Clouds are outgrowing the capacity of existing monitoring systems. This talk covers the Assimilation Monitoring Project which scales to hundreds of thousands of systems without breathing hard.
Services – cloud and non-cloud • EXTREME monitoring scalability 100K systems without breathing hard • Integrated Continuous Stealth DiscoveryTM: systems, switches, services, and dependencies – without setting off network alarms
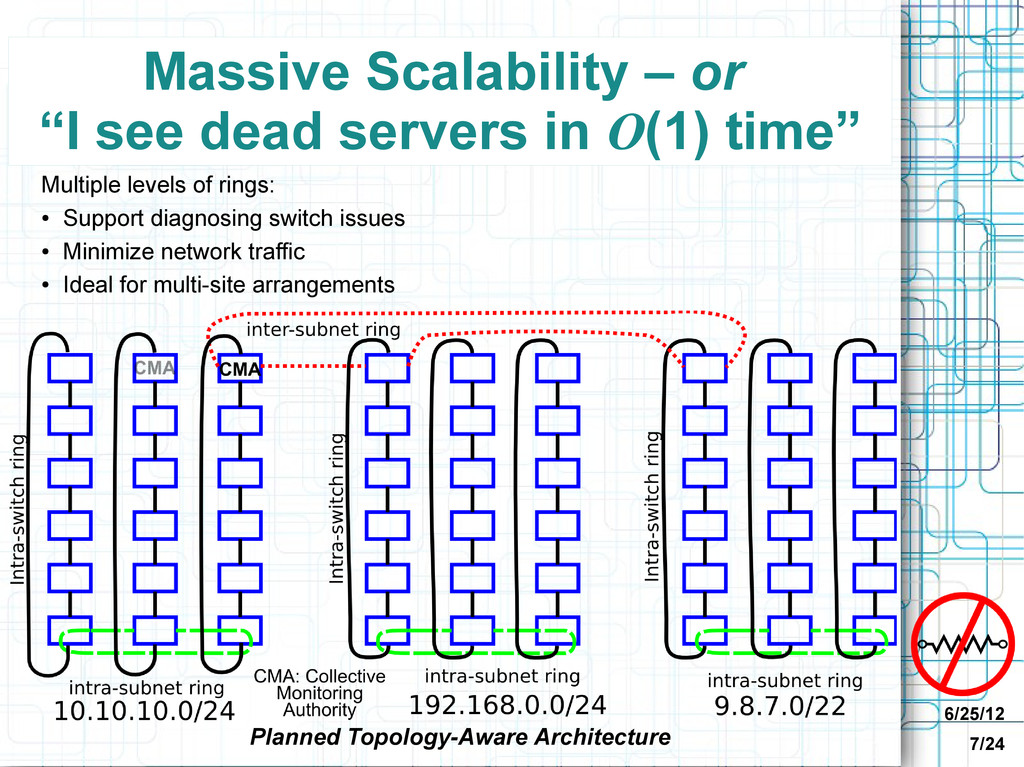
Minimize & simplify configuration • Keep monitoring up-to-date • Know that everything is monitored • Distinguish switch vs system failures • Discovery without setting off alarms • Highlight root causes of cascading failures • Find “forgotten” servers and services • Discover uses and installs of licensed software
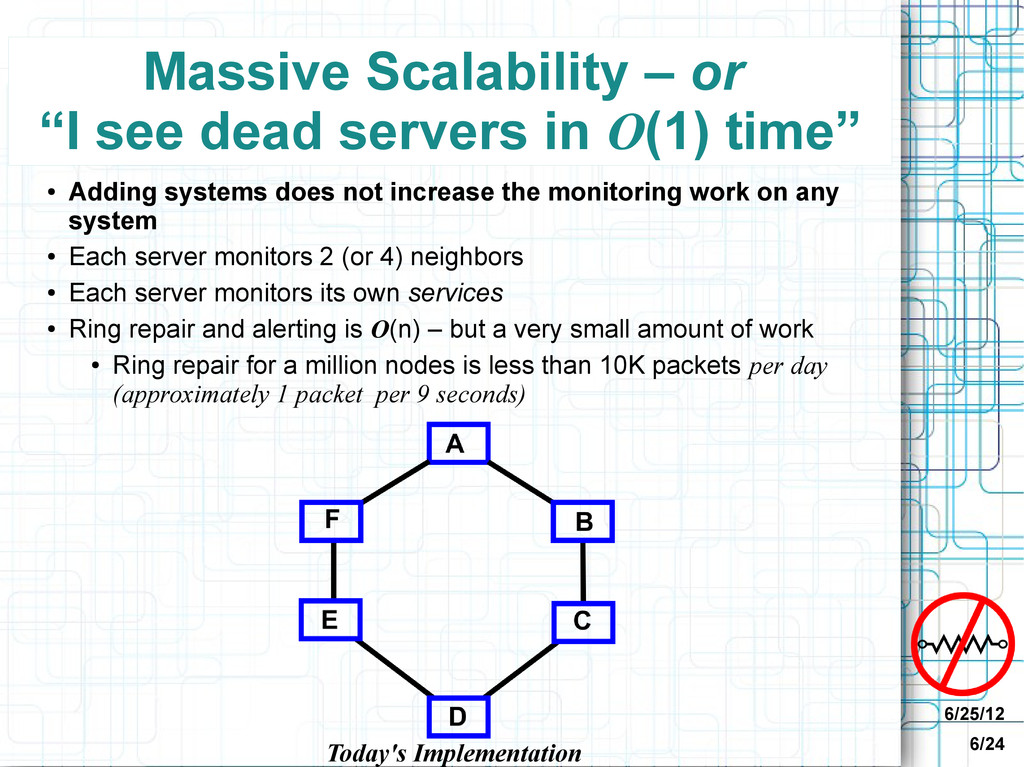
in O(1) time” • Adding systems does not increase the monitoring work on any system • Each server monitors 2 (or 4) neighbors • Each server monitors its own services • Ring repair and alerting is O(n) – but a very small amount of work • Ring repair for a million nodes is less than 10K packets per day (approximately 1 packet per 9 seconds) Today's Implementation
nicely into a huge cloud infrastructure – Should integrate into OpenStack, et al – Can also control VMs – already knows how to start, stop and migrate VMs • Can also monitor customer VMs – bottom level of rings probably disappear – unless LLDP or CDP is provided – If you add this to your base image, with one configuration file per customer, then no need to configure anything for basic monitoring.
things that aren't monitored • Dependencies simplify root cause analysis • Simplifies understanding the environment • “Forgotten” systems are implicated in about 1/3 of all break-ins • Simplifies license management for proprietary software (saves $$)
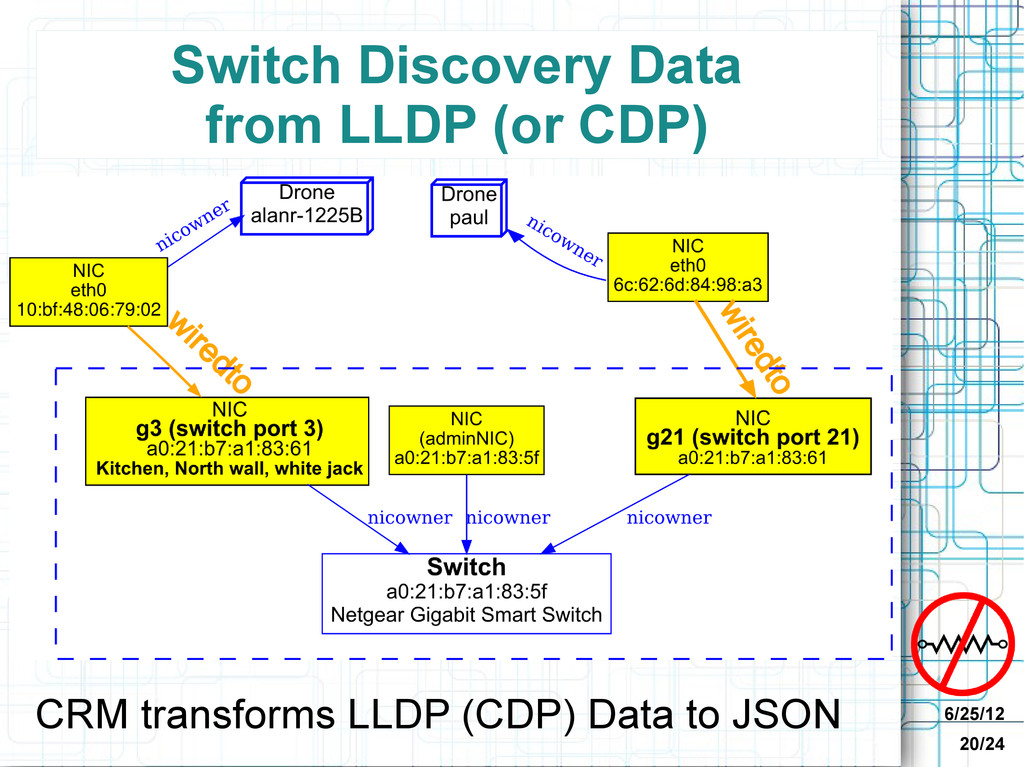
Integrated - Monitoring does discovery; stored in same database Stealth - No network privileges needed - no port scans or pings Discovery - Systems, switches, clients, services and dependencies ➔Up-to-date picture of pieces & how they work w/o “network security jail” :-D
LRM == Local Resource Manager • Well-proven architecture: “no news is good news” • Implements Open Cluster Framework standard (and others) • Each system monitors own services
Uniform work distribution No single point of failure Distinguishes switch vs host failure Easy on LAN, WAN Cons Active agents Potential slowness at power-on
Reserved multicast address (can be unicast address or name if no multicast) Do what CMA says • receive configuration information – CMA addresses, ports, defaults • send/expect heartbeats • perform discovery actions • perform monitoring actions No persistent state across reboots
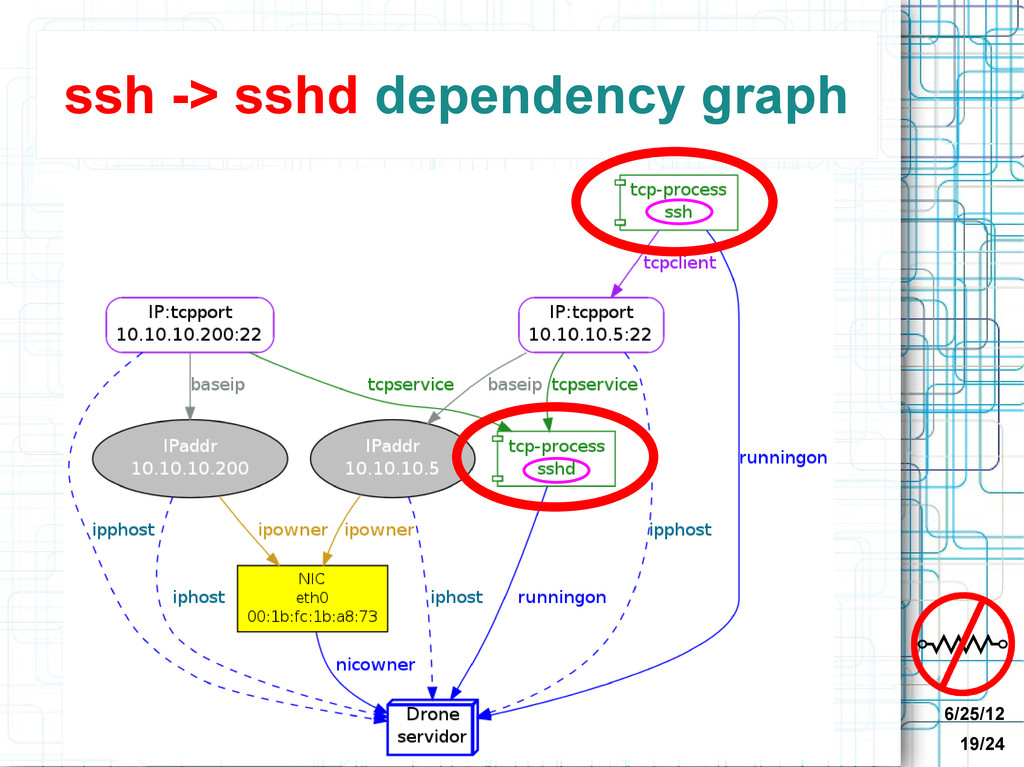
Discovery information: graph • Speed of graph traversals depends on size of subgraph, not total graph size • Root cause queries graph traversals – notoriously slow in relational databases • Visualization of relationships • Schema-less design: good for constantly changing heterogeneous environment
• Each discovers one kind of information • Can take arguments (in environment) • Output JSON CMA stores Discovery Information • JSON stored in Neo4j database • CMA discovery plugins => graph nodes and relationships
• Great unit test infrastructure • Nanoprobe code – works well • Service monitoring works • Lacking digital signatures, encryption, compression • Reliable UDP comm code all working • CMA code works, much more to go • Several discovery methods written • Licensed under the GPL
year • Commercial licenses with support • “Real digital signatures, compression, encryption • Other security enhancements • Dynamic (aka cloud) specialization • Much more discovery • Alerting • GUI • Reporting • Create/audit an ITIL CMDB • Add Statistical Monitoring • Best Practice Audits • Hundreds more ideas – See: https://trello.com/b/OpaED3AT
project Needs for every kind of skill • Awesome User Interfaces (UI/UX) • Test Code (simulate 106 servers!) • Packaging, Continuous Integration • Python, C, script coding • Evangelism, community building • Documentation • Integration with OpenStack • Feedback: Testing, Ideas, Plans • Many others!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}