributional model – Hypernyms of the most similar word from the training set (Nearest Neigbor) are taken – The hypernyms are ordered in descending order of their frequencies – If the similarity to NN is lower than threshold, the most frequent hypernym from the training data is taken
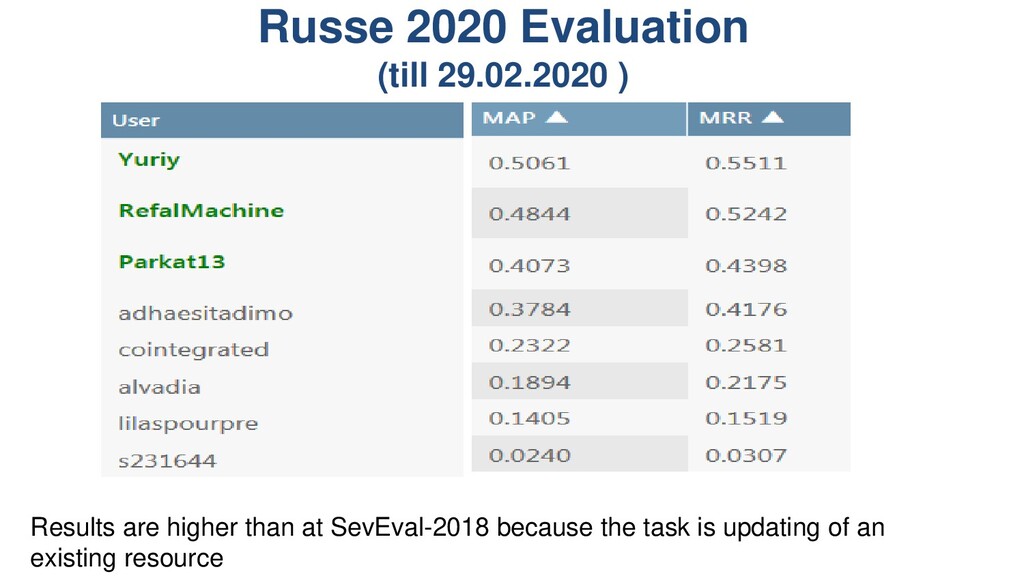
(Loukachevitch, 2019) – 110 thousand Russian words and expressions • New version of RuWordNet – 130 thousand Russian words and expressions is prepared but not published • Evaluation task – For new words (noun and verbs) to predict the nearest synsets from the published version – Correct answers should indicate • Direct hypernyms if a new word created a new synset • One-step hypernyms higher in hierarchy
in NLP applications • Capabilities of current automatic approaches (including neural networks) to extract specific lexical relations are relatively low – Even for most frequent relations (synonyms, hypernyms) • Combined approaches can be useful in various applications – Including the reuse of existing resources – Tuning them in domain-specific text collections – Semi-automatic approaches
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}