Joel VanderWerf stops by to talk about Calvin. This time we have 3 relevant papers:
• Calvin: Fast Distributed Transactions for Partitioned Database Systems, SIGMOD 2012 by Alexander Thomson, Thaddeus Diamond, Shu-Chun Weng, Kun Ren, Philip Shao, and Daniel J. Abadi.
• Consistency Tradeoffs in Modern Distributed Database System Design, 2012 by Daniel J. Abadi.
• Modularity and Scalability in Calvin, IEEE 2013 by Alexander Thomson and Daniel J. Abadi.
Video link coming soon!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
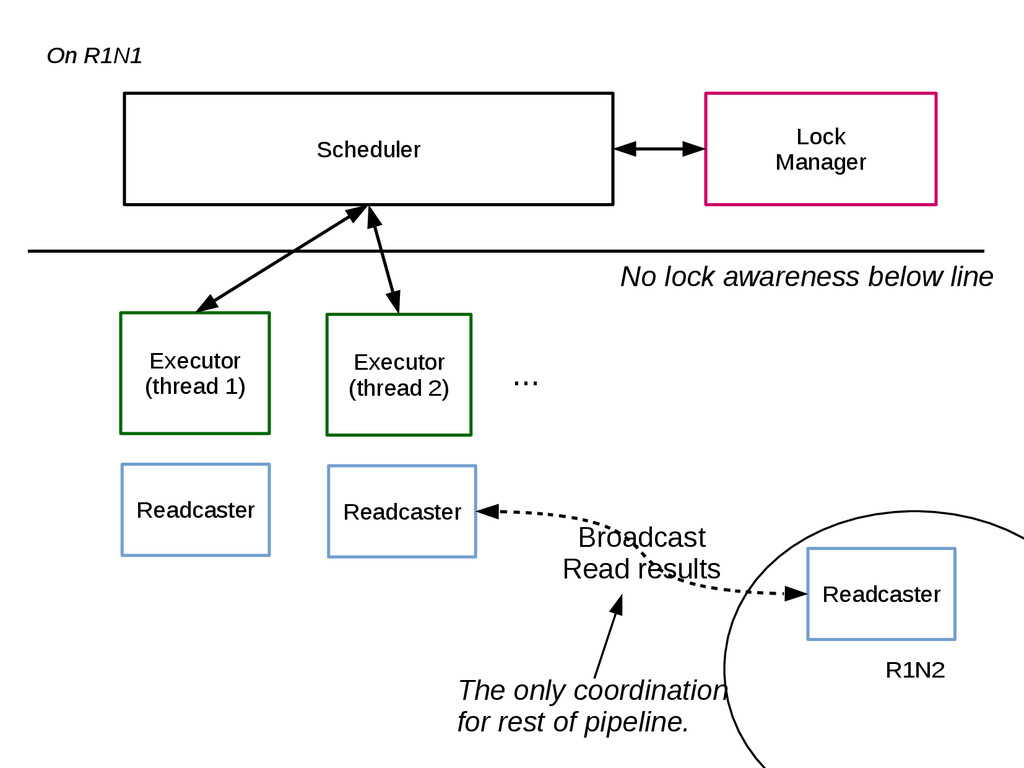{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
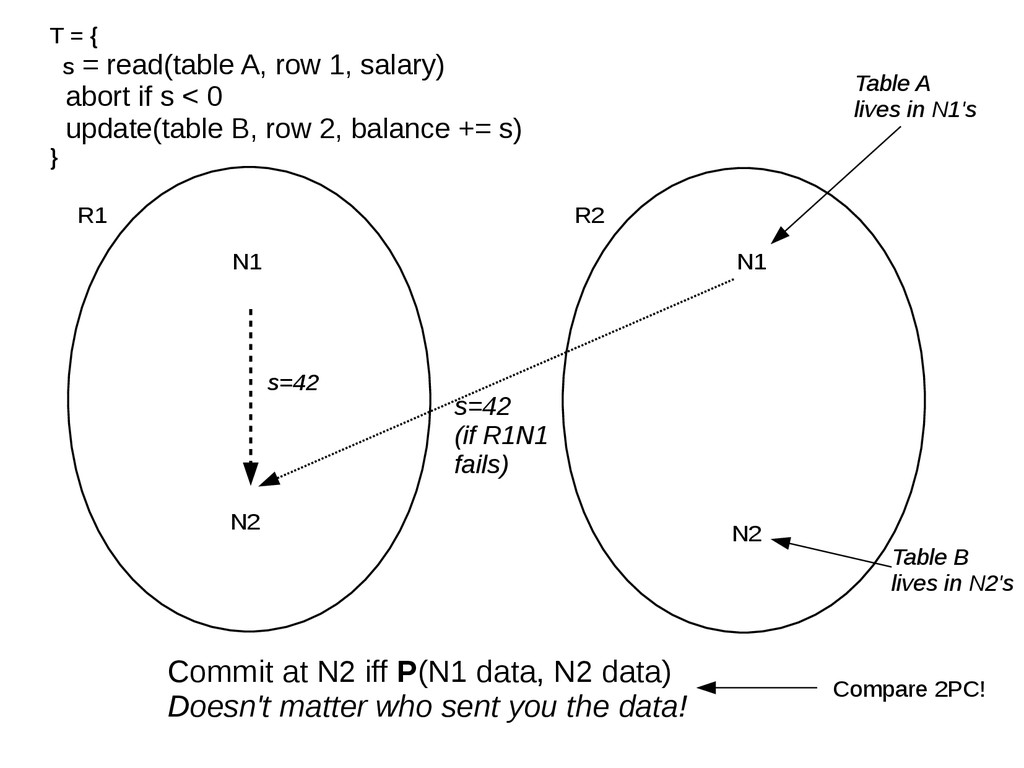{kind=link}
{kind=link}
{kind=link}
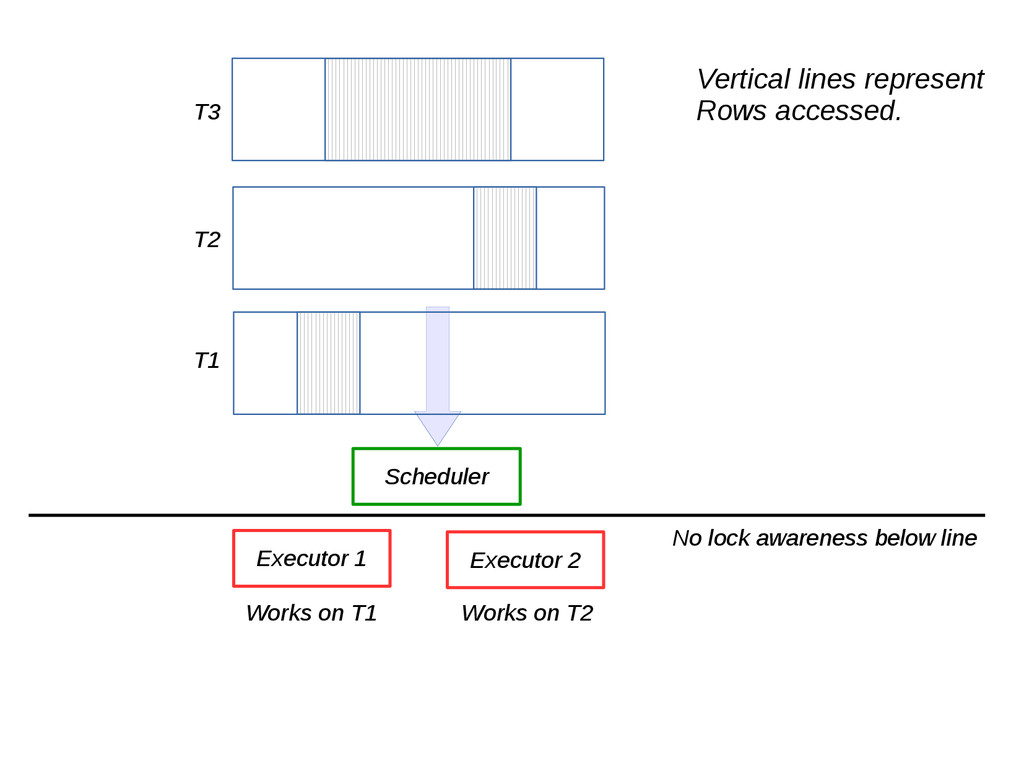{kind=link}
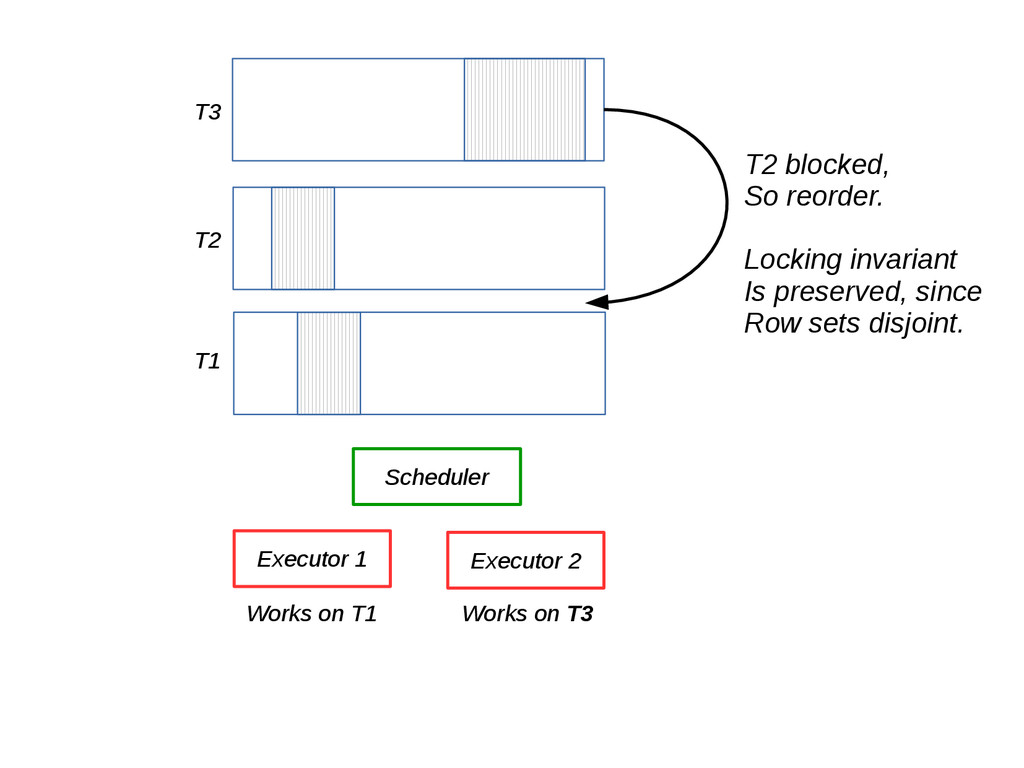{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}