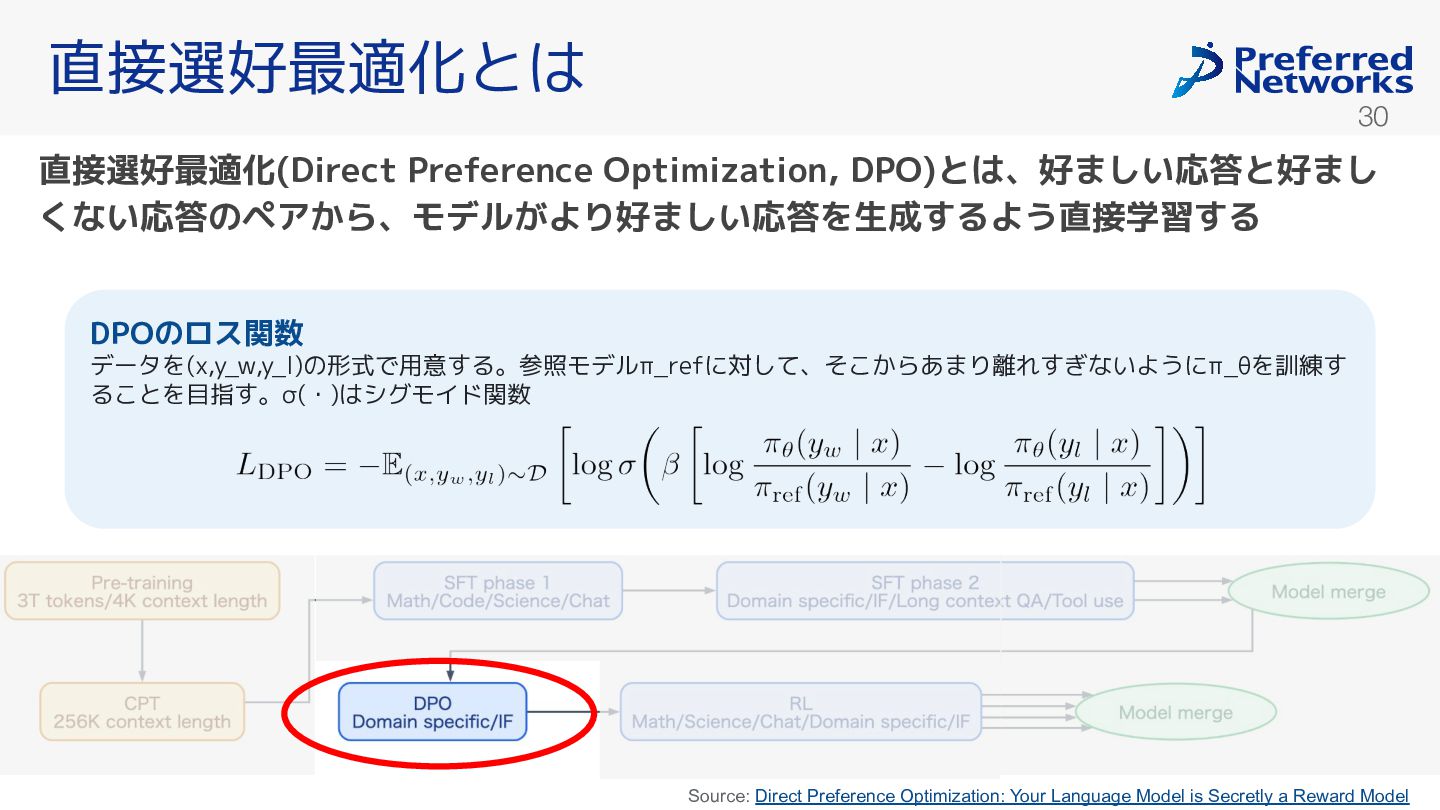
templateによって定まり、Reasoning SFTと似たものを用 いた。ただしDPOの場合は好ましい応答(y_w', y_w)と好まし ない応答(y_l', y_l)を同時に扱えるようにしてい る。以下は例(説明用です)。 y_w'⚪y_wとy_l'⚪y_lにロスを流す。Reasoningを考慮したDPO (Reasoning DPO)のロス関数は以下のようにな る。 1+0 いくら? <|plamo:begin_think:plamo|>The user asks in Japanese: "1+0 いく ら?" meaning "What is 1+0?" The simple answer: 1. Should respond in Japanese perhaps. Provide the answer.<|plamo:end_think:plamo|> 1+0 答え **1** です。 <|plamo:begin_think:plamo|>The user asks: "1+0 いくら? " which means "What is 1*0?" Answer is 0. Should reply in Japanese likely. Provide simple answer.<|plamo:end_think:plamo|> 0です。 好ましい応答 好ましくない応答
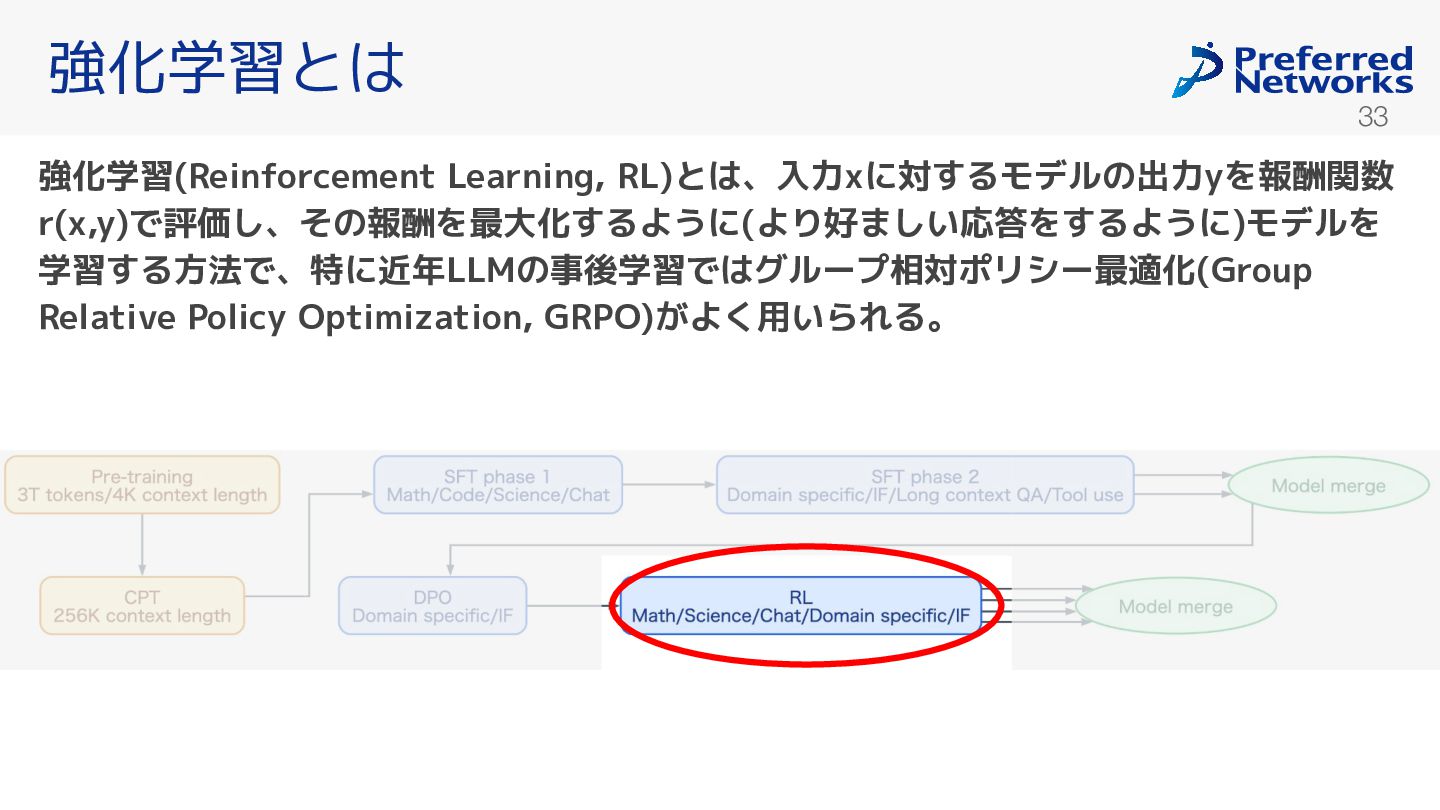
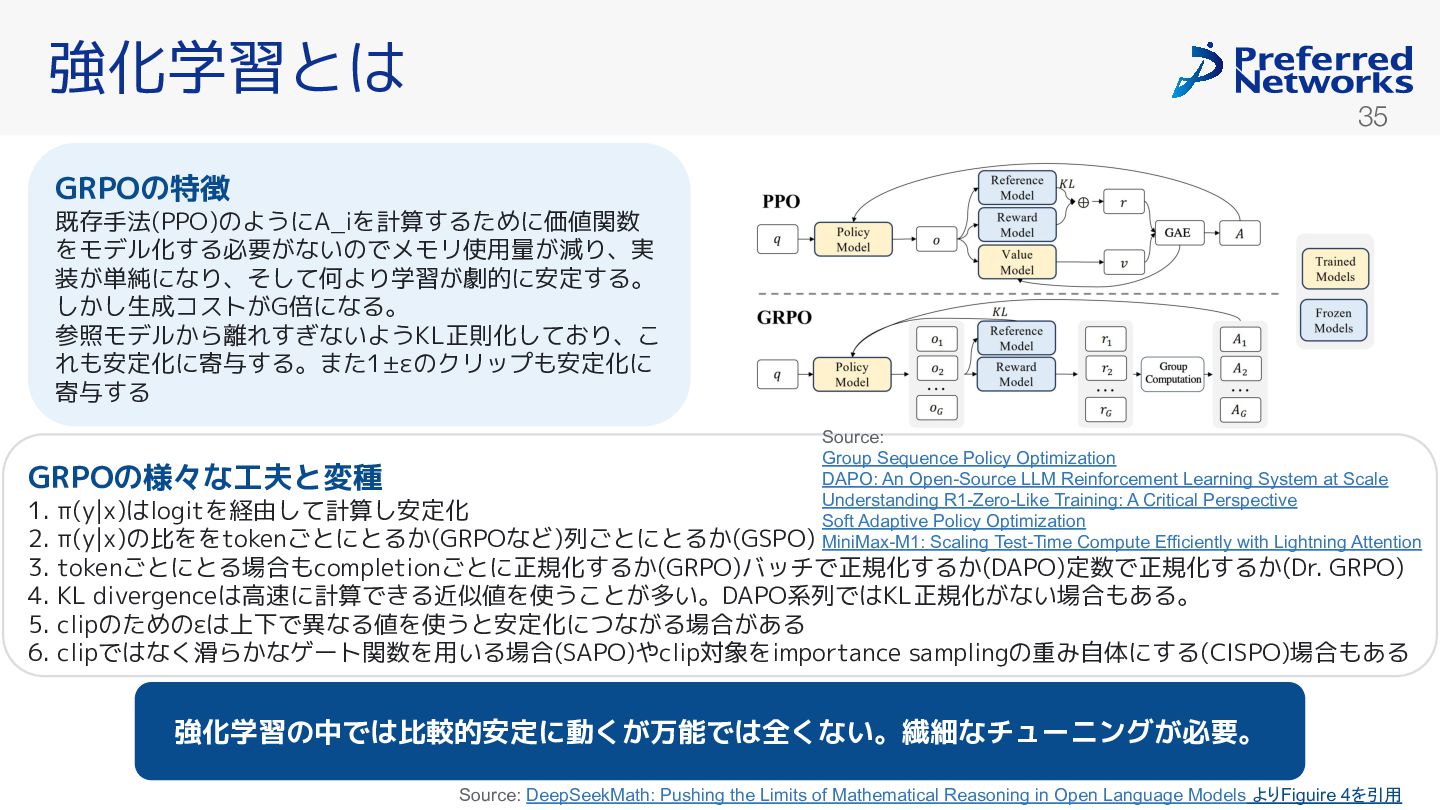
(まとめてグ ループと呼ぶ)を生成して方策の更新に用いる。εとβはハイパーパラメータ。A_iはグループ内に る相対的な報酬 値の良 を表し、以下で定まる。 Source: DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models よりFiguire 4 一部を切り取って引用 強化学習とは
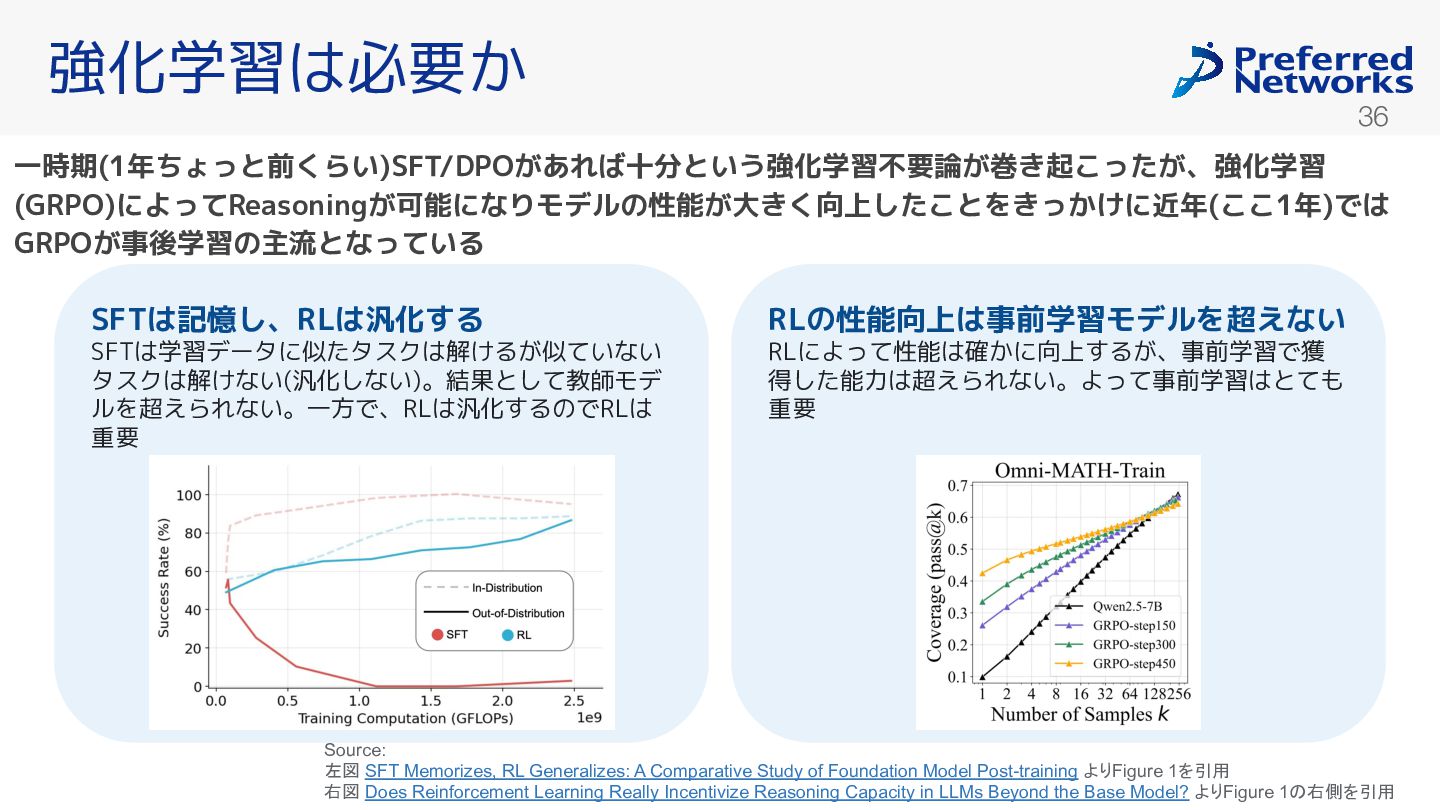
ない(汎化しない)。結果として教師モデ ルを超えられない。一方で、RLは汎化するのでRLは 重要 RLの性能向上は事前学習モデルを超えない RLによって性能は確 に向上する 、事前学習で獲 得した能力は超えられない。よって事前学習はとても 重要 Source: 左図 SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training よりFigure 1を引用 右図 Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model? よりFigure 1 右側を引用
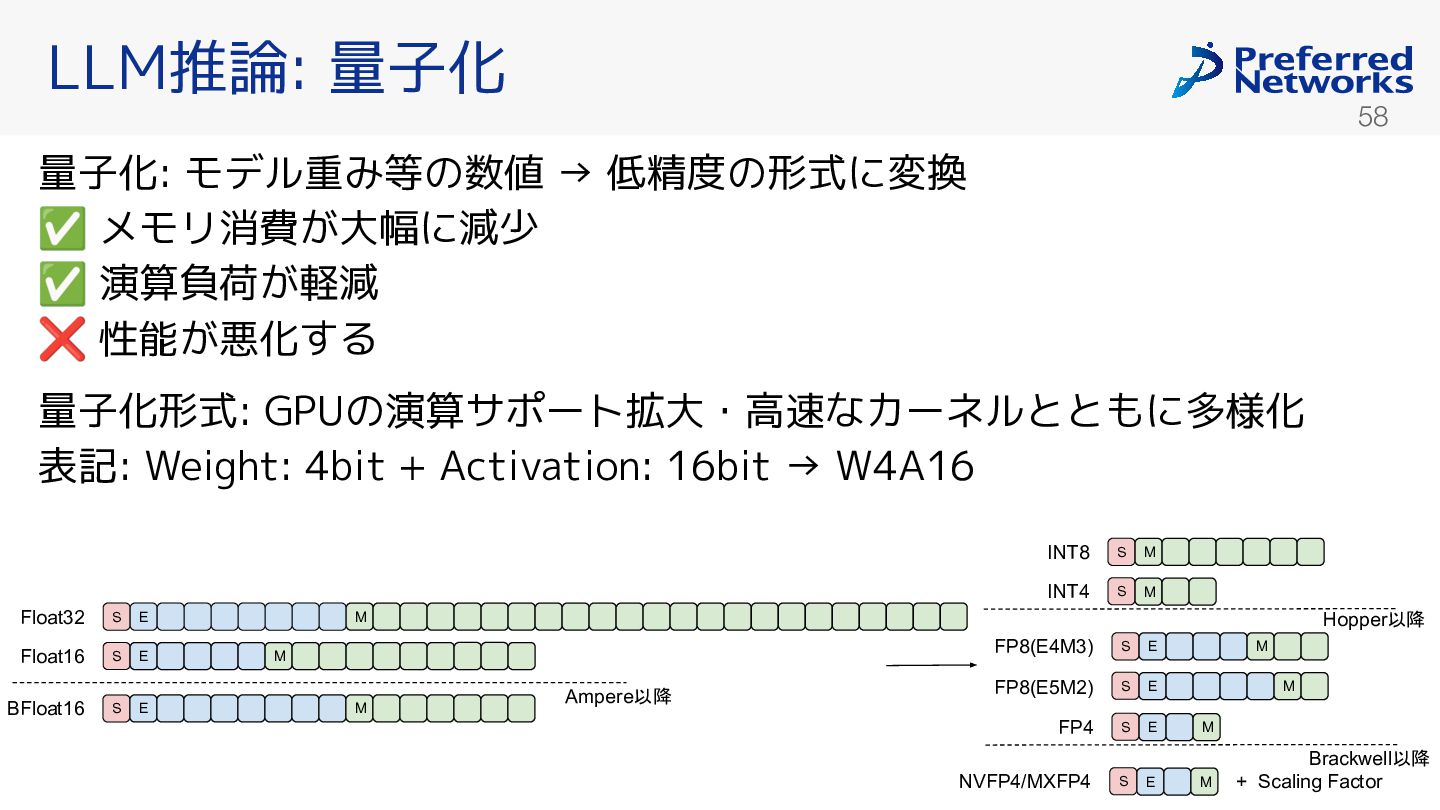
✅ 演算負荷 軽減 ❌ 性能 悪化する 量子化形式: GPUの演算サポート拡大・高速なカーネルとともに多様化 表記: Weight: 4bit + Activation: 16bit → W4A16 S E S E S E M M M Float32 Float16 BFloat16 S S M M INT8 INT4 S E M NVFP4/MXFP4 + Scaling Factor S S E E M FP8(E4M3) FP4 M FP8(E5M2) S E M Ampere以降 Hopper以降 Brackwell以降
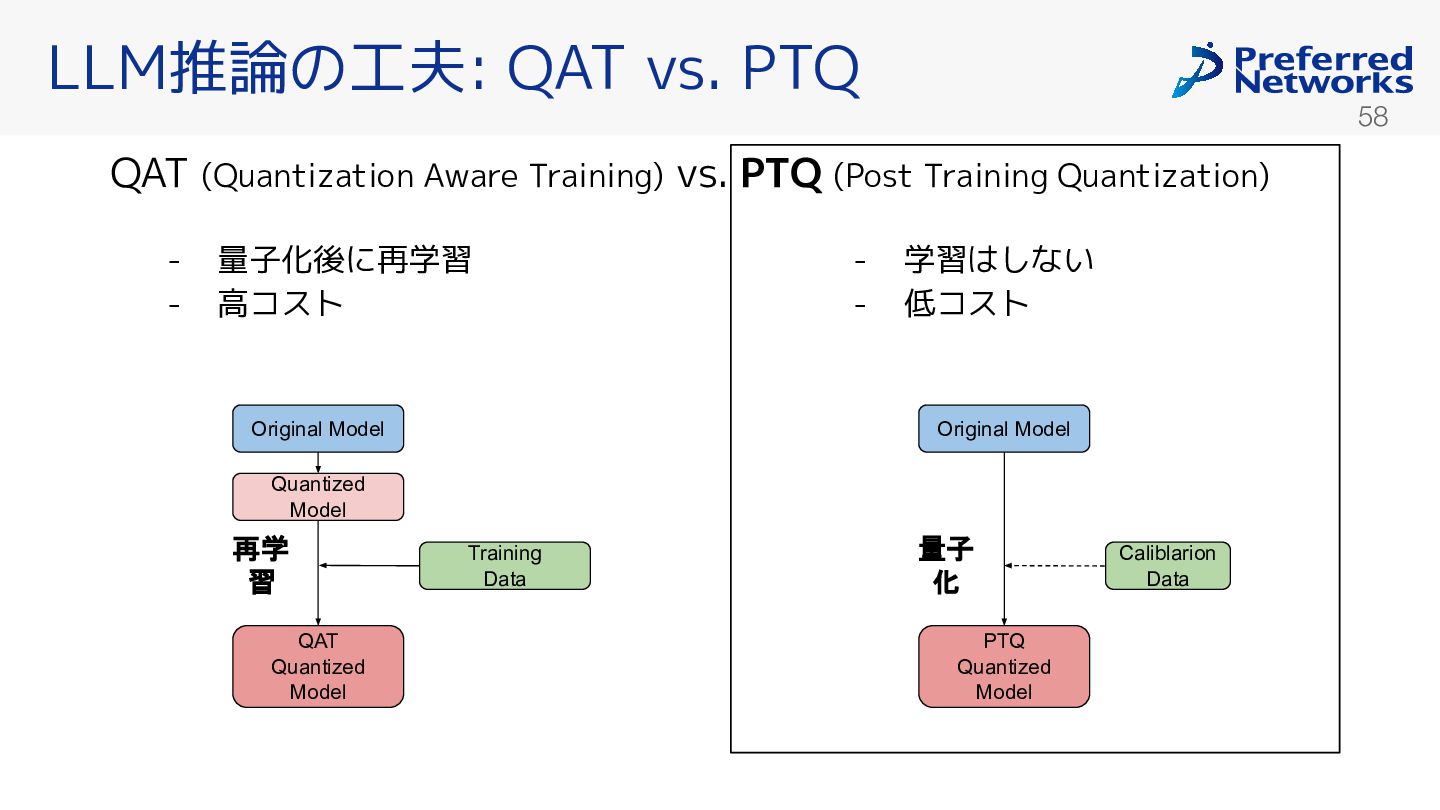
LLM推論の工夫: QAT vs. PTQ Original Model Quantized Model Training Data PTQ Quantized Model Caliblarion Data QAT Quantized Model Original Model - 量子化後に再学習 - 高コスト - 学習はしない - 低コスト 再学 習 量子 化
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
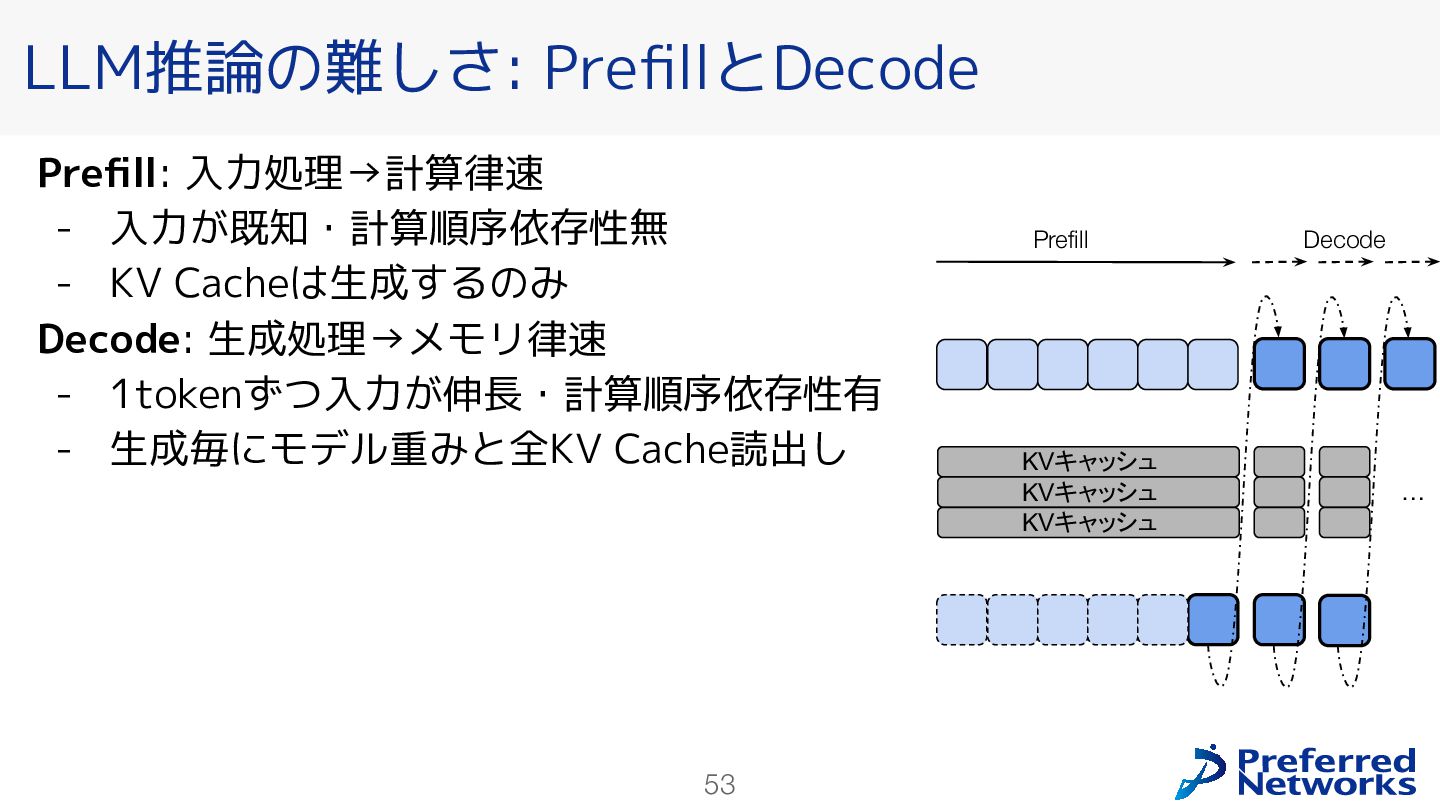{kind=link}
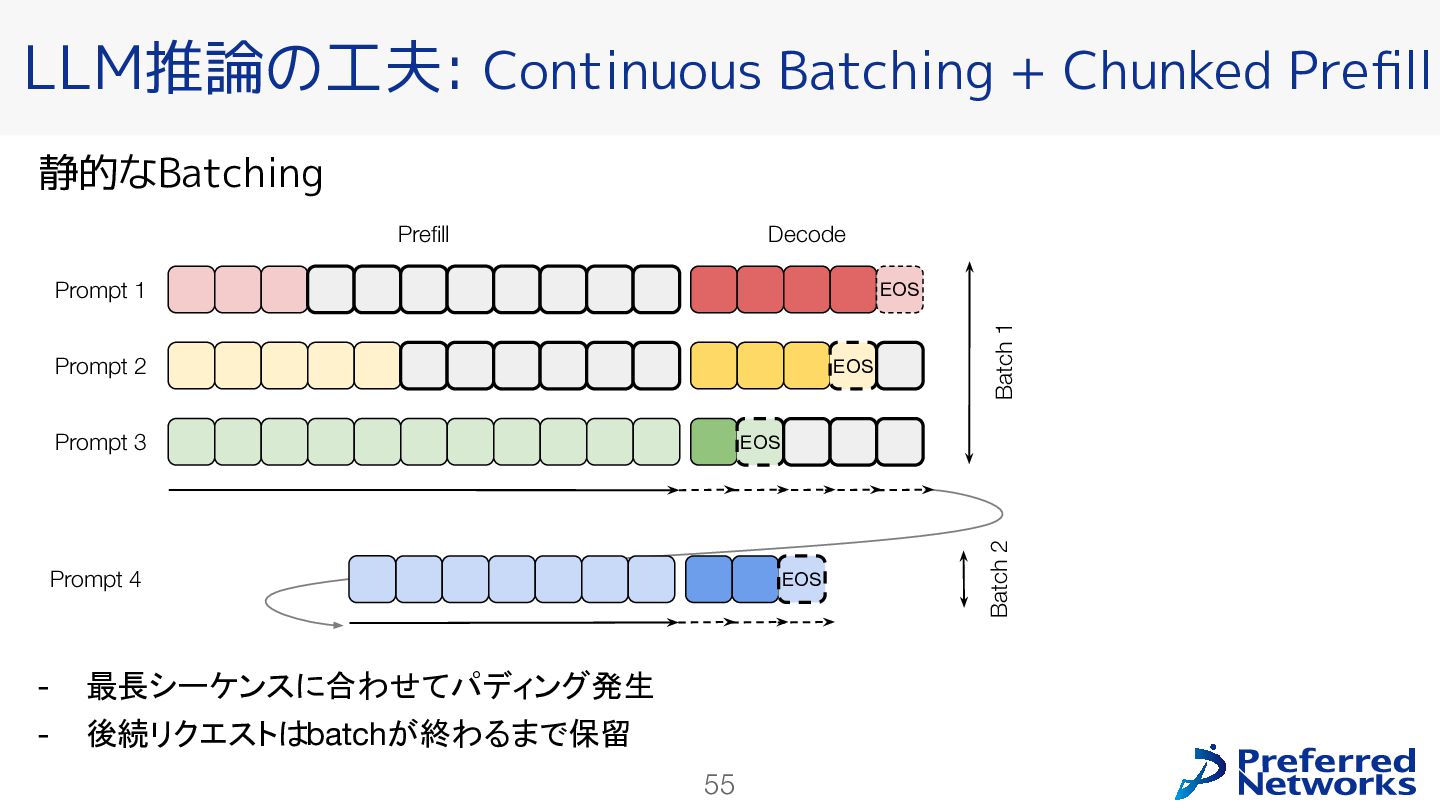{kind=link}
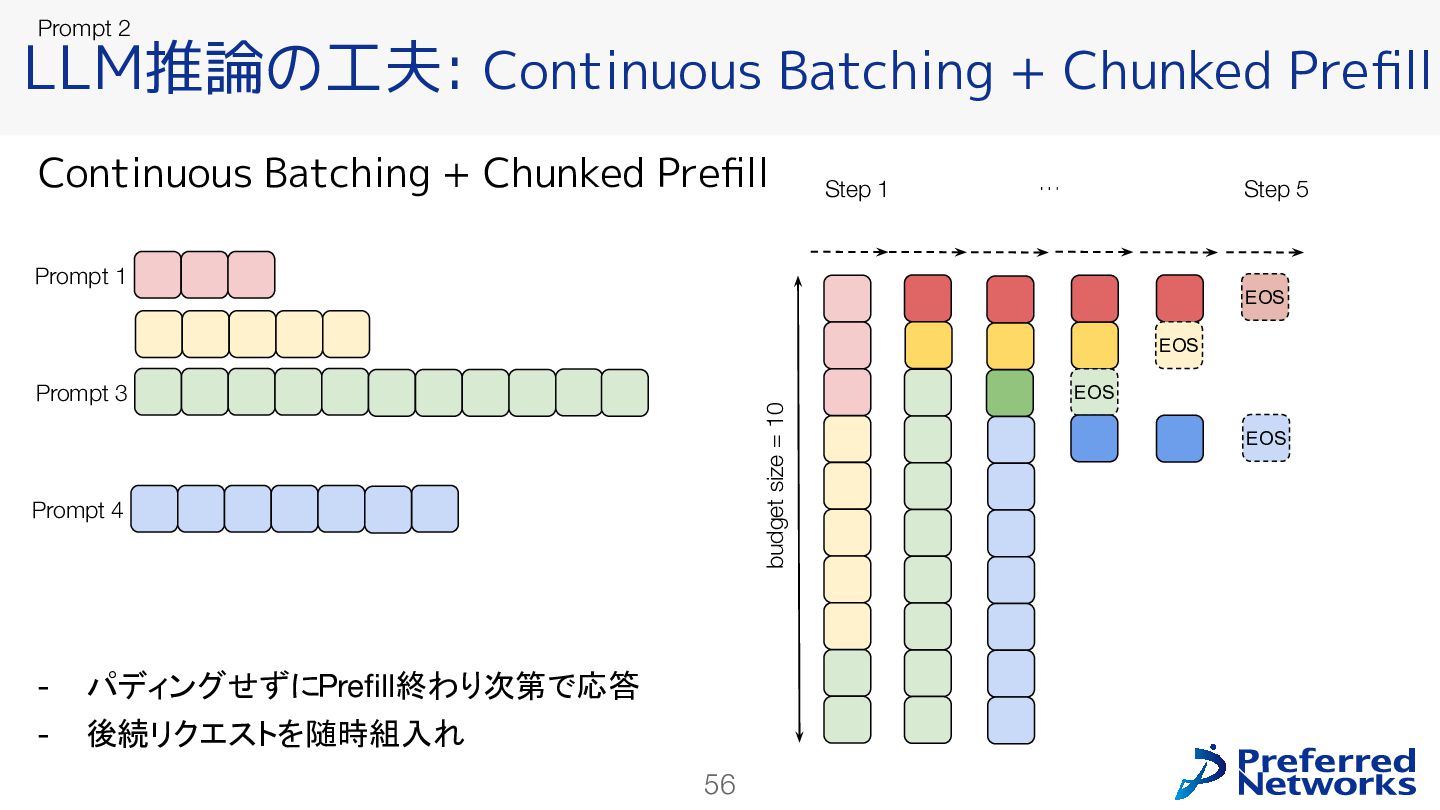{kind=link}
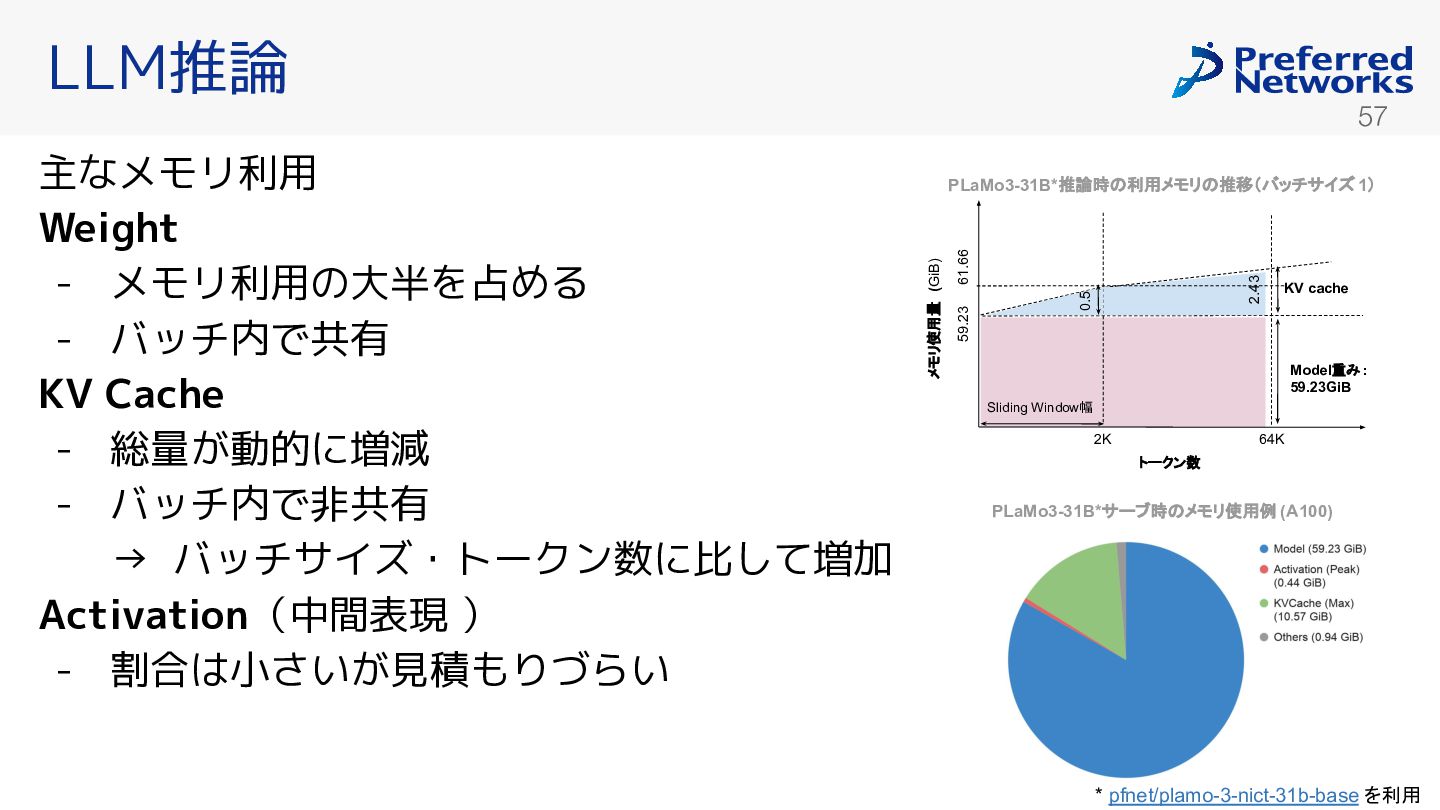{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
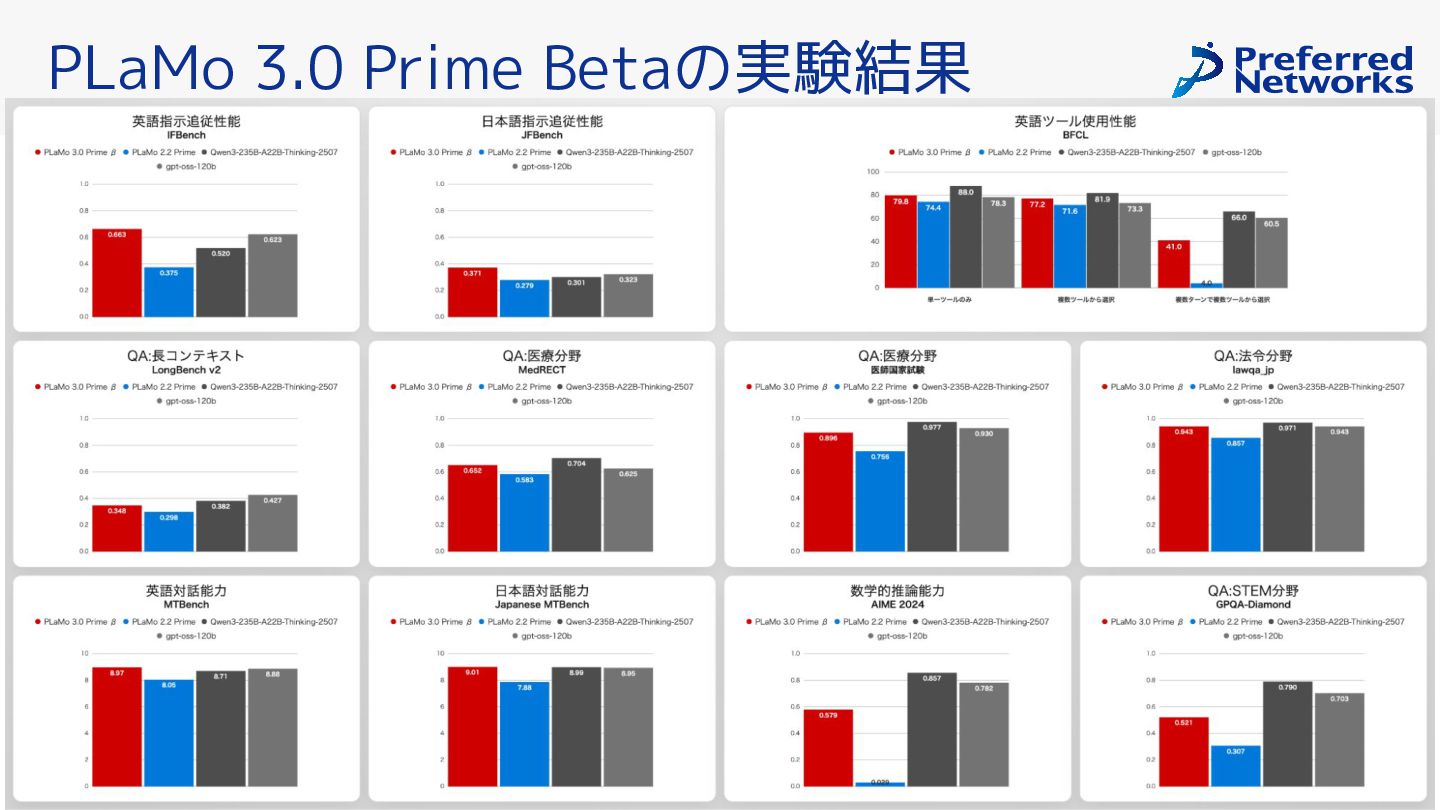{kind=link}
{kind=link}
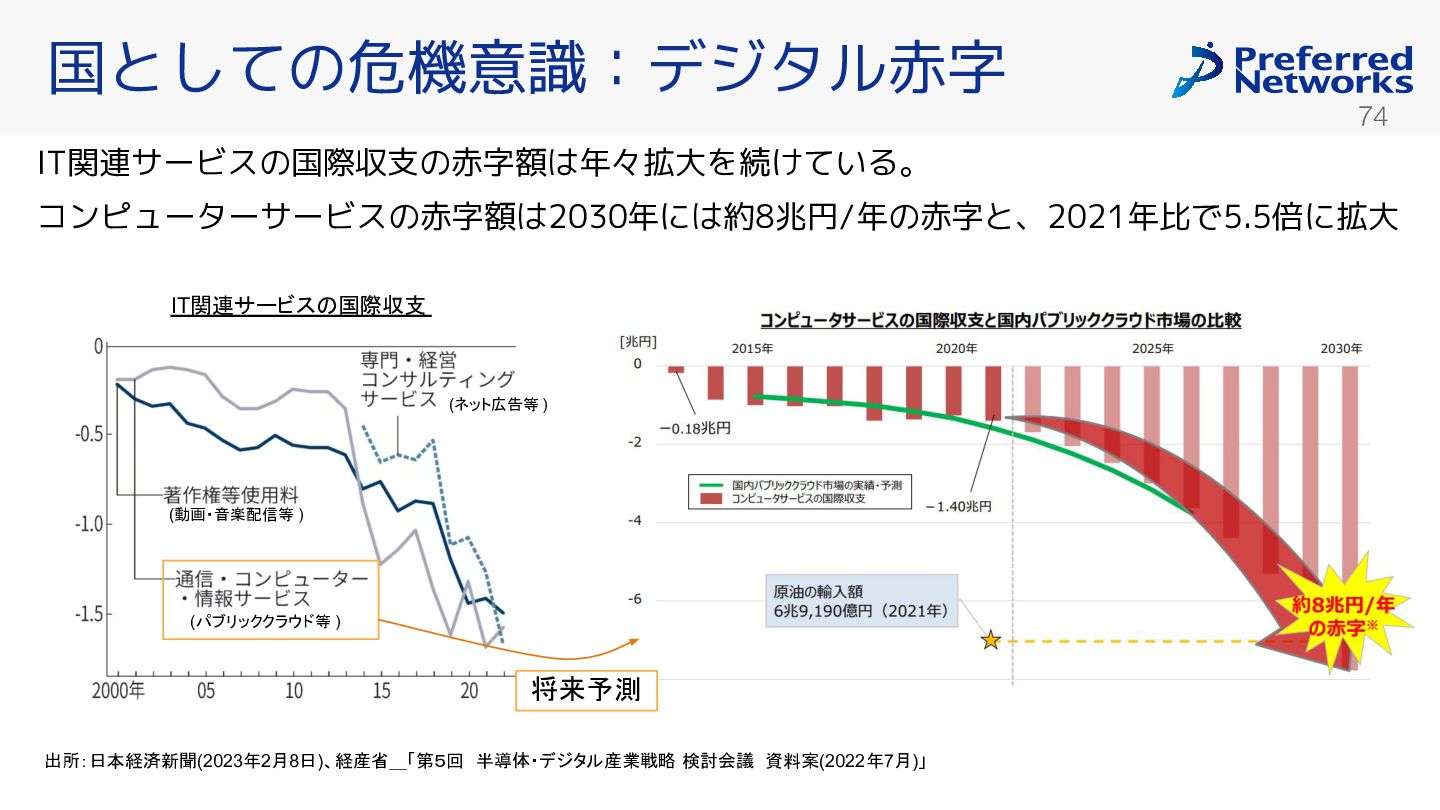
{kind=link}
{kind=link}
{kind=link}
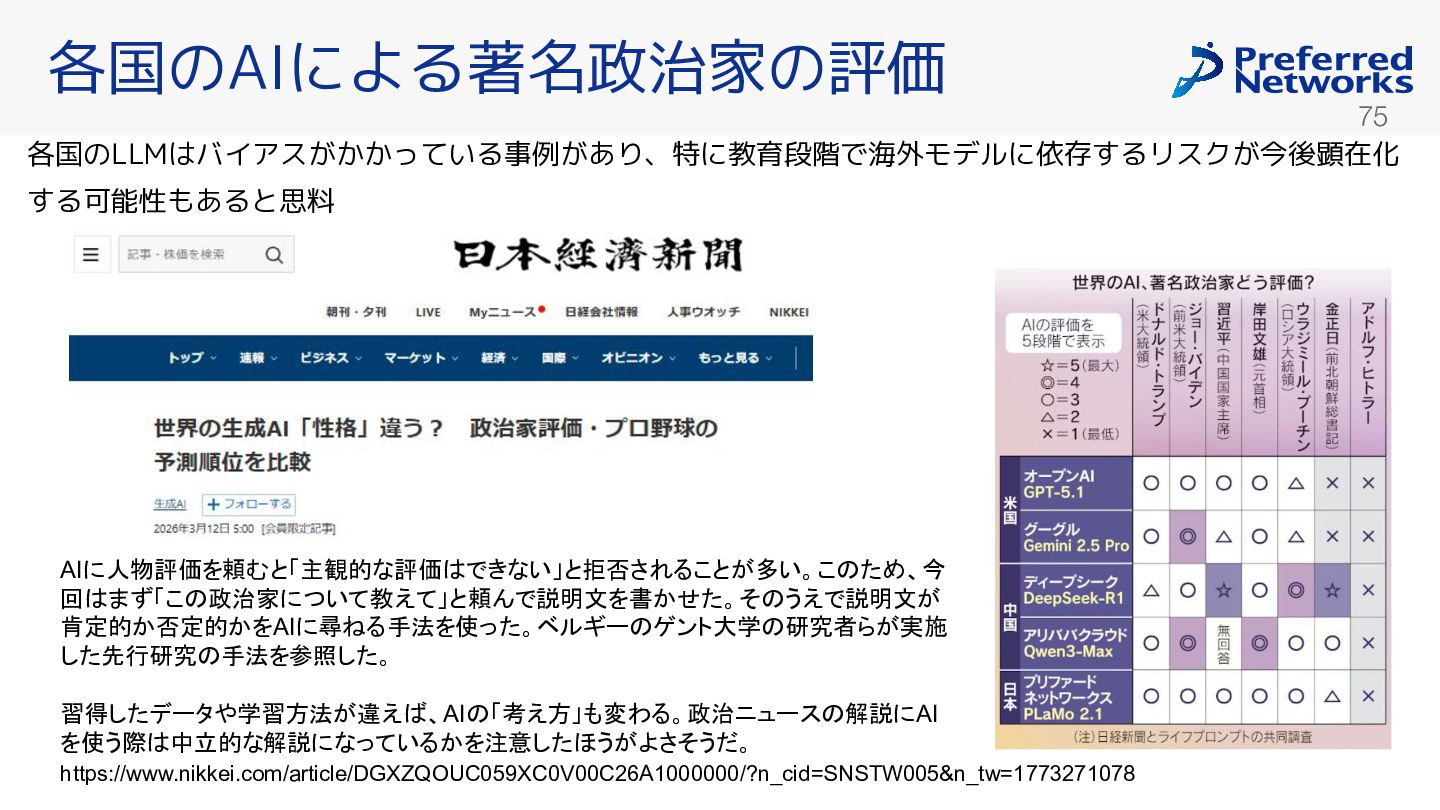{kind=link}