Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
FOSS4G 2023 Japan@FUKUI 熊谷康太様発表資料
Search
OSGeo.JP
September 26, 2023
Technology
250
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
FOSS4G 2023 Japan@FUKUI 熊谷康太様発表資料
FOSS4G 2023 Japan@FUKUI
スポンサー講演7:デジタル社会を目指して~分散DBと分散処理の連携に関する調査
熊谷 康太様(株式会社NTTデータグループ) 発表資料
OSGeo.JP
September 26, 2023
More Decks by OSGeo.JP
See All by OSGeo.JP
Advancing the 3D Geospatial Ecosystem in Japan via Global Collaborations
osgeojp
0
3.3k
農業用ダム監視を目的とした衛星SAR 干渉解析の適用性について
osgeojp
0
3.3k
FOSS4G 山陰Meetup 2024/ QGIS Processing でのGRASSのエラーの調査
osgeojp
0
36
FOSS4G 2023 Japan@FUKUI 佐橋 功一様、 新垣 仁様 発表資料
osgeojp
0
340
FOSS4G 2023 Japan@FUKUI 白土 洋介様 発表資料
osgeojp
0
810
FOSS4G 2023 Japan@FUKUI 小林裕之様発表資料
osgeojp
0
820
吉中輝彦様 QGISで扱うラスタレイヤ (FOSS4G 2022 Japan Online)
osgeojp
0
78
原田 豊様 Windows版『聞き書きマップ』のQGISプラグイン化
osgeojp
0
450
吉中輝彦様 QGISと点群とPLATEAUと
osgeojp
0
2k
Other Decks in Technology
See All in Technology
Claude Codeとハーネスについて考えてみる
oikon48
18
8.9k
地域 SRE コミュニティ最前線 / SRE NEXT 2026 Discussion Night Track C
muziyoshiz
0
180
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
2.9k
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
4.1k
実装だけじゃない! CCA-F取得エンジニアが教えるClaude Code開発プロセス活用術
diggymo
2
480
AI時代のエンジニアキャリアについて今一度考える
sakamoto_582
2
1.4k
Oracle Exadata Database Service on Cloud@Customer X11M (ExaDB-C@C) サービス概要
oracle4engineer
PRO
2
8.4k
AWS Blocks を触ってみた/first-tach-aws-blocks
fossamagna
2
150
FinOps X 2026 Recap from Engineer Side #JapanFinOps
chacco38
0
270
スタートアップにおけるアジャイルの実践について #shibuyagile
murabayashi
3
2.1k
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
100
Featured
See All Featured
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Context Engineering - Making Every Token Count
addyosmani
9
1k
Building AI with AI
inesmontani
PRO
1
1.1k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
A Guide to Academic Writing Using Generative AI - A Workshop
ks91
PRO
1
350
How Fast Is Fast Enough? [PerfNow 2025]
tammyeverts
3
650
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
GraphQLの誤解/rethinking-graphql
sonatard
75
12k
A designer walks into a library…
pauljervisheath
211
24k
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
190
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
Designing for humans not robots
tammielis
254
26k
Transcript
© 2023 NTT DATA Group Corporation © 2023 NTT DATA
Group Corporation デジタル社会を目指して~分散DBと分散処理の連携に関する調査 2023年9月18日 株式会社NTTデータグループ 技術革新統括本部 技術開発本部 IOWN推進室 熊谷康太
© 2023 NTT DATA Group Corporation 2 目指すべき未来社会の姿として第5期科学技術基本計画においてSociety5.0が提唱された。 Society5.0とは情報社会(Society4.0)における課題がIT等を活用したデジタル技術によって解決されている社会である。 デジタル社会(Society
5.0)とは Society 5.0までの変遷 Society 5.0で実現する世界 狩猟社会(Society 1.0)、農耕社会(Society 2.0)、工業社会(Society 3.0)、 情報社会(Society 4.0)に続く、新たな社会のことであり、 経済発展と社会的課題の解決を両立する、人間中心の社会(Society) IoTや人工知能、ロボット、自動走行車などの技術により社会変革(イノベーション)が起き、 情報社会(Society 4.0)における課題を解決できる。 例えば、人手不足のために十分な配送サービスを享受できないという地域の課題に対して、 地理空間情報やドローン技術などを活用することで 自動配送サービスを実現し解決することがあげられる。 参考: 内閣府 Society5.0 (https://www8.cao.go.jp/cstp/society5_0/)
© 2023 NTT DATA Group Corporation 3 Society 5.0の実現に求められること Society5.0はサイバー空間(仮想空間)とフィジカル空間(現実空間)を高度に融合させたシステムによって実現される。
このシステムを実現するためには多様で膨大な地理空間情報をリアルタイムに収集し、効率的に分析することが必要となる。 サイバー空間(仮想空間)とフィジカル空間(現実空間)を 高度に融合させたシステムによって実現される。 Society 5.0のしくみ 参考: 内閣府 Society5.0 (https://www8.cao.go.jp/cstp/society5_0/) 東京都デジタルツインプロジェクト(https://info.tokyo-digitaltwin.metro.tokyo.lg.jp/) サイバー空間とフィジカル空間を高度に融合させたシステムの例 (東京都デジタルツインプロジェクト) 現実空間の様々なIoTセンサデータ(地理空間情報)などをリアルタイムに収集し、 効率的に分析して、現実世界にリアルタイムにフィードバックする必要がある
© 2023 NTT DATA Group Corporation 4 従来技術の課題と先進技術の動向 従来技術について PostGISは多様な地理空間の情報収集、分析に役立つ。
ただし、モノリシックな構成であるためスケーラビリティに課題がある。 (データ、トランザクションの規模の増加に対応することが難しい) 先進技術の動向 水平スケール可能な分散DBが登場。 社会課題と技術動向を踏まえた取組 PostgreSQLとの互換性を持つ分散DBであるYugabyteDBについて地理空間情報の収集(書き込み)と分析(読み込み)の処理性能がスケールするか調査する。 YugabyteDBに書き込みと読み込みを行うアプリケーションについては大規模データのリアルタイム処理に適したApache Sparkを用いる。 参考:PLATEAU (https://www.mlit.go.jp/plateau/use-case/uc22-008/)(https://www.mlit.go.jp/plateau/use-case/uc23-05/), Japan Comuputer Technology(https://www.jctechno.co.jp/system/case1/index.html), 株式会社スポットライト(https://www.pgecons.org/wp-content/uploads/2013/12/7c14ac1727a38c22295af840fc613321.pdf), RESAS(https://resas.go.jp/population-future-mesh/#/map/13/13101/2/2050/0/0/0.5/10.079484783826816/35.6939726/139.7536284/2050/0) PostgreSQL互換 MySQL互換 多様な地理空間情報の収集、分析に役立つ技術としてPostGISがあるがスケーラビリティに課題がある。 一方で近年高いスケーラビリティを特徴とする分散DBが登場している。 3D都市モデル ハザードマップ ヒートマップ ナビゲーション PostGISの活用事例
© 2023 NTT DATA Group Corporation 5 YugabyteDBとは Yugabyte社が中心に開発しているOSSプロダクト。 PostgreSQLとの高い互換性を目指しており、PostGISとも互換性を持っている
YugabyteDBクラスタ YugabyteDBノード#1 YB-Master YB-Tserver YugabyteDBノード#2 YB-Master YB-Tserver YugabyteDBノード#3 YB-Master YB-Tserver YB-Masterはクラスタ全体の メタデータを管理 YB-Tserverはクエリ処理や ユーザデータの保管を担当 ユーザデータの配置先・ユーザ・権限などのメタデータを管理する「YB-Master」と、 ユーザデータを保持するとともに、ユーザリクエストを処理する「YB-Tserver」の2つのコンポーネントから構成される。 複数のYB-MasterとYB-Tserverで構成されるクラスタをYugabyteDBクラスタと呼ぶ。
© 2023 NTT DATA Group Corporation 6 Apache Sparkとは 大量のデータを
たくさんのサーバを並べて並 列分散処理し、 現実的な時間(数分~数時間)で 目的の処理結果を得る ビッグデータのリアルタイム分析に適したOSSの分散処理フレームワークである。 ◼ 分散処理フレームワークの概要 ◼ Apache Sparkを用いる理由 ディスクIOを少なくしてなるべくインメモリで処理する設計となっており高速に動作することが特徴である。 この特徴を活かしてYugabyteDBと組み合わせることで今まで困難であった大規模な地理空間情報の リアルタイムな収集、分析が実現できるのではないかと考えて採用する。
© 2023 NTT DATA Group Corporation 7 取組の概略 YugabyteDBに対するApache Sparkを用いた地理空間情報の書き込みと読み込みについて調査し、
実機を用いて動作を確認した。 AWS Apache Sparkクラスタ YugabyteDBクラスタ クライアント ノード Spark クライアントアプリ メトリクス収集・ 監視ノード Master ノード#3 Master ノード#2 Master ノード#1 Worker ノード#3 Worker ノード#2 Worker ノード#1 YugabyteDB ノード#3 YugabyteDB ノード#2 YugabyteDB ノード#1 C1 C2 C3 xxx yyy zzz .. .. .. .. .. .. STEP1 YugabyteDBにテーブルを作成し、 27万レコードを挿入 ※日本全国の橋梁数の約3/1に相当 C1 C2 C3 xxx yyy zzz .. .. .. .. .. .. STEP2 Sparkクライアントアプリでの操作をトリガとして YugabyteDBのテーブルをSpark上に読み込み C1 C2 C3 xxx yyy zzz .. .. .. .. .. .. STEP3 Sparkクライアントアプリでの操作をトリガとして Spark上に読み込んだデータを別名テーブルとして YugabyteDBに書き込み 各ノードのスペックは以下 • t3.xlarge(4CPU, 16GiB) • gp2(100GiB, 300IOPS) 参考: 国土交通省 道路の維持管理について https://www8.cao.go.jp/kisei-kaikaku/kisei/meeting/wg/seicho/20191219/191219seicho03.pdf
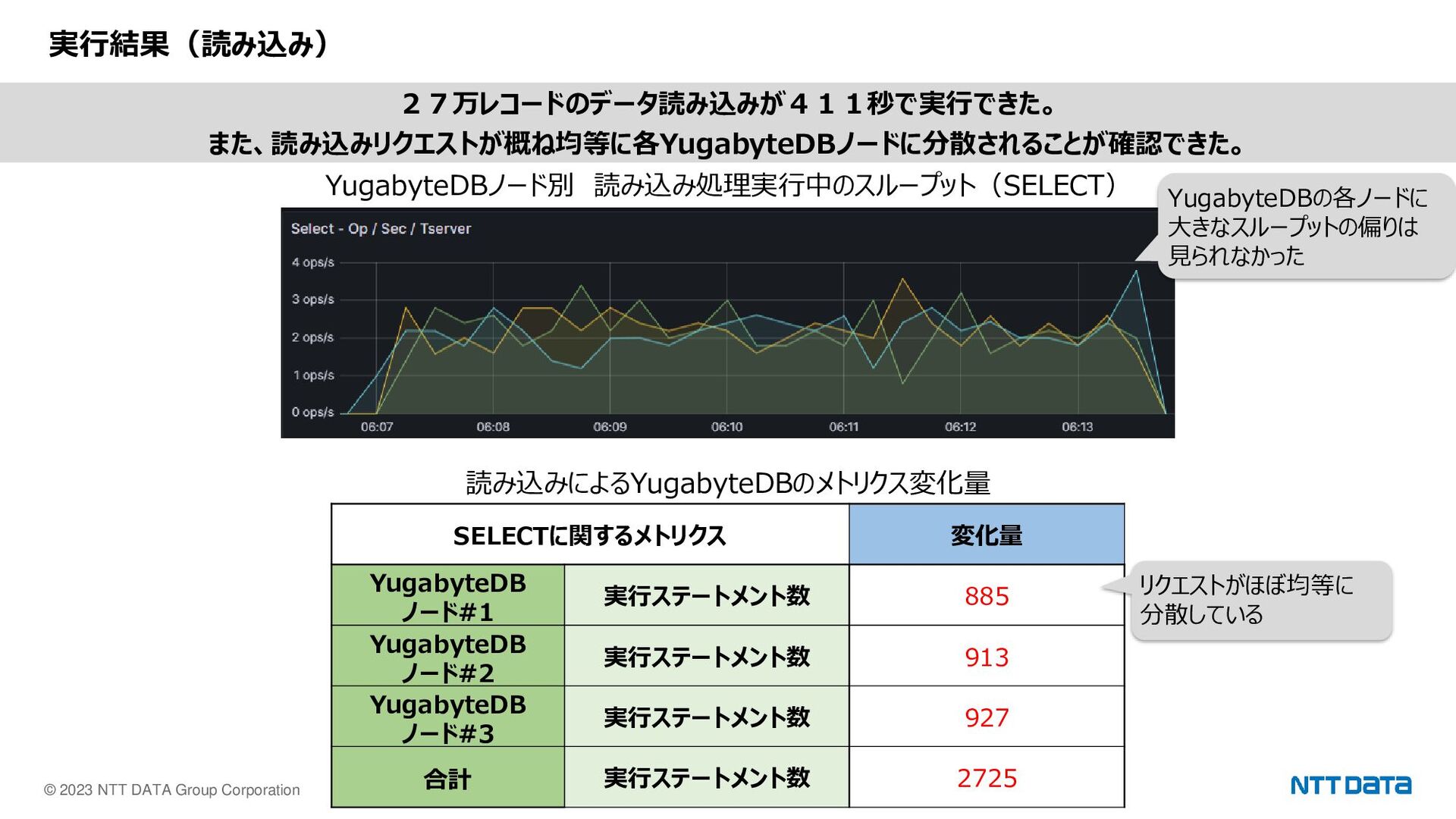
© 2023 NTT DATA Group Corporation 8 実行結果(読み込み) YugabyteDBノード別 読み込み処理実行中のスループット(SELECT)
読み込みによるYugabyteDBのメトリクス変化量 SELECTに関するメトリクス 変化量 YugabyteDB ノード#1 実行ステートメント数 885 YugabyteDB ノード#2 実行ステートメント数 913 YugabyteDB ノード#3 実行ステートメント数 927 合計 実行ステートメント数 2725 27万レコードのデータ読み込みが411秒で実行できた。 また、読み込みリクエストが概ね均等に各YugabyteDBノードに分散されることが確認できた。 YugabyteDBの各ノードに 大きなスループットの偏りは 見られなかった リクエストがほぼ均等に 分散している
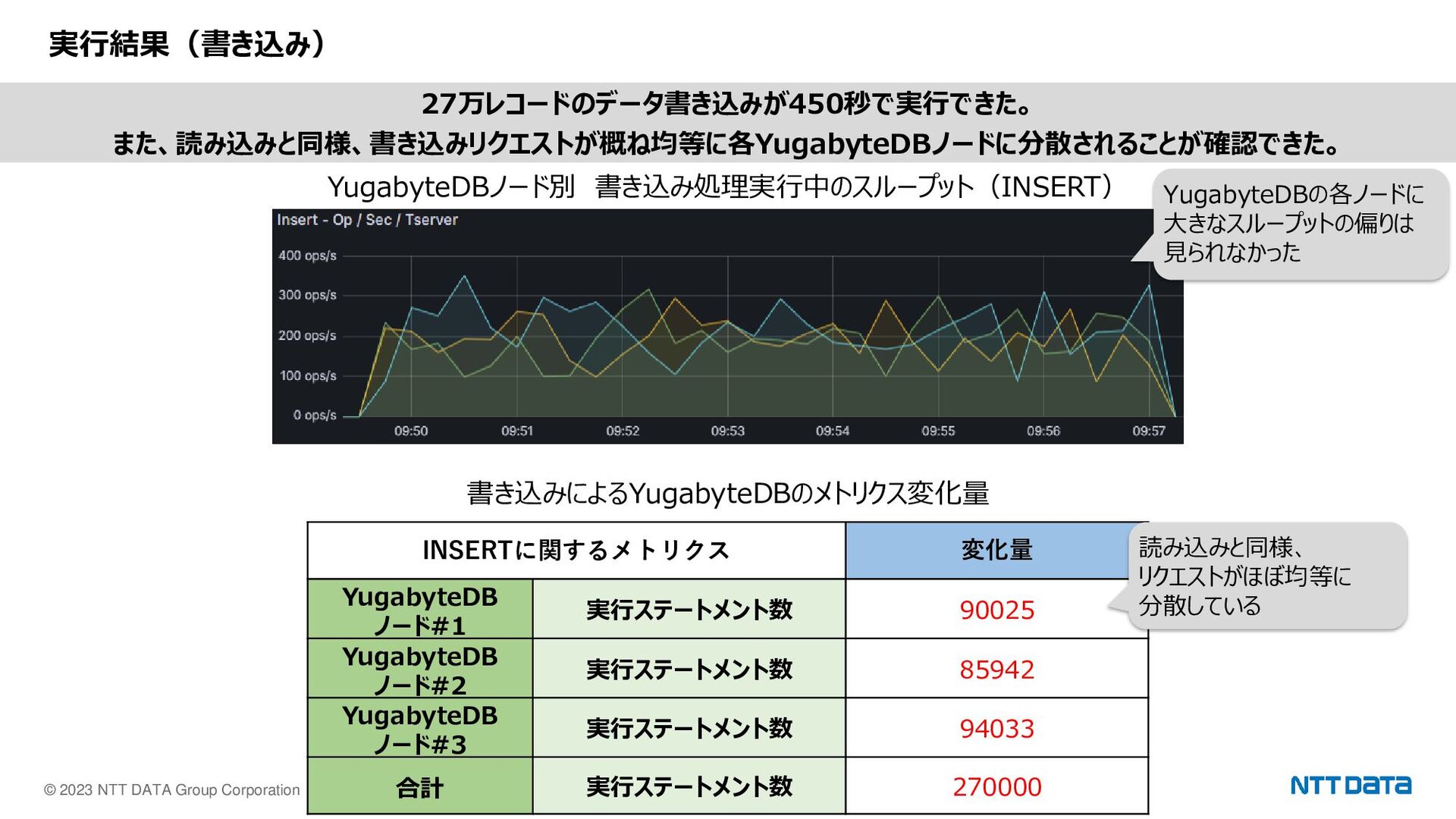
© 2023 NTT DATA Group Corporation 9 実行結果(書き込み) YugabyteDBノード別 書き込み処理実行中のスループット(INSERT)
書き込みによるYugabyteDBのメトリクス変化量 INSERTに関するメトリクス 変化量 YugabyteDB ノード#1 実行ステートメント数 90025 YugabyteDB ノード#2 実行ステートメント数 85942 YugabyteDB ノード#3 実行ステートメント数 94033 合計 実行ステートメント数 270000 27万レコードのデータ書き込みが450秒で実行できた。 また、読み込みと同様、書き込みリクエストが概ね均等に各YugabyteDBノードに分散されることが確認できた。 YugabyteDBの各ノードに 大きなスループットの偏りは 見られなかった 読み込みと同様、 リクエストがほぼ均等に 分散している
© 2023 NTT DATA Group Corporation 10 まとめと今後の展望 ◼ まとめ
Society5.0に向けた社会課題と技術動向を踏まえてPostgreSQLと互換性のある分散DBであるYugabyteDBと 分散処理フレームワークであるApache Sparkを用いて地理空間情報の読み込みと書き込みの処理性能がスケールするかについて調査した。 調査の結果、今回検証で用いた構成においては27万件レコードの処理について、読み込み処理の場合は411秒で完了し、書き込み処理の 場合は450秒で完了することが確認できた。また、書き込みと読み込みのいずれについてもSparkノードからのリクエストが 各YugabyteDBノードにおよそ均等に分散することから、Sparkクラスタを構成するノード数とYugabyteDBクラスタを構成するノード数を 水平スケールさせることで地理空間情報の読み込みと書き込みの処理性能がスケールする可能性があると考える。 ◼ 今後の展望 従来技術で課題となっていたスケーラビリティの部分が分散DBによって解決することができれば、大規模な地理空間情報をリアルタイムに収集し、 効率的に分析して、現実世界にフィードバックすることが求められるシステムの実現に寄与できると考える。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}