This presentation of the automated subject indexing tool Annif was prepared for the SWIB18 conference in Bonn, Germany.
Video recording: https://youtu.be/lSrFP3D-uTg
Full abstract:
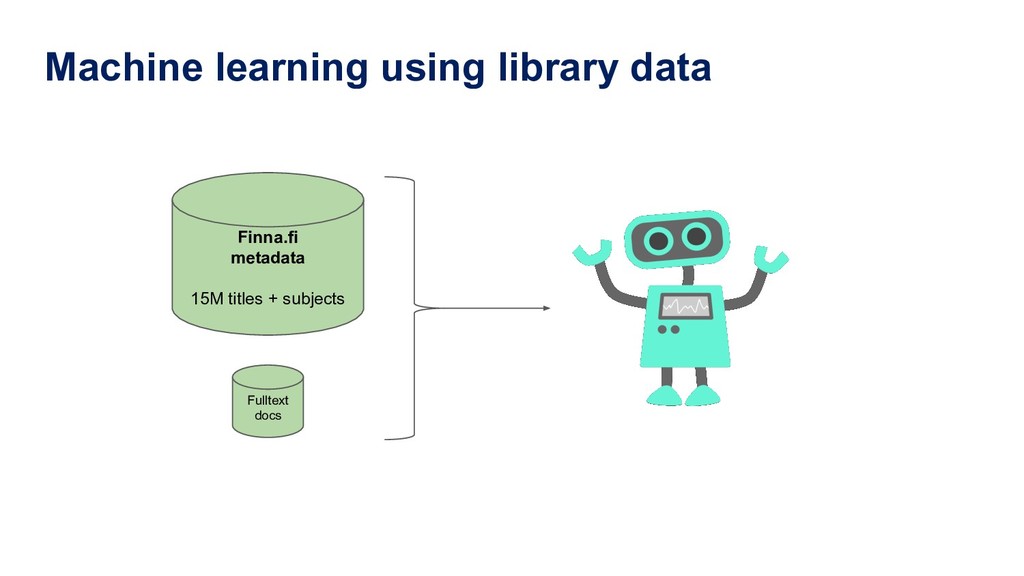
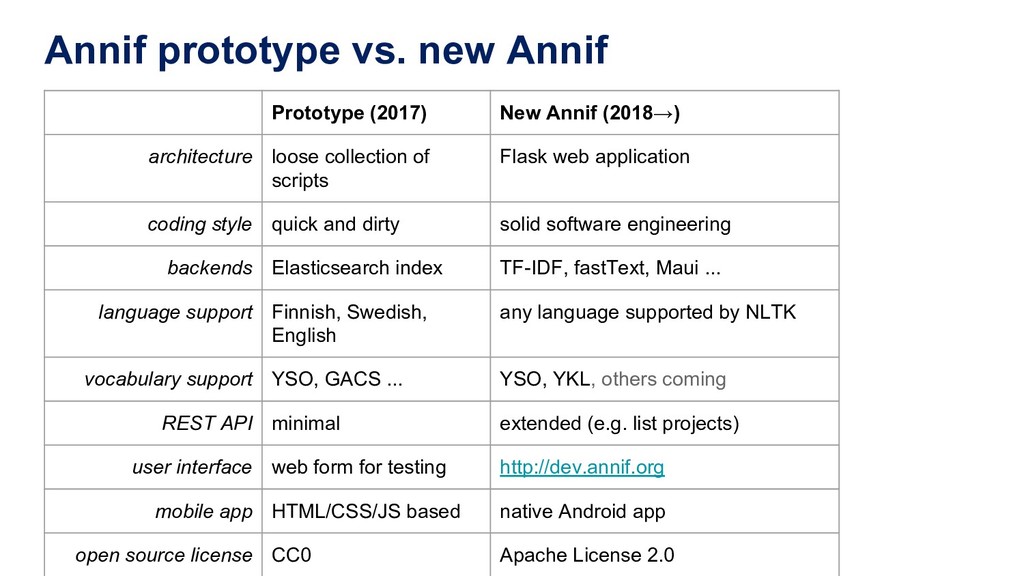
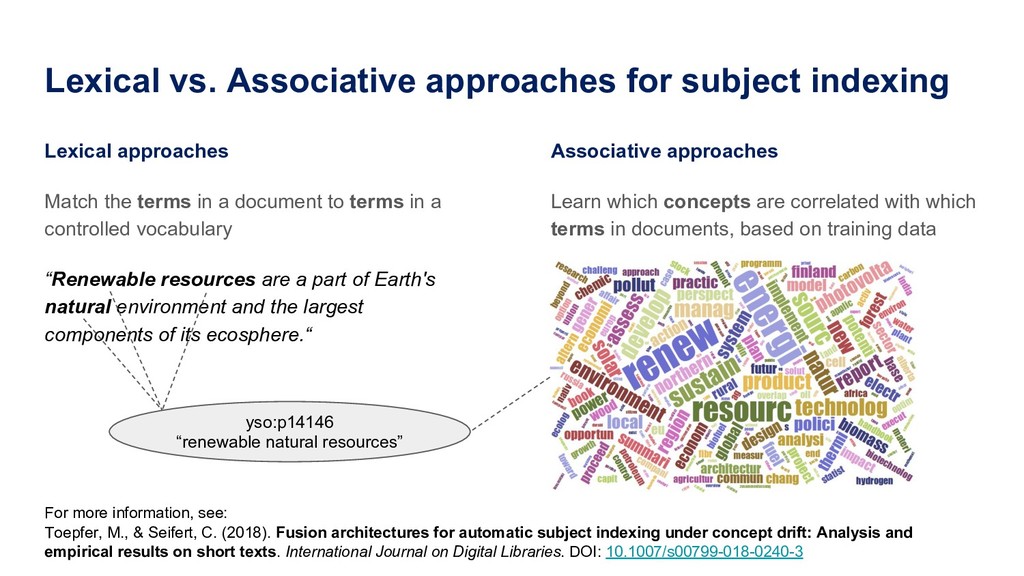
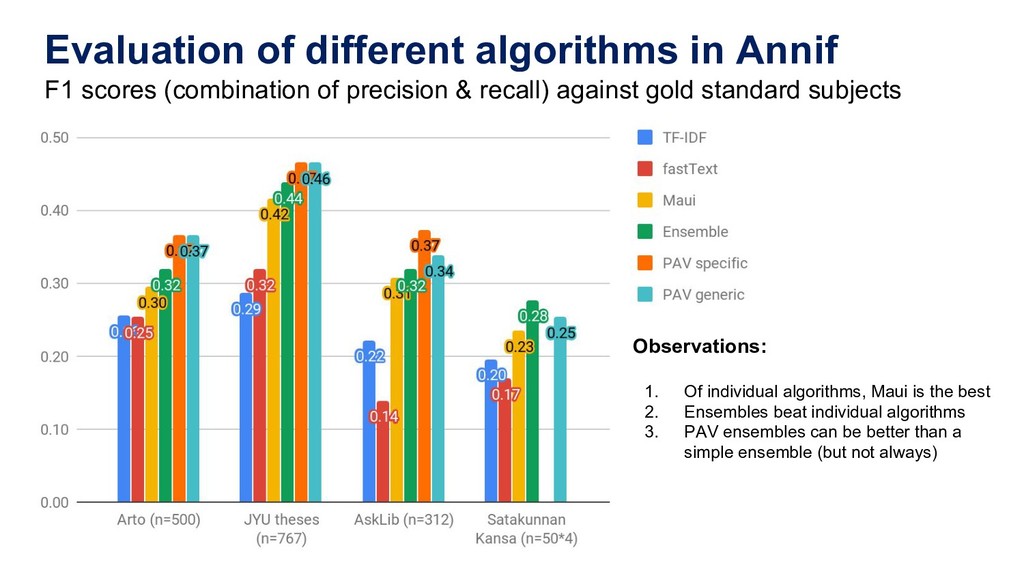
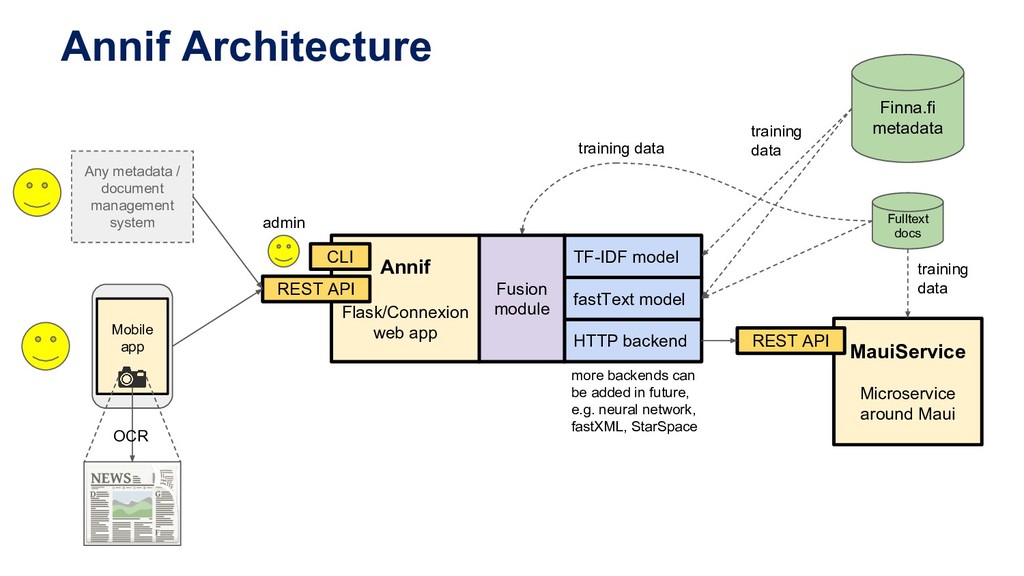
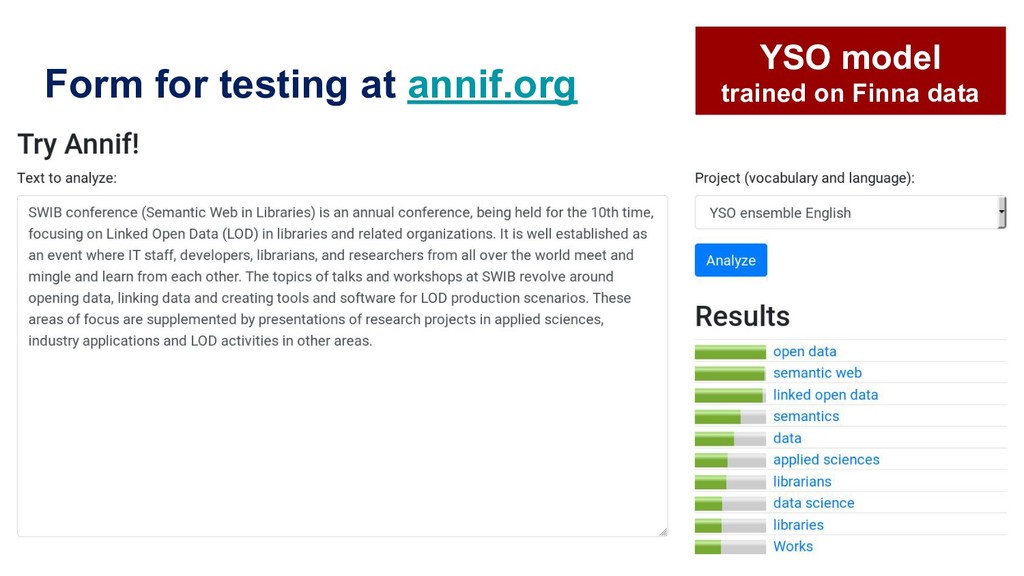
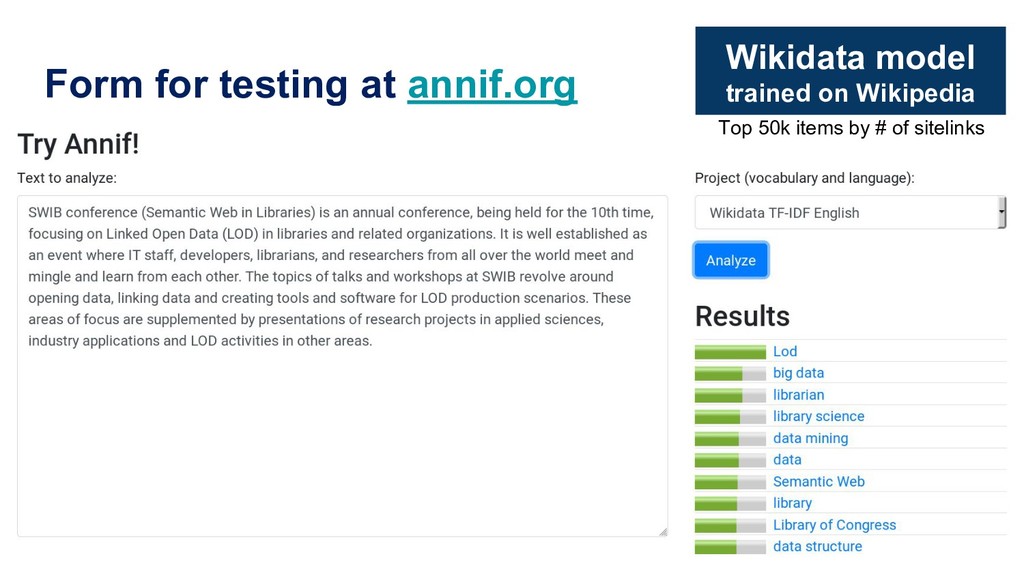
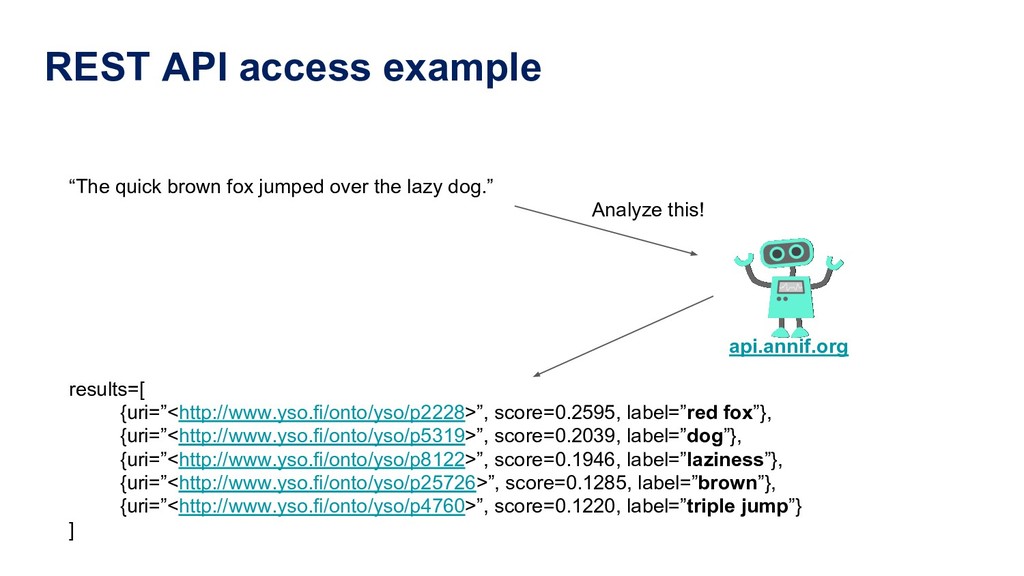
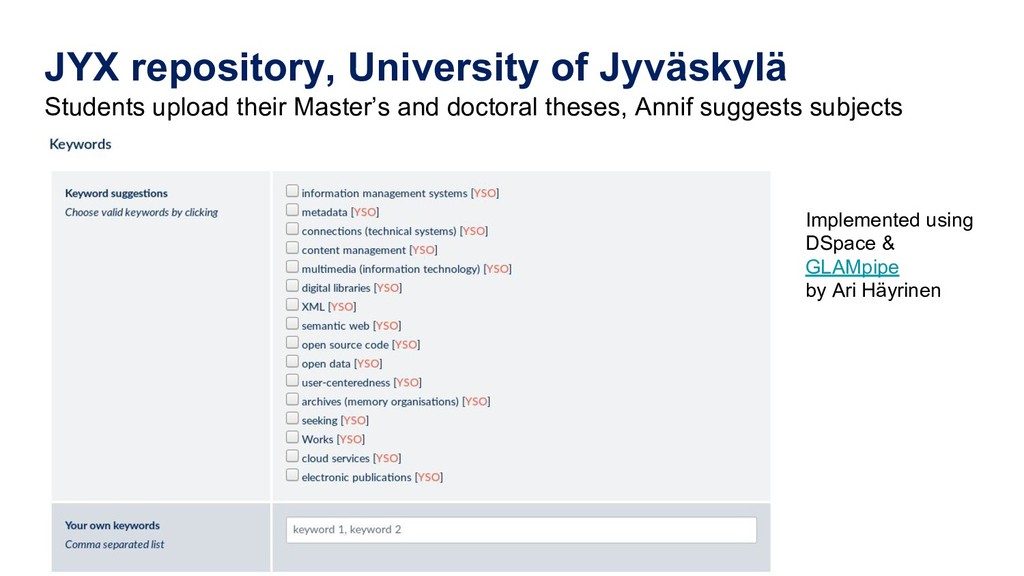
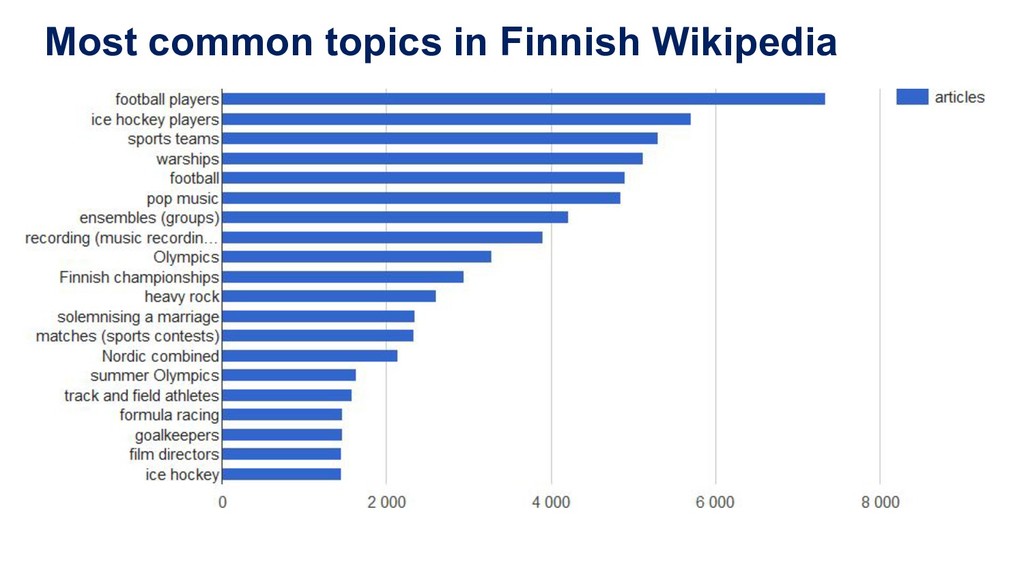
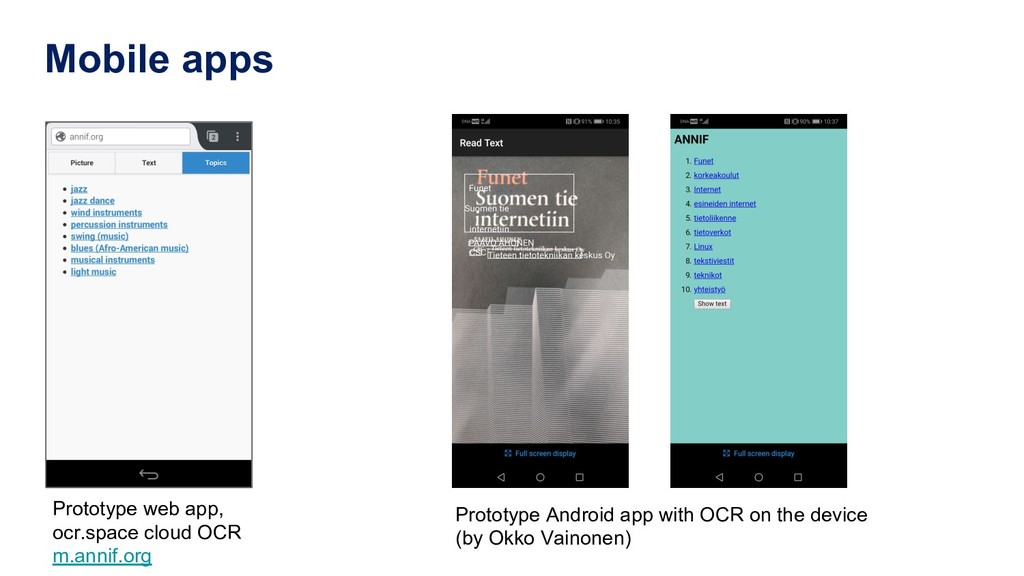
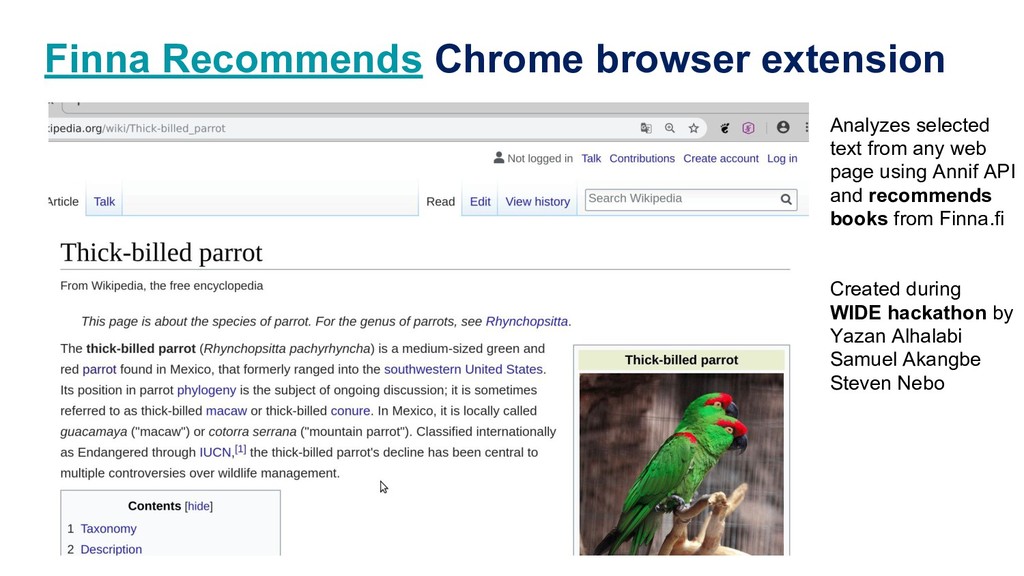
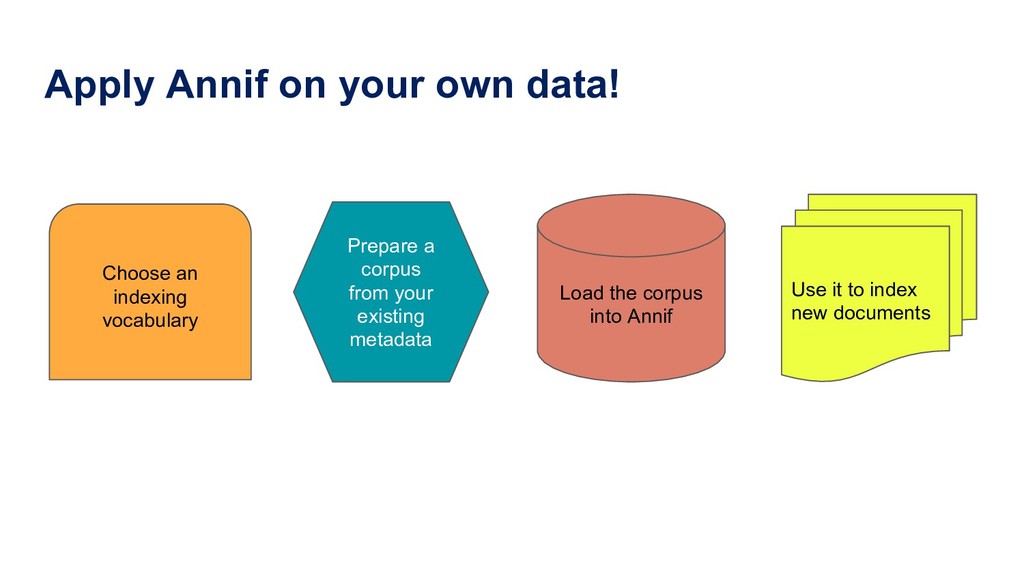
Manually indexing documents for subject-based access is a very labour-intensive intellectual process. A machine could perform similar subject indexing much faster. However, an algorithm needs to be trained and tested with examples of indexed documents. Libraries have a lot of training data in the form of bibliographic databases, but often only a title is available, not the full text. We propose to leverage both title-only metadata and, when available, already indexed full text documents to help indexing new documents. To do so, we are developing Annif, an open source tool for automated indexing and classification. After feeding it a SKOS vocabulary and existing metadata, Annif knows how to assign subject headings for new documents. It has a microservice-style REST API and a mobile web app that can analyse physical documents such as printed books. We have tested Annif with different document collections including scientific papers, old scanned books and current e-books, Q&A pairs from an “ask a librarian” service, Finnish Wikipedia, and the archives of a local newspaper. The results of analysing scientific papers and current books have been reassuring, while other types of documents have proved more challenging. The new version currently being developed is based on a combination of existing NLP and machine learning tools including Maui, fastText and Gensim. By combining multiple approaches, Annif can be adapted to different settings. The tool can be used with any vocabulary and with suitable training data, documents in many different languages may be analysed. With Annif, we expect to improve subject indexing and classification processes especially for electronic documents as well as collections that otherwise would not be indexed at all.
Google Slides: https://tinyurl.com/annif-swib
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Questions? [email protected] - @OsmaSuominen Website: http://annif.org API: http://api.annif.org](https://files.speakerdeck.com/presentations/039cdf2c56bd40058a5e63b48ccdb286/slide_37.jpg){kind=link}