A talk about bibliographic data models given at the SWIB16 conference in Bonn, Germany, on November 30, 2016.
Video recording: https://www.youtube.com/watch?v=xp-PRtdF5_U
Abstract:
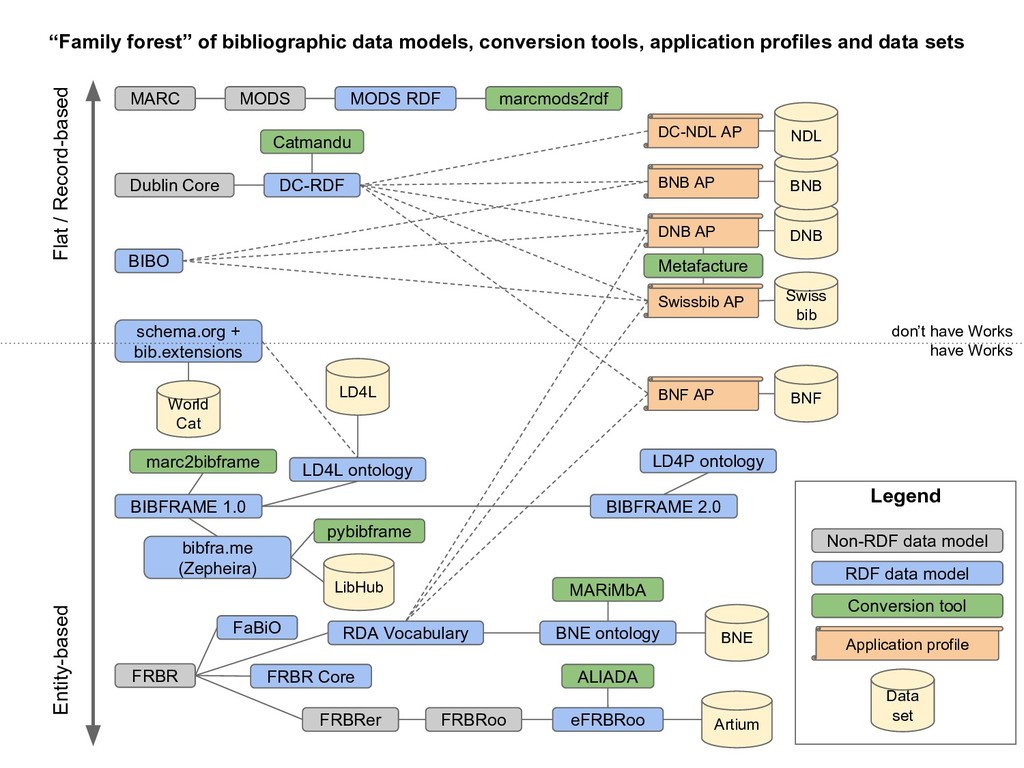
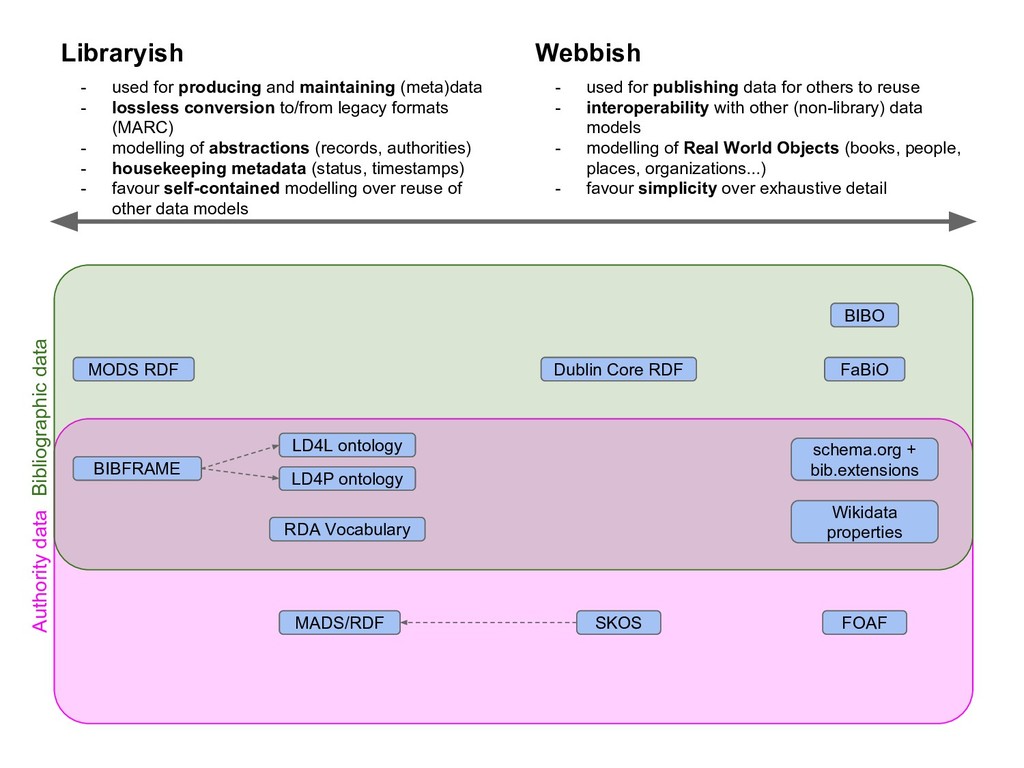
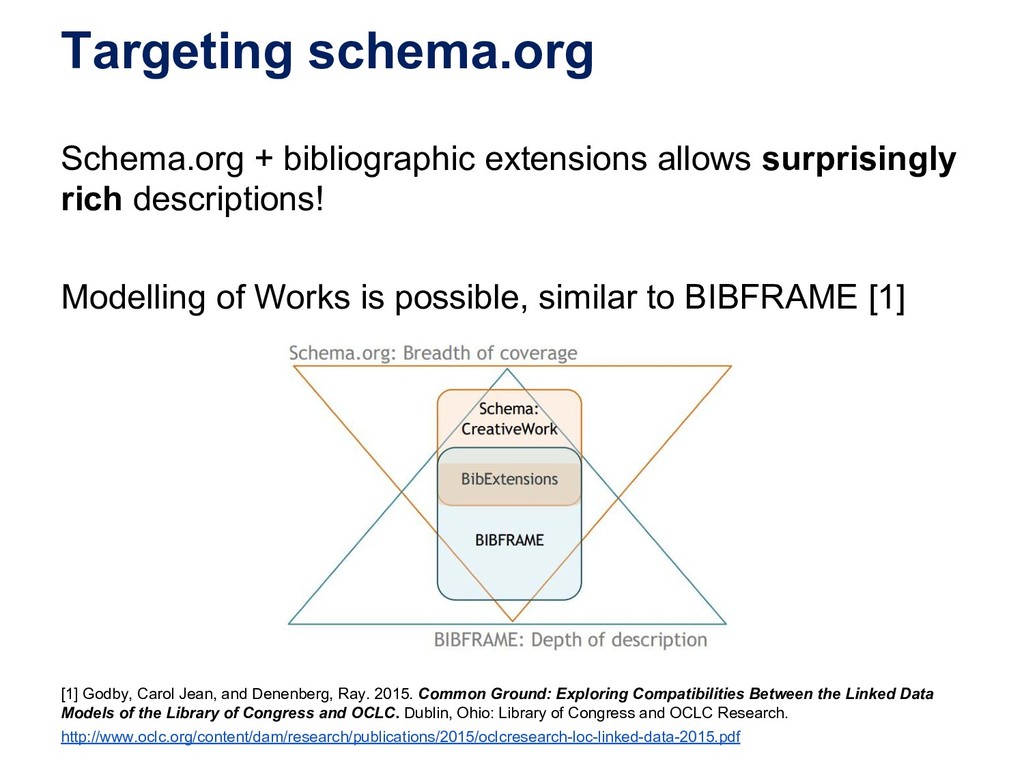
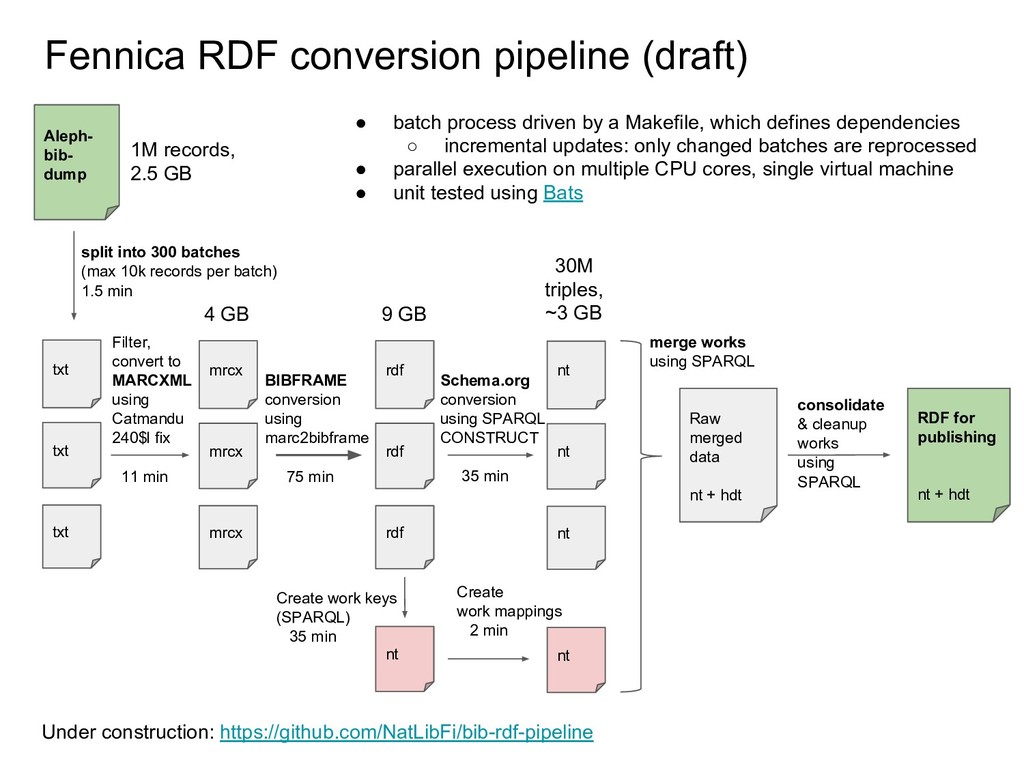
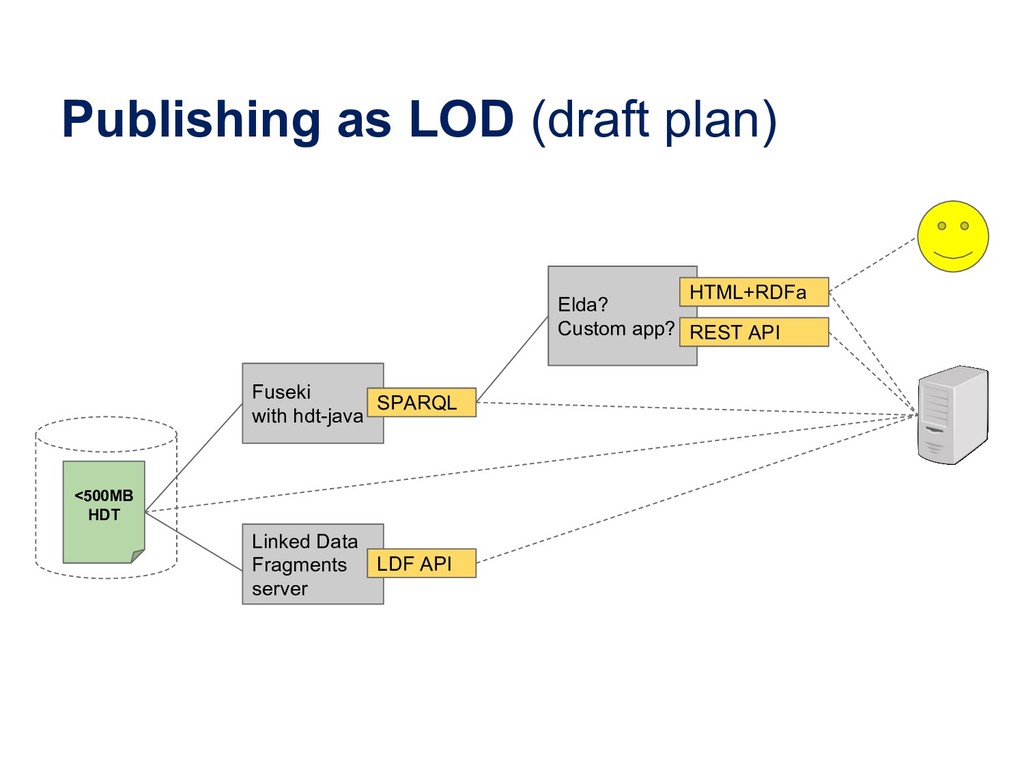
Many libraries are experimenting with publishing their metadata as Linked Data in order to open up bibliographic silos, usually based on MARC records, and make them more interoperable, accessible and understandable to developers who are not intimately familiar with library data. The libraries who have published Linked Data have all used different data models for structuring their bibliographic data. Some are using a FRBR-based model where Works, Expressions and Manifestations are represented separately. Others have chosen basic Dublin Core, dumbing down their data into a lowest common denominator format. The proliferation of data models limits the reusability of bibliographic data. In effect, libraries have moved from MARC silos to Linked Data silos of incompatible data models. Data sets can be difficult to combine, for example when one data set is modelled around Works while another mixes Work-level metadata such as author and subject with Manifestation-level metadata such as publisher and physical form. Small modelling differences may be overcome by schema mappings, but it is not clear that interoperability has improved overall. We present a survey of published bibliographic Linked Data, the data models proposed for representing bibliographic data as RDF, and tools used for conversion from MARC. We also present efforts at the National Library of Finland to open up metadata, including the national bibliography Fennica, the national discography Viola and the article database Arto, as Linked Data while trying to learn from the examples of others.
Google Slides: https://tinyurl.com/linked-silos
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! [email protected] code: https://github.com/NatLibFi/bib-rdf-pipeline these slides: http://tinyurl.com/linked-silos](https://files.speakerdeck.com/presentations/0850ce14d38c48d3b4e4da94d0754b0e/slide_27.jpg){kind=link}