Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Oracle Cloud Infrastructure Data Science Service
Search
oracle4engineer
PRO
May 31, 2022
Technology
1.6k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Oracle Cloud Infrastructure Data Science Service
2020年2月リリース OCI Data Science Service技術概要資料
oracle4engineer
PRO
May 31, 2022
More Decks by oracle4engineer
See All by oracle4engineer
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
Deep Data Security 機能解説
oracle4engineer
PRO
2
280
Oracle Cloud Infrastructure:2026年6月度サービス・アップデート
oracle4engineer
PRO
1
530
Oracle AI Databaseデータベース・サービスのメンテナンス(BaseDB/ExaDB-D/ExaDB-XS)
oracle4engineer
PRO
4
1.9k
Oracle AI Database@Google Cloud:サービス概要のご紹介
oracle4engineer
PRO
6
1.6k
Oracle AI Database@Azure:サービス概要のご紹介
oracle4engineer
PRO
6
2.1k
Oracle AI Database@AWS:サービス概要のご紹介
oracle4engineer
PRO
4
3.1k
CrossplaneによるCloud Native Control Plane
oracle4engineer
PRO
0
120
OCI Oracle AI Database Services新機能アップデート(2026/03-2026/05)
oracle4engineer
PRO
1
660
Other Decks in Technology
See All in Technology
AI時代のエンジニアキャリアについて今一度考える
sakamoto_582
2
1.3k
AI Agent SaaS を支える自社仮想化基盤への挑戦と実運用 / ai-agent-saas-virtualization
flatt_security
2
3k
GuardrailからGovernanceへ~AIエージェント運用の次の課題~
sbspsy
1
220
認証認可だけじゃない! ID管理の構成要素と ライフサイクルを意識しよう
ritou
1
520
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
2.8k
完全自律ロボットを作りたくて、先に開発を自律させた話(ROS Japan UG #63 LT)
rryz09
0
420
事業価値を⽣み出すSREへ SREが担うべき意思決定の5層
kenta_hi
2
2.2k
最適な自走を最小限の支援で — M&Aで拡大する組織で少人数SREが挑んだ1年 / SRE NEXT 2026
genda
0
360
インフラ寄りSREでも 開発に踏み出せる〜境界を越えてユーザー体験に向き合いたい〜
sansantech
PRO
1
2.6k
はじめてのWDM
miyukichi_ospf
1
120
ローカルLLMとLINE Botの組み合わせ その3 / LINE DC Generative AI Meetup #8
you
PRO
0
120
AWS Summit の片隅で、体育座りしながらコミュニティがにぎわう理由を考えた
k_adachi_01
2
360
Featured
See All Featured
Building a Scalable Design System with Sketch
lauravandoore
463
34k
Designing for Timeless Needs
cassininazir
1
280
A designer walks into a library…
pauljervisheath
211
24k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
560
Game over? The fight for quality and originality in the time of robots
wayneb77
1
220
Context Engineering - Making Every Token Count
addyosmani
9
1k
Agile that works and the tools we love
rasmusluckow
331
22k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
The Spectacular Lies of Maps
axbom
PRO
1
850
Color Theory Basics | Prateek | Gurzu
gurzu
0
380
Darren the Foodie - Storyboard
khoart
PRO
3
3.4k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Transcript
Oracle Cloud Infrastructure Data Science Service 製品概要 日本オラクル株式会社
一般的な機械学習環境 2022/5/31 Copyright © 2022, Oracle and/or its affiliates 2
Operating System MLライブラリ群 etc. Server HW CPU Server HW GPU 様々なPythonライ ブラリを自由にイン ストール データロード データ変換 モデル学習 モデル評価 モデル解釈 etc. 機械学習のワークフロー データ レイク DWH IoT オープン データ ... ... コーディング • Pythonでの開発環境(機械学習ツール のデファクト) • Pythonの多種多様なライブラリをユー ザー自由にインストールし、開発環境を 構築(古典的なライブラリから最先端のラ イブラリまで) • ノートブック(Jupyterなど)でコーディング ベースの機械学習ワークフロー • 汎用サーバーでCPUやGPUを利用 • データレイク、DWH、IoT、オープンデータ などの外部データが学習データのソース
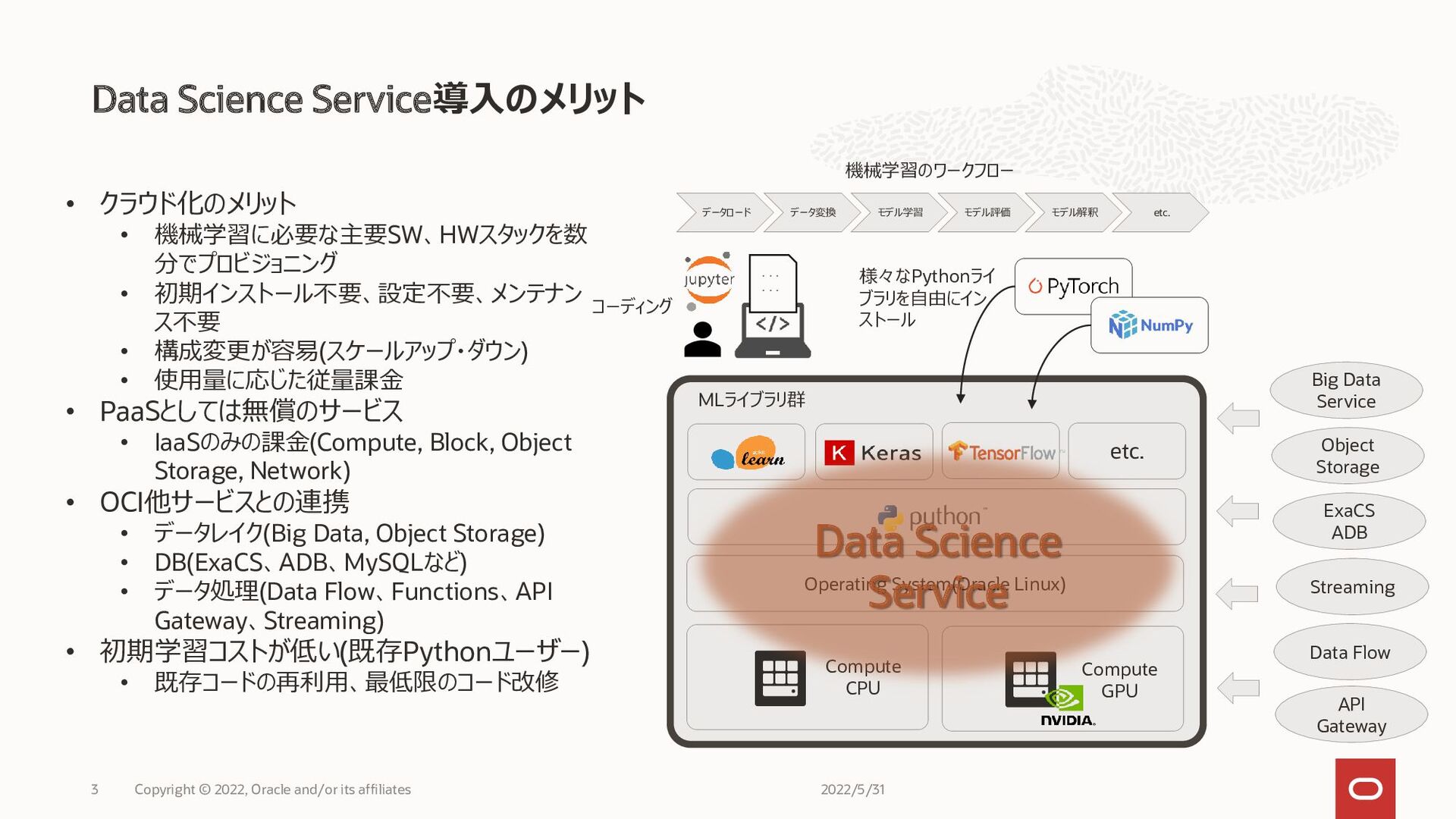
Data Science Service導入のメリット 2022/5/31 Copyright © 2022, Oracle and/or its
affiliates 3 Operating System(Oracle Linux) MLライブラリ群 etc. Compute CPU Compute GPU データロード データ変換 モデル学習 モデル評価 モデル解釈 etc. 機械学習のワークフロー Big Data Service Object Storage Data Flow API Gateway ExaCS ADB 様々なPythonライ ブラリを自由にイン ストール ... ... コーディング • クラウド化のメリット • 機械学習に必要な主要SW、HWスタックを数 分でプロビジョニング • 初期インストール不要、設定不要、メンテナン ス不要 • 構成変更が容易(スケールアップ・ダウン) • 使用量に応じた従量課金 • PaaSとしては無償のサービス • IaaSのみの課金(Compute, Block, Object Storage, Network) • OCI他サービスとの連携 • データレイク(Big Data, Object Storage) • DB(ExaCS、ADB、MySQLなど) • データ処理(Data Flow、Functions、API Gateway、Streaming) • 初期学習コストが低い(既存Pythonユーザー) • 既存コードの再利用、最低限のコード改修 Streaming Data Science Service
• プロジェクト • 全てのリソースを保持する共同ワークスペース • Notebookセッション • モデルを構築、学習するためのコーディング環境 • Jupyter
Notebook、MLライブラリ群がプリインス トールされたComputeインスタンス • 作成時にCompartment、VCN、Subnet、 Computeシェイプ、Block Volumeの容量を指定 • MLライブラリ • Keras、Tensor Flow • scikit-learn • XGBoost • Oracle Accelerated Data Science(ADS) • モデルカタログ • 構築したモデルを登録、共有するストレージ領域 Data Science Serviceのコンポーネント 2022/5/31 Copyright © 2022, Oracle and/or its affiliates 4 Accelerated Data Science scikit-learn MLライブラリ Jupyter Notebook Notebootセッション Compute Block Storage プロジェクト モデルカタログ モデル モデル 分析チーム インフラ担当 アプリ開発担当 データサイエンティスト ビジネスユーザー ノウハウ、リソースの共有共同開発
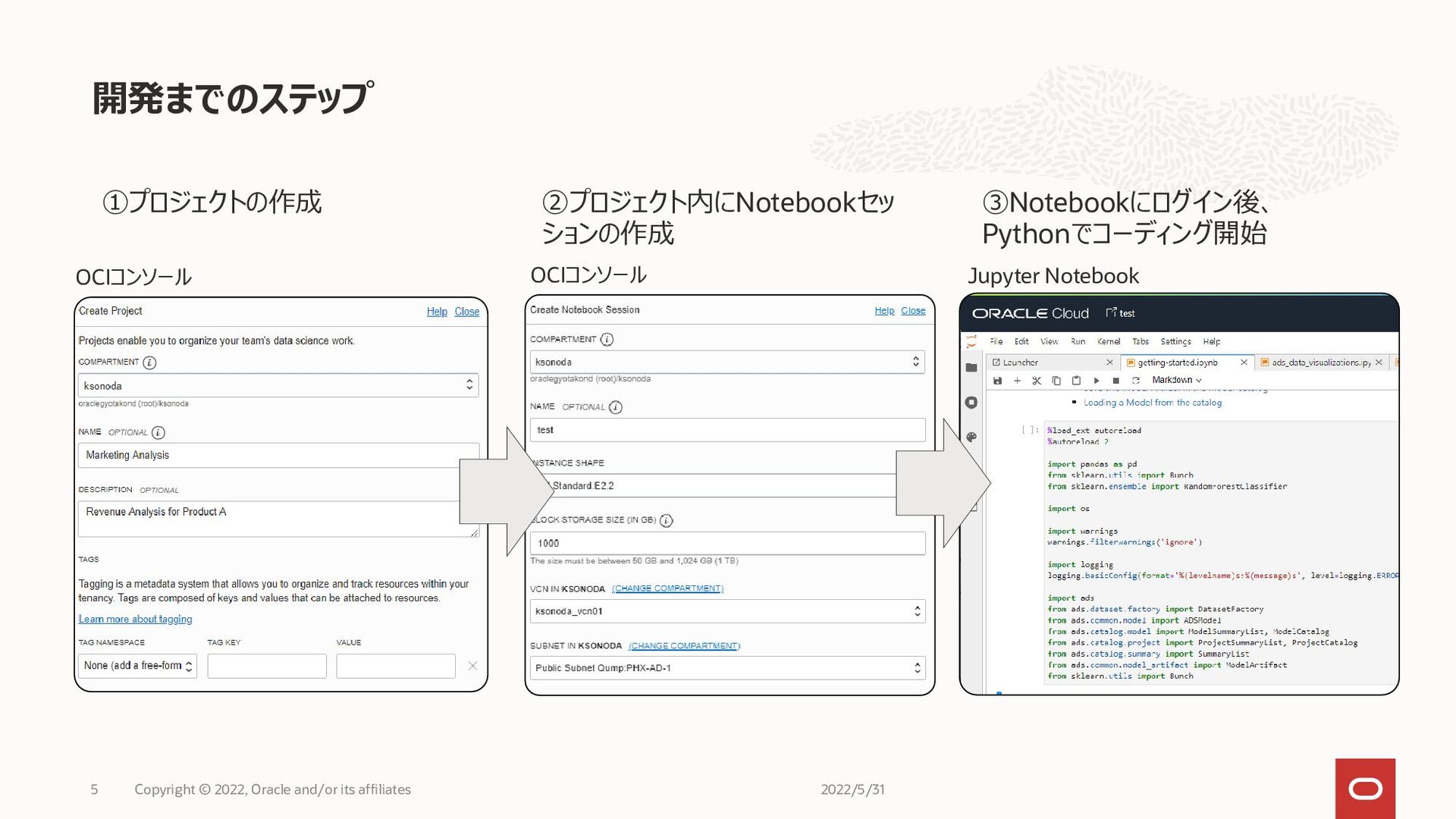
開発までのステップ 2022/5/31 Copyright © 2022, Oracle and/or its affiliates 5
③Notebookにログイン後、 Pythonでコーディング開始 ②プロジェクト内にNotebookセッ ションの作成 ①プロジェクトの作成 OCIコンソール OCIコンソール Jupyter Notebook
• Oracle Cloud Infrastructure Data Scienceの一 部として機能するPythonライブラリ • 機械学習のライフサイクル全てのフェーズで使いやすく シンプルなAPI
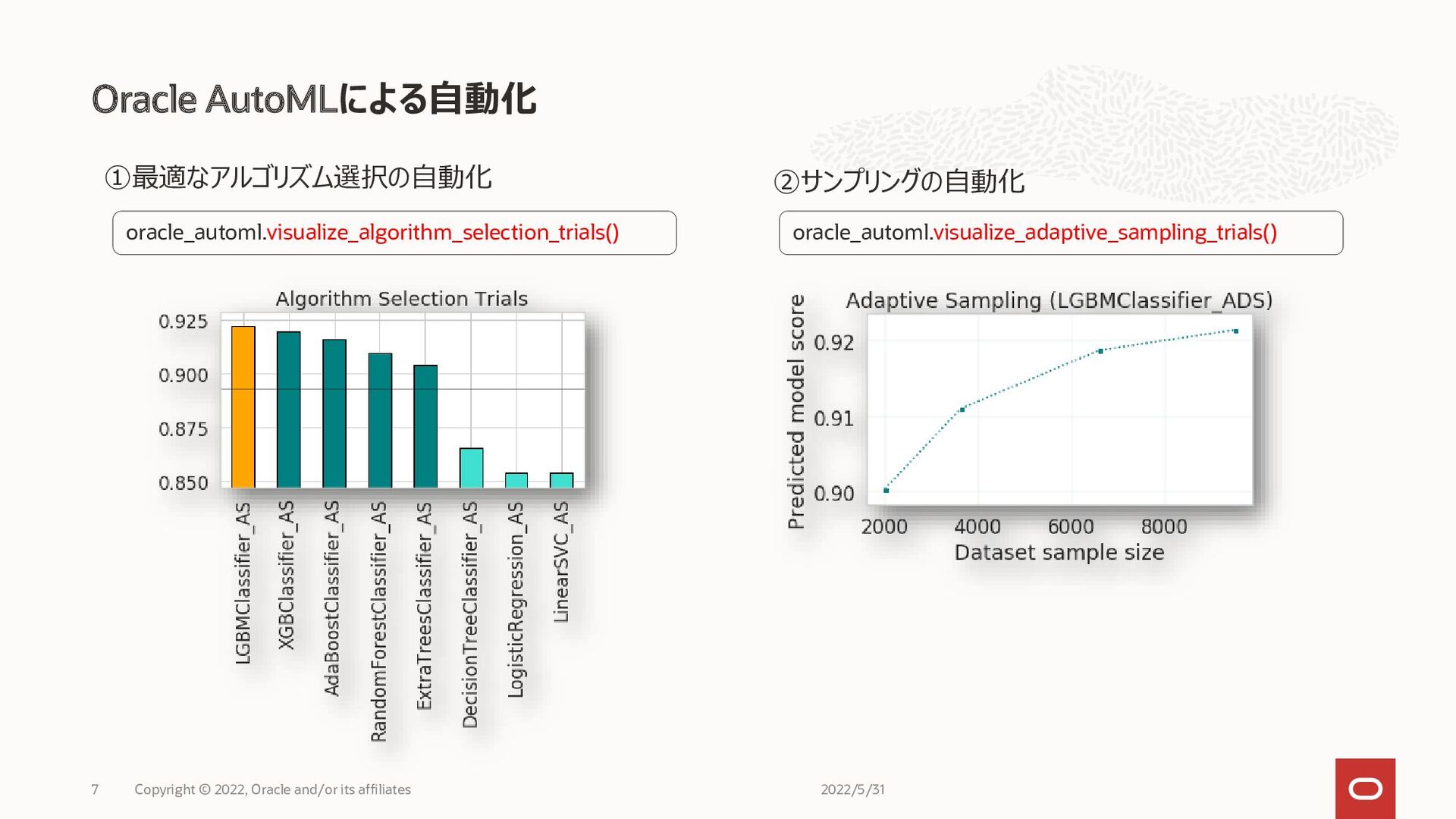
• OCIのその他のサービスおよび他社サービス(Amazon S3、Google Cloud Storage、Azure Blob)との連 携API • Oracle AutoML 1. 最適なアルゴリズム選択の自動化 2. データのサンプリングの自動化 3. 最適な特徴量選択の自動化 4. ハイパーパラメータ・チューニングの自動化 Oracle Accelerated Data Science(ADS) 2022/5/31 Copyright © 2022, Oracle and/or its affiliates 6 機械学習のワークフロー Confidential – © 2020 Oracle Internal ⑥モデルの 解釈 ②データの 変換 ①データの ロード ⑤モデルの 評価 ③データの 可視化 ④モデルの 学習 Accelerated data Science AutoML
Oracle AutoMLによる自動化 2022/5/31 Copyright © 2022, Oracle and/or its affiliates
7 ①最適なアルゴリズム選択の自動化 ②サンプリングの自動化 oracle_automl.visualize_algorithm_selection_trials() oracle_automl.visualize_adaptive_sampling_trials()
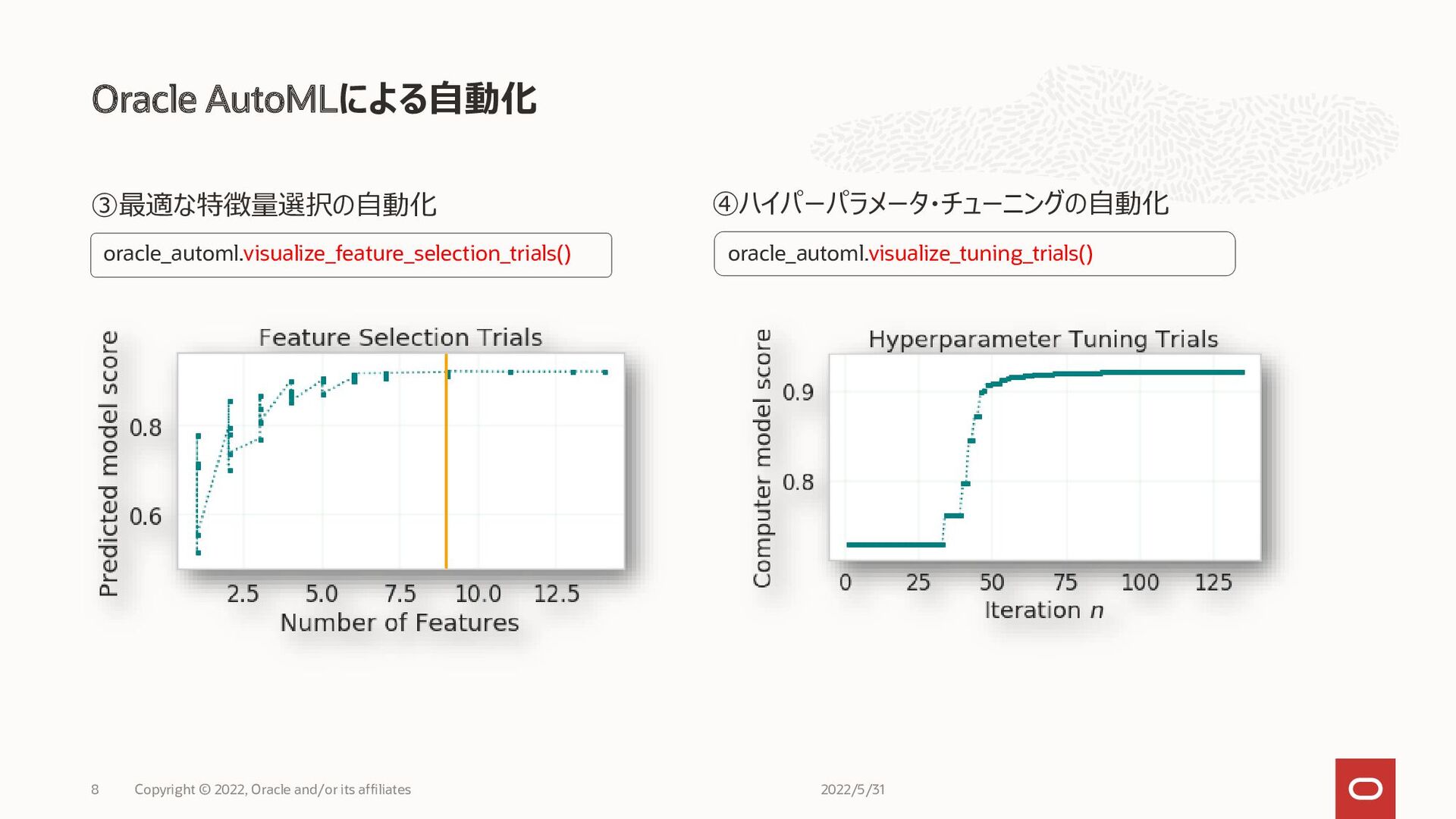
Oracle AutoMLによる自動化 2022/5/31 Copyright © 2022, Oracle and/or its affiliates
8 ③最適な特徴量選択の自動化 ④ハイパーパラメータ・チューニングの自動化 oracle_automl.visualize_feature_selection_trials() oracle_automl.visualize_tuning_trials()
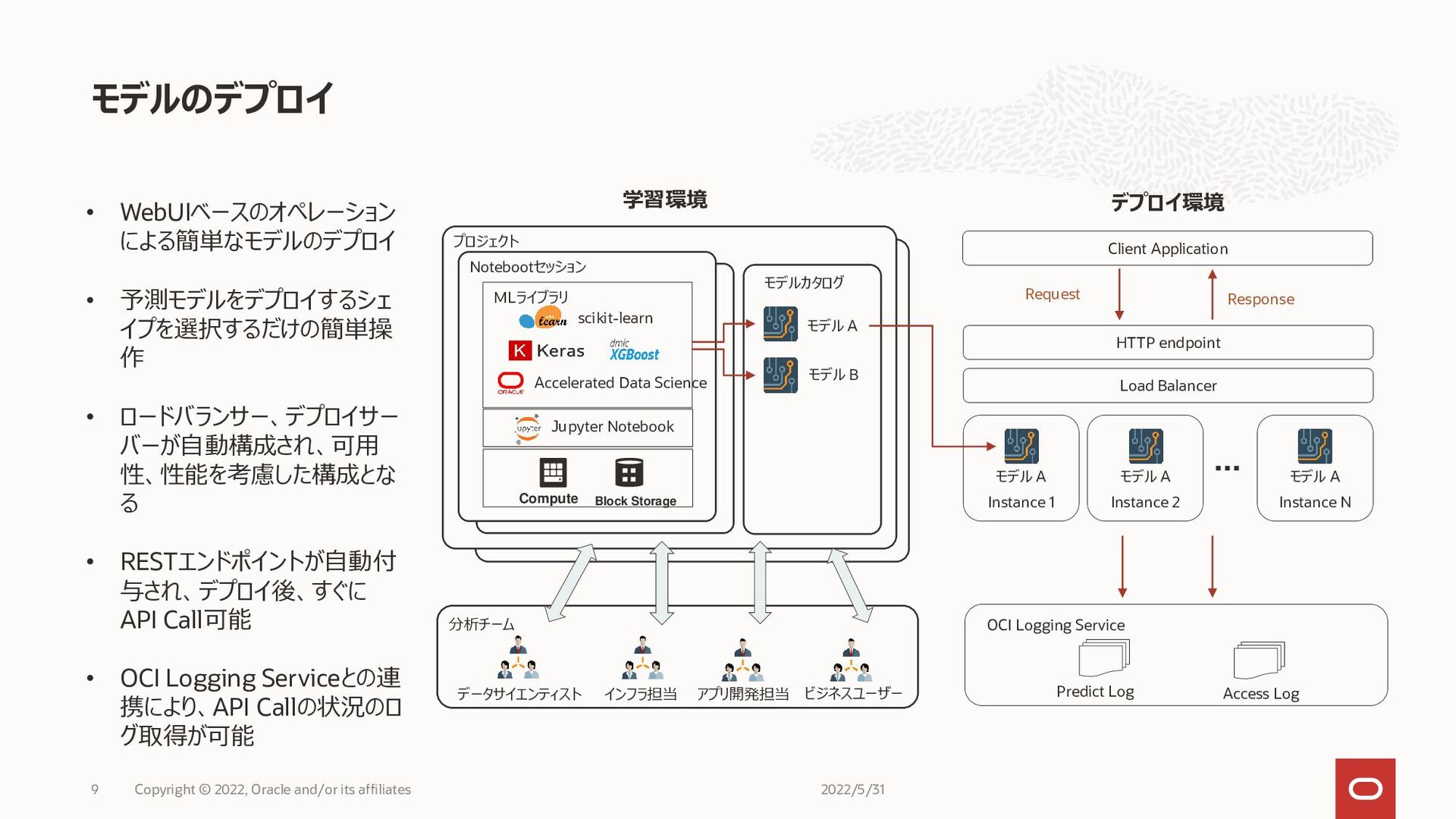
モデルのデプロイ 2022/5/31 Copyright © 2022, Oracle and/or its affiliates 9
Accelerated Data Science scikit-learn MLライブラリ Jupyter Notebook Notebootセッション Compute Block Storage プロジェクト モデルカタログ モデル A モデル B 分析チーム インフラ担当 アプリ開発担当 データサイエンティスト ビジネスユーザー Instance 1 Instance 2 Instance N HTTP endpoint Load Balancer Client Application Predict Log Access Log OCI Logging Service モデル A モデル A モデル A Request Response • WebUIベースのオペレーション による簡単なモデルのデプロイ • 予測モデルをデプロイするシェ イプを選択するだけの簡単操 作 • ロードバランサー、デプロイサー バーが自動構成され、可用 性、性能を考慮した構成とな る • RESTエンドポイントが自動付 与され、デプロイ後、すぐに API Call可能 • OCI Logging Serviceとの連 携により、API Callの状況のロ グ取得が可能 学習環境 デプロイ環境
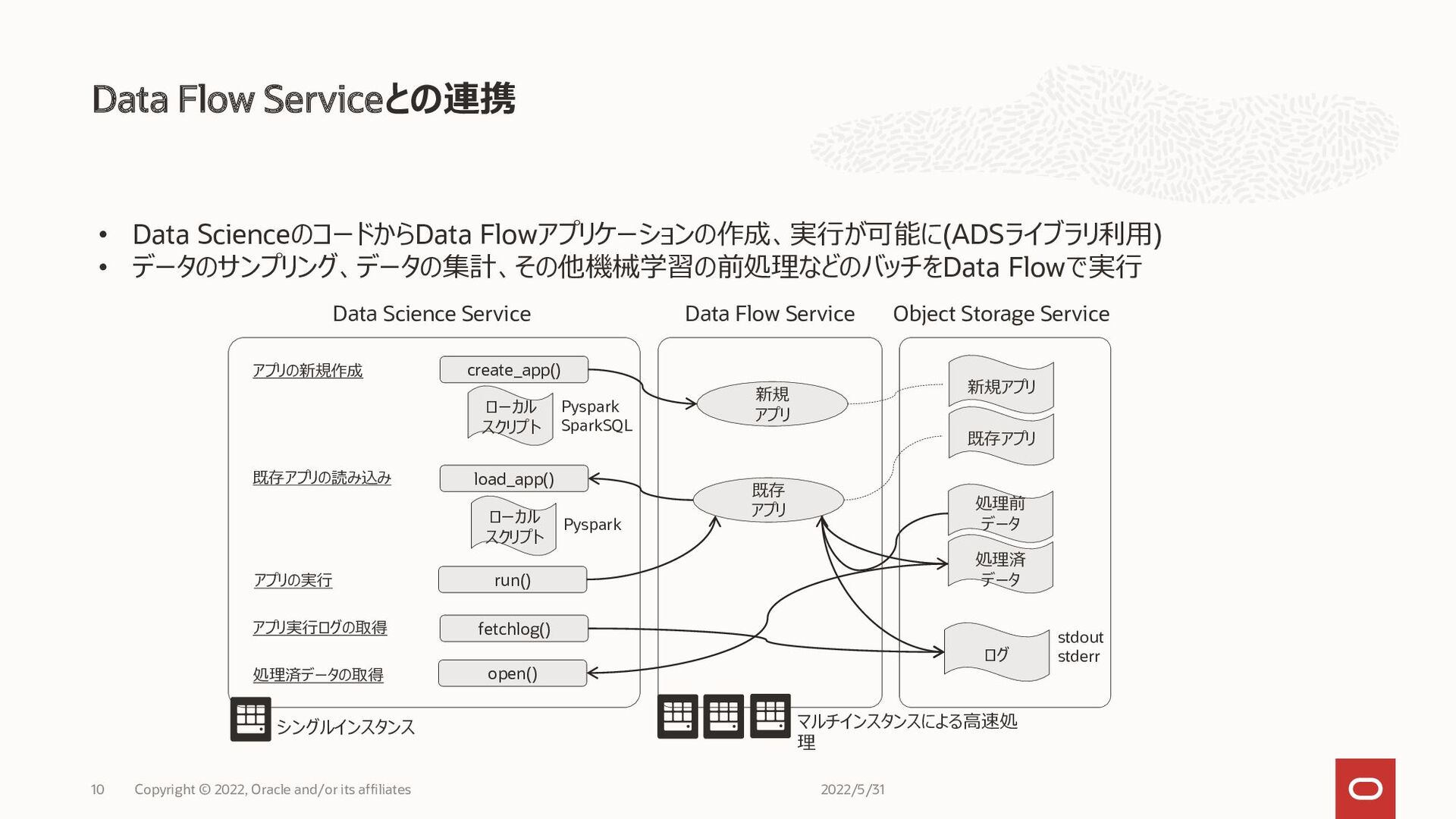
Data Flow Serviceとの連携 Copyright © 2022, Oracle and/or its affiliates
10 • Data ScienceのコードからData Flowアプリケーションの作成、実行が可能に(ADSライブラリ利用) • データのサンプリング、データの集計、その他機械学習の前処理などのバッチをData Flowで実行 Data Science Service Data Flow Service アプリの新規作成 アプリの実行 既存アプリの読み込み create_app() load_app() run() fetchlog() 新規 アプリ 既存 アプリ アプリ実行ログの取得 ローカル スクリプト ローカル スクリプト Pyspark SparkSQL Pyspark 処理済データの取得 open() Object Storage Service 新規アプリ 既存アプリ 処理前 データ 処理済 データ ログ stdout stderr シングルインスタンス マルチインスタンスによる高速処 理 2022/5/31
他サービスとの連携による分析基盤 Copyright © 2022, Oracle and/or its affiliates 11 インフラ担当
アプリ開発担当 データ サイエンティスト ビジネスユーザー Data Science Service Data Flow Service アプリの新規作成 アプリの実行 既存アプリの読み込み create_app() load_app() run() fetchlog() 新規 アプリ 既存 アプリ アプリ実行ログの取得 ローカル スクリプト ローカル スクリプト Pyspark SparkSQL Pyspark 処理済データの取得 open() Object Storage Service 新規アプリ 既存アプリ 処理前 データ 処理済 データ ログ stdout stderr シングルインスタンス マルチインスタンスによる高速処 理 ソーシャル データ クリックスト リーム システムロ グ センサー Streaming Service データレイク あらゆるデータをオブジェクトス トレージに安価に集約し、用 途に応じたデータ処理エンジ ンから利用する ETL データのサンプリング、データ の集計、その他機械学習 の前処理などをSparkバッ チで実行 データ分析、機械学習環境 ITOps、LOBユーザーがノウハウを集結し、 分析シナリオ、データ、構築済モデルなどを 共有しながら、チームとして分析プロジェクトを推進 メッセー ジング Data Science をデータ分析、機械学習環境、Data FlowをETL、オブジェクトストレージをデータレイク、Streamingを メッセージングシステムとして構成し、分析基盤を構築 2022/5/31
Data Labelingのデータセットの読み込み 2022/5/31 Copyright © 2022, Oracle and/or its affiliates
12 df = pd.DataFrame.ads.read_labeled_data( dataset_id = “<dataset_ocid>”, materialize = True ) dataset_id :Data Labelingで作成したデータセットのOCID materialized : Trueの場合、データフレーム作成時に実データを 読み込む。Falseの場合実データの読み込みは行わない。 Data Science Service AI Vision Service ⚫ Accelerated Data Science APIを利用 ⚫ オブジェクトストレージ上のデータセットのOCIDを指定し、 Pandasデータフレームにデータをロード ⚫ VisionのOCI Consoleからデータセットを選択
None
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}