StrangeLoop 2015
25 September 2015
St. Louis, MO
Talk video: https://www.youtube.com/watch?v=ZGIAypUUwoQ
More information: http://bailis.org/
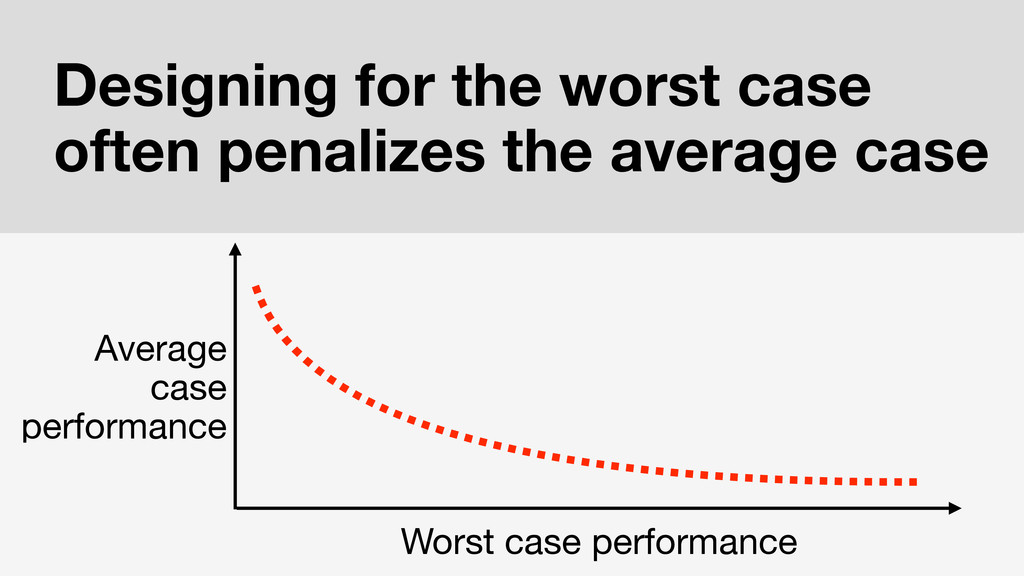
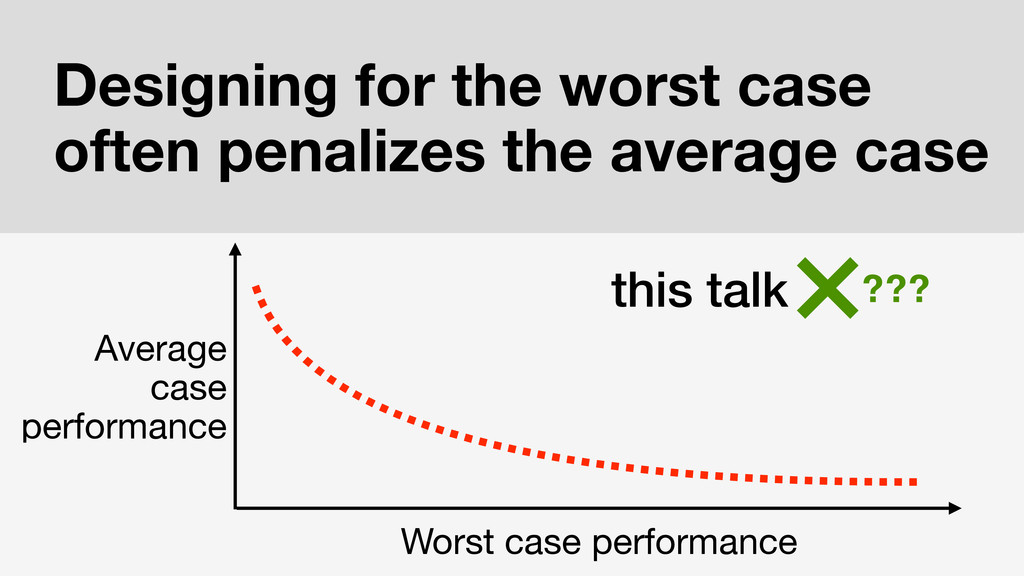
n many areas of systems design, provisioning for worst-case behavior (e.g., load spikes and anomalous user activity) incurs sizable penalties (e.g., performance and operational overheads) in the typical and best cases. However, in distributed systems, building software that is resilient to worse-case network behavior can -- perhaps paradoxically -- lead to improved behavior in typical and best-case scenarios. That is, systems that don't rely on synchronous communication (or coordination) in the worst case frequently aren't forced to wait in any case -- improving latency, scalability, and performance via increased concurrency.
In this talk, we'll explore how to use this worst-case analysis as a more general design principle for scalable systems design. As developers increasingly interacting with and building our own distributed systems, we tend to fixate only on failure scenarios (e.g., "partition tolerance" in the CAP Theorem); this is an important first step, but it's not the whole story. To illustrate why, I'll present practical lessons learned from applying this principle to both web and transaction processing applications as well as database internals such as integrity constraints and indexes. We've found considerable evidence that many of these common tasks and workloads can benefit substantially (e.g., regular order-of-magnitude speedups) from this analysis. In all likelihood, you can too.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}