that makes troubleshooting issues more dif fi • Is the invalid code a cause or a symptom? • Easy to miss real issues when there are many "expected" errors • Exceptions for "known" conditions can prevent alerts for real problems Invalid and orphaned objects www.viscosityna.com @ViscosityNA
Missing rollback/cleanup procedures • Developing/testing in production • In user schemas, often a sign of poor coding practices/cleanliness • May be accompanied by security issues (overprivileged users) • Endangers performance, stability, security of application data/code Causes of invalid objects www.viscosityna.com @ViscosityNA
for the database • The optimizer can't know data meets a condition w/o validated constraints • If a constraint is disabled, why? • Code failure: either the code or the rule is wrong • Prevented deletion: orphans are signs of broken relationships • The optimizer won't understand relationships • May lead to poor/wrong joins, index choices Disabled, not validated constraints www.viscosityna.com @ViscosityNA
for performance • Joining parent/child tables using the FK • Updating parent PK/deleting a parent record locks the child table • Exception: • Parent records are never deleted • The parent PK value never changes • Parent and child tables are never joined Foreign keys without indexes www.viscosityna.com @ViscosityNA
and make recommendations • When space in a disk block isn't optimized/maximized: • I/O increases (reads get empty space, not data) • Cached objects consume more space in buffer cache • Increase in Global Cache waits (more hot blocks) • Less ef fi Oversized and fragmented objects www.viscosityna.com @ViscosityNA
"mirrors" the key value • Reverse key indexes are not ordered & do not support: • Predicates using BETWEEN, LIKE, <, ≤, >, ≥ • Ordinary range scans • Useful for bypassing two very speci fi • Index block contention on right-leaning indexes • Sparsely populated indexes (fragmentation) caused by key deletion Reverse key indexes www.viscosityna.com @ViscosityNA
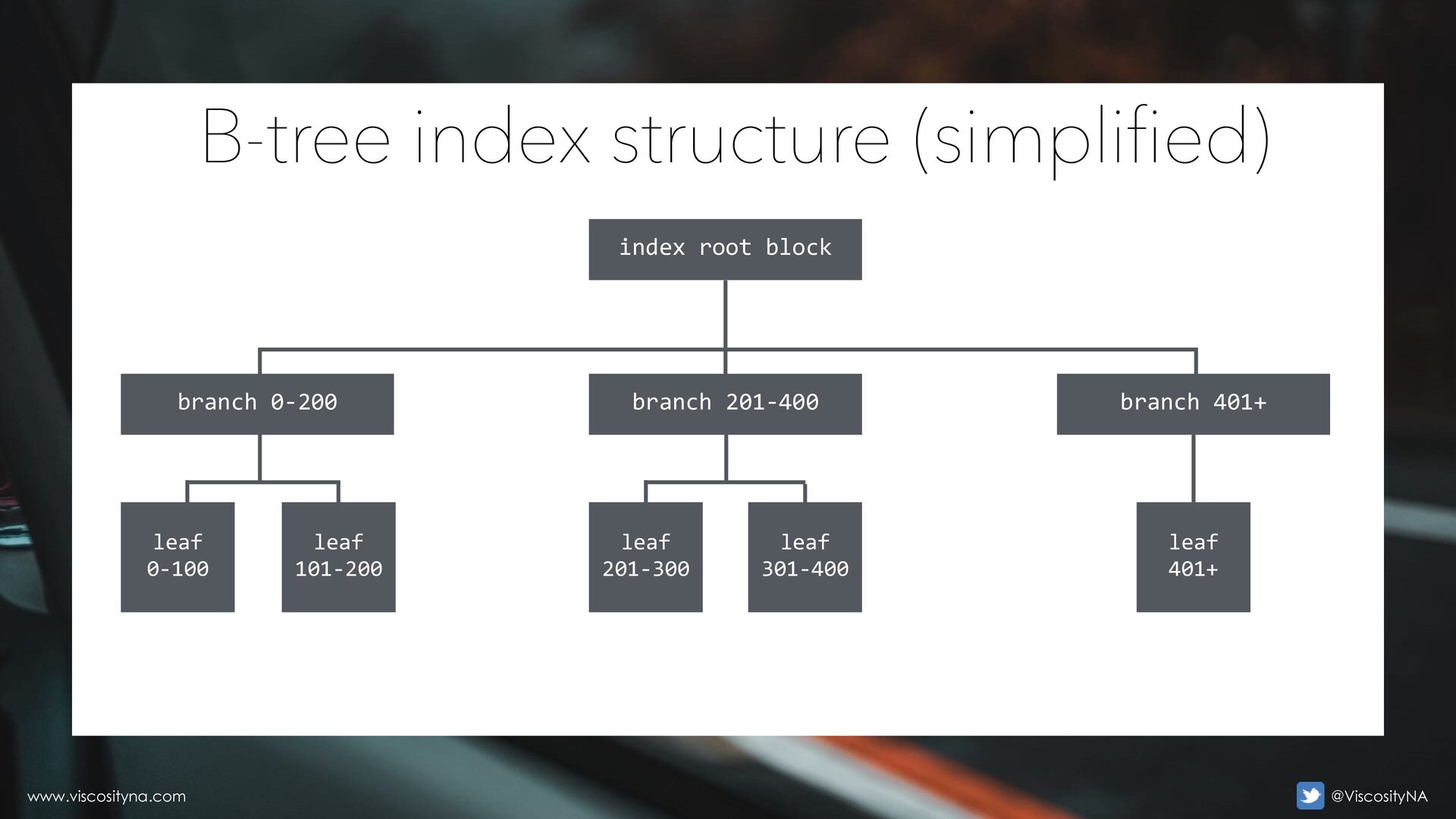
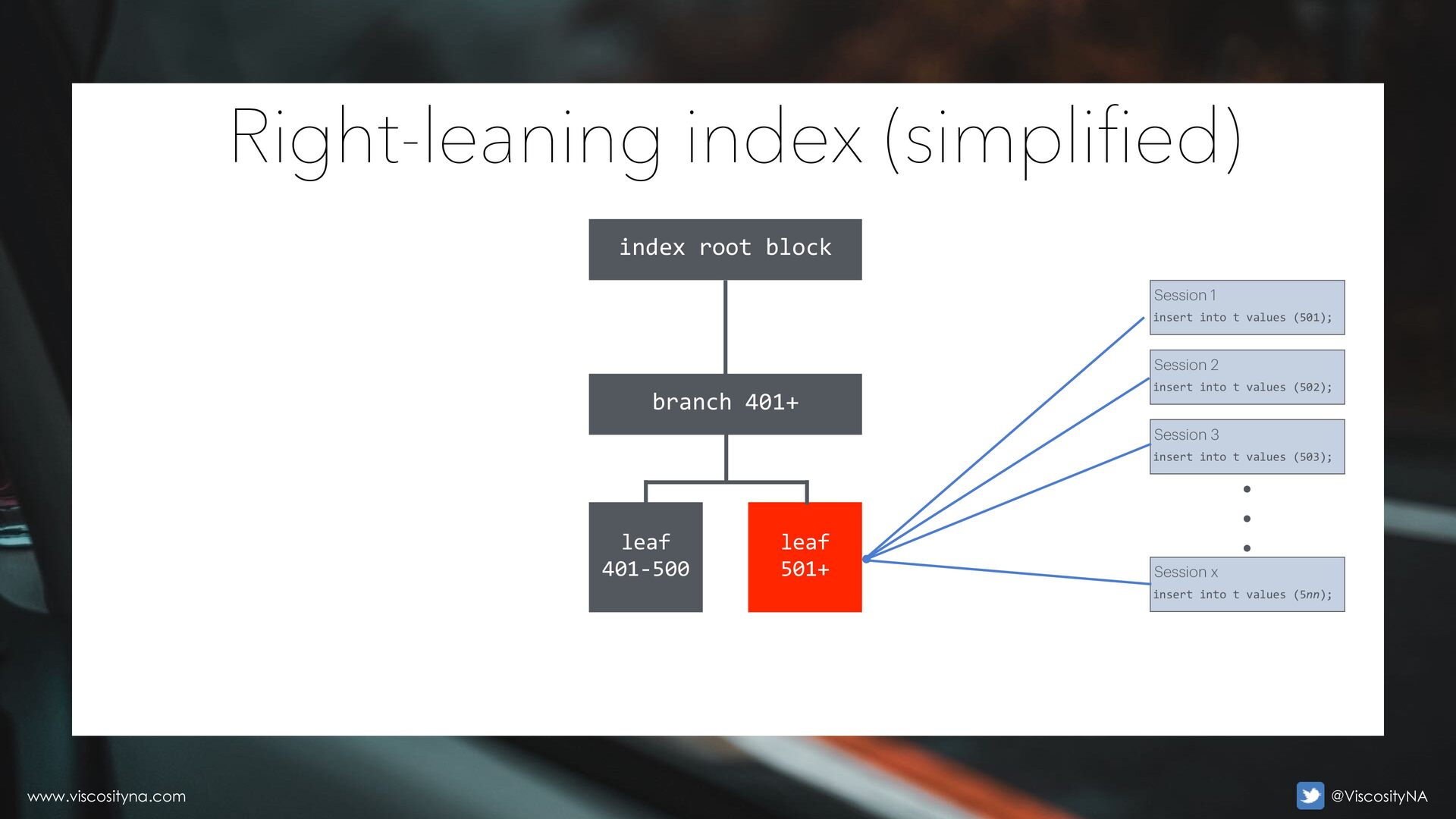
increasing/right-leaning index (PK using a sequence) • High insert concurrency (sometimes also update, delete) • RAC can aggravate the situation Right-leaning indexes www.viscosityna.com @ViscosityNA
501+ index root block Session 1 insert into t values (501); Session 2 insert into t values (502); Session 3 insert into t values (503); Session x insert into t values (5nn); • • • www.viscosityna.com @ViscosityNA
pre fi • Reverse key distributes similar values across multiple blocks • 1001 remains 1001, goes to leaf 1000+ • 1002 becomes 2001, goes to leaf 2000+ • 1005 becomes 5001, goes to leaf 5000+, etc. • Equivalent to hash partitioning over 10 buckets (for numeric values) Reverse keys for right-leaning values www.viscosityna.com @ViscosityNA
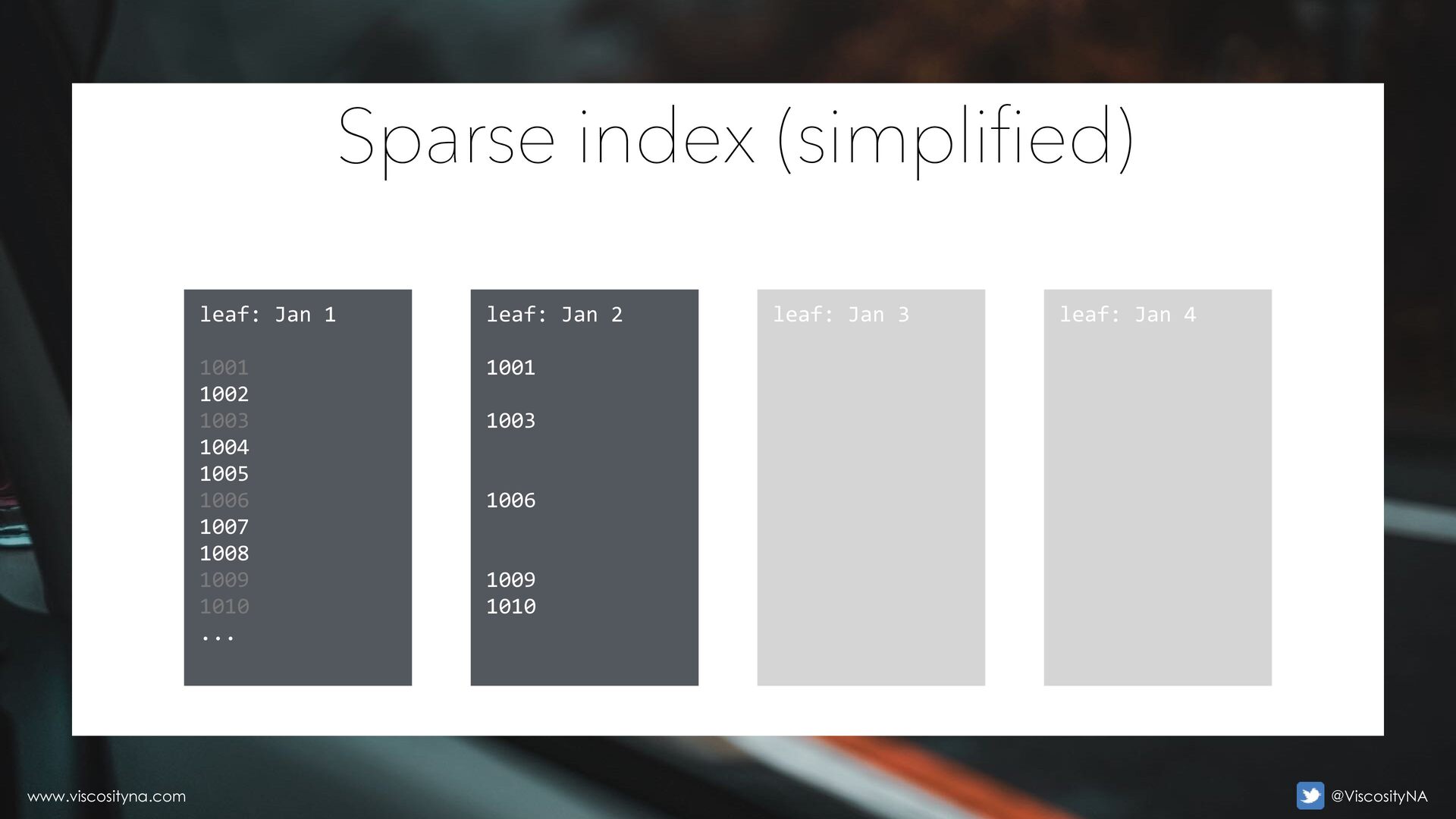
fi • New values "move to the right" • Old values "empty from the left" • Think claims processing with index on last_updated_date • Updates remove the old value; new value goes to the right • Space where "old" value was isn't reused (can't update to the past) Sparse (fragmented) indexes www.viscosityna.com @ViscosityNA
• Reverse key breaks the monotonic order—effectively "hash partitioning" • Minimizes fragmentation effect • Higher chance of reusing/reclaiming voided space • Reduced index growth • Cannot range scan! This will not use the index: ... where Reverse keys for sparse indexes www.viscosityna.com @ViscosityNA
sequence • Sequence cannot be converted to a scalable sequence • No sequence cache contention • Table/index cannot be partitioned • Record access/joins exclusively via equality conditions (no range scan) • Evidence of index contention (buffer busy, index block splits, etc.) Reverse key indexes - use case #1 www.viscosityna.com @ViscosityNA
sequence, number, or date • If a sequence, it cannot be converted to a scalable sequence • No sequence cache contention • If number or date, the values advance monotonically and aren't reused • The leading column is updated frequently to a larger/later value • Table/index cannot be partitioned • Record access exclusively via equality condition on the key (no range scan) • The index is heavily fragmented Reverse key indexes - use case #2 www.viscosityna.com @ViscosityNA
• Often used as surrogate keys to guarantee uniqueness • Calculating new values is expensive, especially when concurrency is high • Oracle computes a block of sequence values and caches them • The sequence cache size = how many sequences are created at once Sequence cache www.viscosityna.com @ViscosityNA
sequence calculation • Calculating the next sequence block requires a lock on the sequence • A busy sequence is more likely to cause concurrency issues • In RAC, a single node locks all others out of the sequence Sequence cache www.viscosityna.com @ViscosityNA
cache?" • Sequence cache is per-instance on RAC • Instance failure/restart = loss of unused/cached sequences • Causes sequence gaps and arti fi Sequence cache www.viscosityna.com @ViscosityNA
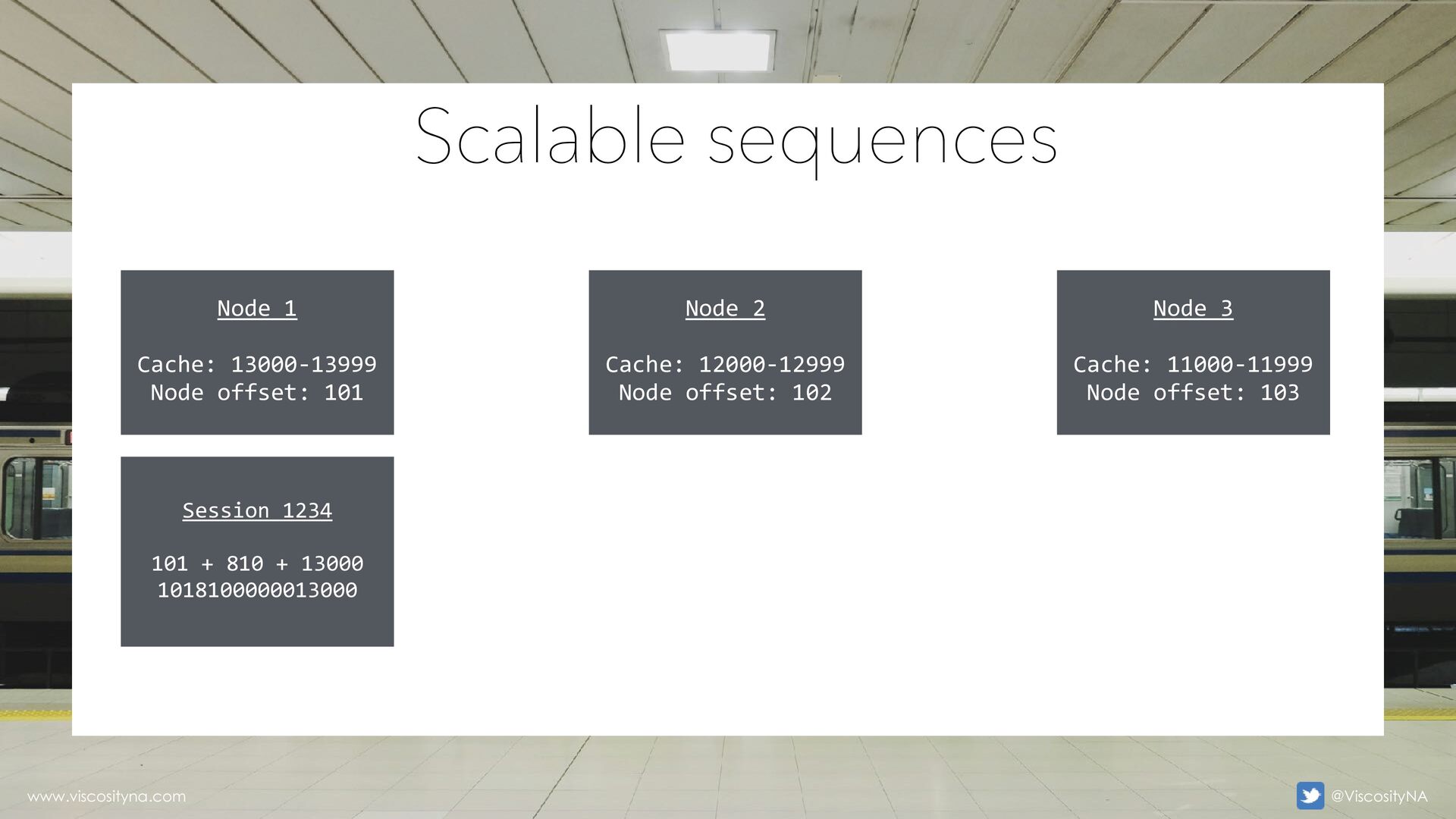
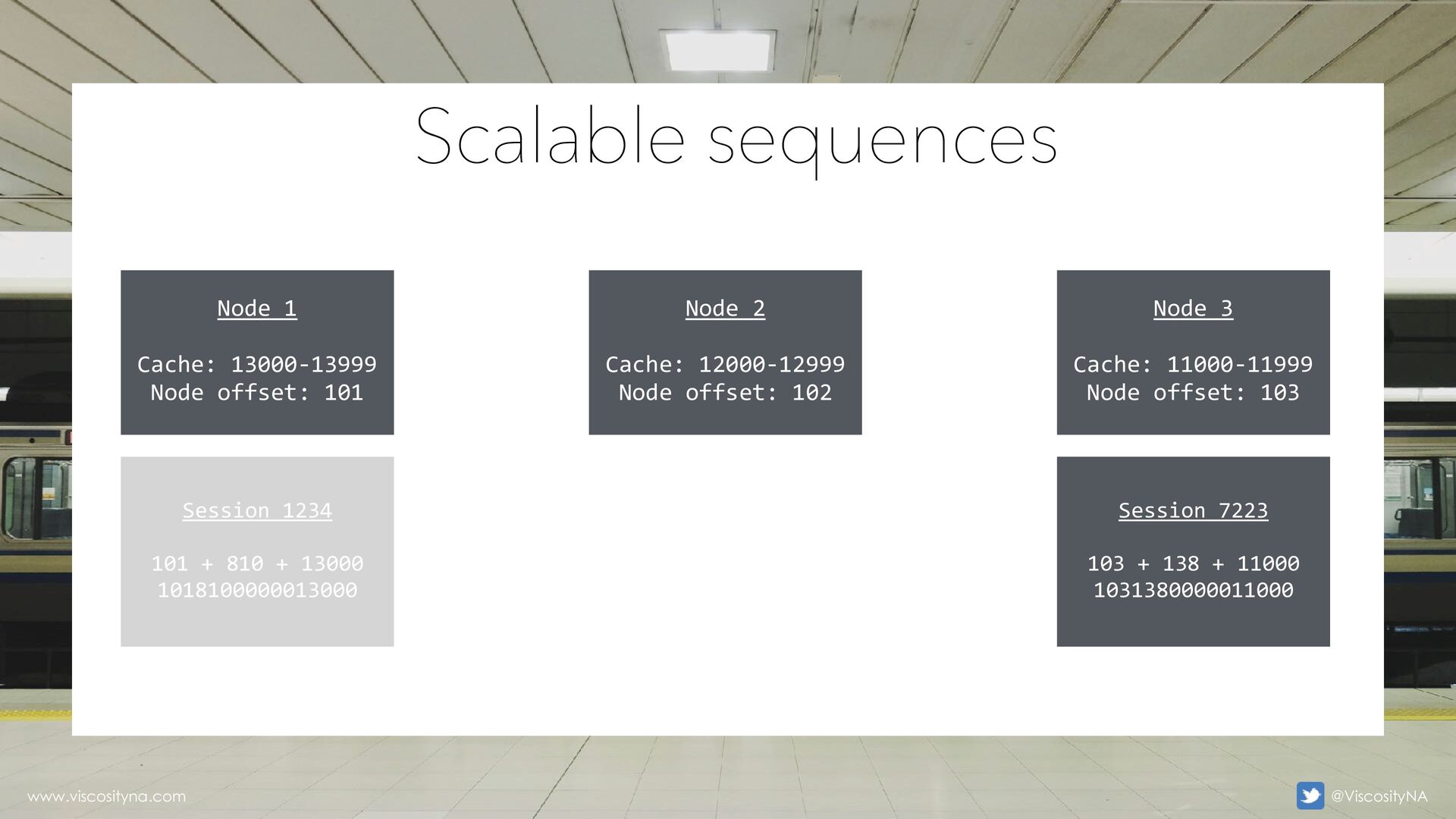
(default) 6-digit pre fi • Pre fi • Sequence component is padded w/0 to keep a consistent length • The pre fi Scalable sequences www.viscosityna.com @ViscosityNA
Reduce need for reverse key, hash partitioning • The incremental sequence component is the same • Scalable sequences are still vulnerable to undersized sequence cache Scalable sequences www.viscosityna.com @ViscosityNA
resources • Guarantee consistency • Spinlocks: waiters "spin" on CPU • Latch: prone to false contention (one latch controls many objects) • Mutex: precise and faster; part of the object's memory structure Latches and mutexes www.viscosityna.com @ViscosityNA
One to many relationship is prone to false latch contention • Latch count, location, status are always known ($latch, Latches www.viscosityna.com @ViscosityNA
more precise than latches • Often implemented directly under hardware = FAST • Dynamic—part of/internal to the object it protects • Not tracked/instrumented individually to reduce overhead Mutexes www.viscosityna.com @ViscosityNA
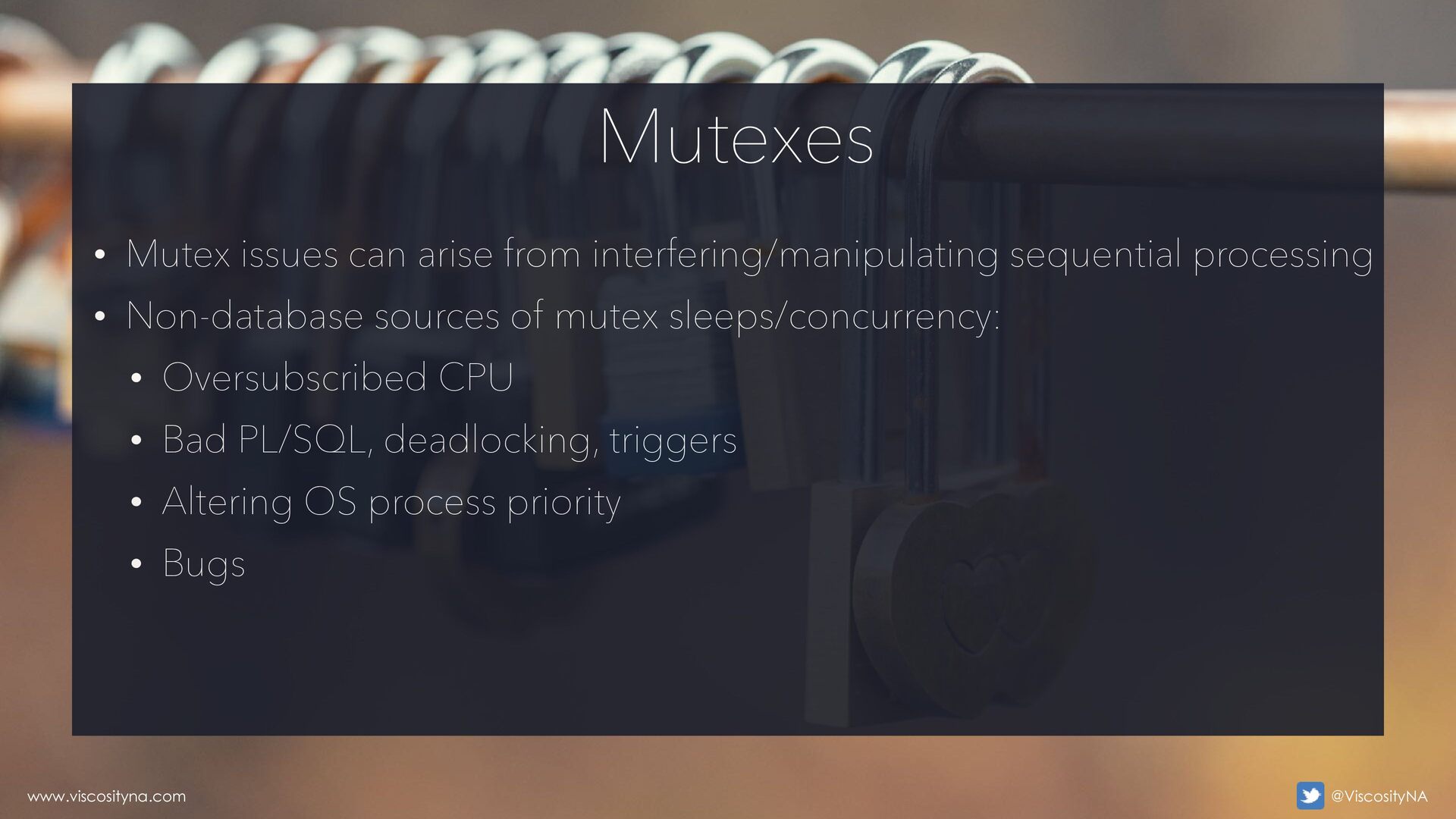
• Oracle collects statistics on mutex activity, not individual mutexes • Sleeping is a wait event • Spinning is not a wait—it is registered as CPU time • Mutex sleeps indicate a concurrency problem... ...but not necessarily a database concurrency problem Mutexes www.viscosityna.com @ViscosityNA
processing • Non-database sources of mutex sleeps/concurrency: • Oversubscribed CPU • Bad PL/SQL, deadlocking, triggers • Altering OS process priority • Bugs Mutexes www.viscosityna.com @ViscosityNA
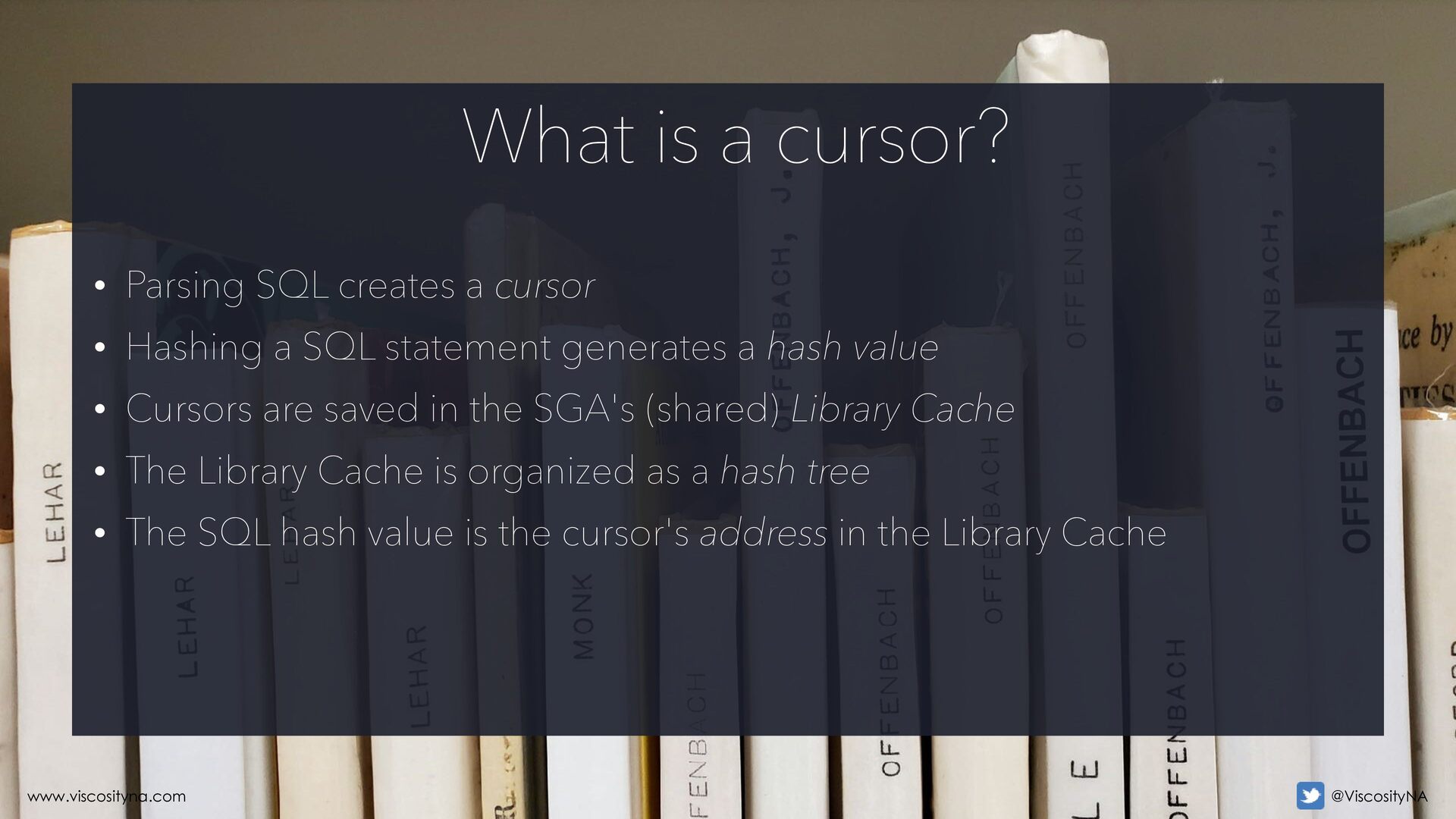
a SQL statement generates a hash value • Cursors are saved in the SGA's (shared) Library Cache • The Library Cache is organized as a hash tree • The SQL hash value is the cursor's address in the Library Cache What is a cursor? www.viscosityna.com @ViscosityNA
permission checks • Evaluates access paths, performs cost-based optimization • Creates an executable version of the cursor (think: compiled) Parsing: Hard Parse www.viscosityna.com @ViscosityNA
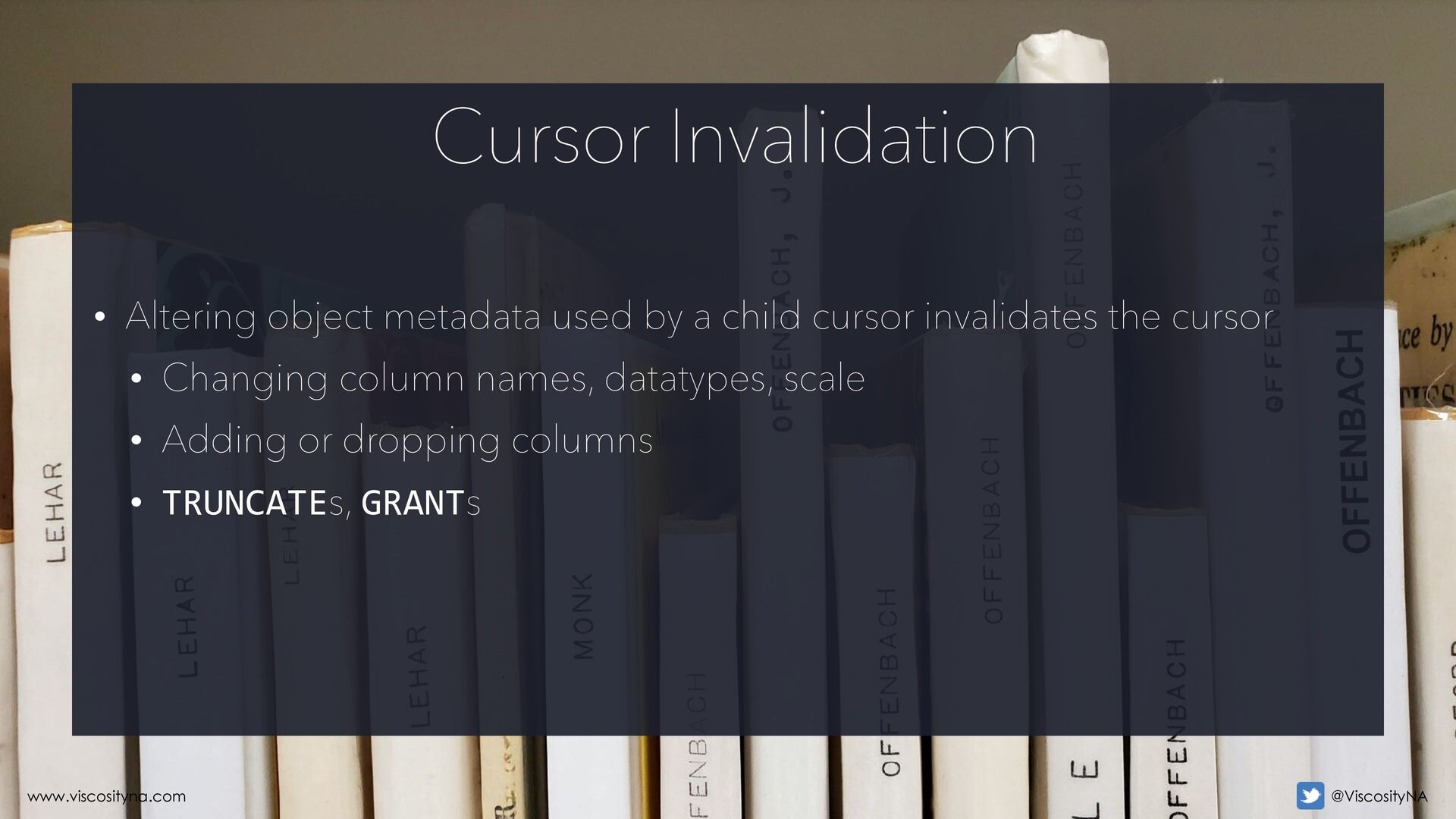
Library Cache: • The parent cursor with static/de fi • A child cursor of dynamic metadata (e.g. variables/bind values) Parsing: Hard Parse www.viscosityna.com @ViscosityNA
always gets the same hash • BUT... queries with different variables are not identical! Cursor Sharing and Soft Parsing www.viscosityna.com @ViscosityNA
metadata • Bind variables in the SQL text produce identical SQL hashes • Saves space in the Library Cache • Reduces impact of hard parsing • Soft parsing evaluates bind values • Oracle reuses the existing execution plan if possible Cursor Sharing and Soft Parsing www.viscosityna.com @ViscosityNA
• The SQL is the same, but existing cursors can't be shared, so: • The SQL hash maps to an existing address in the Library Cache • The dynamic metadata creates a new child cursor under the parent Cursor Sharing www.viscosityna.com @ViscosityNA
different execution plans • A parent cursor can be marked: • Bind-sensitive: Cursor can be re-parsed to improve the plan • Bind-aware: Child execution plans are based on bind values • Bind-aware cursors are parsed differently: • A soft parse isn't adequate but a full, hard parse is too much • Optimizer reviews children for potential reuse based on bind values Cursor Sharing www.viscosityna.com @ViscosityNA
• Improves performance, reduces cost, eases data lifecycle management • Partition by range, list, hash • Composite partitioning combines two methods, e.g. list + range Partitioning www.viscosityna.com @ViscosityNA
e.g. from Jan 1, 2024 until Feb 1, 2024 • Reporting on January 2024 selects one partition • All other partitions are eliminated • Older (unused) data can be moved to low-cost storage • Inactive partitions can be marked read-only • Reduces backup size, time Range partitioning www.viscosityna.com @ViscosityNA
NY, TX) get dedicated partitions • Smaller states (MT, NH, NM) grouped in a single partition • Allows fi • Queries realize the same partition-elimination bene fi List partitioning www.viscosityna.com @ViscosityNA
and assigned to a bucket • Sequential values are distributed across hash partitions • Effective for eliminating hot blocks/records • Queries on sequential ranges will likely hit multiple partitions • Often useful for transactional environments w/lookups by key value • Not always a good choice for reporting Hash partitioning www.viscosityna.com @ViscosityNA
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.viscosityna.com @ViscosityNA • [DBA|ALL|USER]_ERRORS lists stored code with errors or](https://files.speakerdeck.com/presentations/50f5a7cf6b424d6a850e216f5aaaea84/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.viscosityna.com @ViscosityNA Questions [email protected] https://linktr.ee/oraclesean](https://files.speakerdeck.com/presentations/50f5a7cf6b424d6a850e216f5aaaea84/slide_63.jpg){kind=link}
{kind=link}