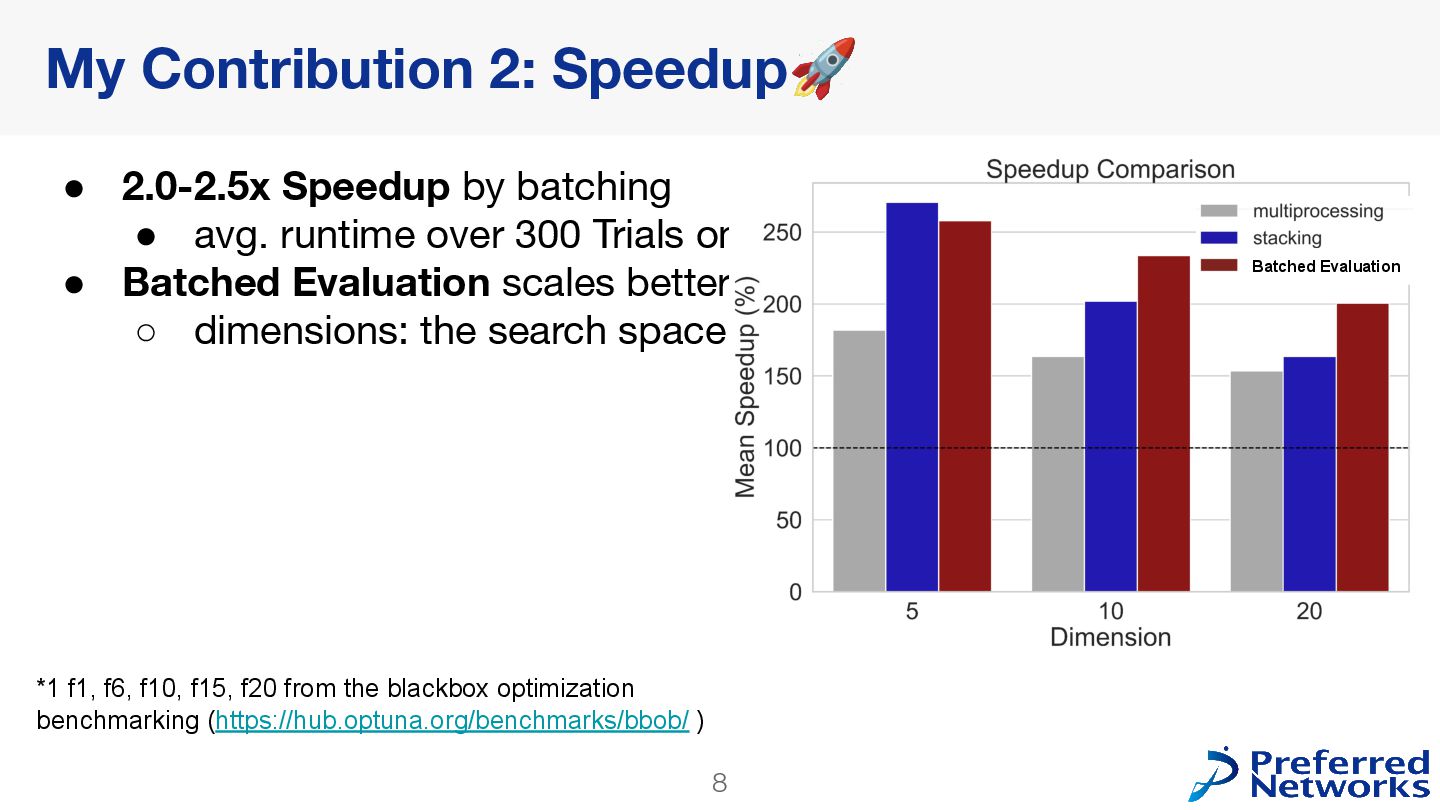
but slow, creating a critical bottleneck in real-world, large-scale optimization tasks Objective • Accelerate GPSampler without compromising its optimization accuracy, the library's usability, and maintainability Approach • Replace sequential multi-start optimization with batching Key Achievements & Impact • 2.0-2.5x speedup🚀 without degrading accuracy or usability • Merged into master🎉 : will be available in Optuna v4.6+ 2
optimization • GPSampler is a powerful sampler, especially for continuous optimization ◦ TPESampler is the default sampler due to broader applicability ▪ e.g., search spaces with conditional parameters About Optuna and GPSampler 3 https://optuna.readthedocs.io/en/stable/reference/samplers/index.html
N is the number of trials. ◦ Example (500 trials): ▪ GPSampler: 1,000 - 10,000 seconds ▪ TPESampler: 10 - 100 seconds • Real-World Impact: GPSampler sometimes becomes a bottleneck, as its sampling process can take as long as the objective function evaluation itself. The Challenge: GPSampler is slow 4
50+% of overall runtime, yet executed sequentially • PyTorch batching is faster than simple for-loop The Inner Optimizations are the Current Bottleneck 5 Currently sequential, but can be batched!
BoTorch suggests Stacking speeds up • Stacking: one of the batching approaches • BoTorch: a library for Bayesian Optimization built on PyTorch Open Questions: 1. What batching methods should we consider? ◦ cf. Investigation 2. What are the pros & cons of each method? ◦ cf. Investigation + Speedup 3. How should we implement and is it acceptable for Optuna? ◦ cf. Investigation + Master merge 6
when the dimension is small & simple implementation ◦ ❌ Degrade optimization accuracy • Multiprocessing: ◦ ✅ Simple Implementation ◦ ❌ Not so fast (-1.5x) & Break Sampler’s API • Batched Evaluation: ⭐ Chosen ◦ ✅ Fastest ◦ ❌ Require design discussion for master merge My Contribution 1: Investigation 7
API Limitations: SciPy API does not allow batched evaluation • Built-in Python Multithreading: Too slow Design Question: Who should handle batching? 🤔 • The Optimizer? The Function? Project Constraints • Avoid additional packages • Avoid using internal modules in third-party libraries • Keep API compatibility 9
library (& already in Optuna requirement) • ✅ 2.0-2.5x Faster • ✅ No additional packages required • ✅ Same accuracy, same usability • will be available in Optuna v4.6+ ◦ Run: pip install -U optuna My Contribution 3: Master Merge 🎉 (#6268) 10 https://github.com/optuna/optuna/pull/6268
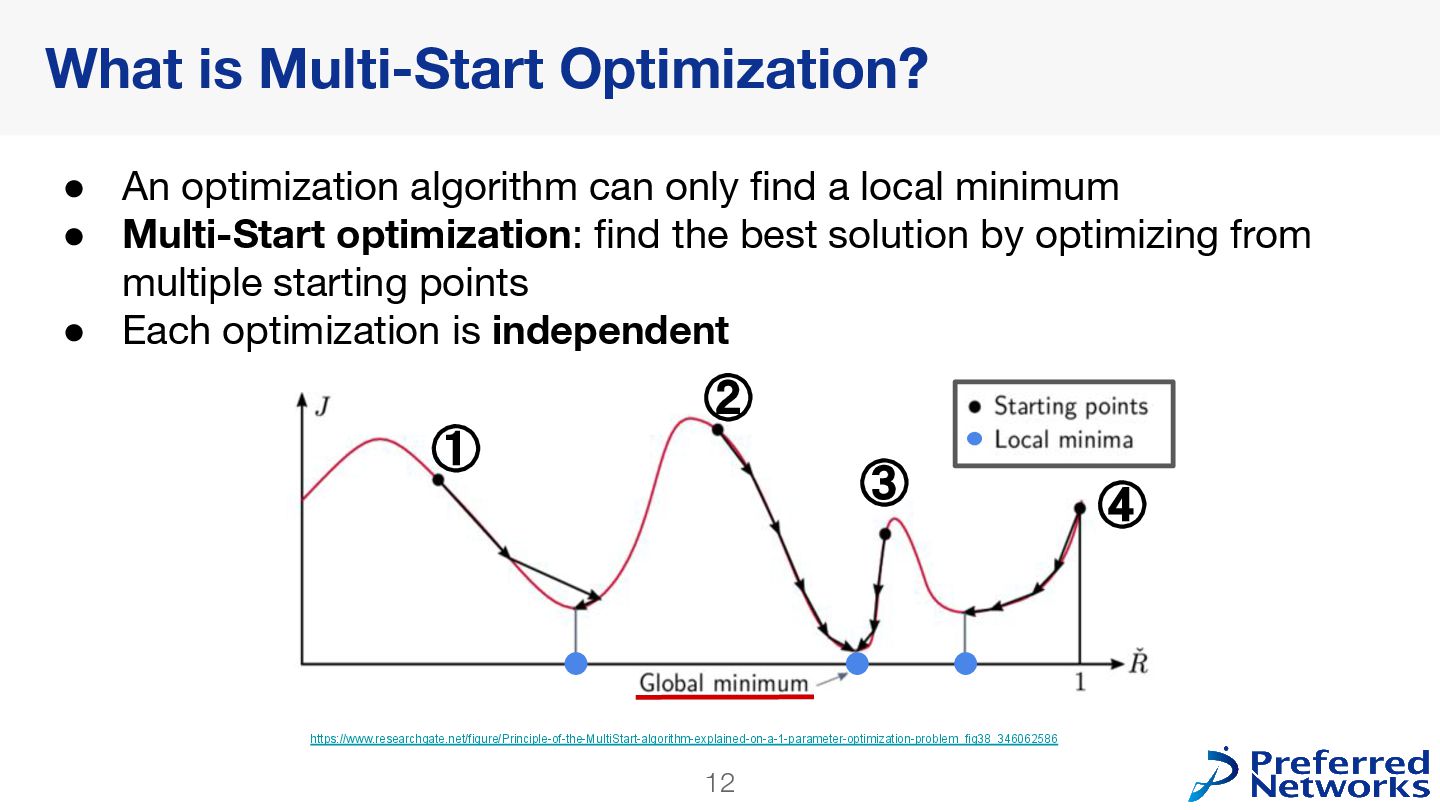
only find a local minimum • Multi-Start optimization: find the best solution by optimizing from multiple starting points • Each optimization is independent https://www.researchgate.net/figure/Principle-of-the-MultiStart-algorithm-explained-on-a-1-parameter-optimization-problem_fig38_346062586 ① ③ ② ④
f by repeating a two-step cycle: Step 1: Evaluate Current Point x: Calculate f(x), g(x) Step 2: Update x: Use the value and gradient to decide next point 13
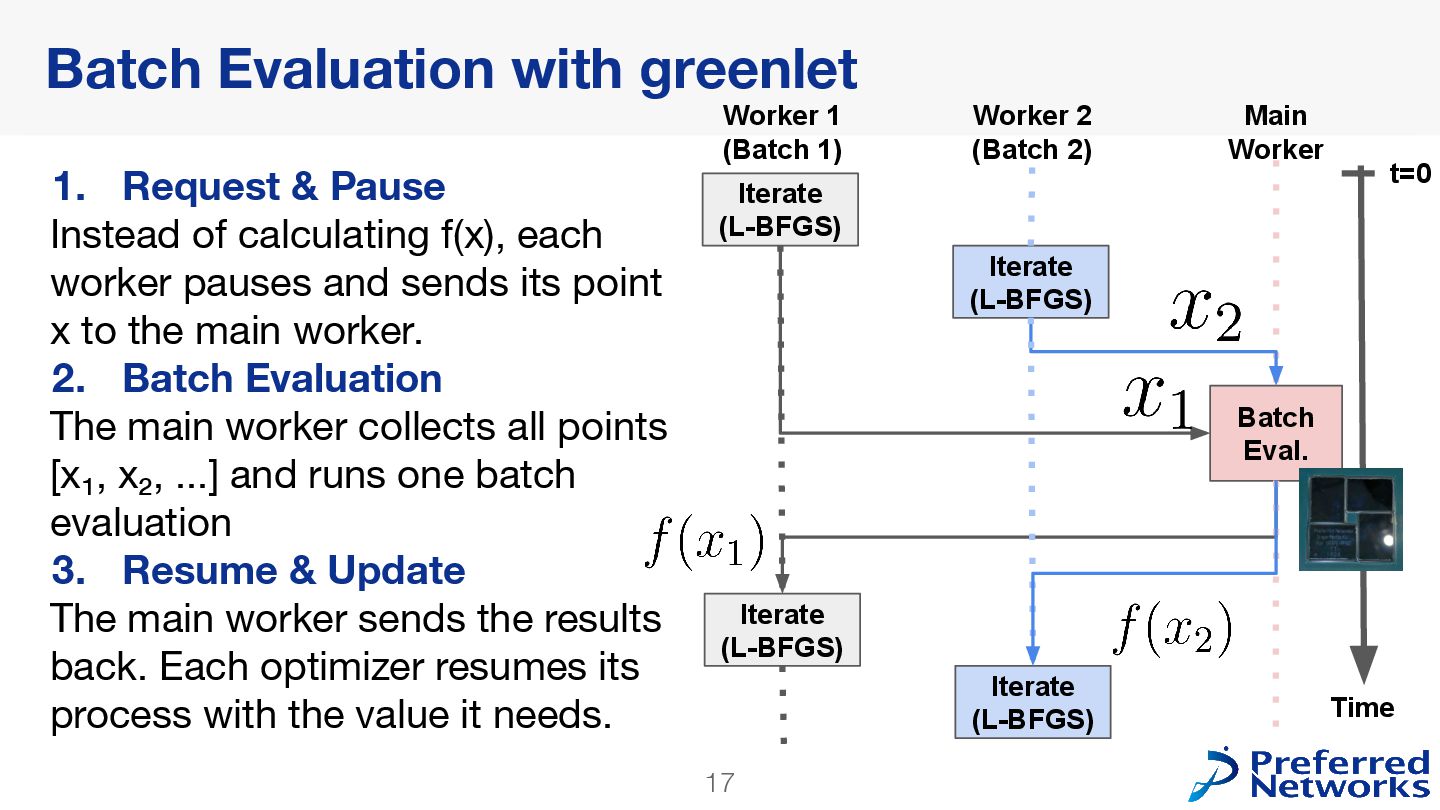
acquisition function requires expensive computations on large Tensors. • The Solution: The optimizer evaluates many points. We can extract these evaluations and run all the Tensor computations at once in a batch. scipy_optim
(L-BFGS) Iterate (L-BFGS) Main Worker Worker 2 (Batch 2) Worker 1 (Batch 1) Iterate (L-BFGS) Time t=0 1. Request & Pause Instead of calculating f(x), each worker pauses and sends its point x to the main worker. 2. Batch Evaluation The main worker collects all points [x₁, x₂, ...] and runs one batch evaluation 3. Resume & Update The main worker sends the results back. Each optimizer resumes its process with the value it needs.
• 2x-2.5x faster in low dimensions. • Fewer iterations in low dimensions (for some reason!). • Simple to implement with no new dependencies. 👎 The Downsides • It changes the optimization problem, which can change the result. • Suffers in high dimensions: more iterations mean longer runtimes, or lower quality solutions if you limit them. ◦ Doesn't work well with quasi-Newton (e.g., L-BFGS-B) method, causing bad hessian approximation more iterations. 18
• Consistent ~1.5x speed-up for any dimension. • Super simple to code and to understand. • Same problem, same results. (Iterations and accuracy are identical). 👎 The Downsides • Slower speed-up than other techniques. • Requires API changes to the Sampler to handle processes. • Too much overhead to start mid-optimization. • A nightmare to debug for developers (logging, profiling, etc.). 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}