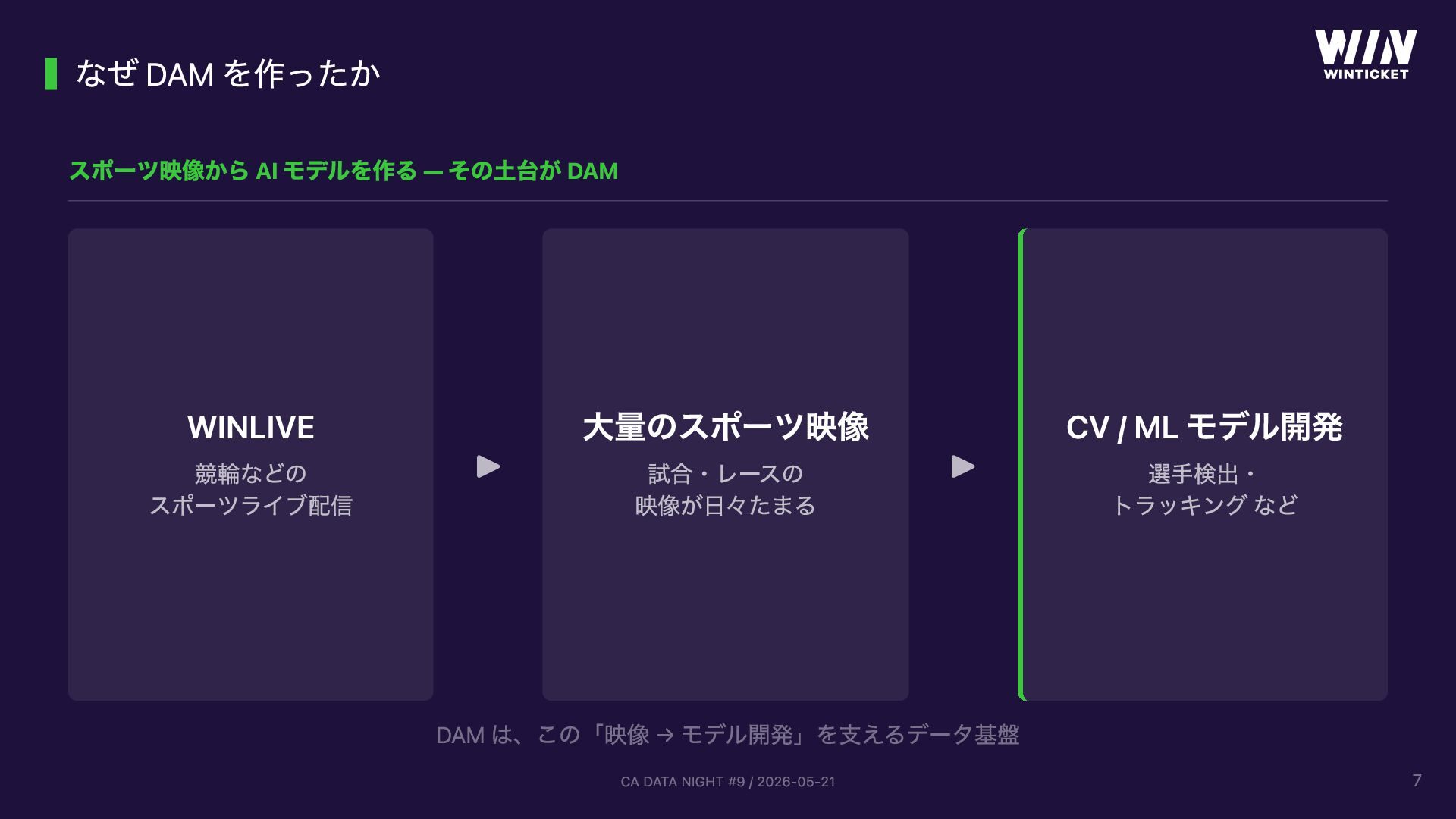
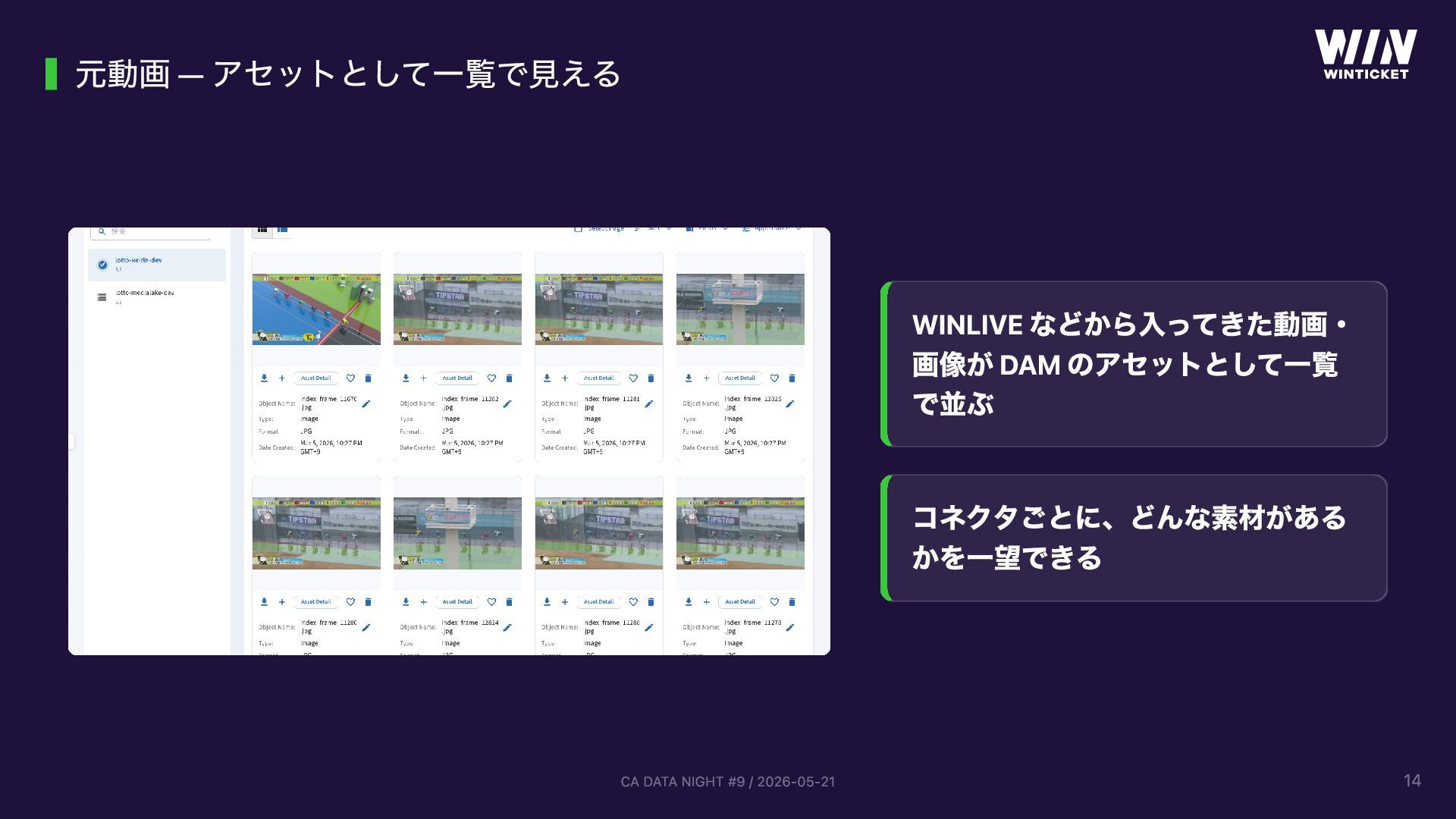
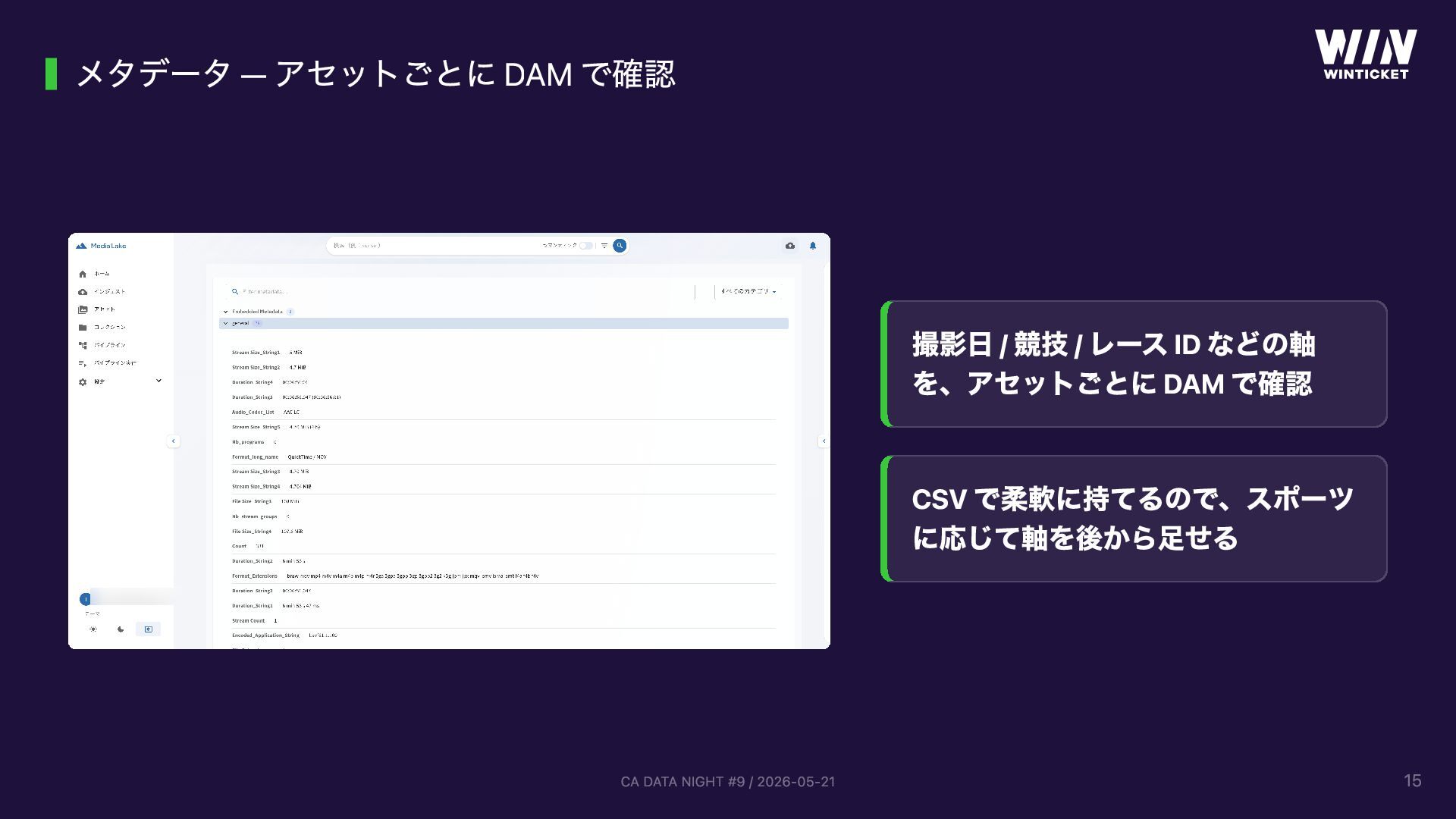
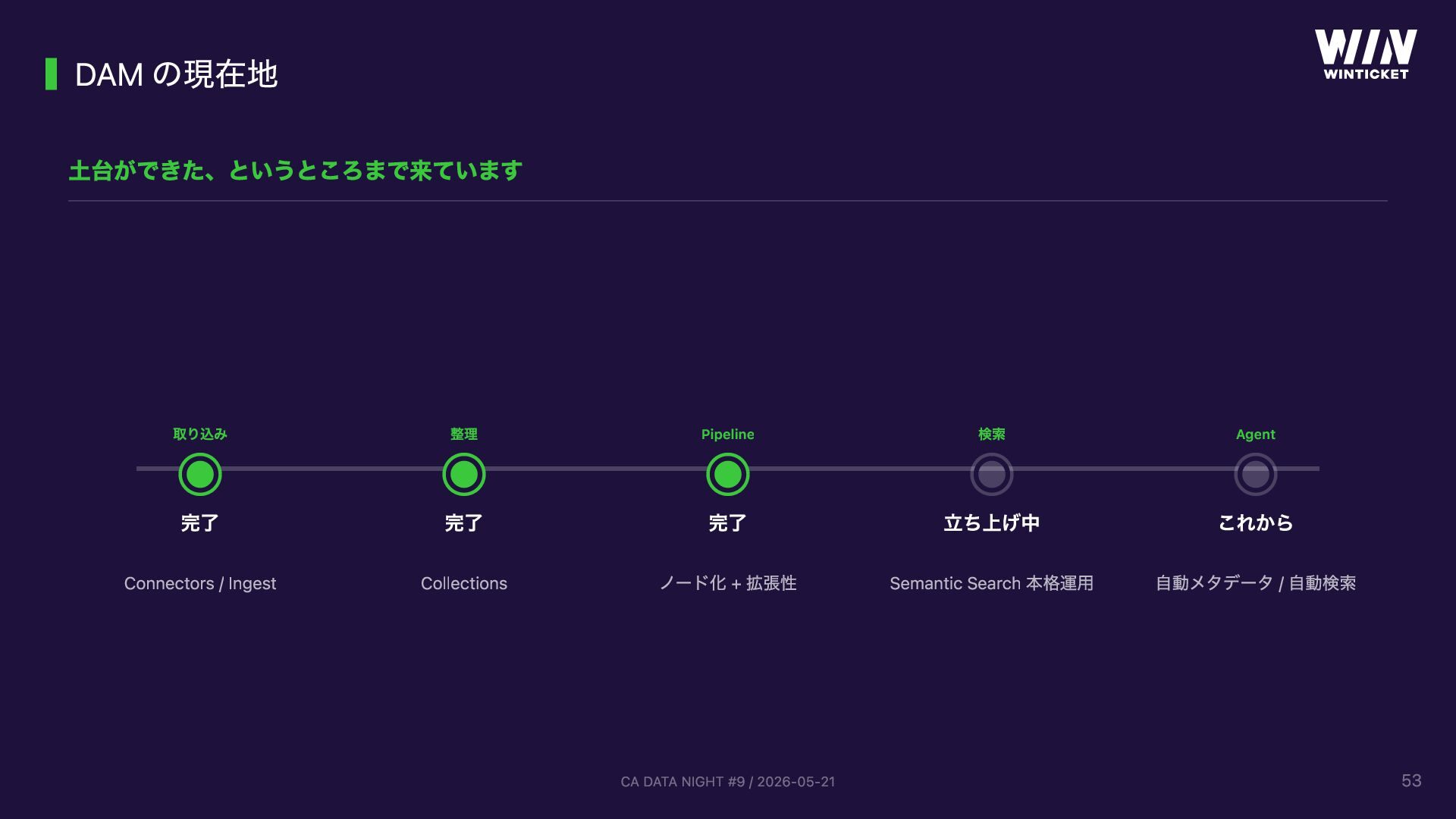
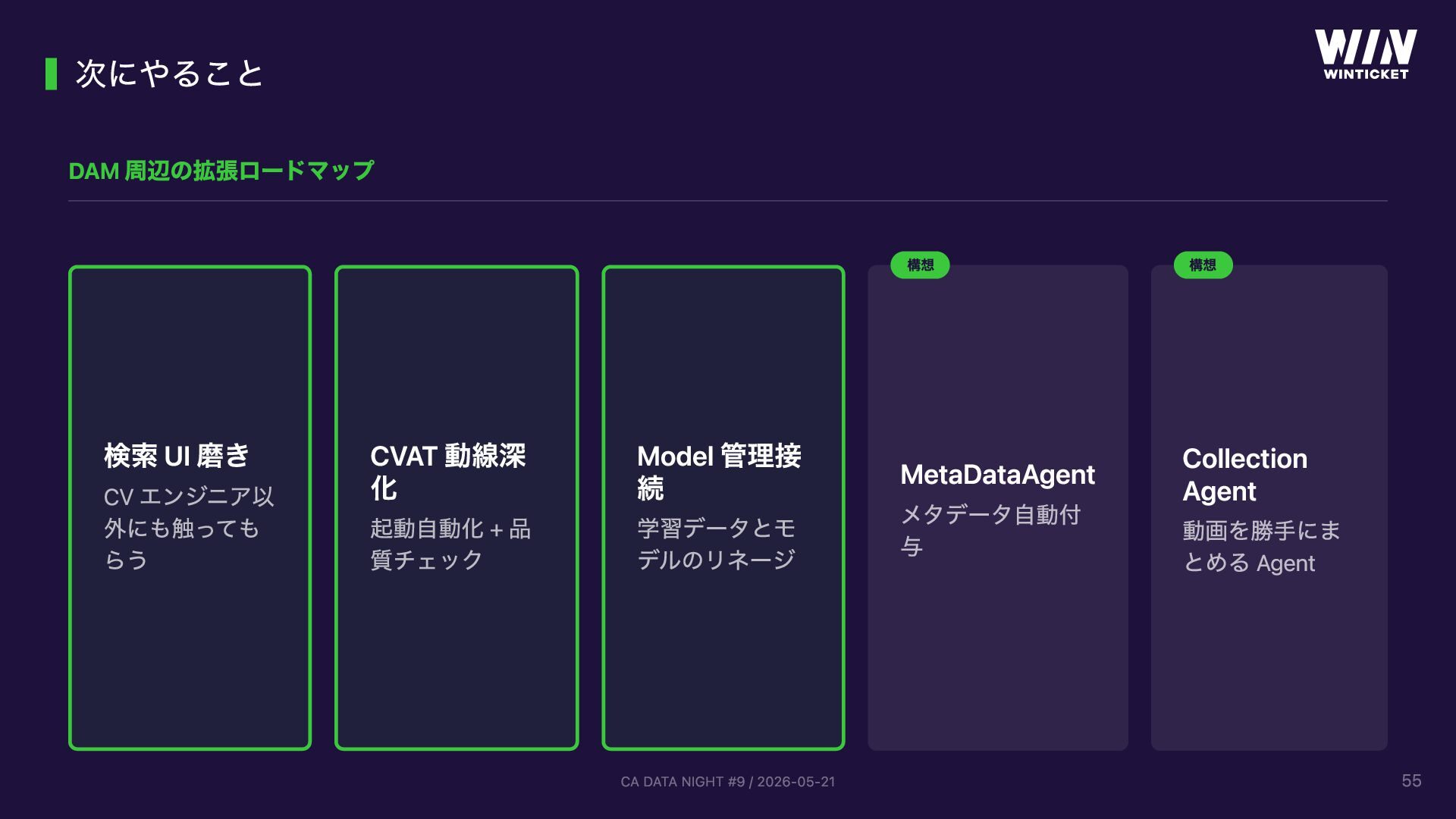
WinTicket スポーツ映像テック事業部で開発する「動画データ管理基盤 (DAM)」の話。競輪 WINLIVE / ABEMA × ボクシングなどスポーツ中継の映像から ML/CV モデル開発を支えるため、AWS MediaLake OSS をベースにサーバーレスで構築しています。GUI でパイプラインを組み立てる仕組み、Lambda としてカスタムノードを追加できる拡張性、CVAT アノテーションの自動連携、TwelveLabs Marengo + OpenSearch によるセマンティック検索などを実装。「動画の管理・整理・検索といった汎用化できる工程は基盤に任せ、ML/CV エンジニアは本来のモデル開発に集中できる」という思想で設計しています。CA DATA NIGHT #9 (2026-05-21) 登壇資料。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
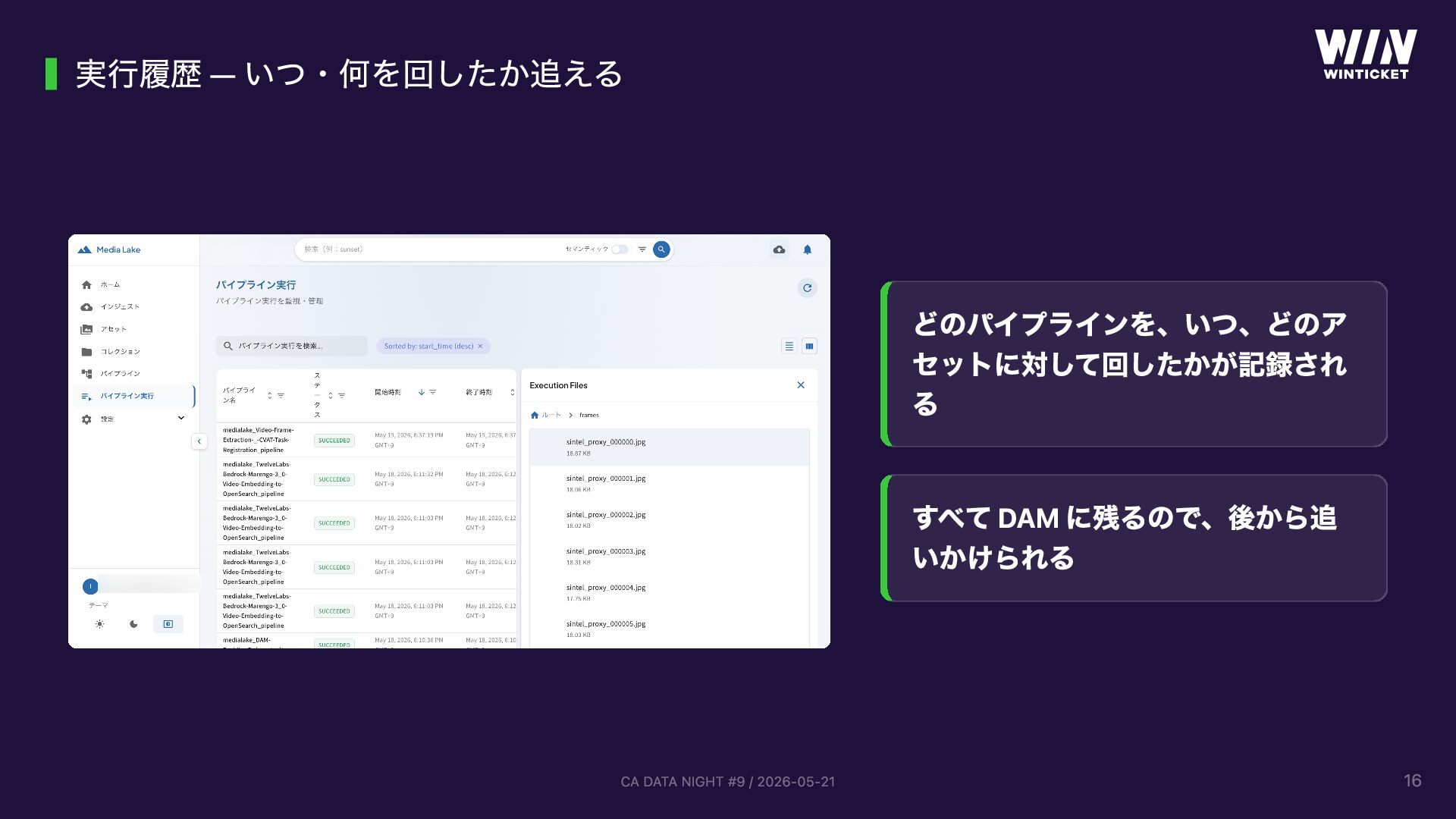{kind=link}
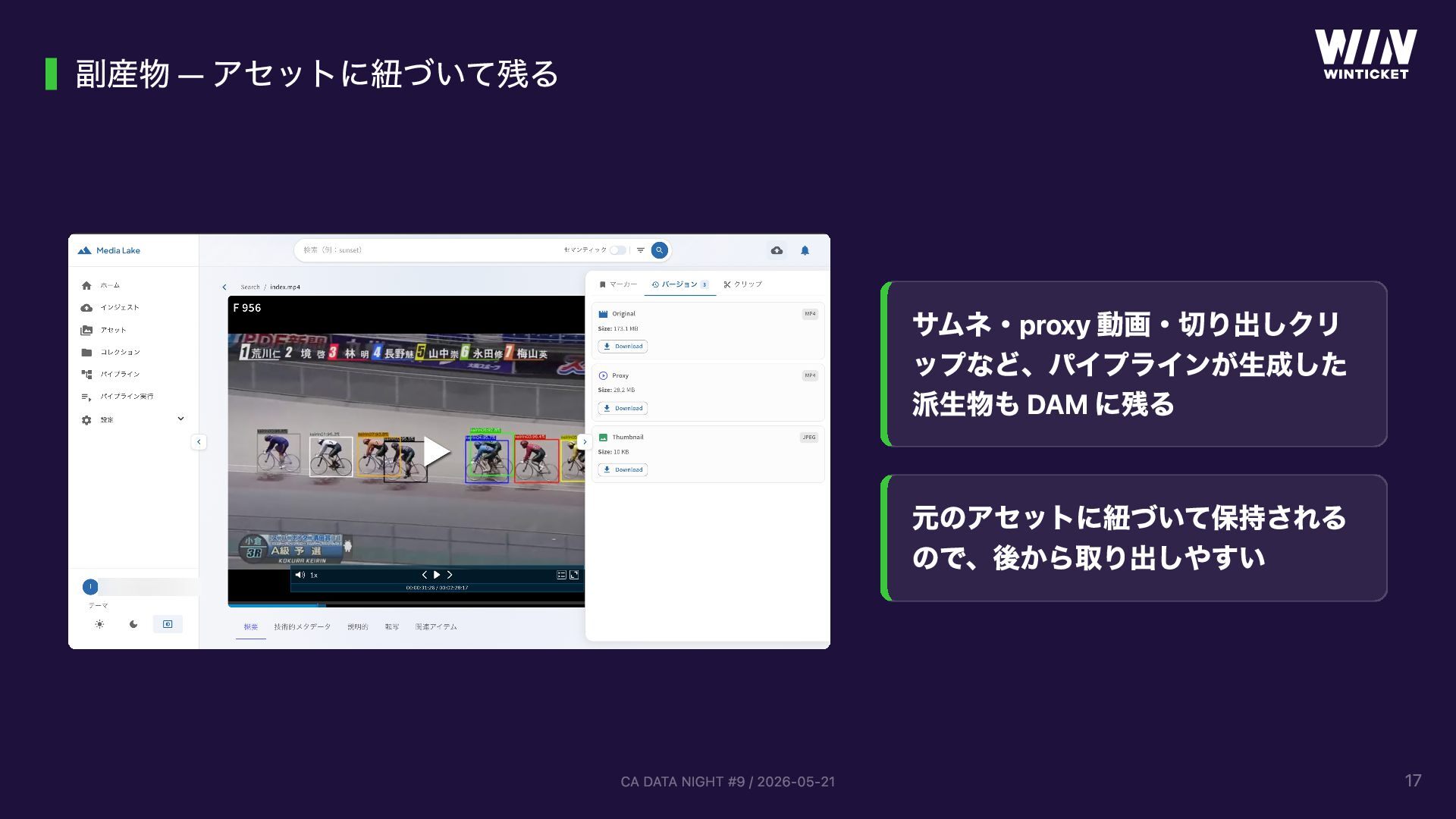{kind=link}
{kind=link}
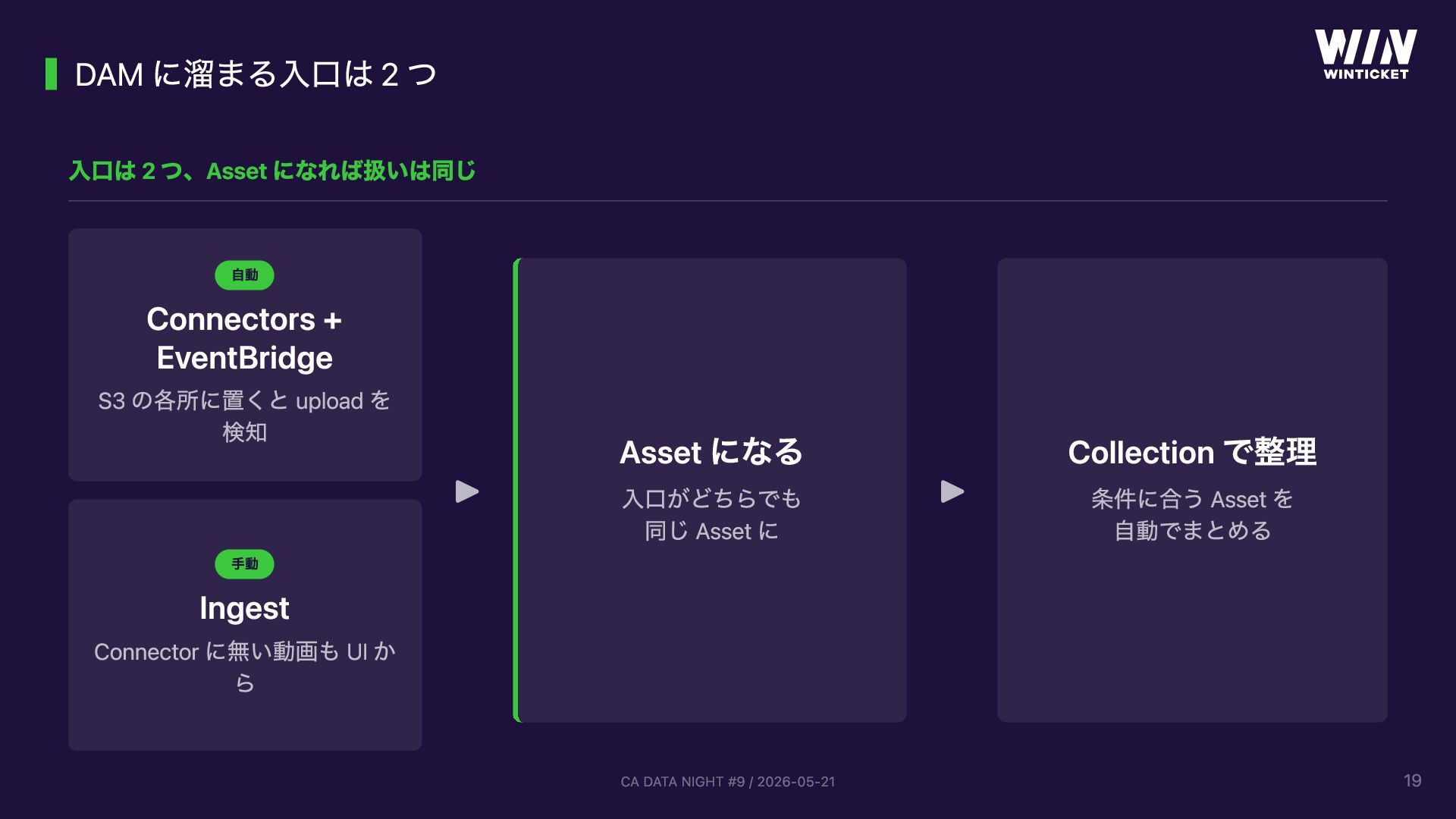{kind=link}
{kind=link}
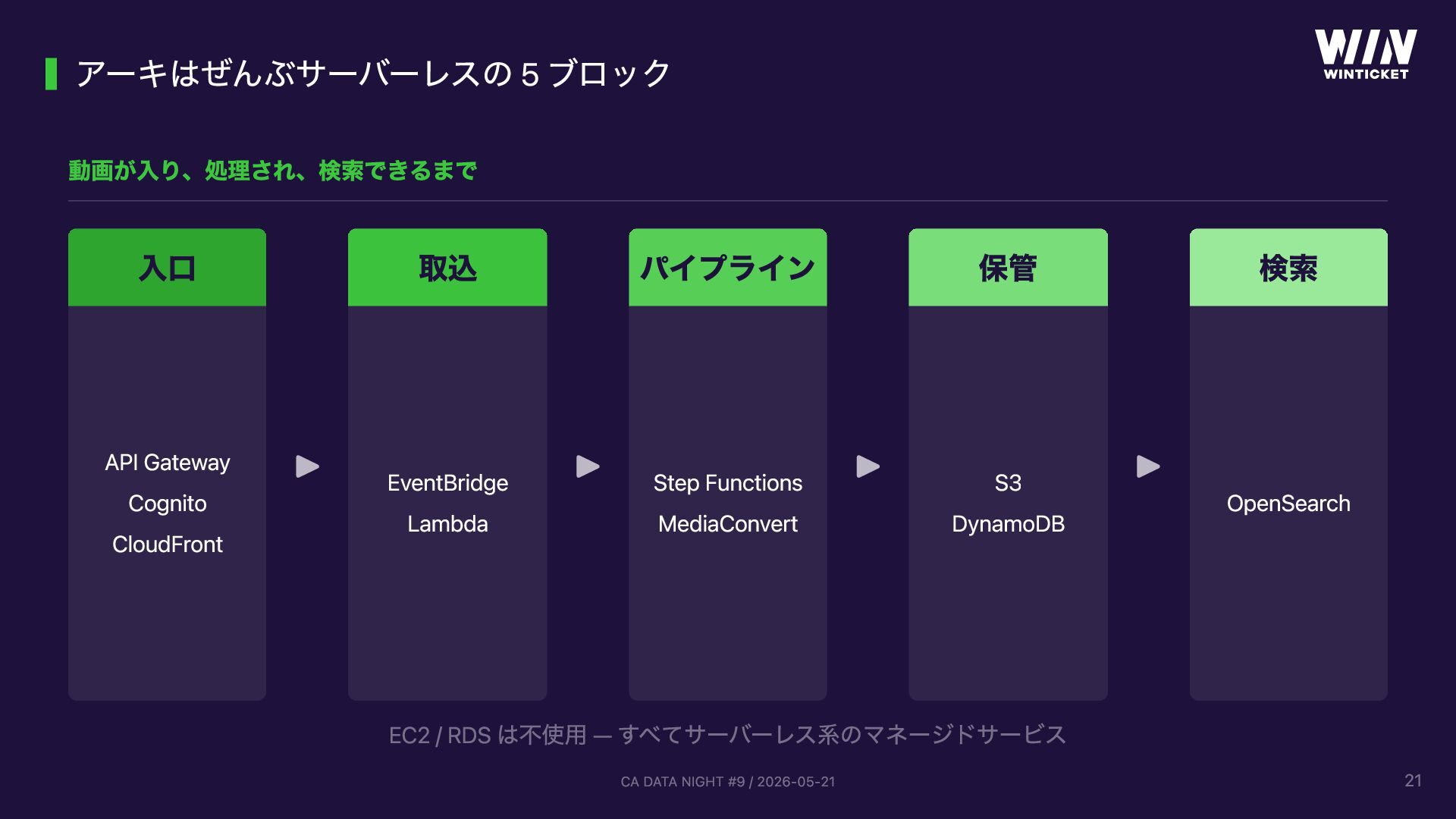{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
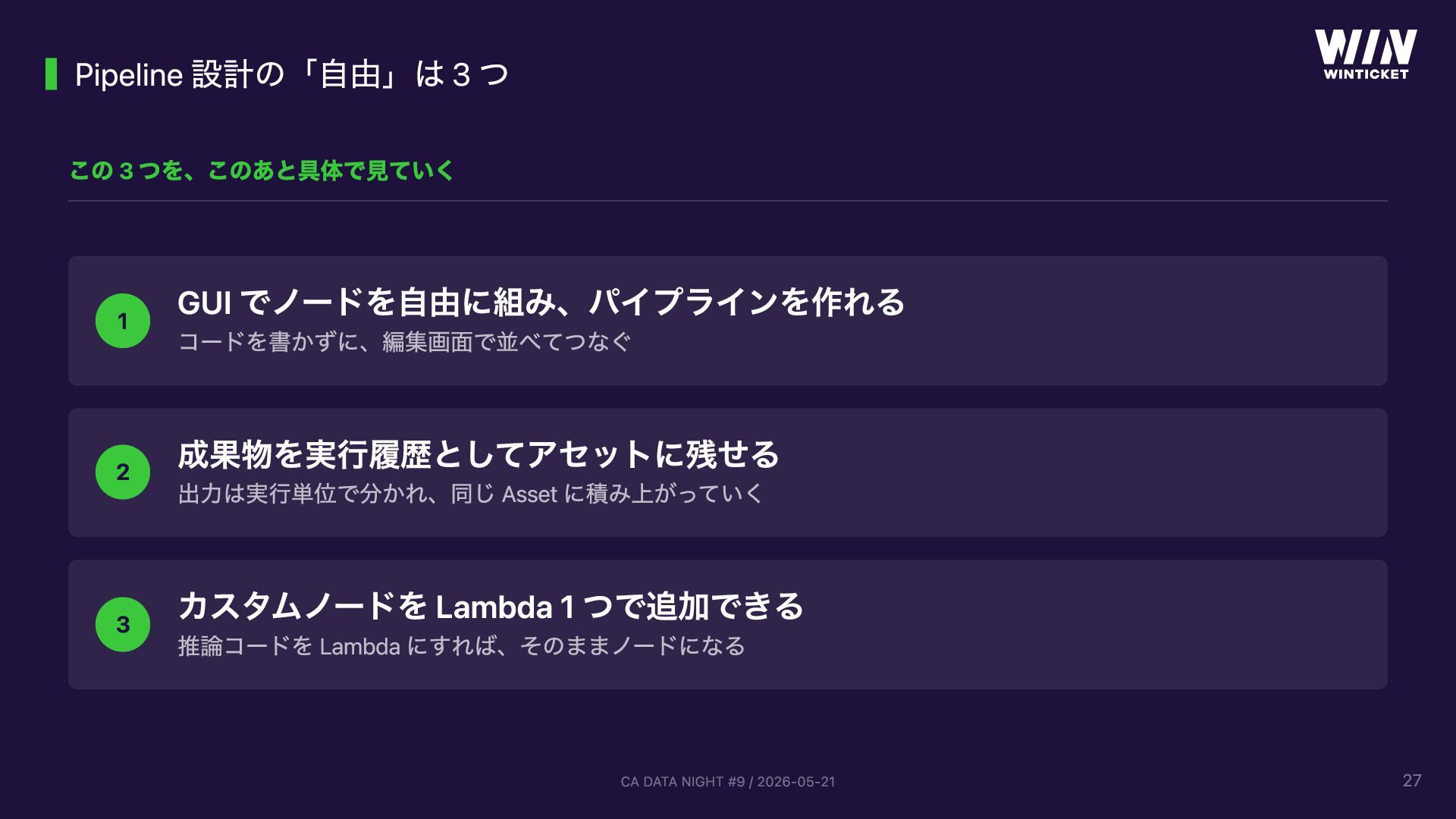{kind=link}
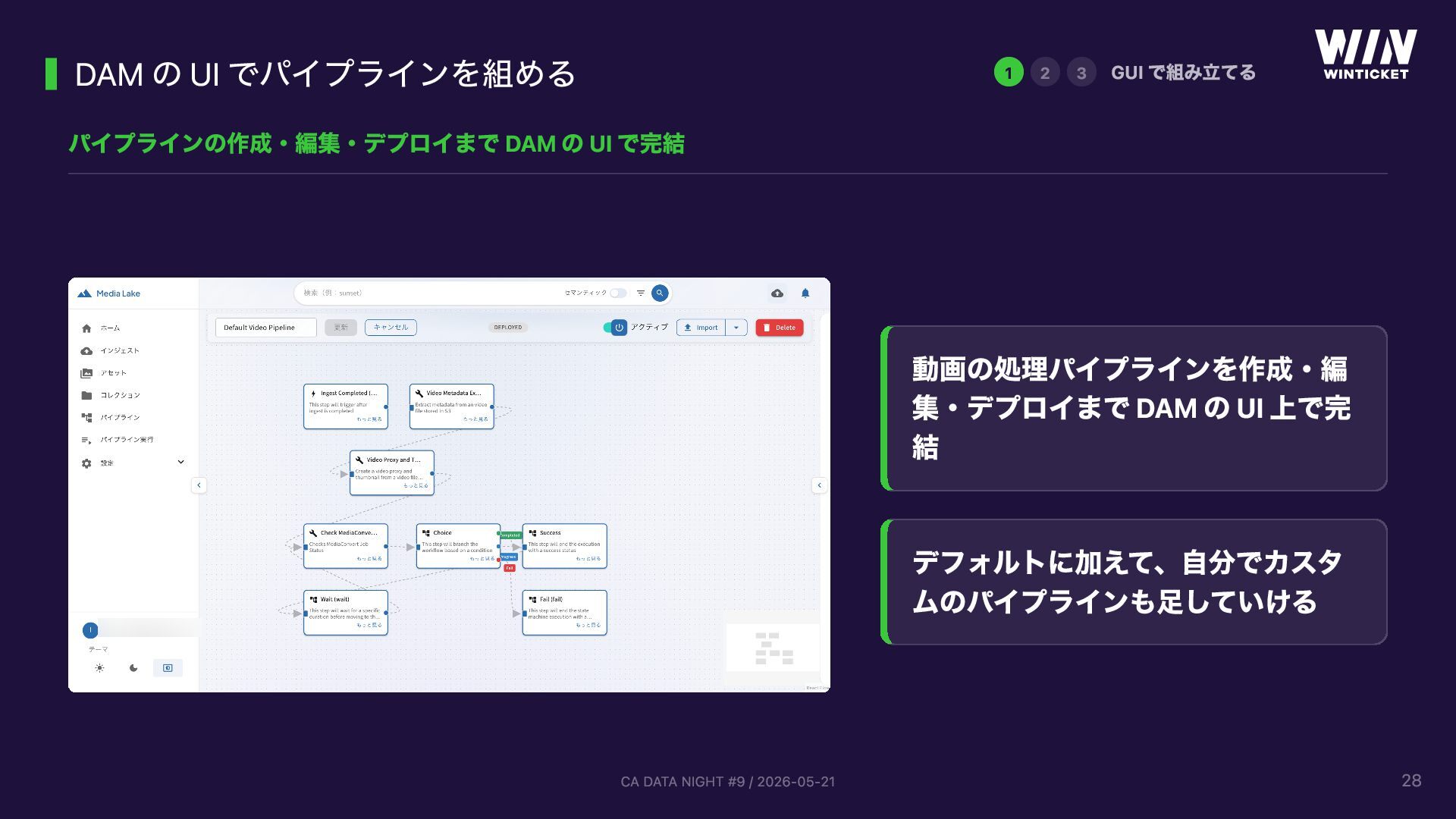{kind=link}
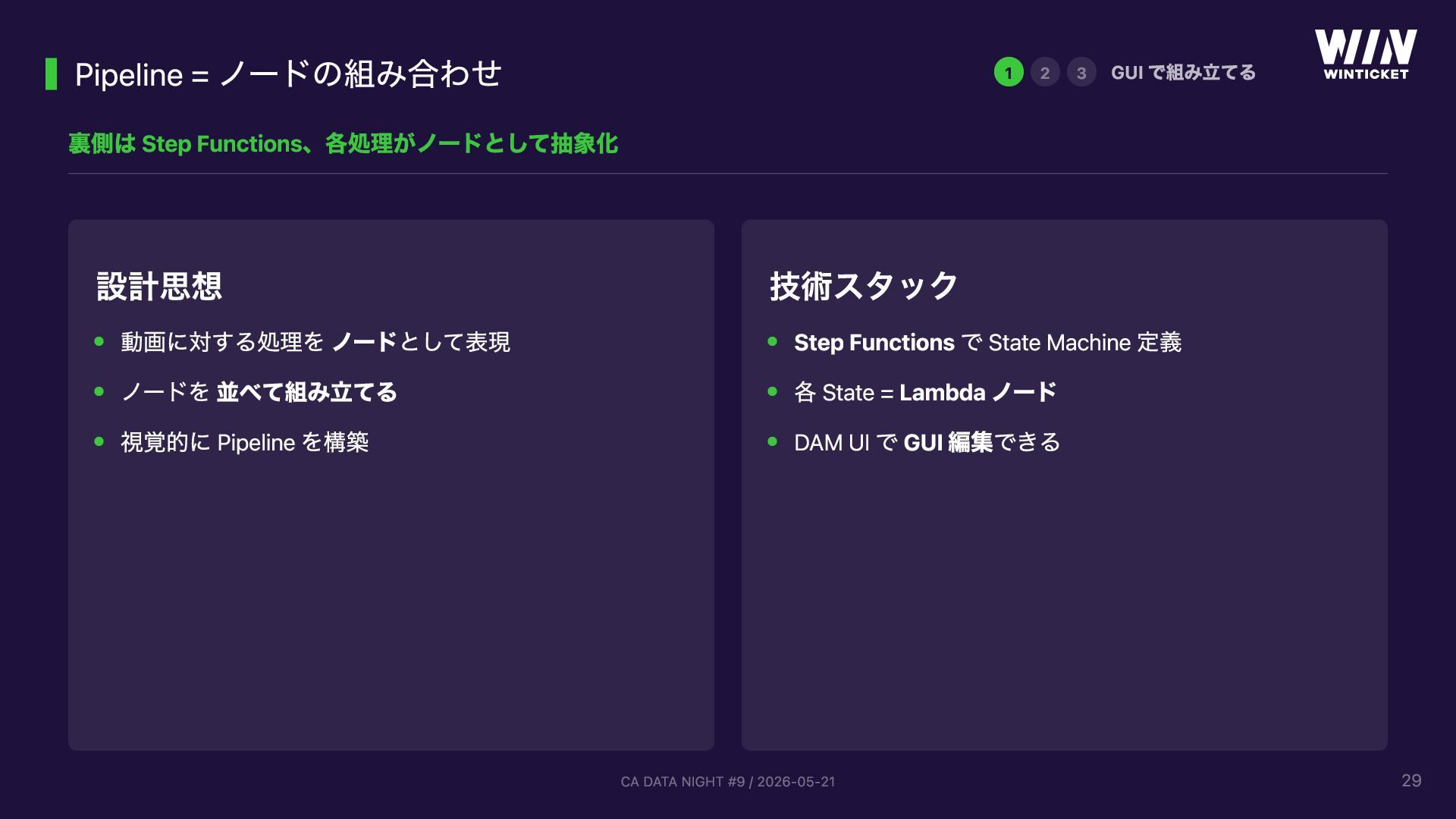{kind=link}
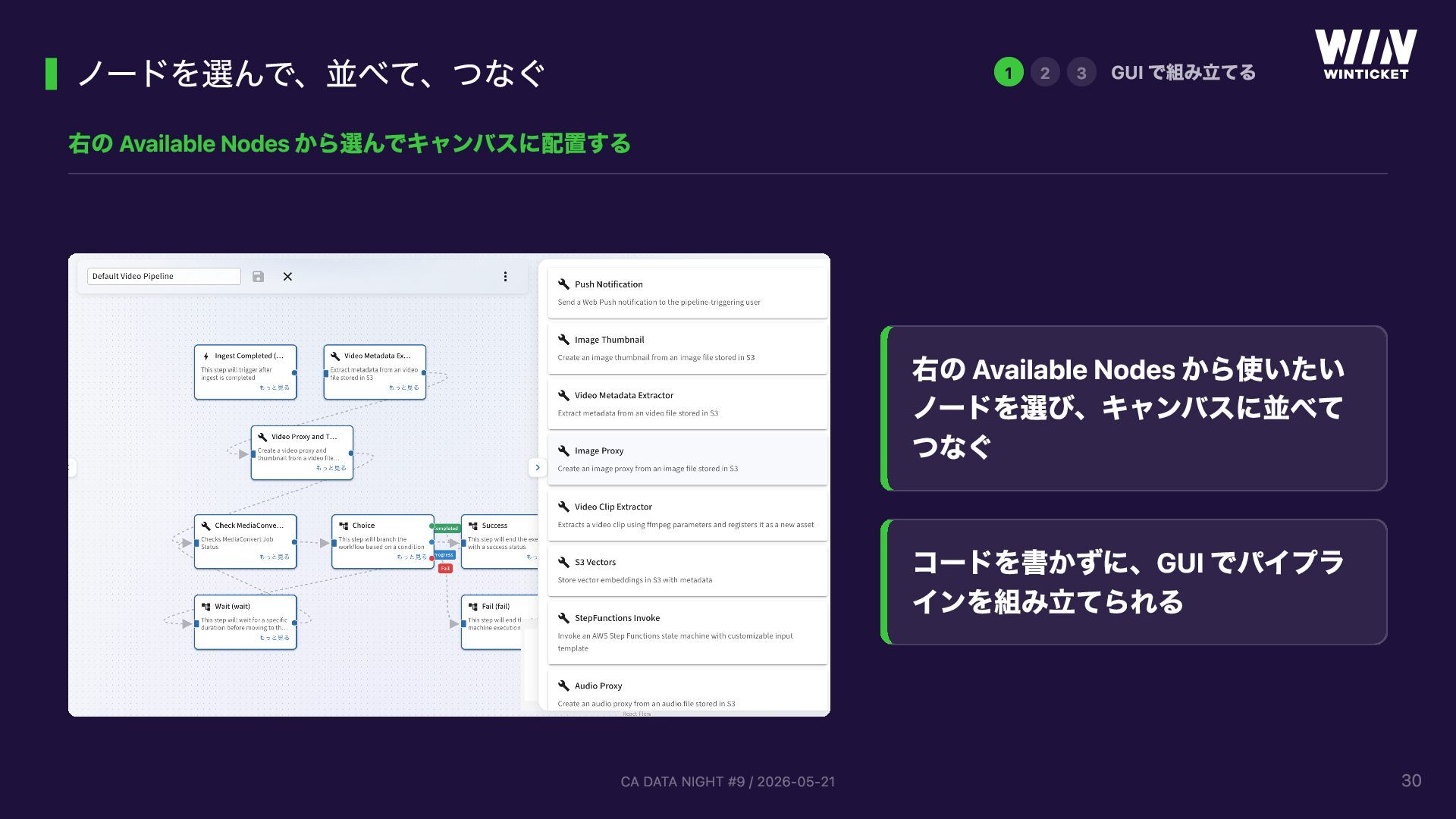{kind=link}
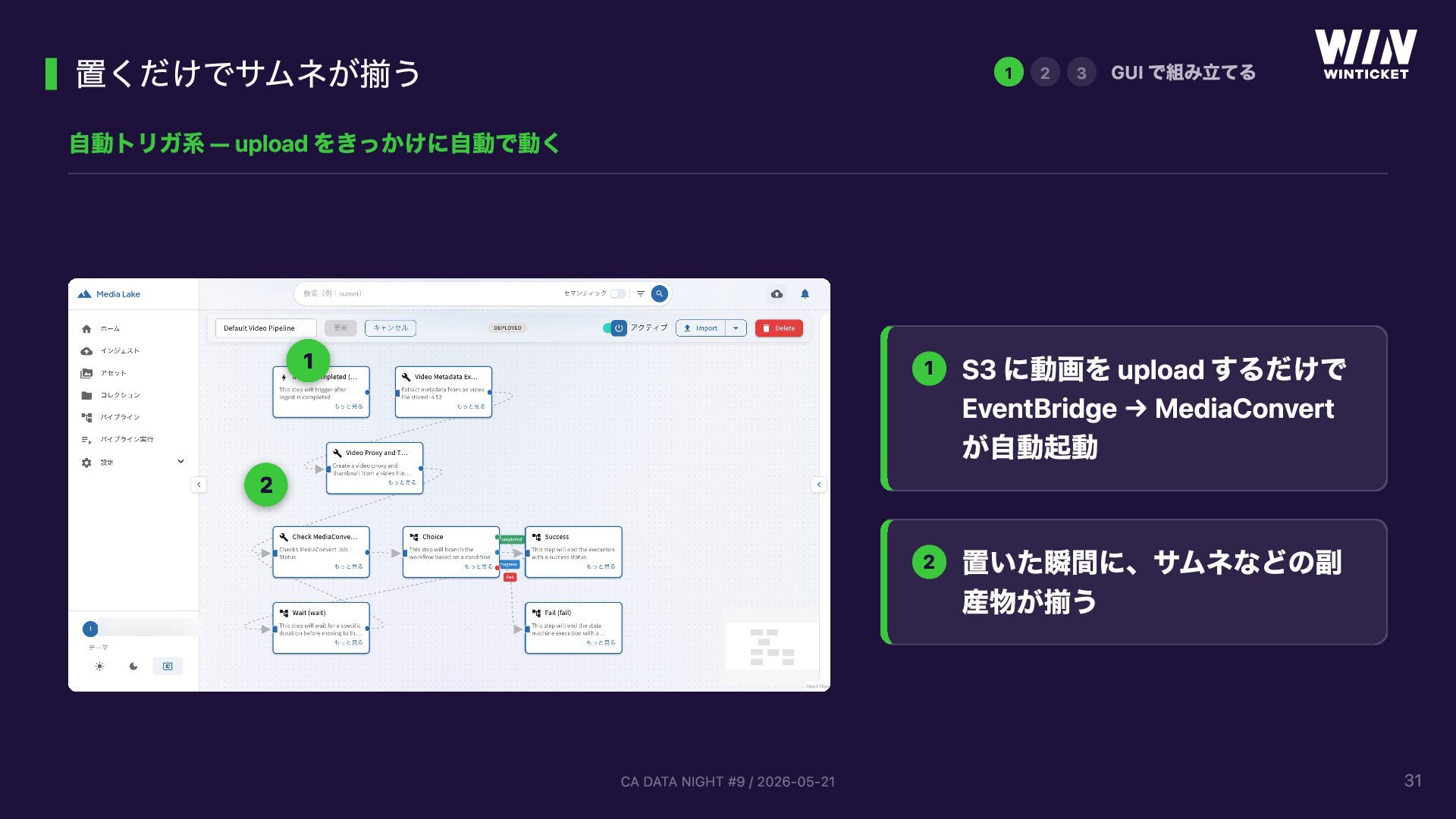{kind=link}
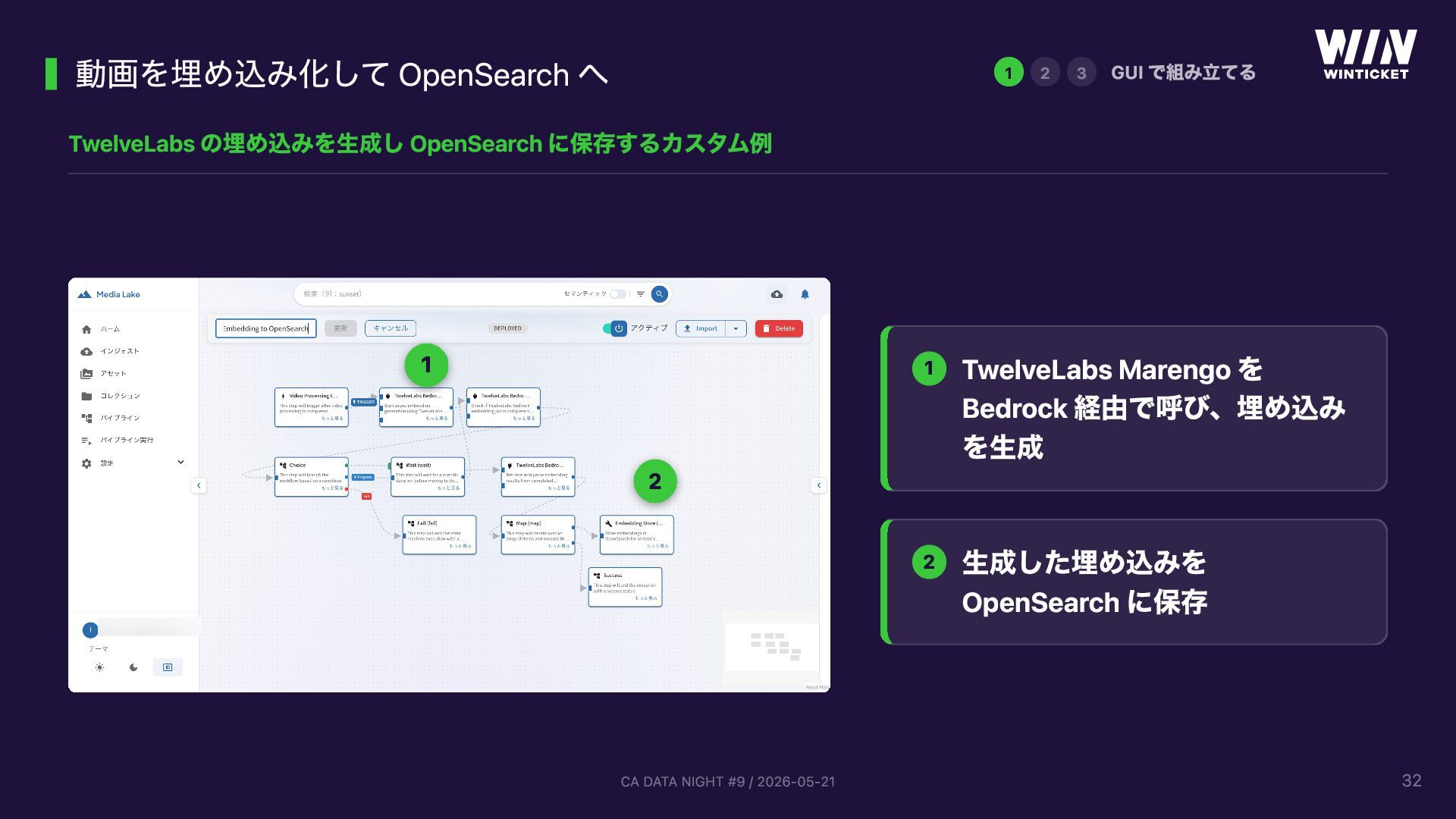{kind=link}
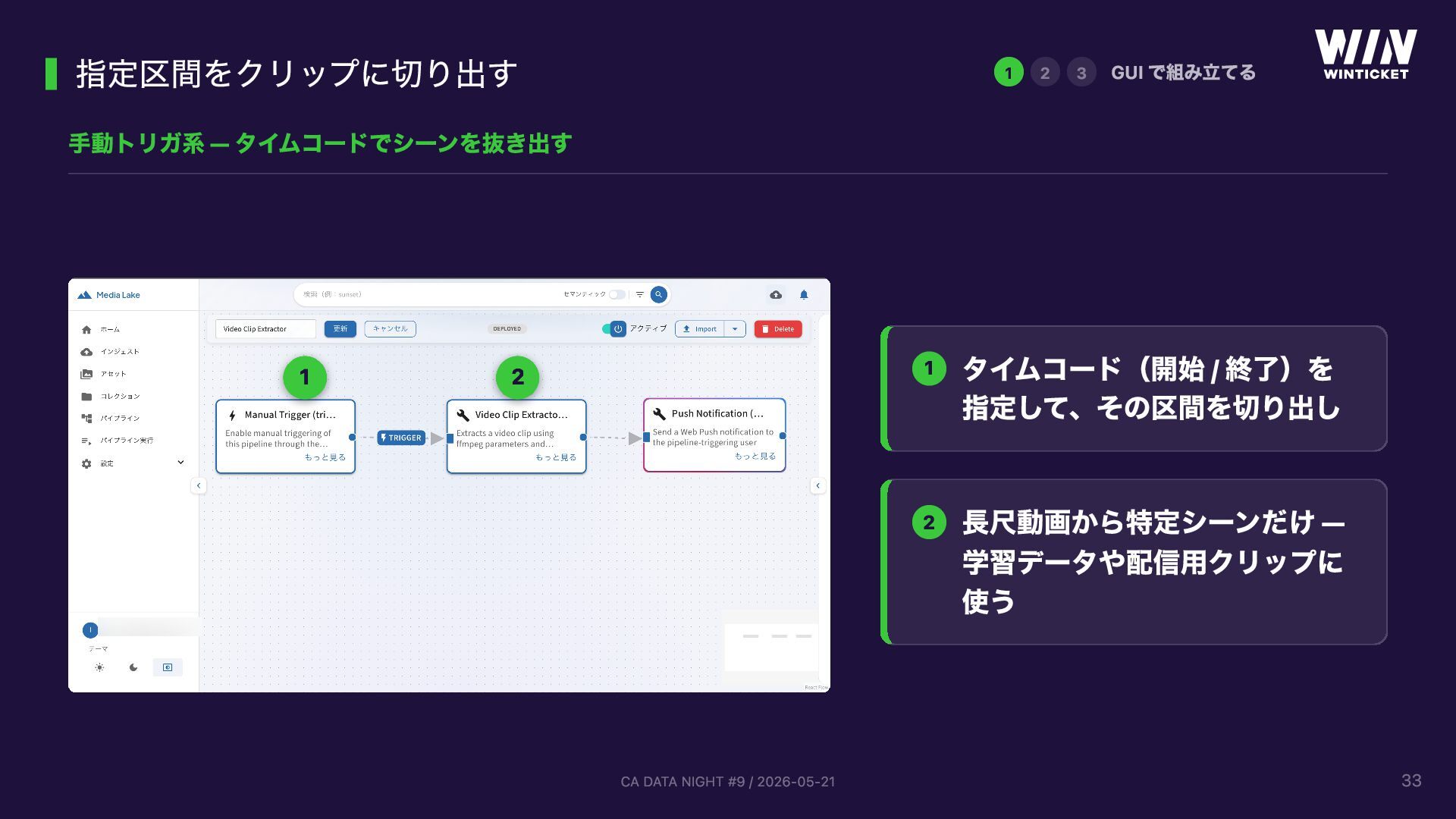{kind=link}
{kind=link}
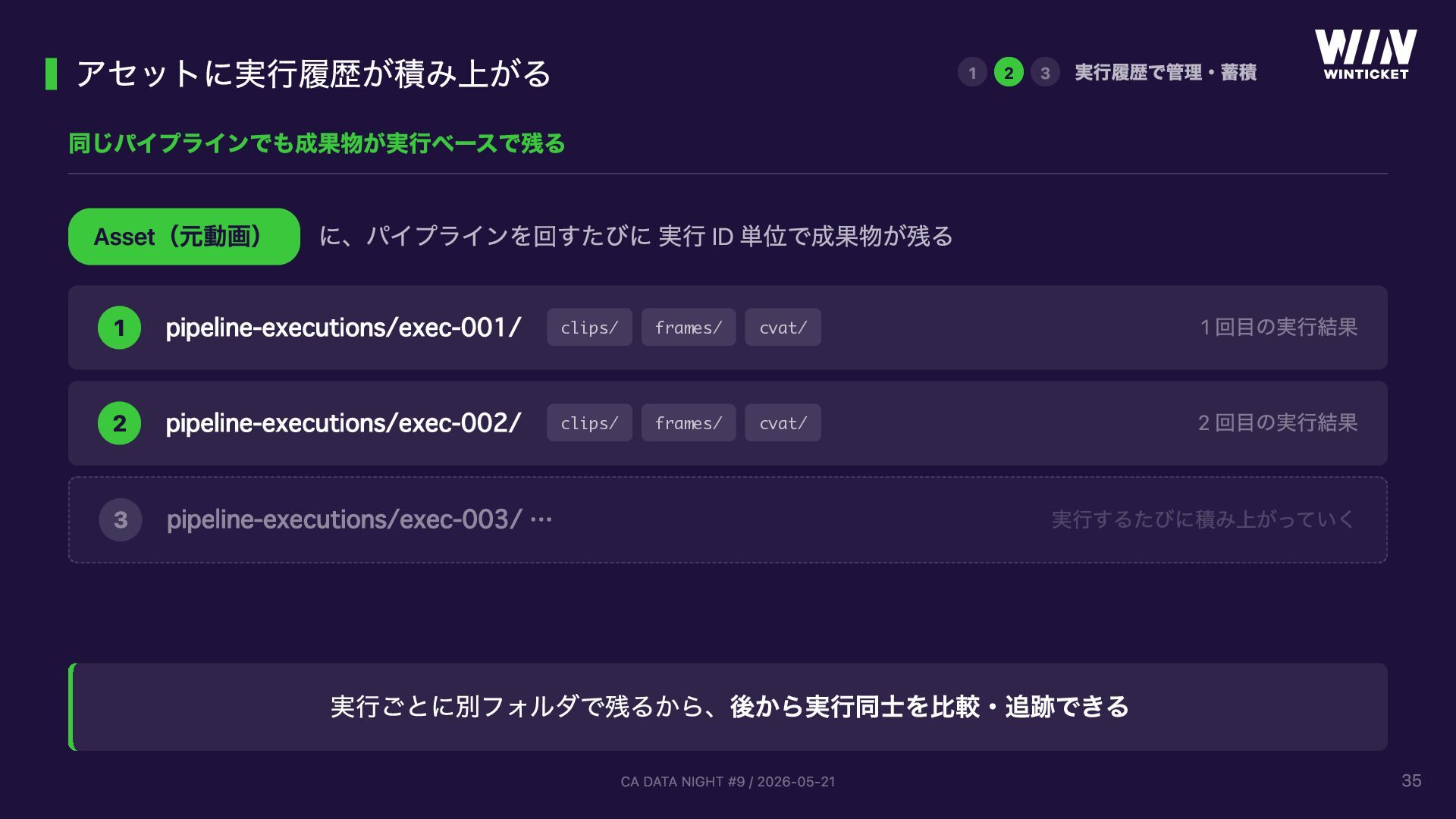{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
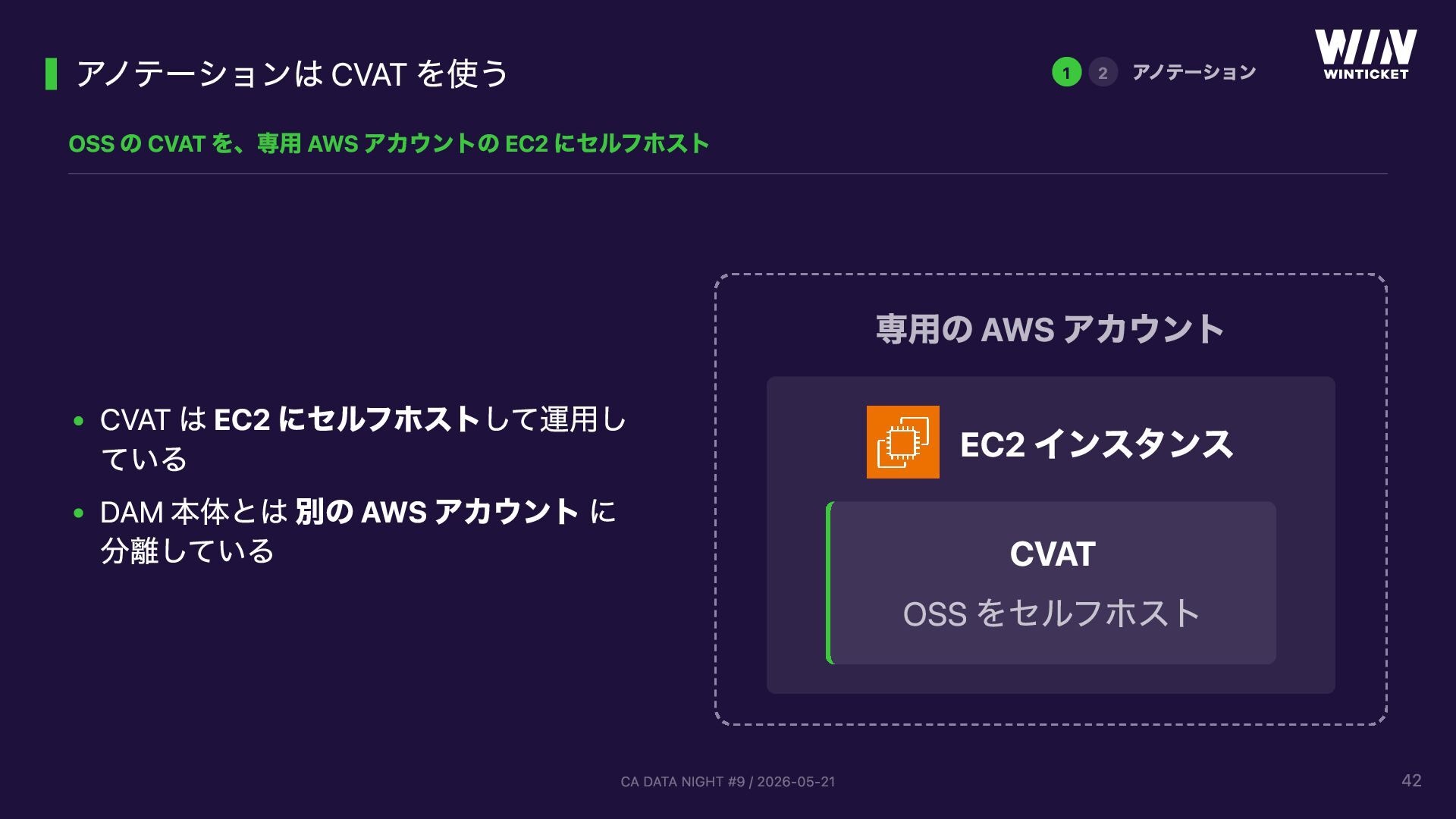{kind=link}
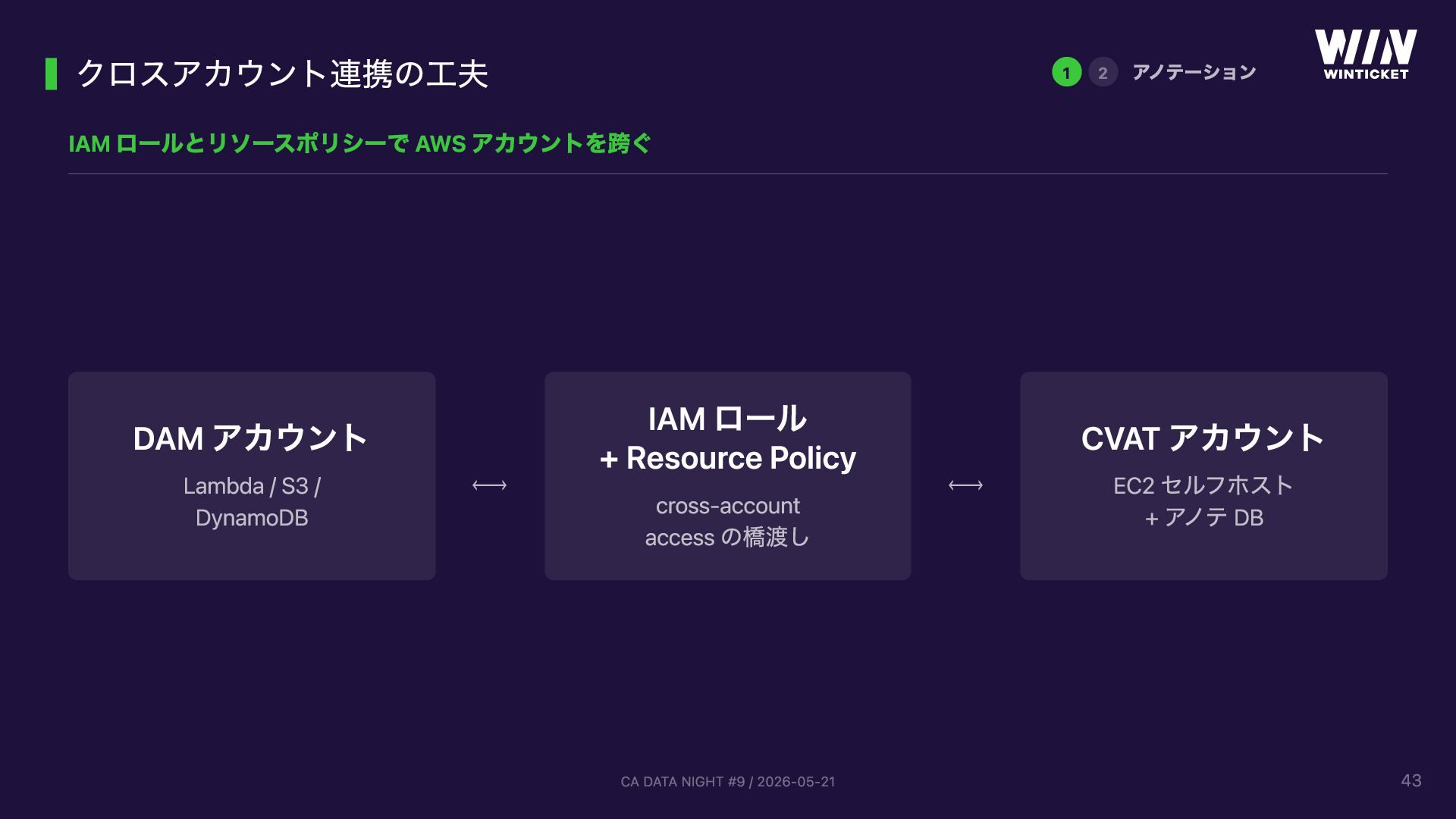{kind=link}
{kind=link}
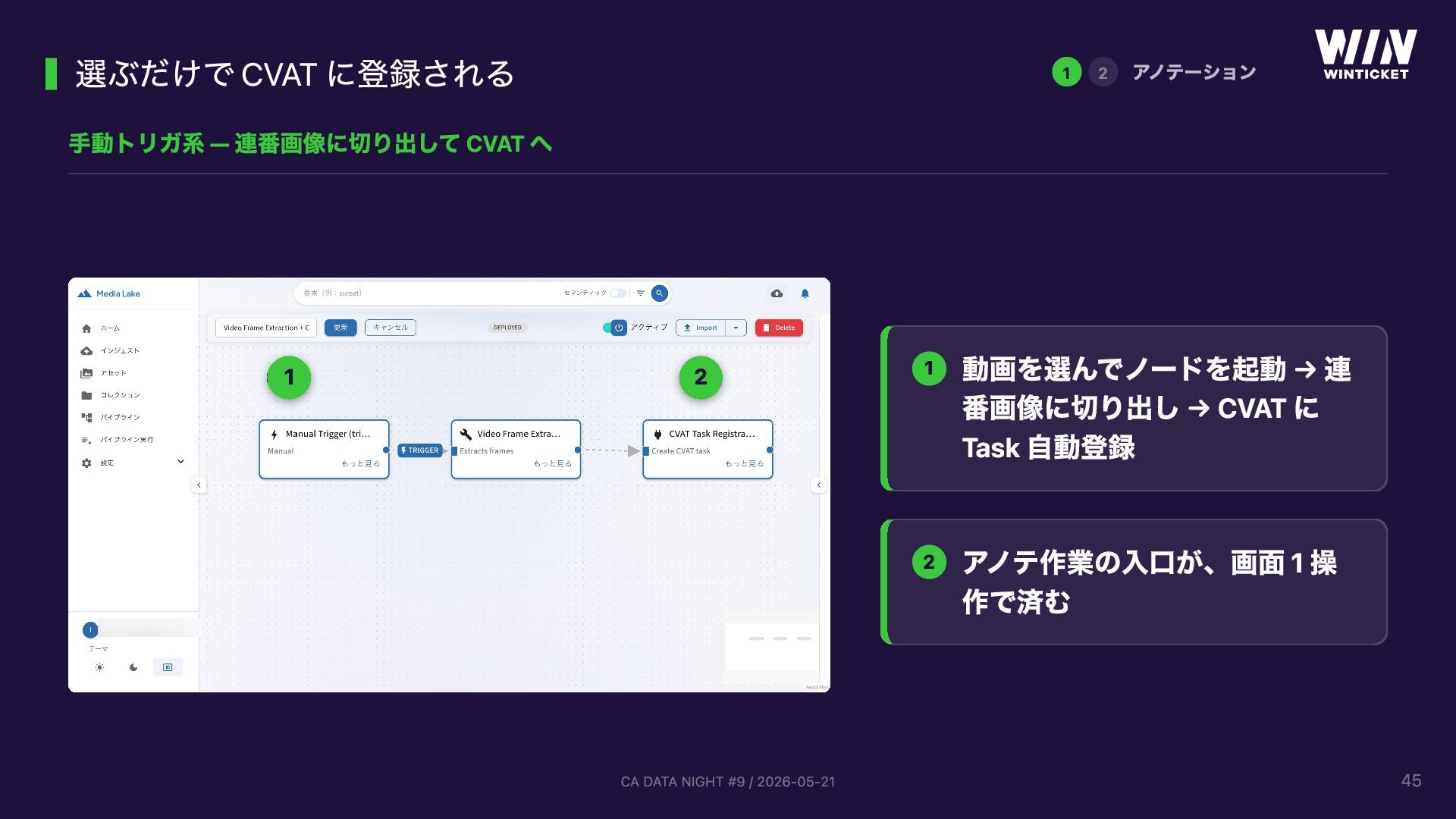{kind=link}
{kind=link}
{kind=link}
{kind=link}
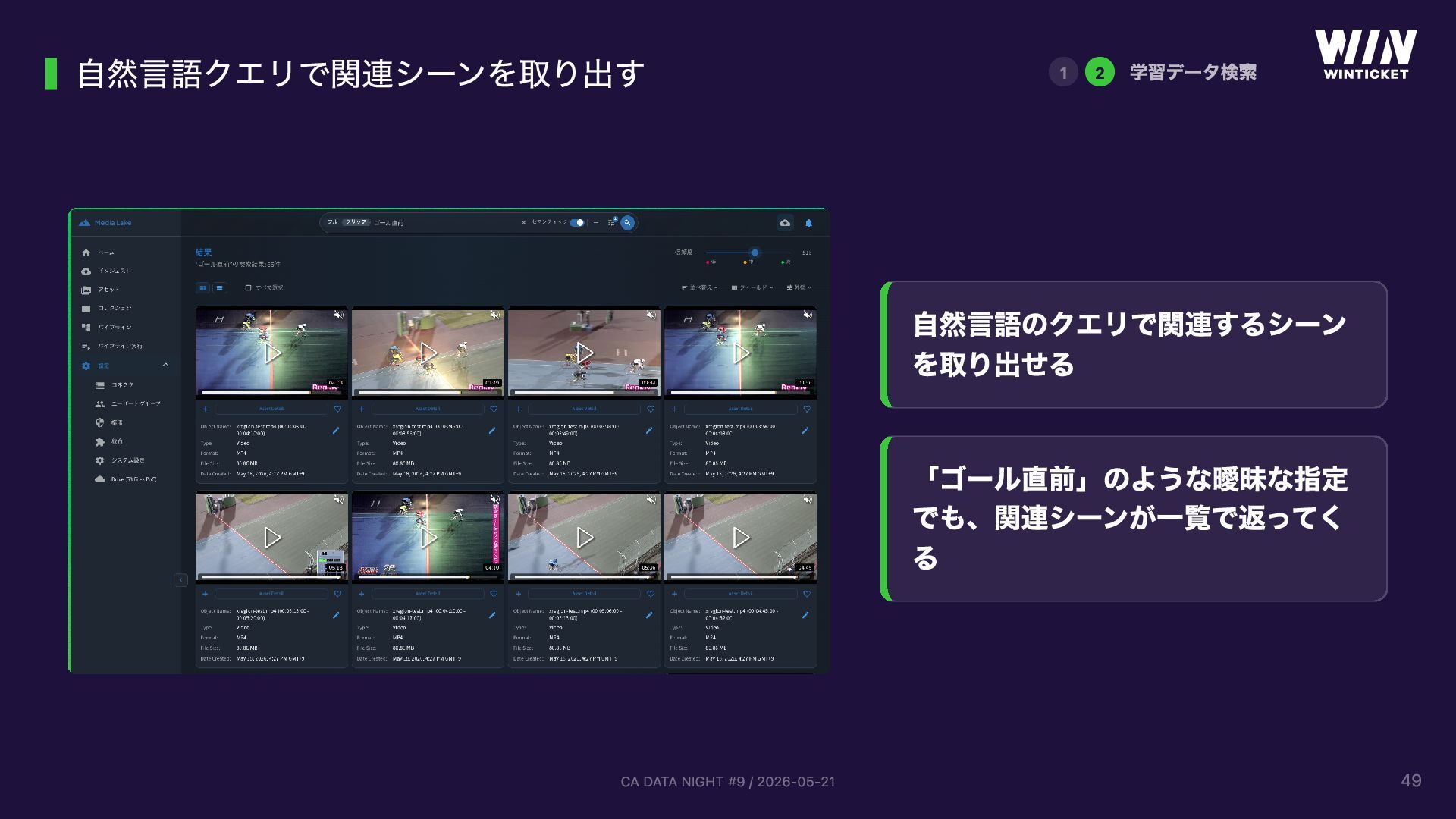{kind=link}
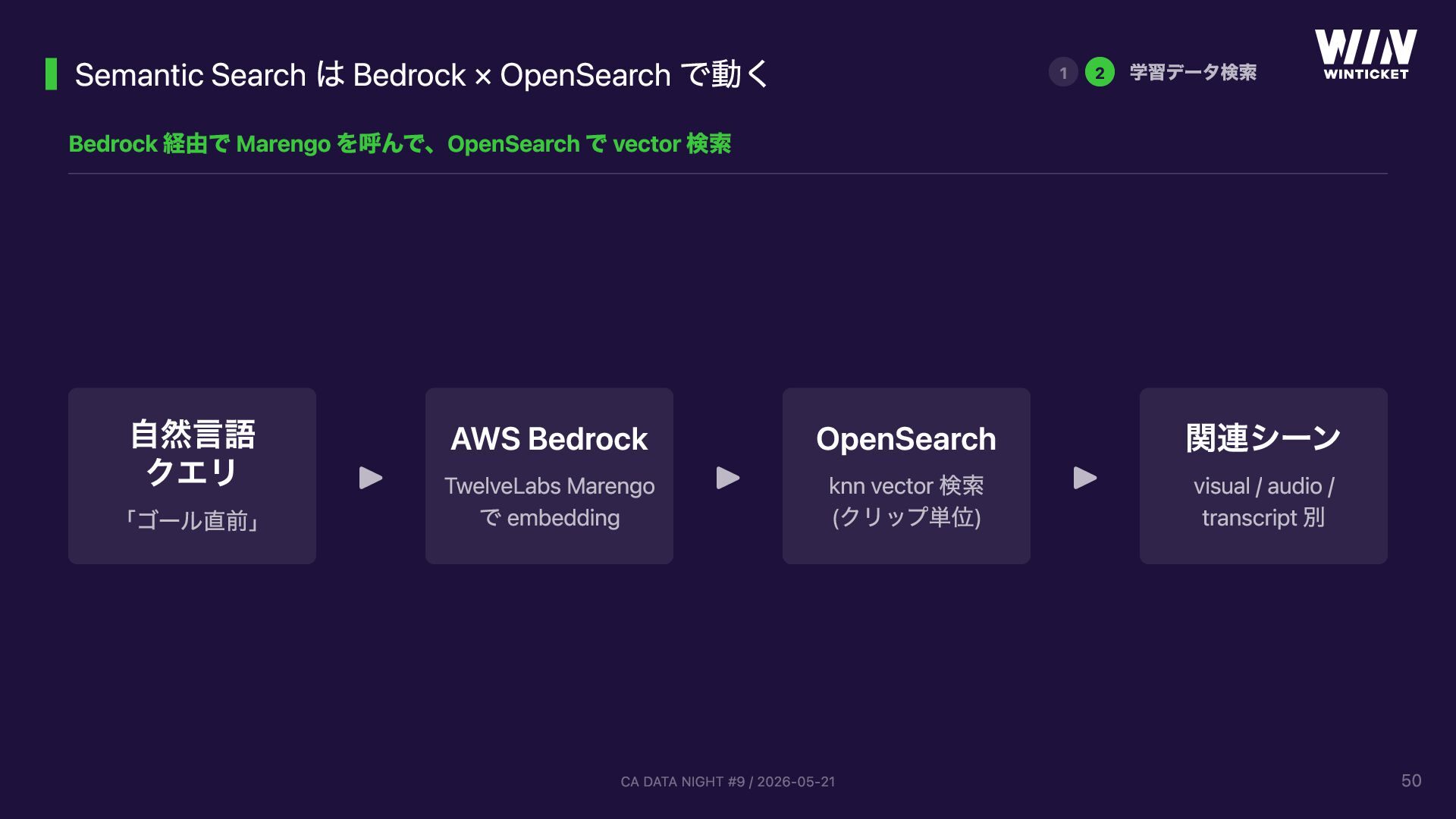{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}