Bordes, A. (2014). Memory networks. arXiv preprint arXiv:1410.3916. • Pritzel, Alexander, et al. "Neural episodic control." Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017. • Graves, Alex, et al. "Hybrid computing using a neural network with dynamic external memory." Nature 538.7626 (2016): 471-476. • Wu, Yan, et al. "Learning attractor dynamics for generative memory." Advances in Neural Information Processing Systems. 2018. • Rae, Jack W., Sergey Bartunov, and Timothy P. Lillicrap. "Meta-learning neural bloom filters." arXiv preprint arXiv:1906.04304 (2019). • Du, Yilun, and Igor Mordatch. "Implicit generation and generalization in energy-based models." arXiv preprint arXiv:1903.08689 (2019). • Munkhdalai, Tsendsuren, et al. "Metalearned neural memory." Advances in Neural Information Processing Systems. 2019. • Miconi, Thomas, Jeff Clune, and Kenneth O. Stanley. "Differentiable plasticity: training plastic neural networks with backpropagation." arXiv preprint arXiv:1804.02464 (2018). • Rae, J. W., Potapenko, A., Jayakumar, S. M., & Lillicrap, T. P. (2019). Compressive Transformers for Long-Range Sequence Modelling. arXiv preprint arXiv:1911.05507.
{kind=link}
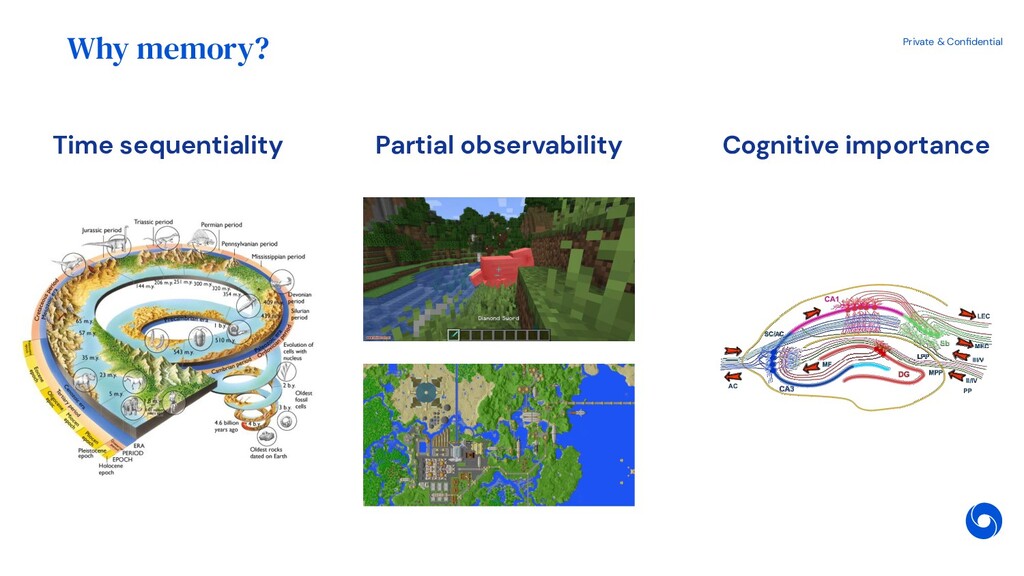{kind=link}
{kind=link}
{kind=link}
{kind=link}
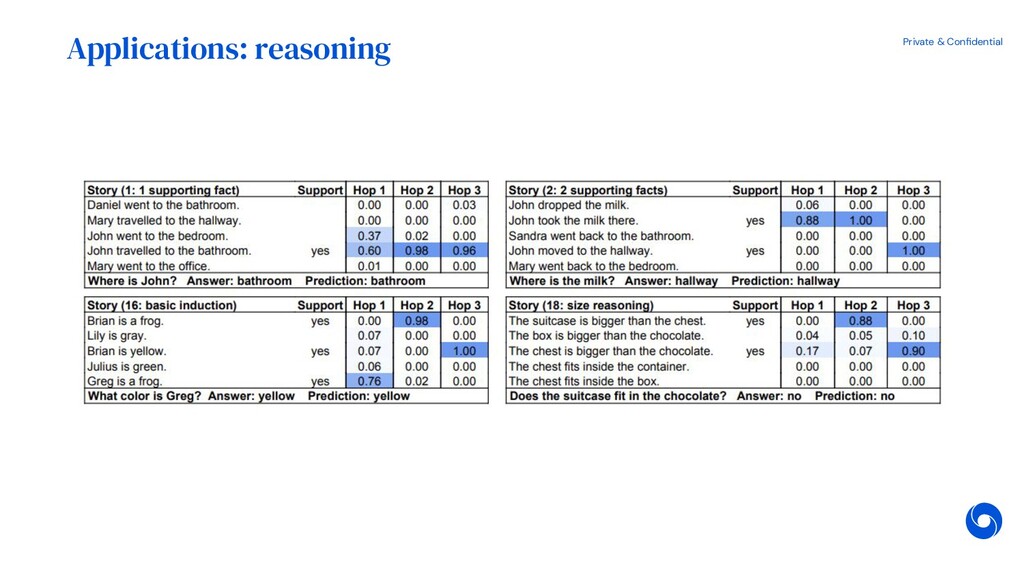{kind=link}
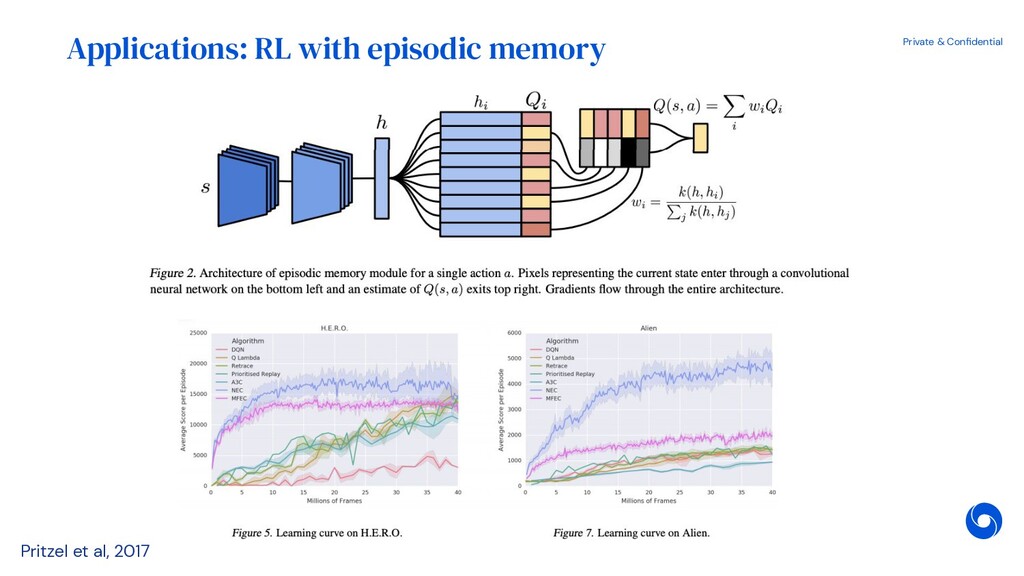{kind=link}
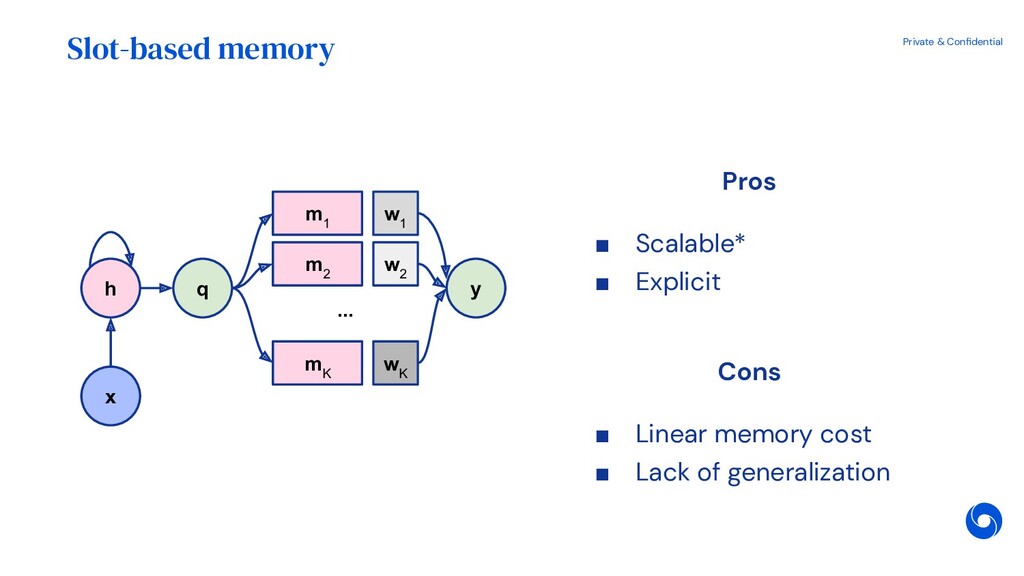{kind=link}
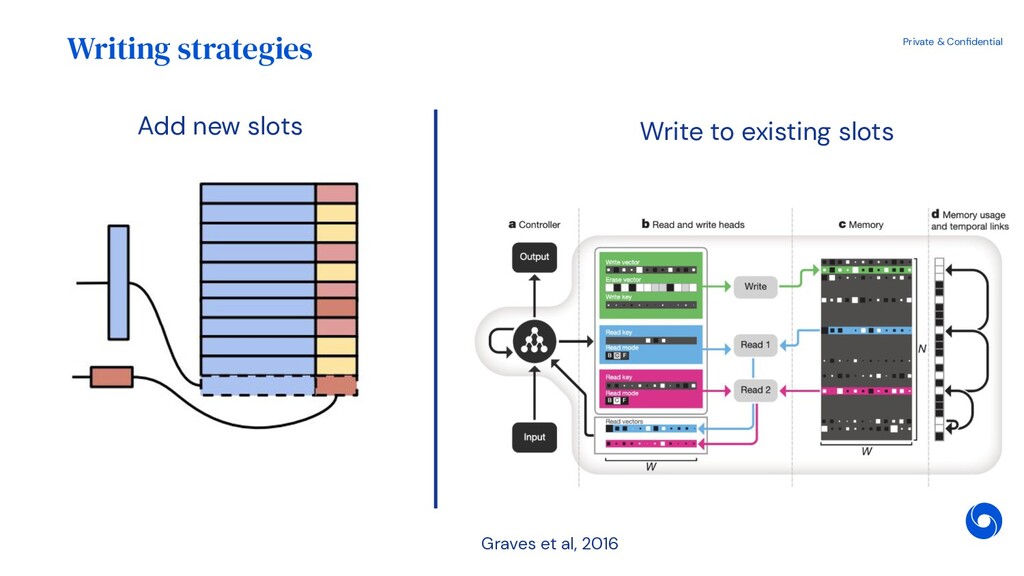{kind=link}
{kind=link}
{kind=link}
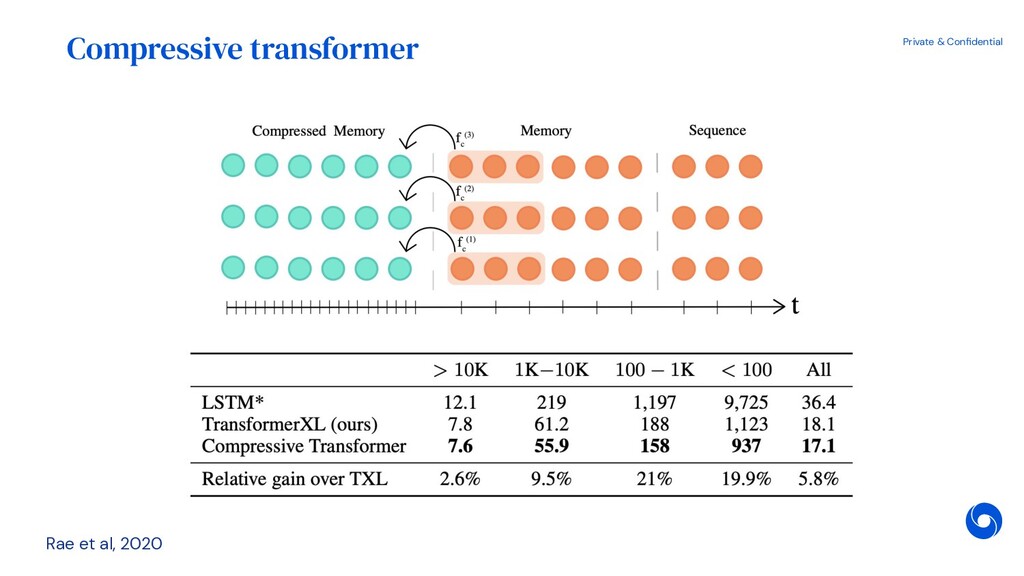{kind=link}
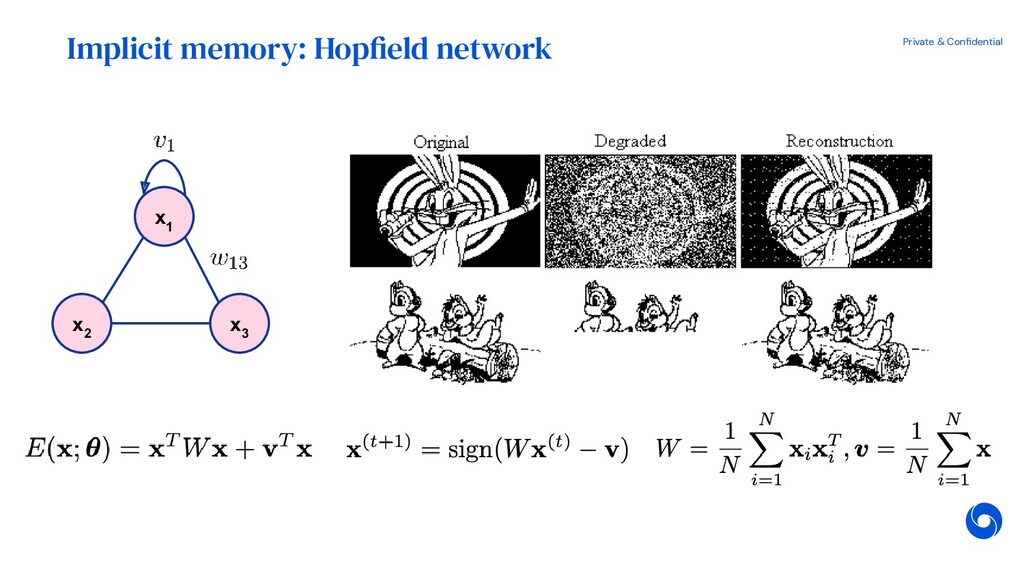{kind=link}
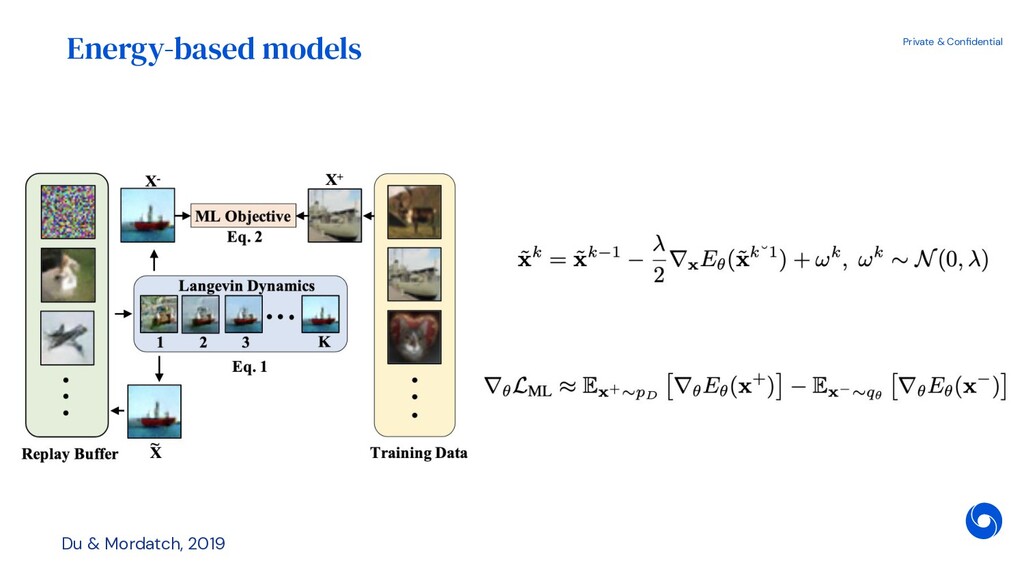{kind=link}
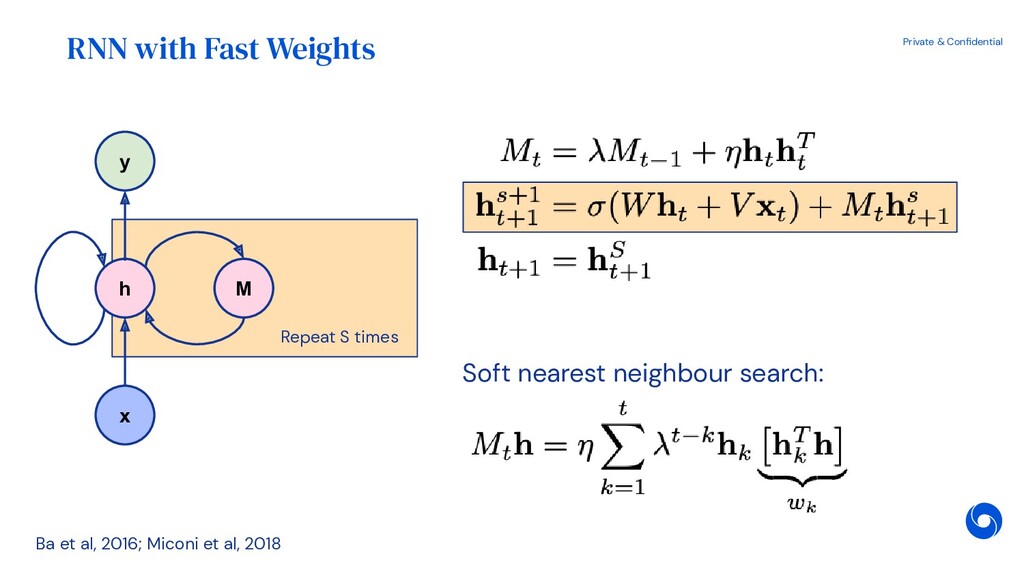{kind=link}
{kind=link}
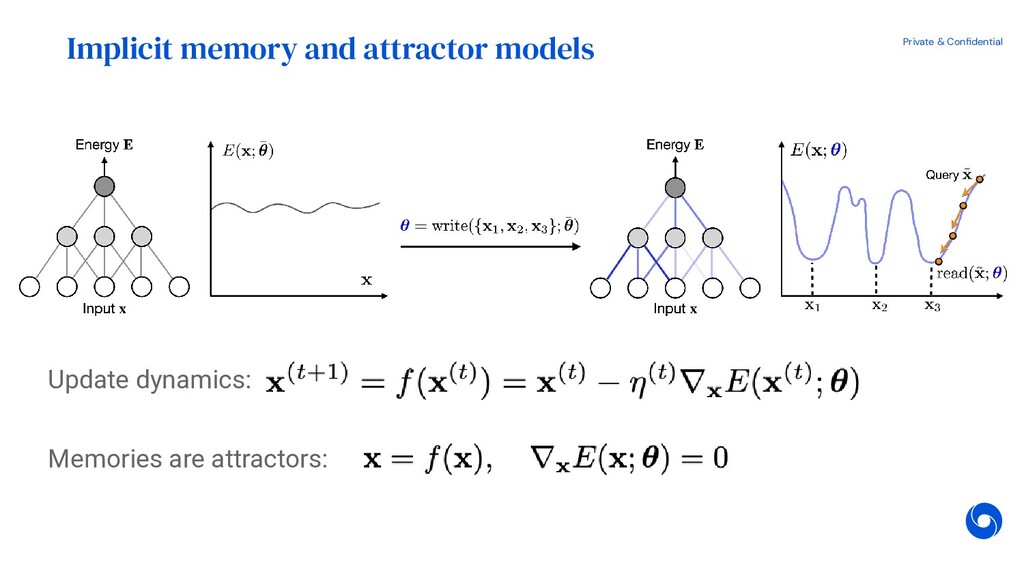{kind=link}
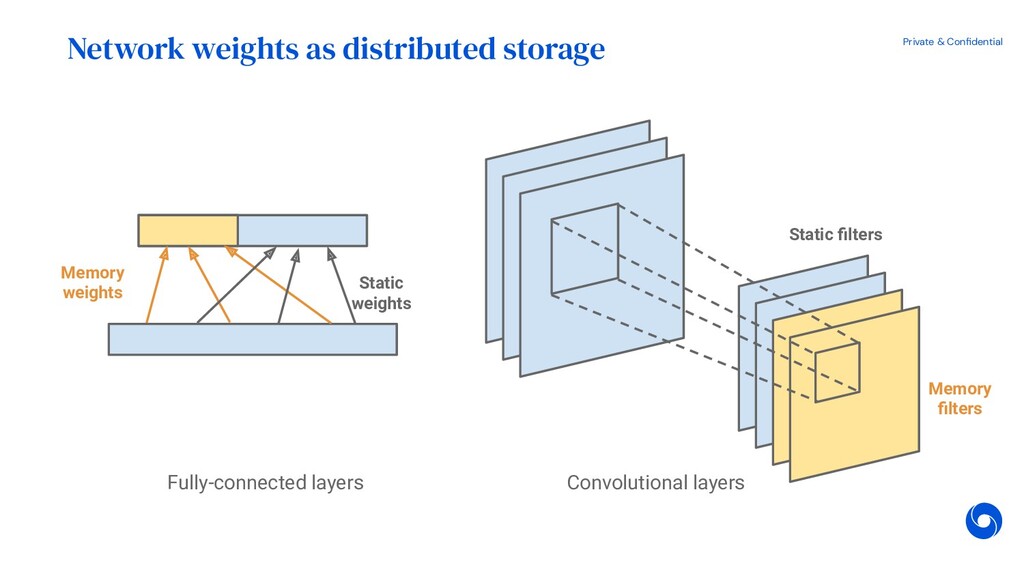{kind=link}
{kind=link}
{kind=link}
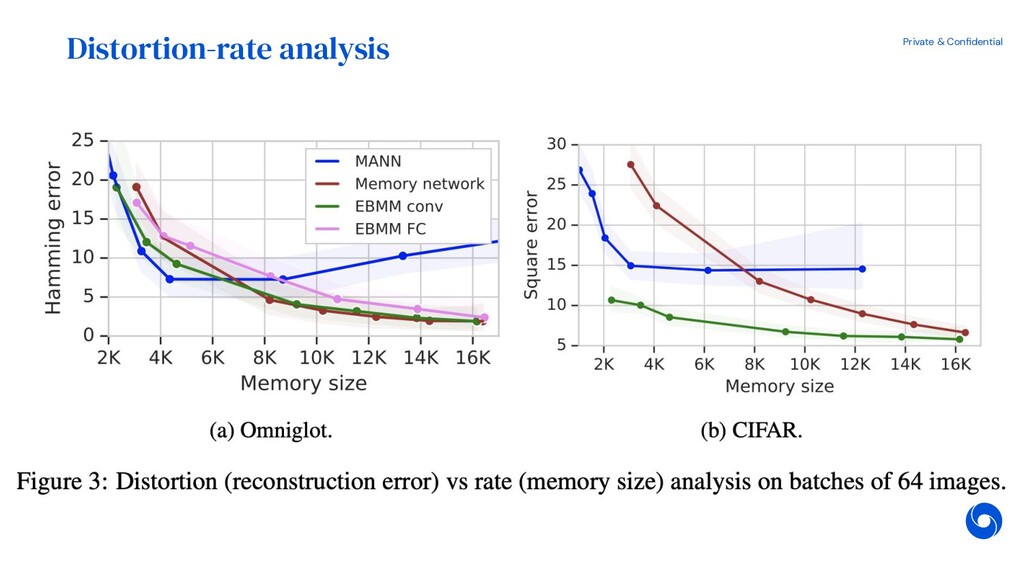{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}