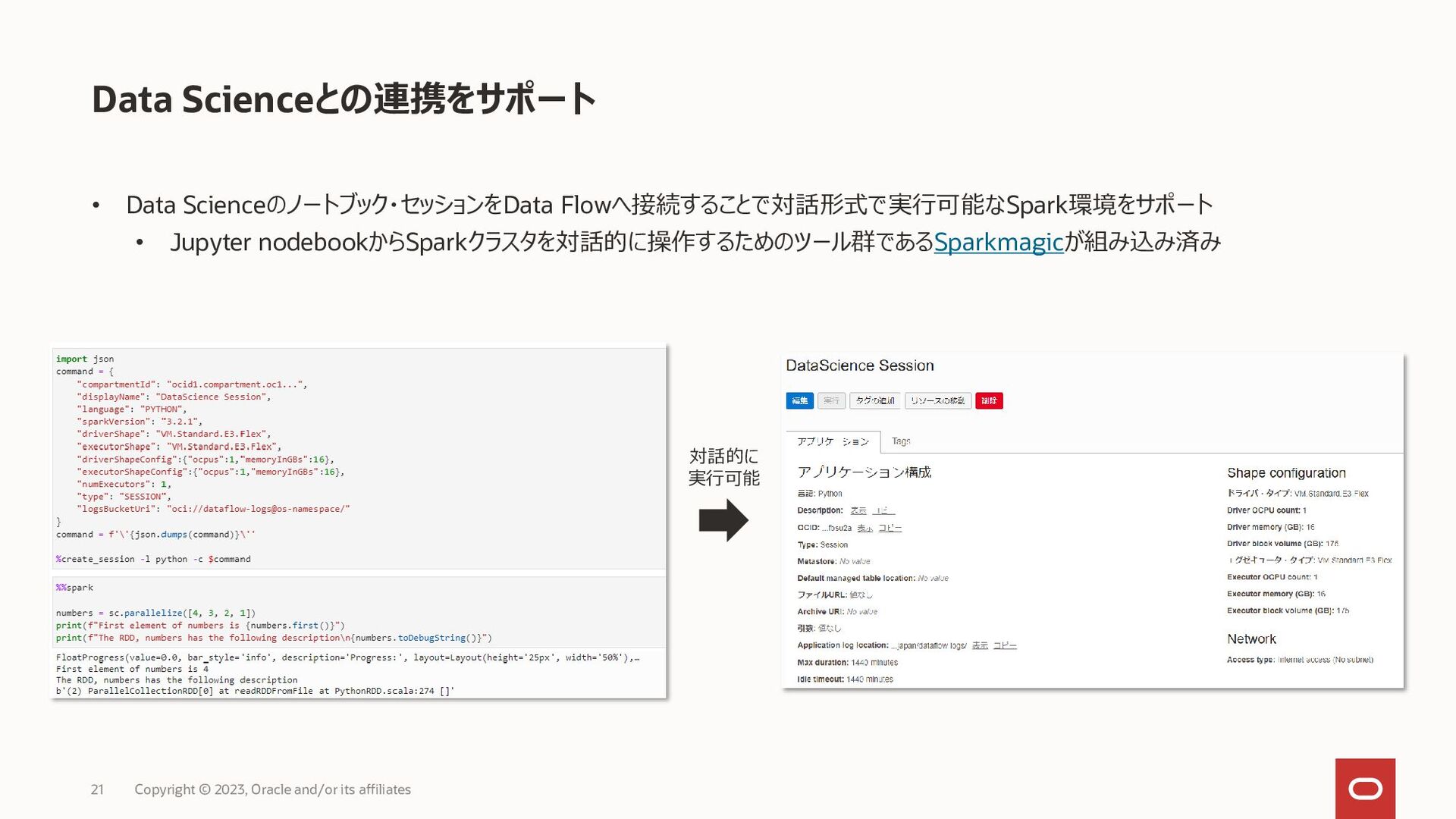
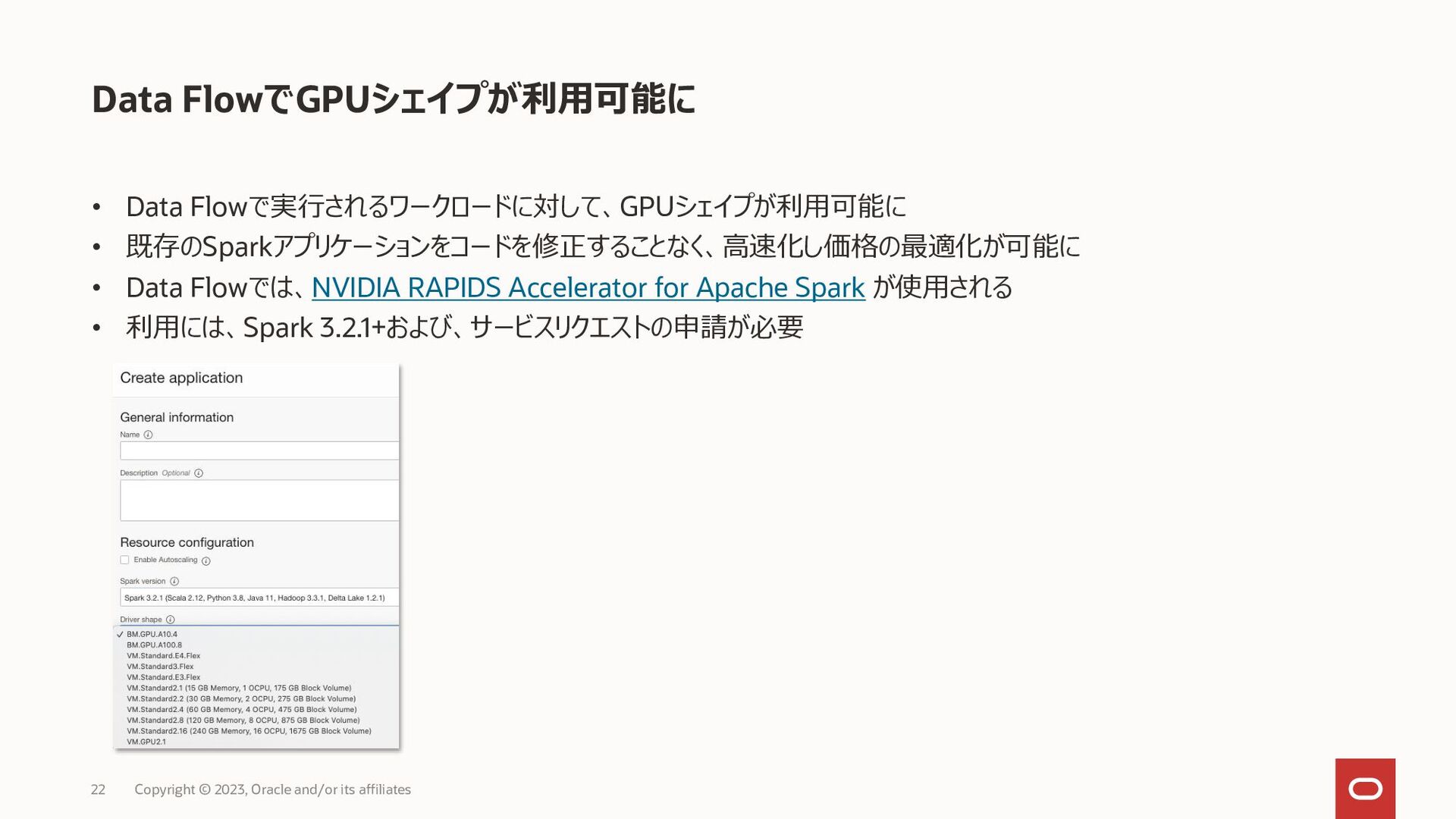
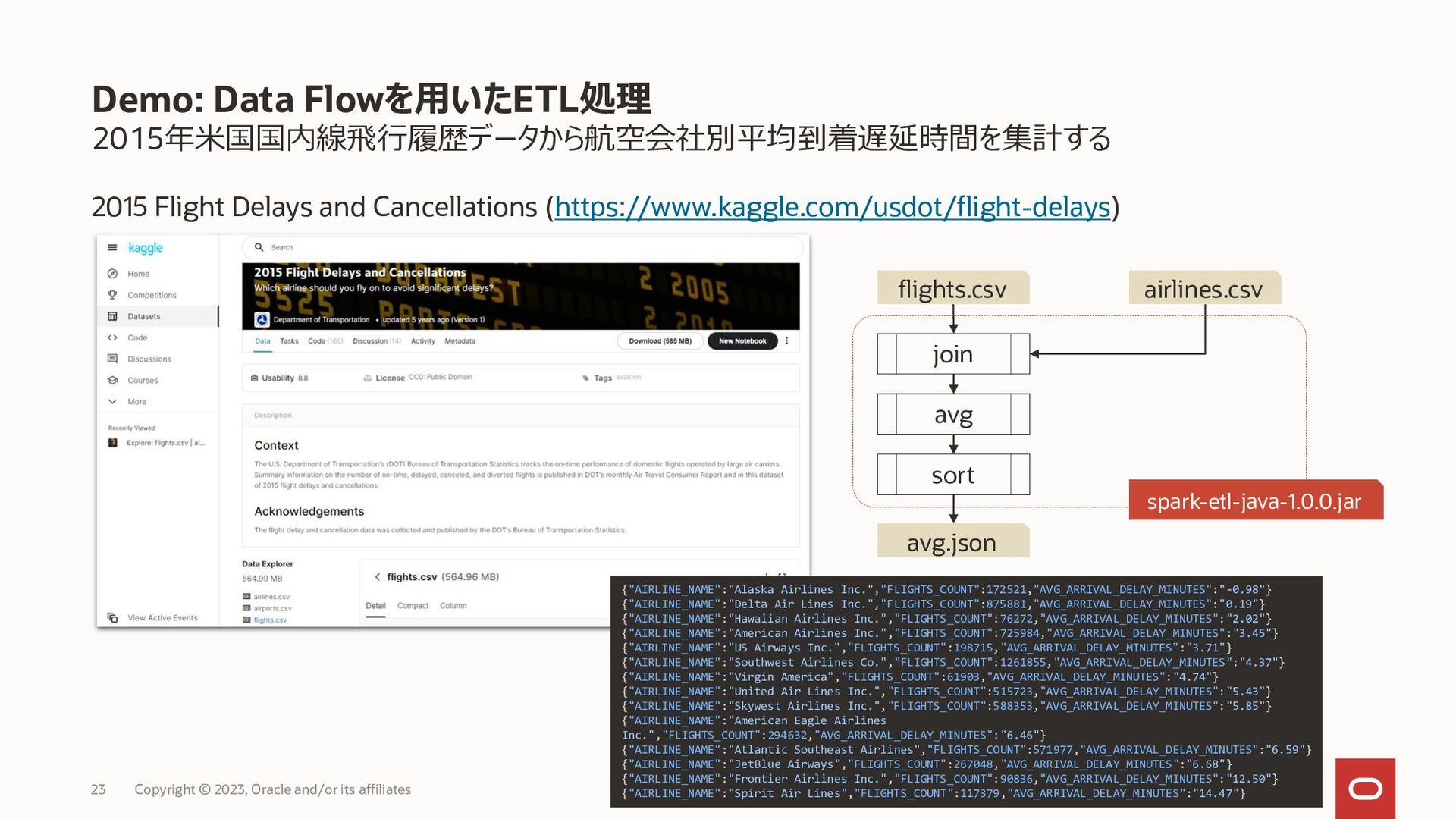
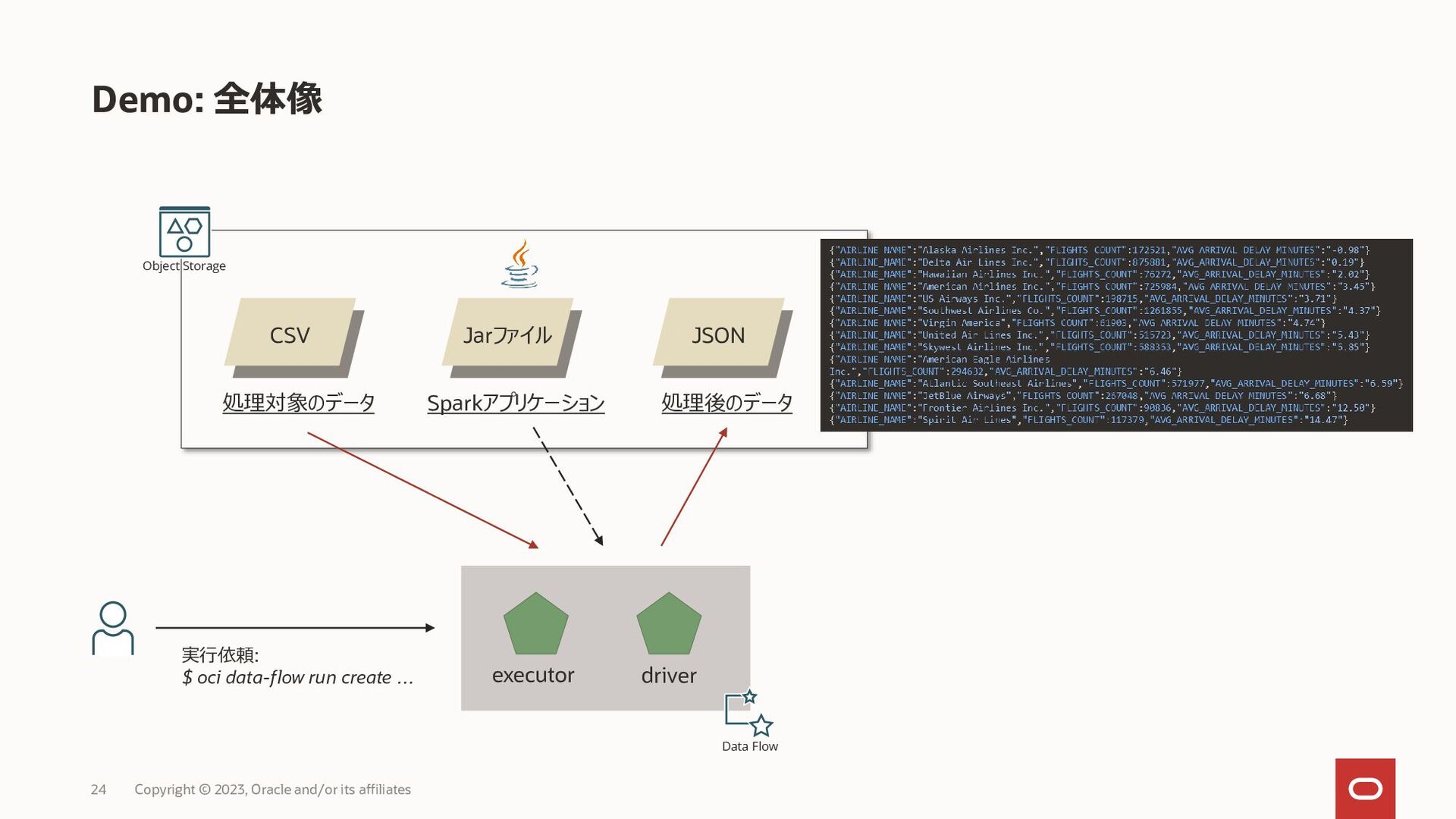
Copyright © 2023, Oracle and/or its affiliates 23 join avg sort avg.json spark-etl-java-1.0.0.jar flights.csv airlines.csv {"AIRLINE_NAME":"Alaska Airlines Inc.","FLIGHTS_COUNT":172521,"AVG_ARRIVAL_DELAY_MINUTES":"-0.98"} {"AIRLINE_NAME":"Delta Air Lines Inc.","FLIGHTS_COUNT":875881,"AVG_ARRIVAL_DELAY_MINUTES":"0.19"} {"AIRLINE_NAME":"Hawaiian Airlines Inc.","FLIGHTS_COUNT":76272,"AVG_ARRIVAL_DELAY_MINUTES":"2.02"} {"AIRLINE_NAME":"American Airlines Inc.","FLIGHTS_COUNT":725984,"AVG_ARRIVAL_DELAY_MINUTES":"3.45"} {"AIRLINE_NAME":"US Airways Inc.","FLIGHTS_COUNT":198715,"AVG_ARRIVAL_DELAY_MINUTES":"3.71"} {"AIRLINE_NAME":"Southwest Airlines Co.","FLIGHTS_COUNT":1261855,"AVG_ARRIVAL_DELAY_MINUTES":"4.37"} {"AIRLINE_NAME":"Virgin America","FLIGHTS_COUNT":61903,"AVG_ARRIVAL_DELAY_MINUTES":"4.74"} {"AIRLINE_NAME":"United Air Lines Inc.","FLIGHTS_COUNT":515723,"AVG_ARRIVAL_DELAY_MINUTES":"5.43"} {"AIRLINE_NAME":"Skywest Airlines Inc.","FLIGHTS_COUNT":588353,"AVG_ARRIVAL_DELAY_MINUTES":"5.85"} {"AIRLINE_NAME":"American Eagle Airlines Inc.","FLIGHTS_COUNT":294632,"AVG_ARRIVAL_DELAY_MINUTES":"6.46"} {"AIRLINE_NAME":"Atlantic Southeast Airlines","FLIGHTS_COUNT":571977,"AVG_ARRIVAL_DELAY_MINUTES":"6.59"} {"AIRLINE_NAME":"JetBlue Airways","FLIGHTS_COUNT":267048,"AVG_ARRIVAL_DELAY_MINUTES":"6.68"} {"AIRLINE_NAME":"Frontier Airlines Inc.","FLIGHTS_COUNT":90836,"AVG_ARRIVAL_DELAY_MINUTES":"12.50"} {"AIRLINE_NAME":"Spirit Air Lines","FLIGHTS_COUNT":117379,"AVG_ARRIVAL_DELAY_MINUTES":"14.47"}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
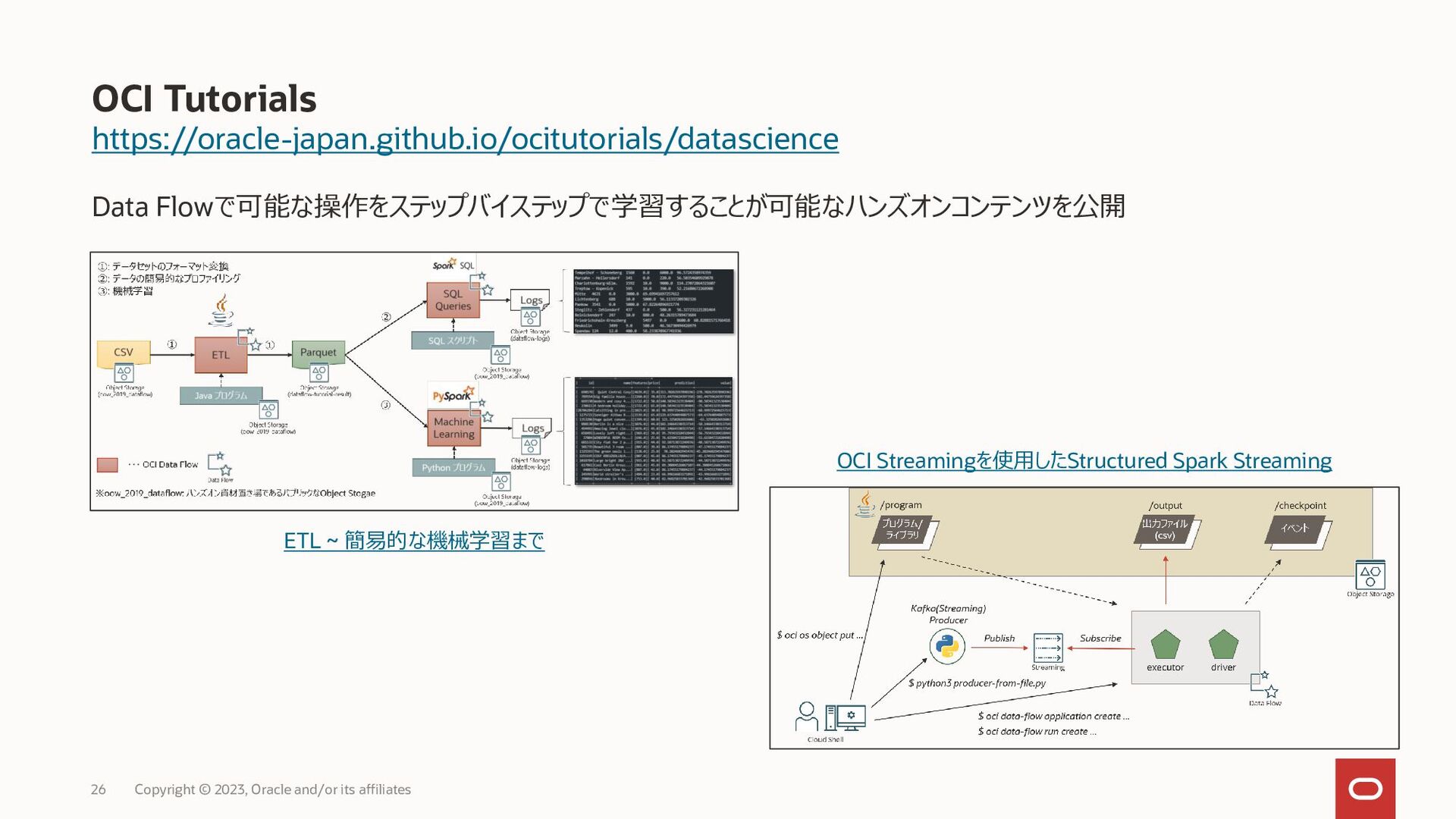{kind=link}