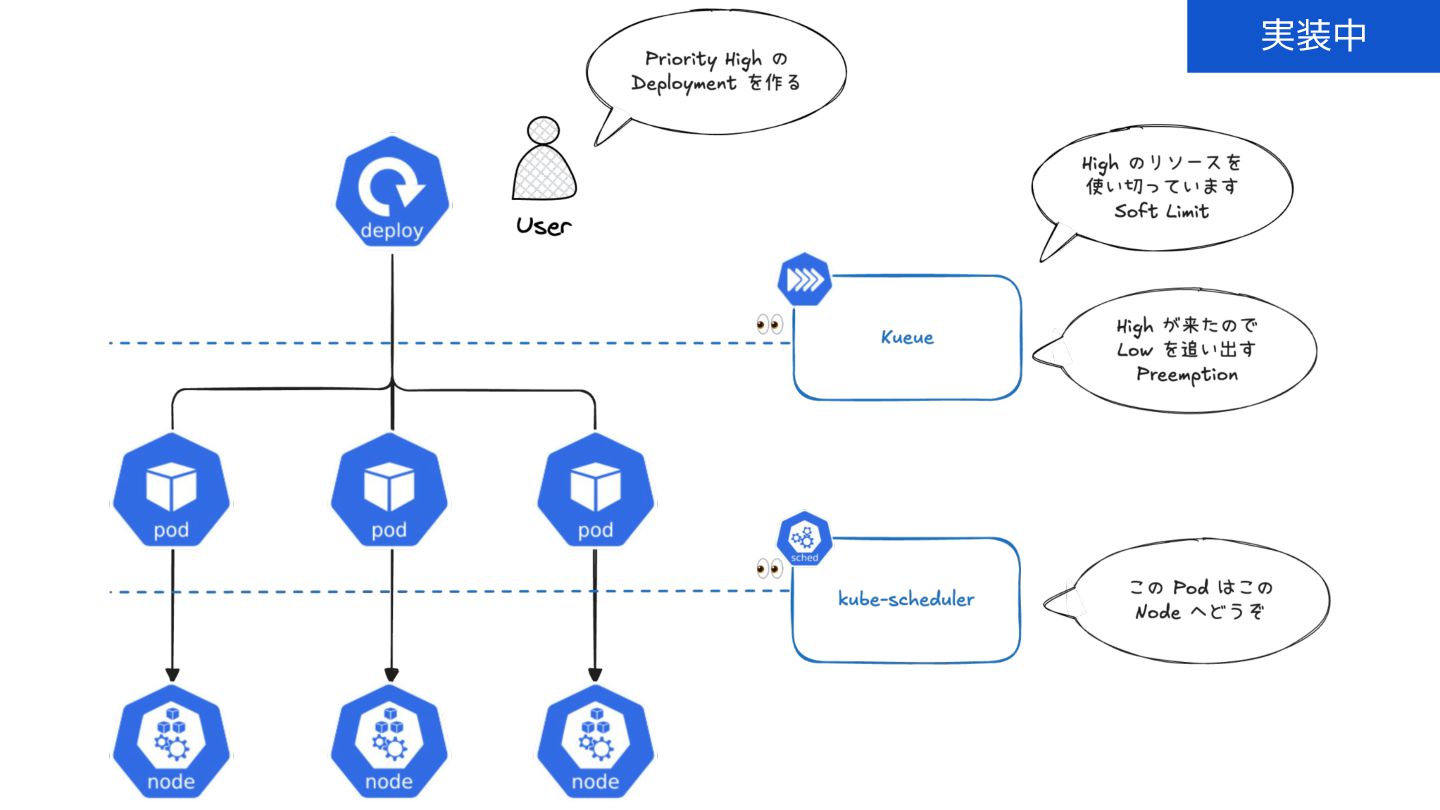
Preferred Networksでは、AI/MLワークロード向けのクラウドサービスである「Preferred Computing Platform (PFCP)」をマルチテナントKubernetesコンテナ基盤として提供している。本講演では、複数ユーザが利用するマルチテナント基盤で重要となる、Kubernetes APIレベルでの権限分離とその強制、同一ホスト上でのプロセス・データの分離、同一ネットワーク内での通信分離等のアイソレーション技術、限られた計算リソースの公平制御、および課金システムについて、その実現のための技術と設計思想について説明する。また、Kubernetes上でAI/ML ワークロードを実行するために必要なアクセラレータのサポート、RDMAを含めHPCアプリケーションを実行する上で必要になる基本的な技術、複数の拠点にスケール可能なシステム構成等、PFCP全体についても概説する。
イベントサイト: https://www.media.kyoto-u.ac.jp/accms_web/event/3427.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
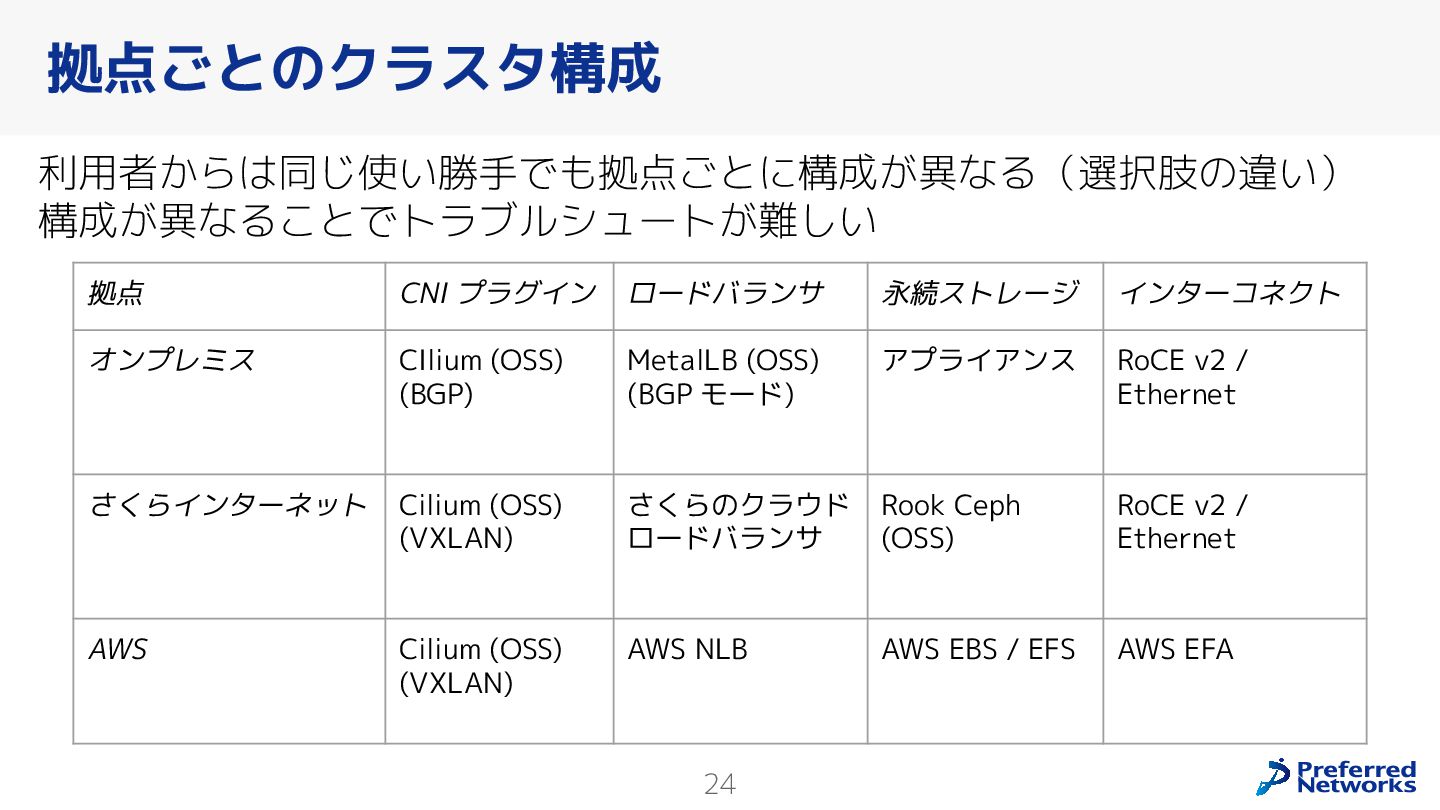{kind=link}
{kind=link}
{kind=link}
{kind=link}
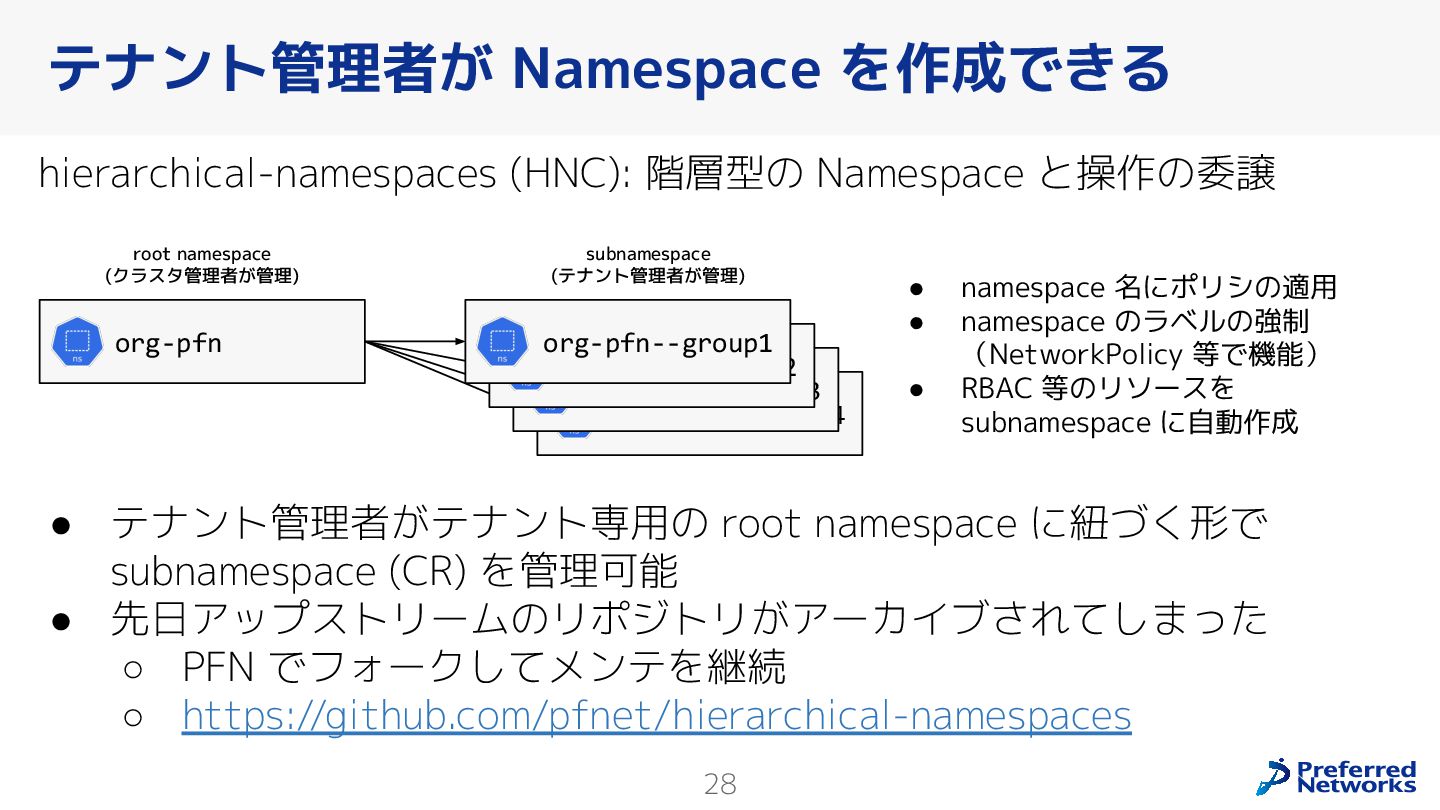{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
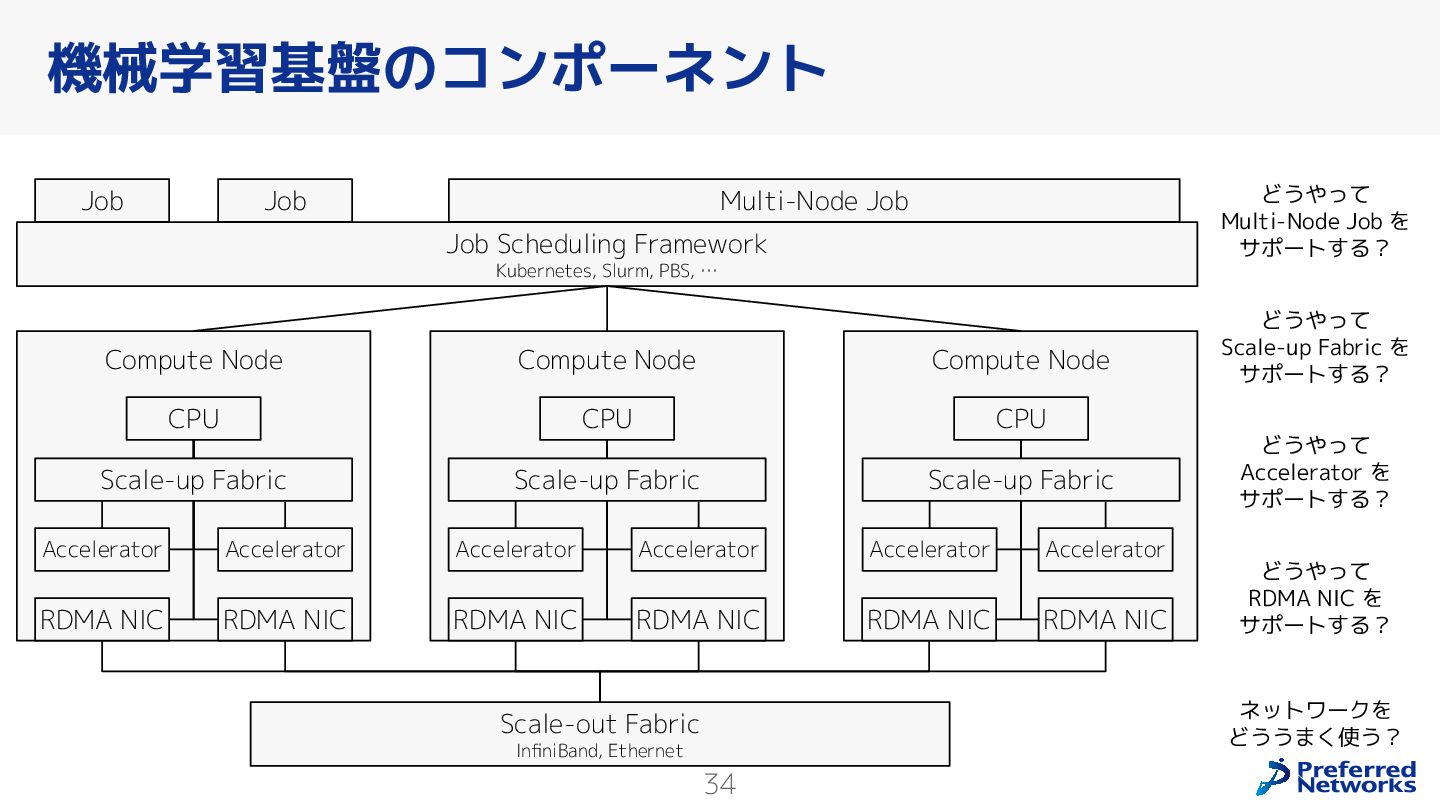{kind=link}
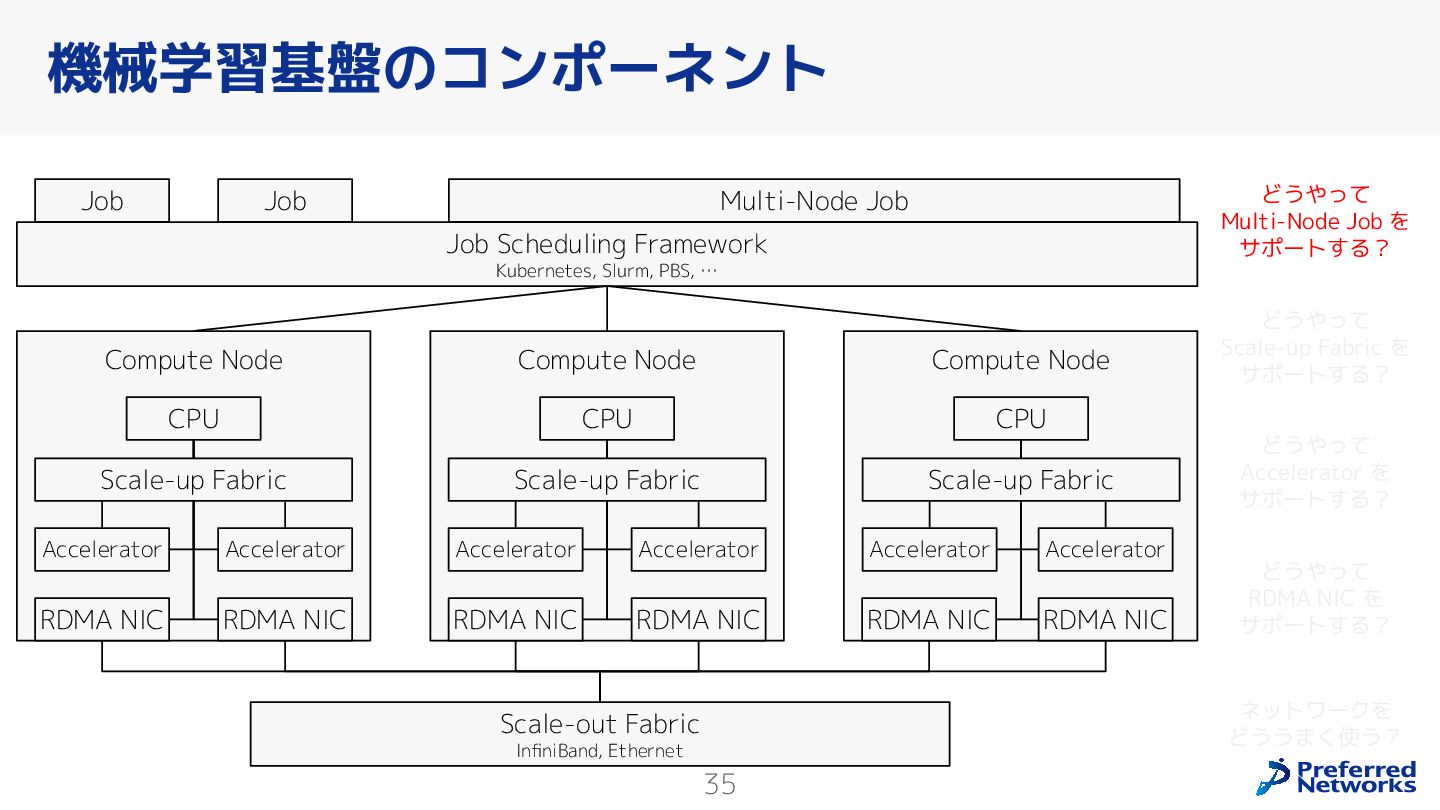{kind=link}
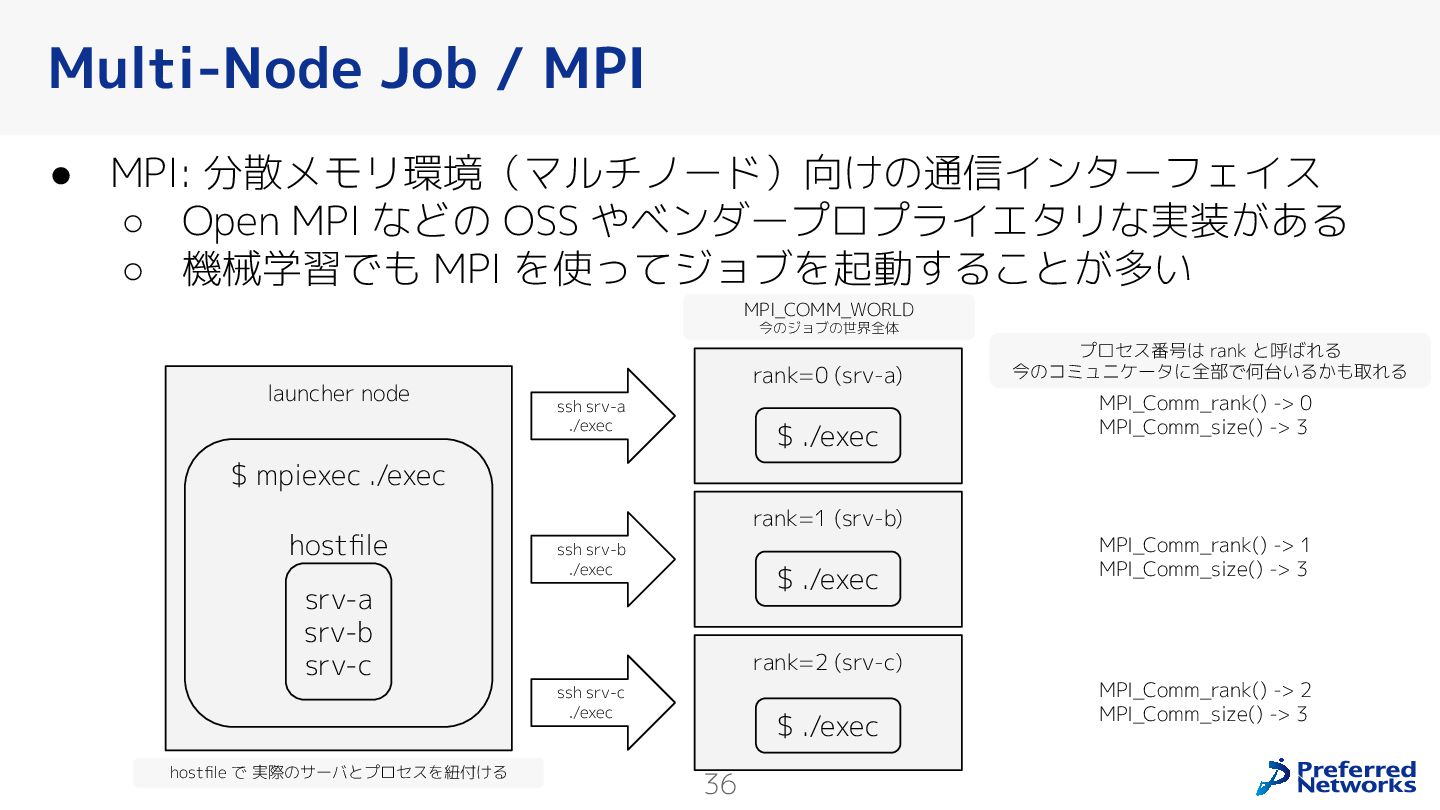{kind=link}
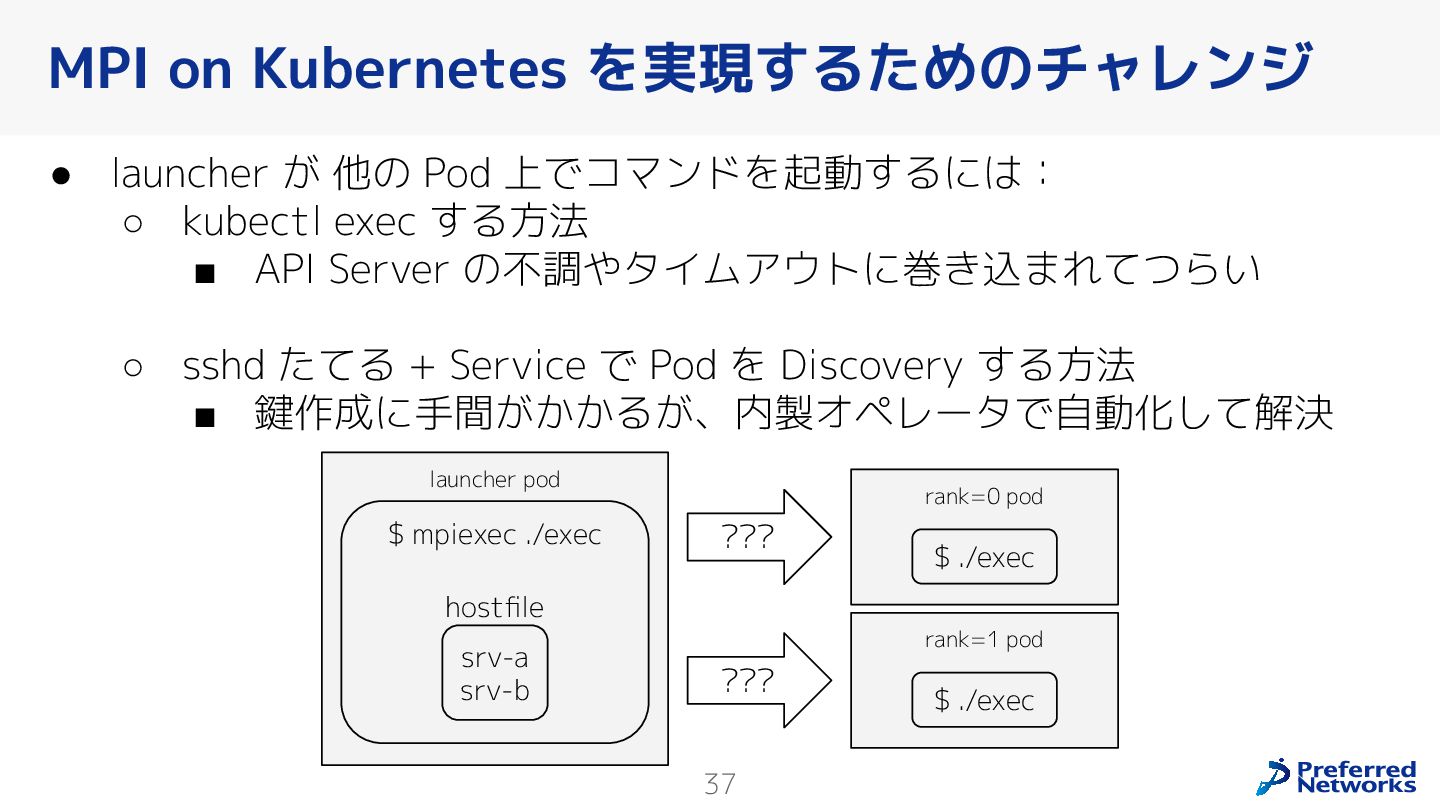{kind=link}
{kind=link}
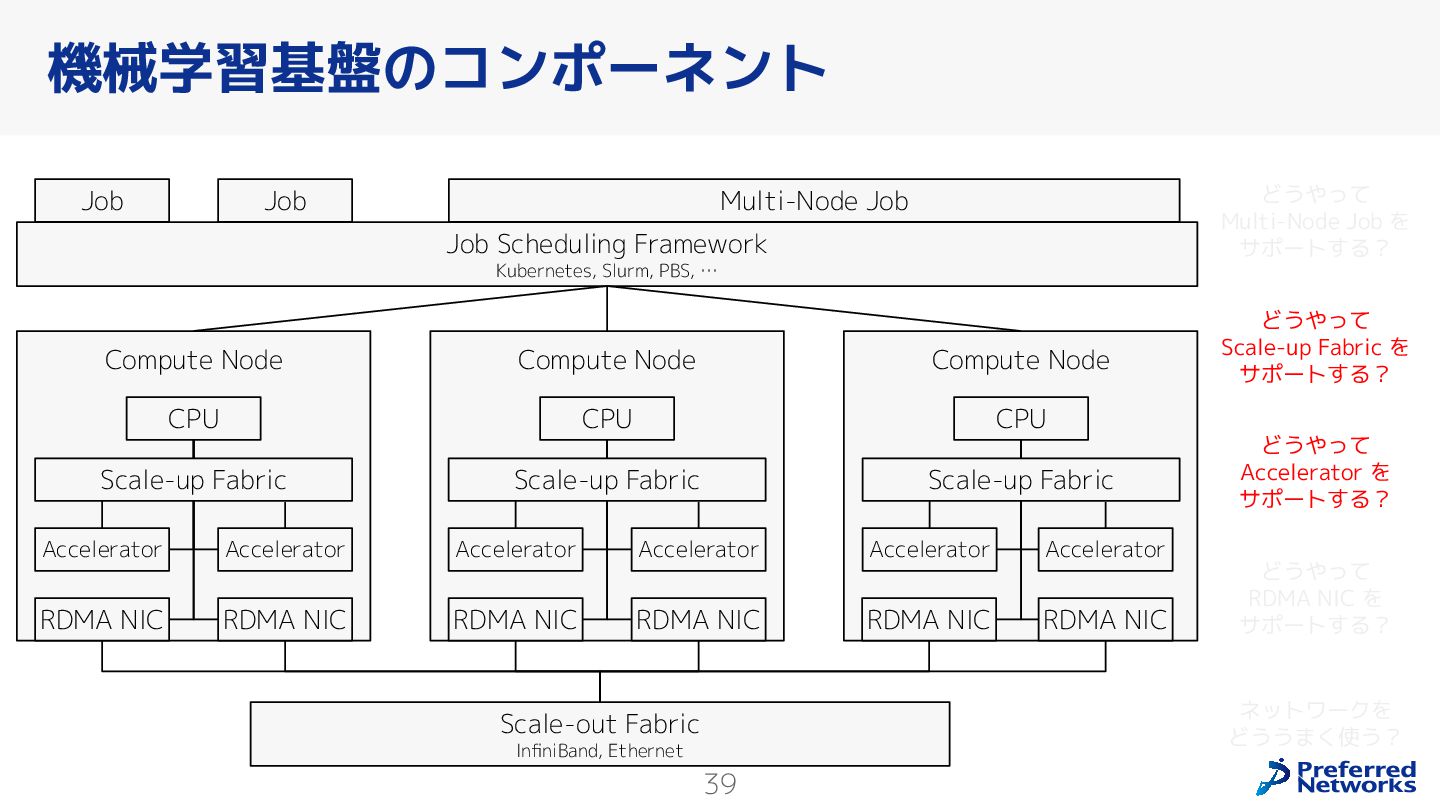{kind=link}
{kind=link}
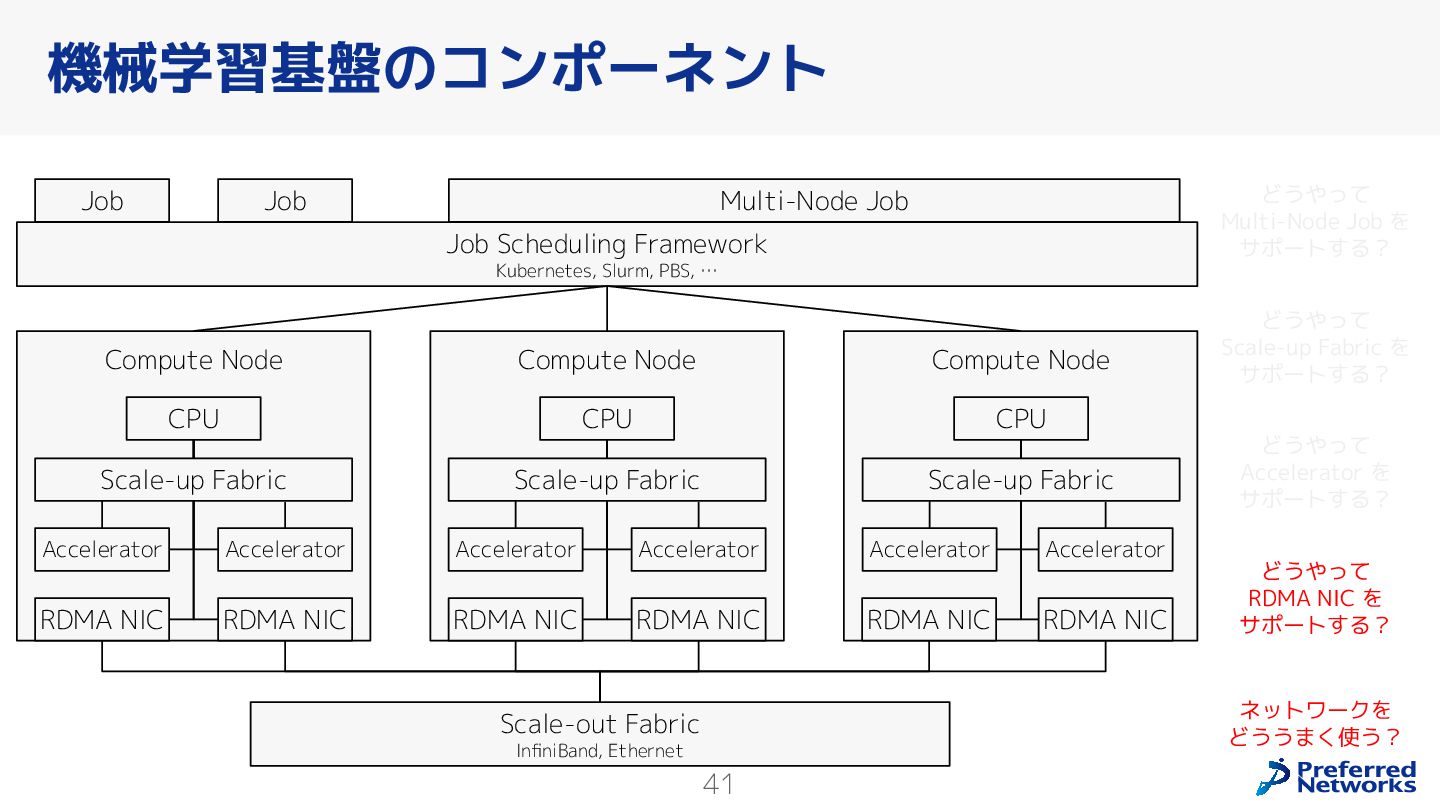{kind=link}
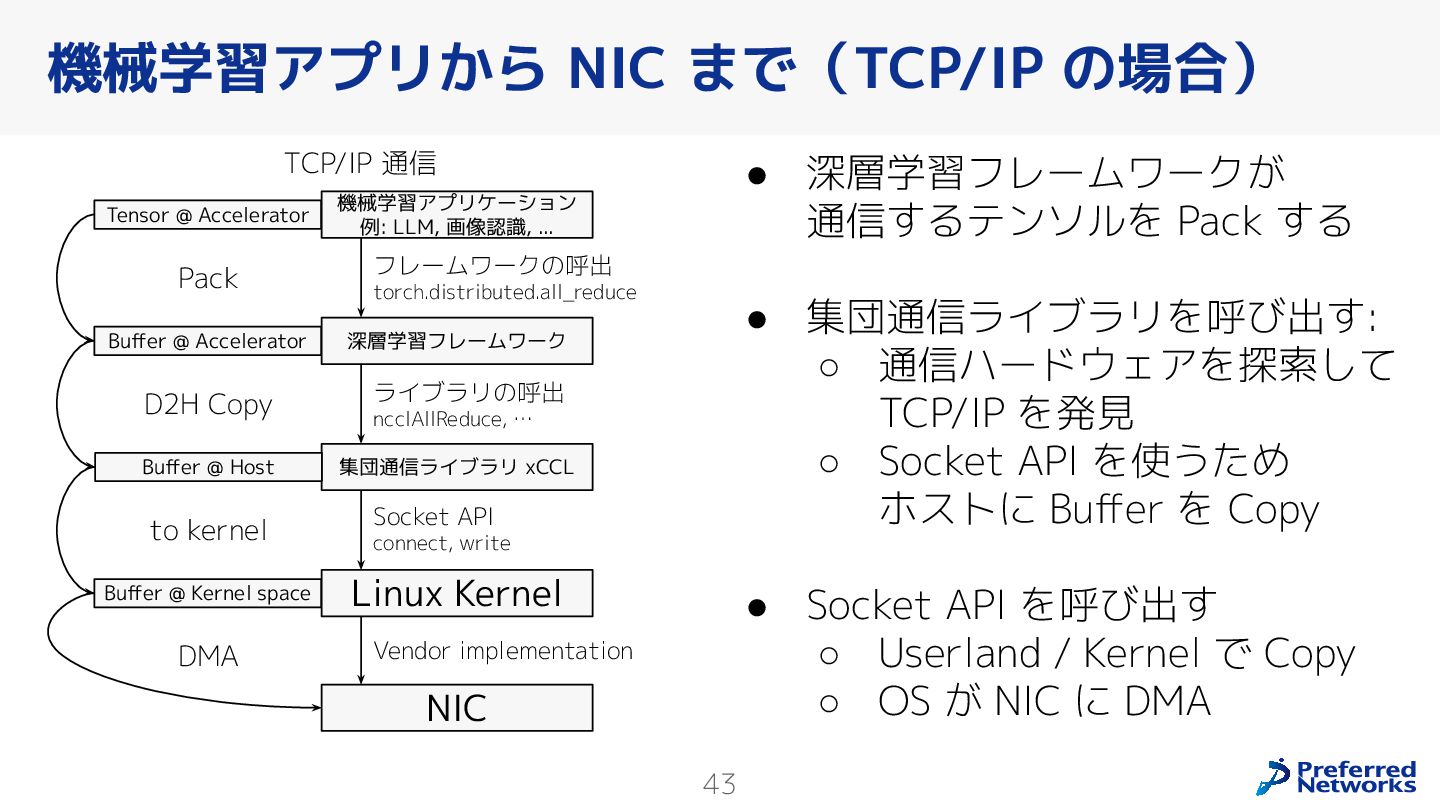
{kind=link}
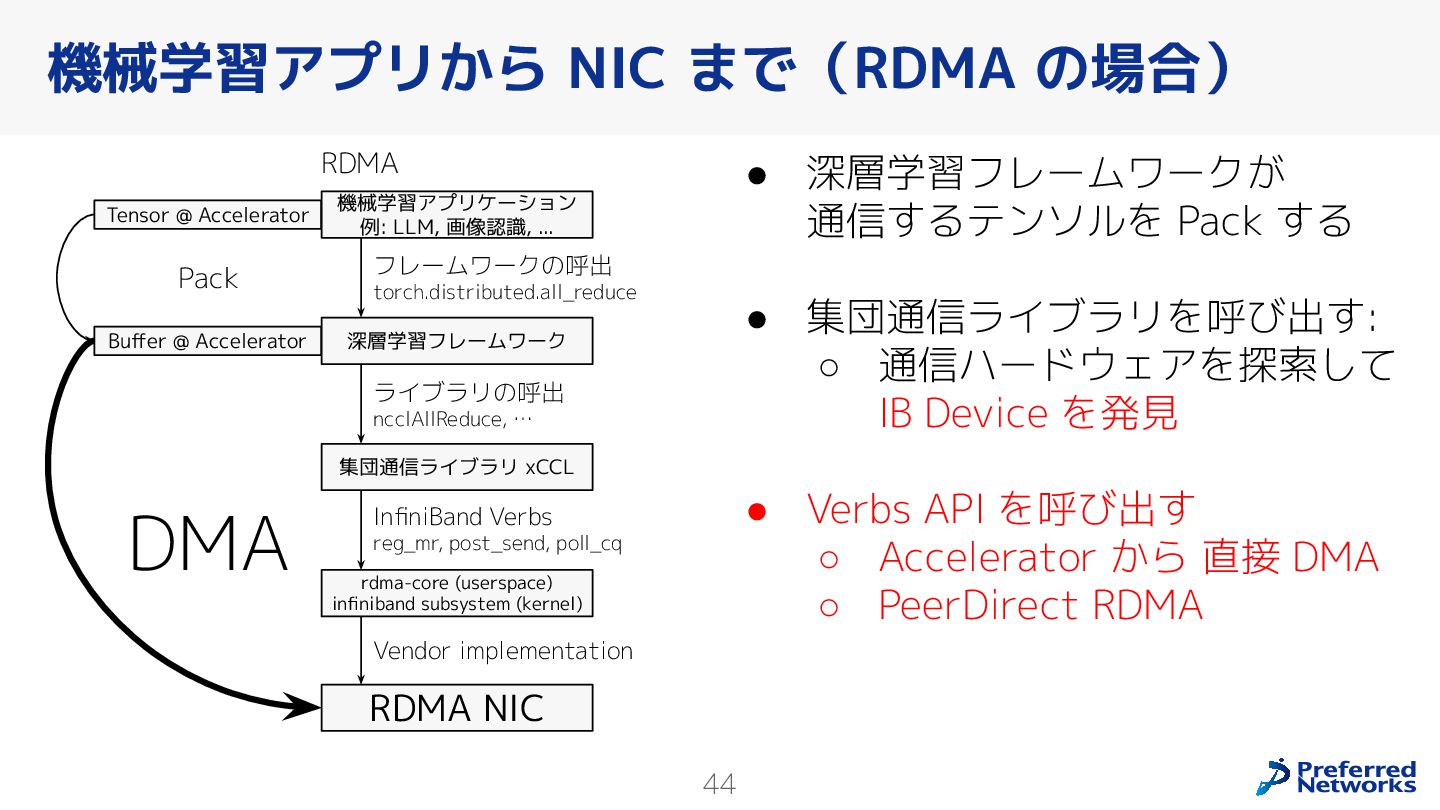
{kind=link}
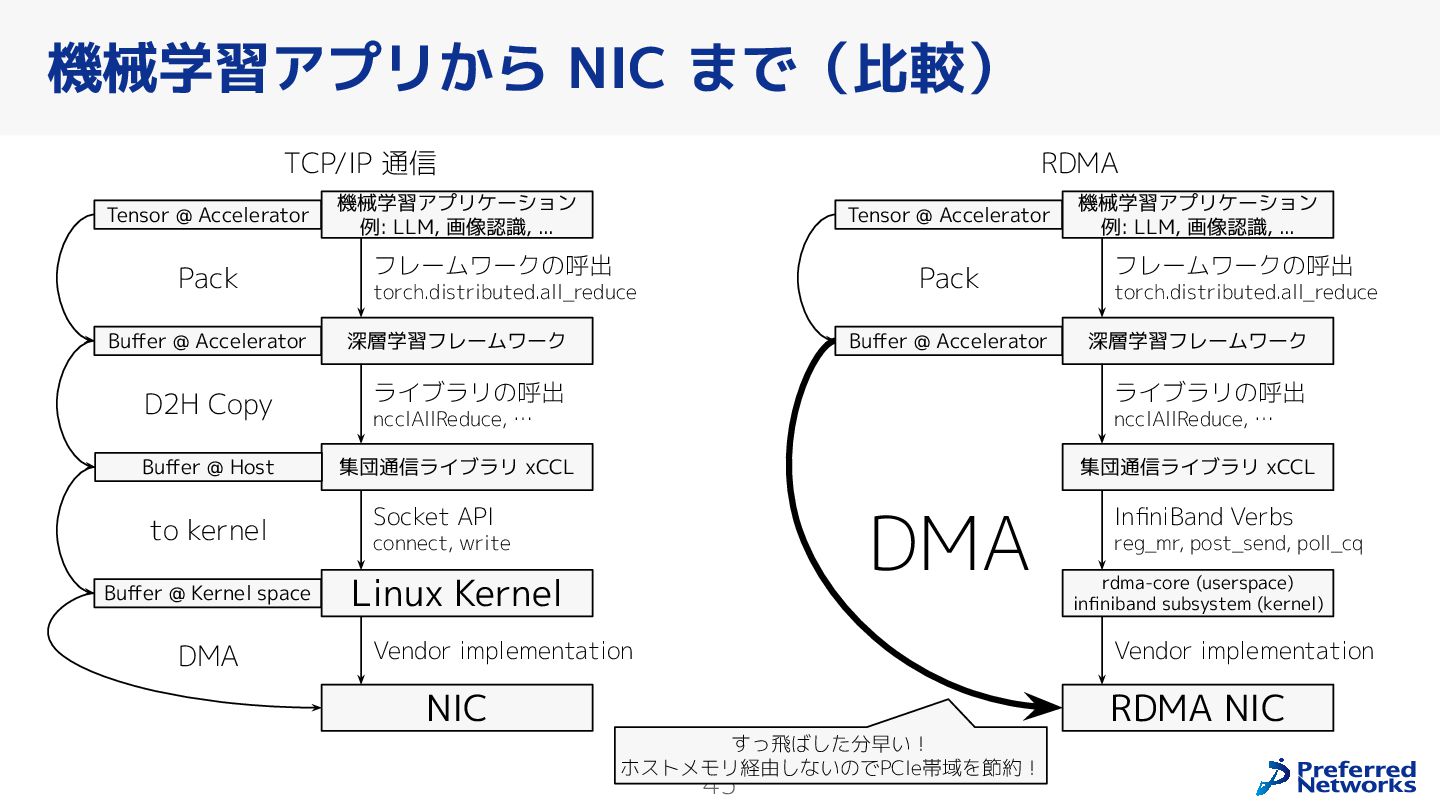
{kind=link}
{kind=link}
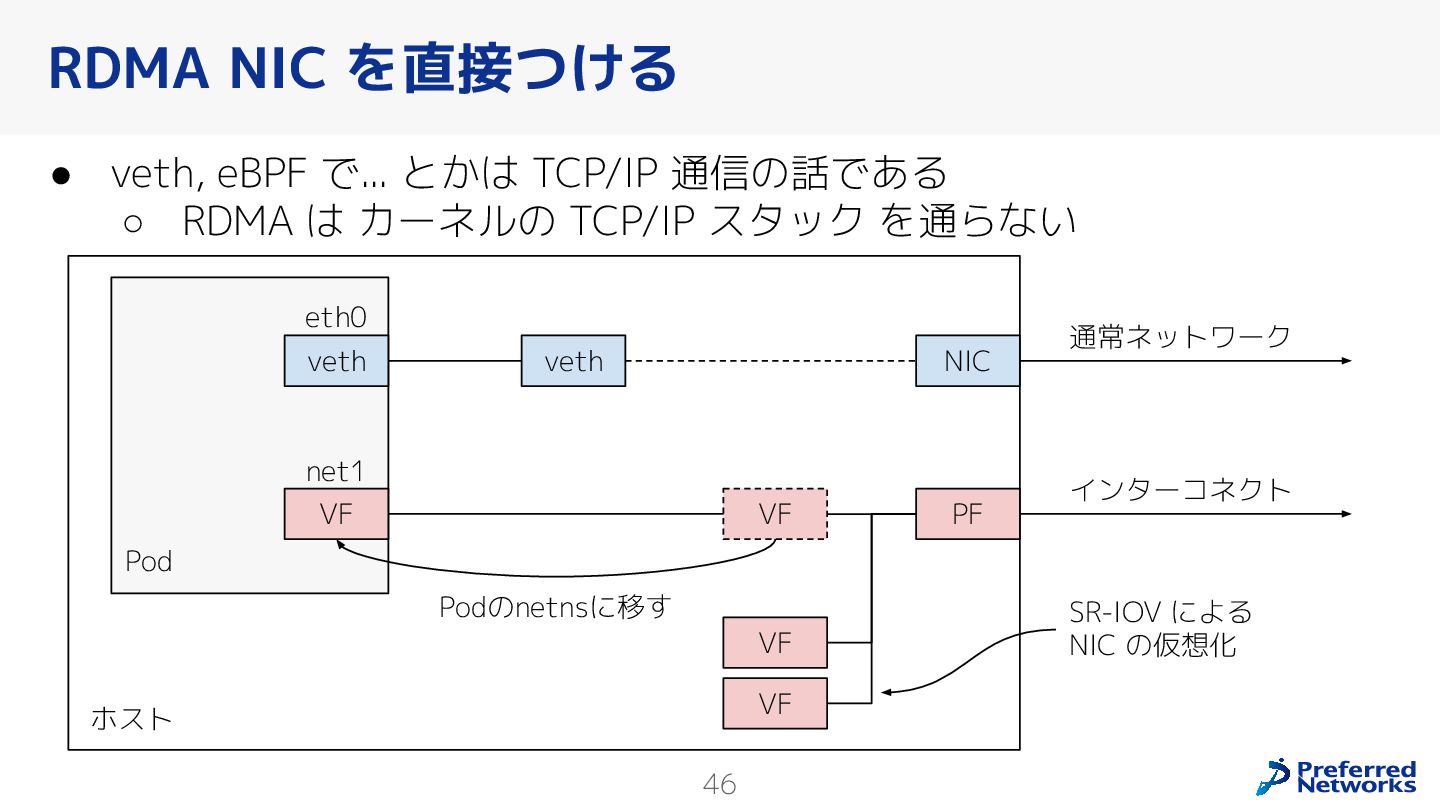{kind=link}
{kind=link}
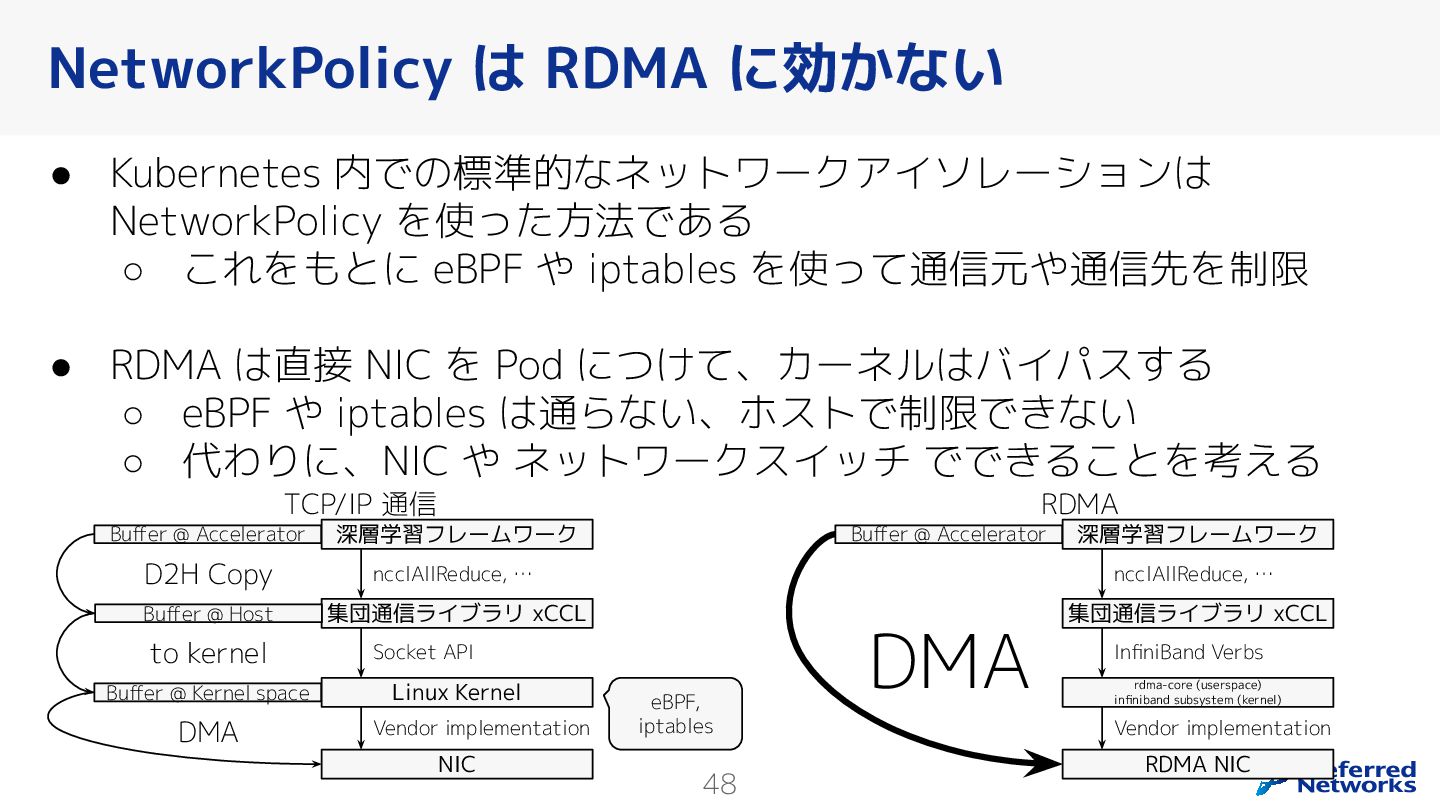{kind=link}
{kind=link}
{kind=link}
{kind=link}
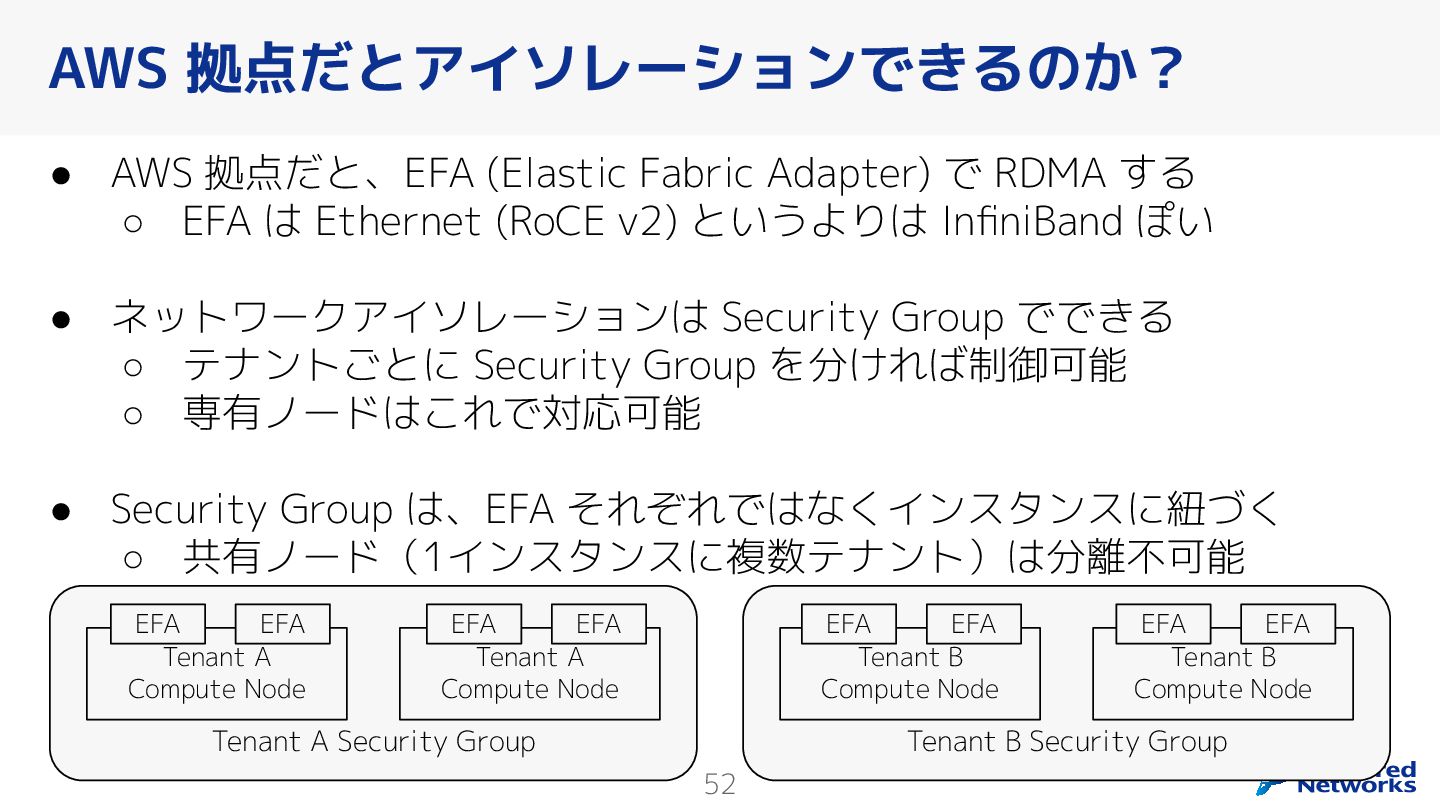{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
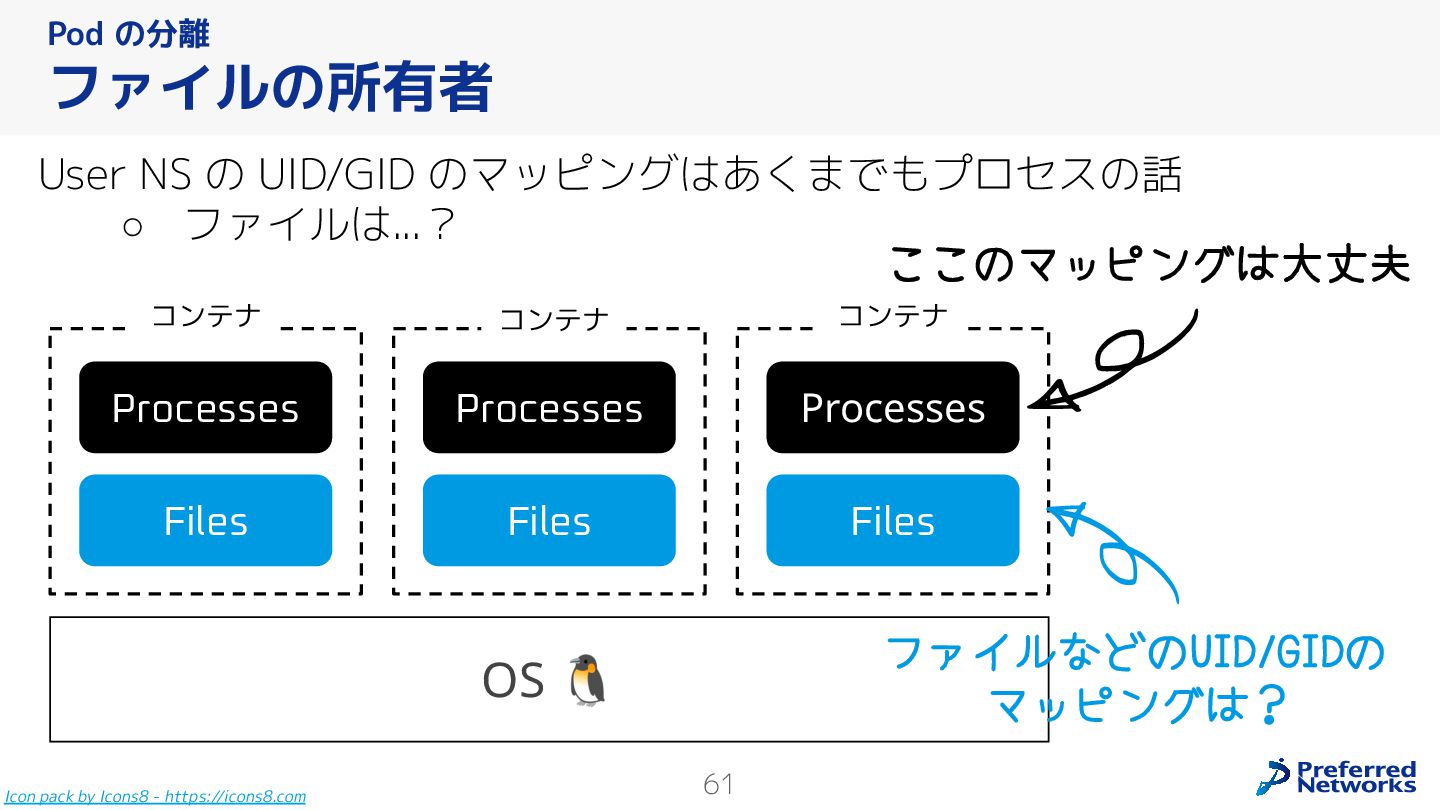{kind=link}
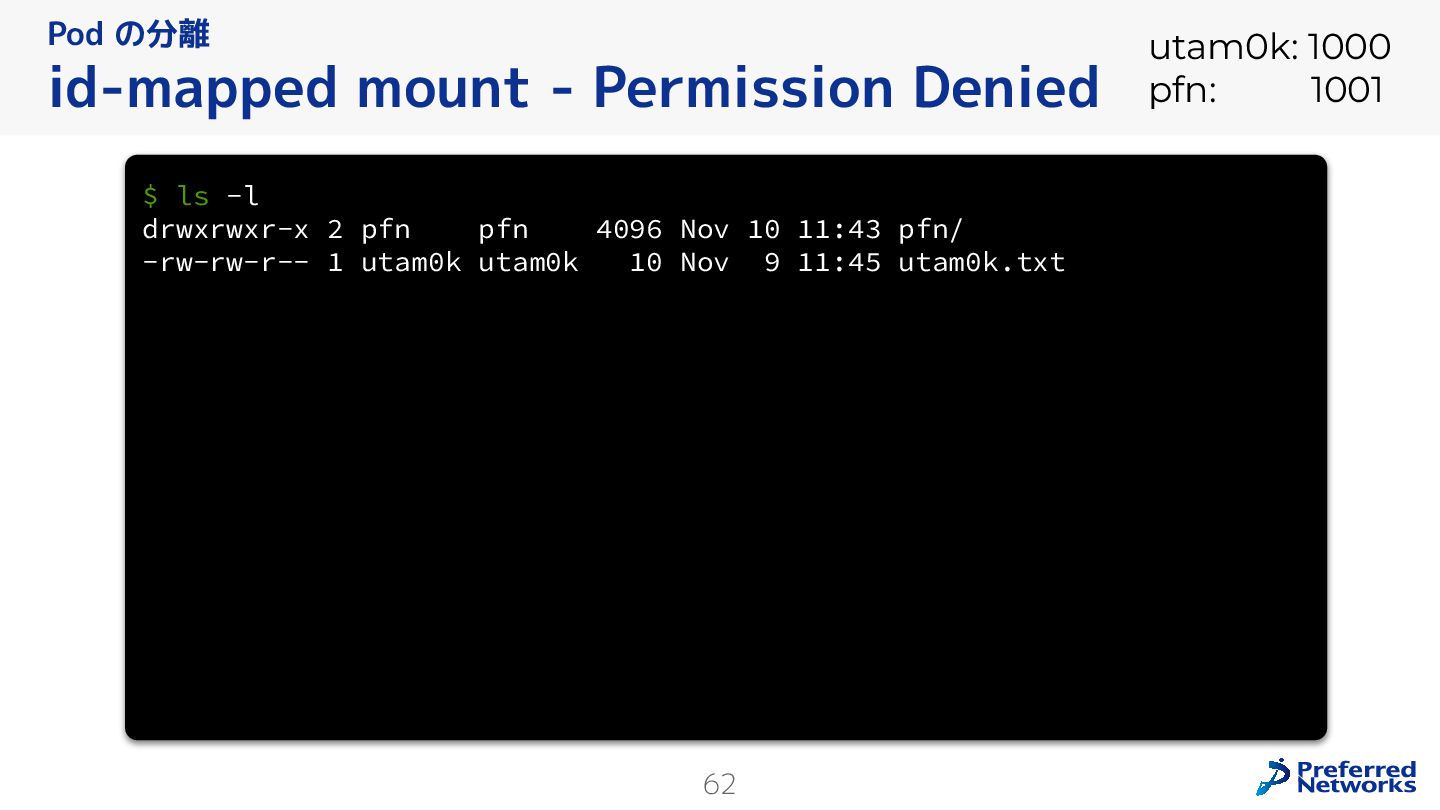{kind=link}
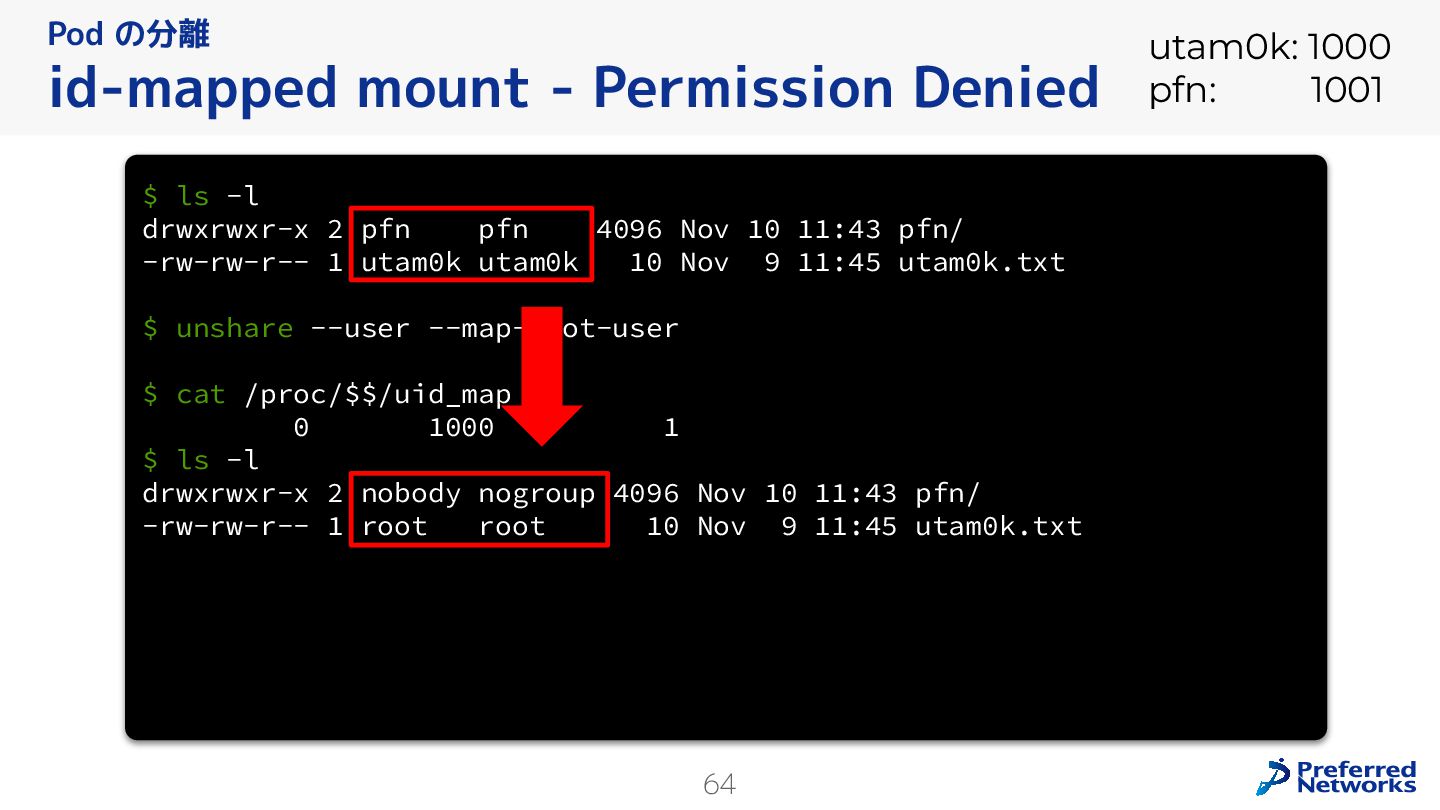
{kind=link}
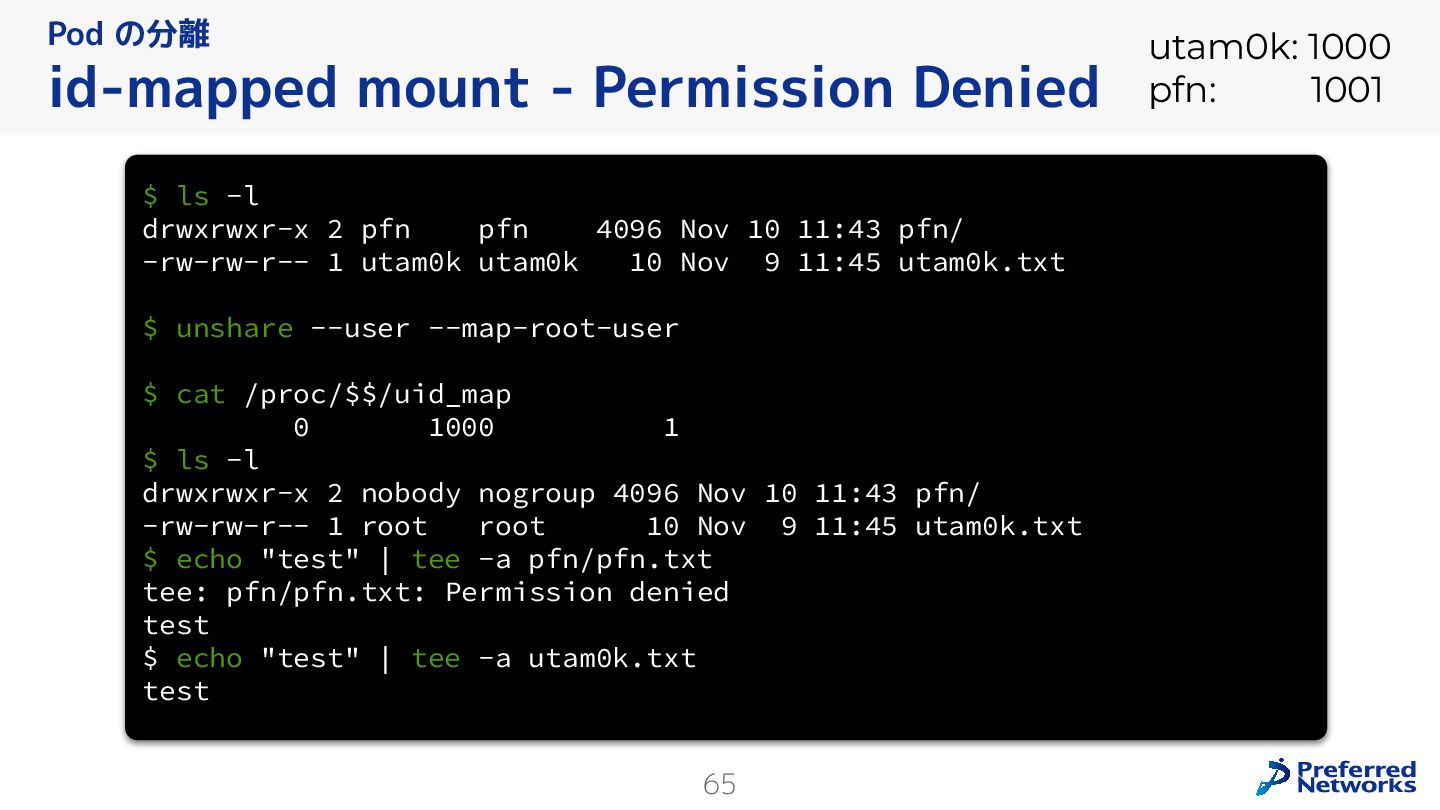
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
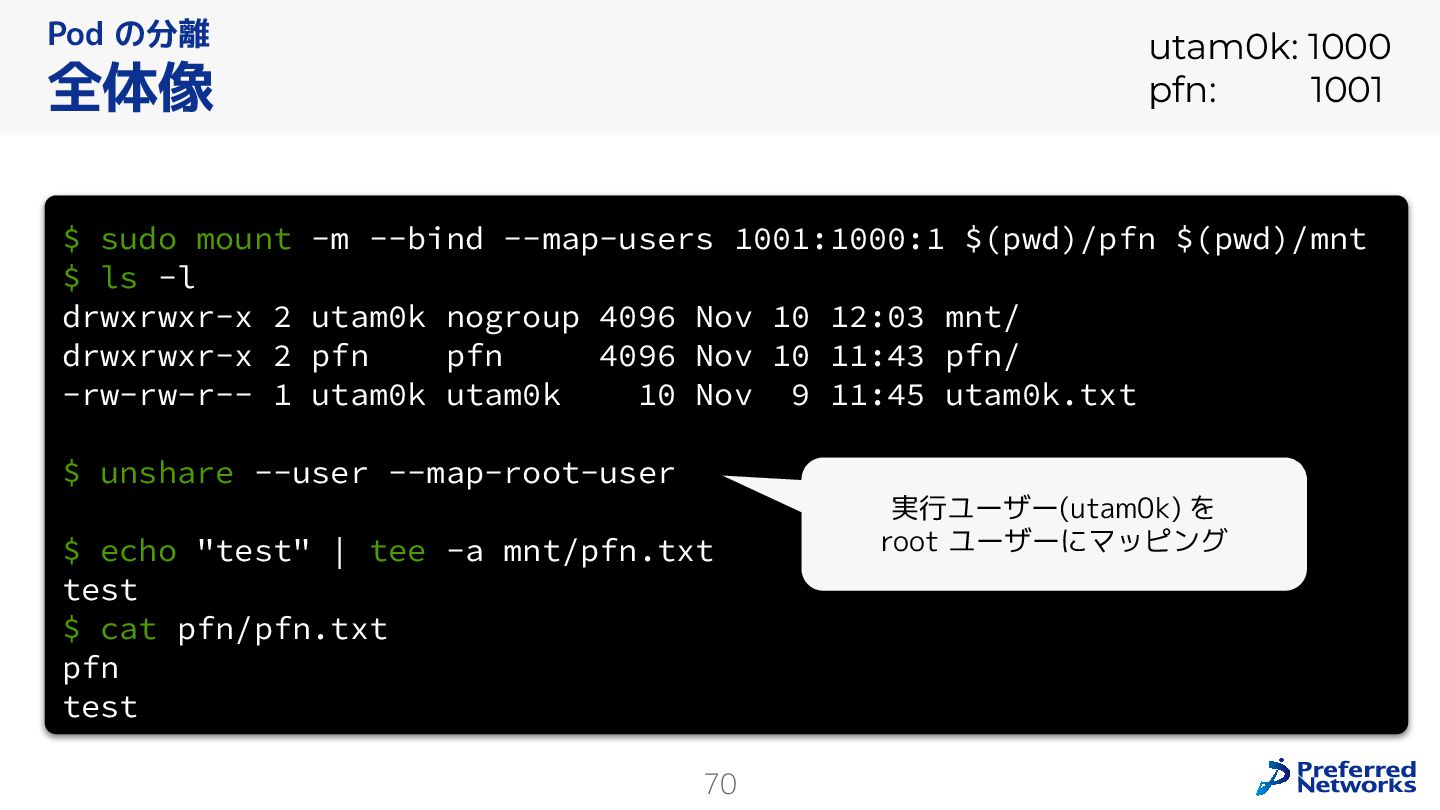{kind=link}
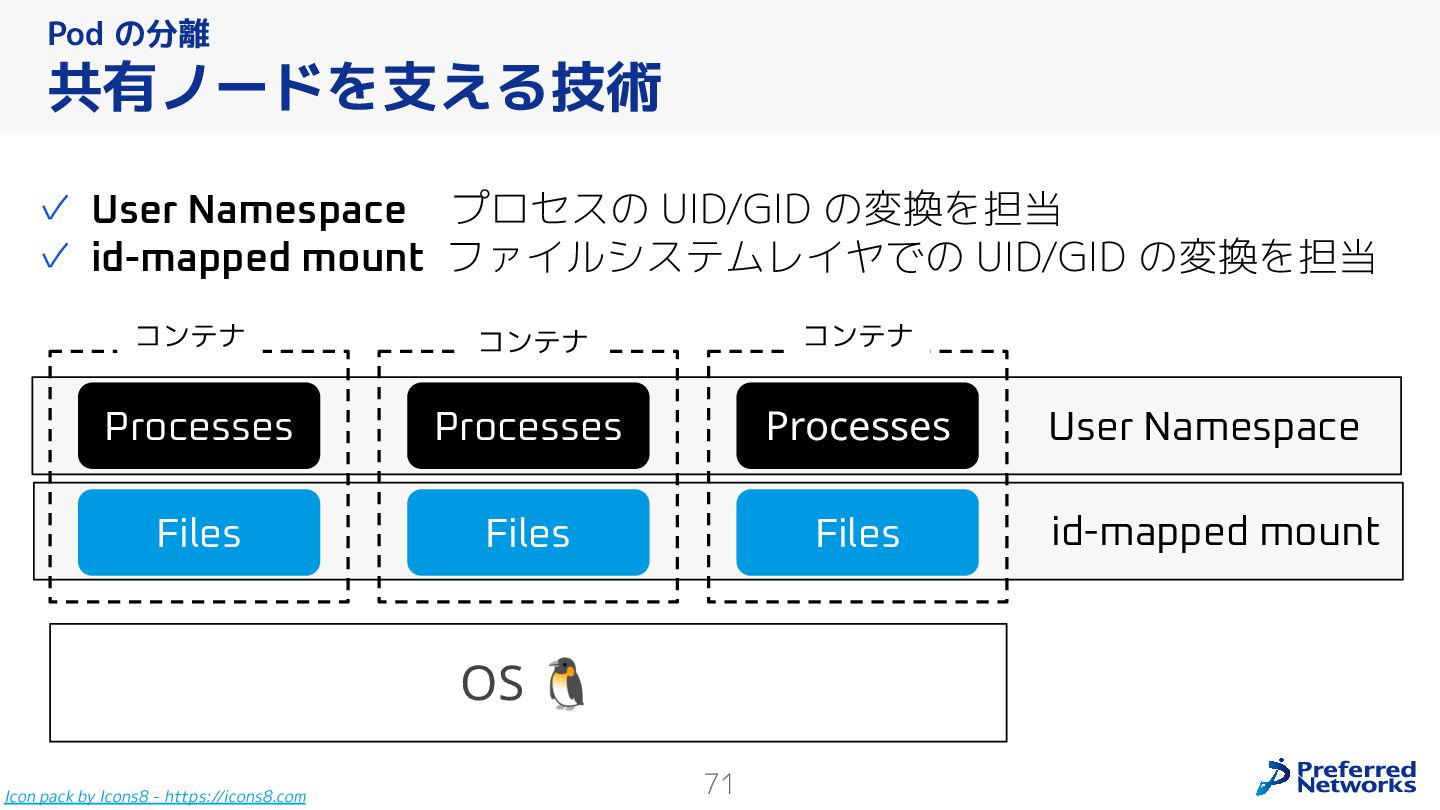{kind=link}
{kind=link}
{kind=link}
{kind=link}
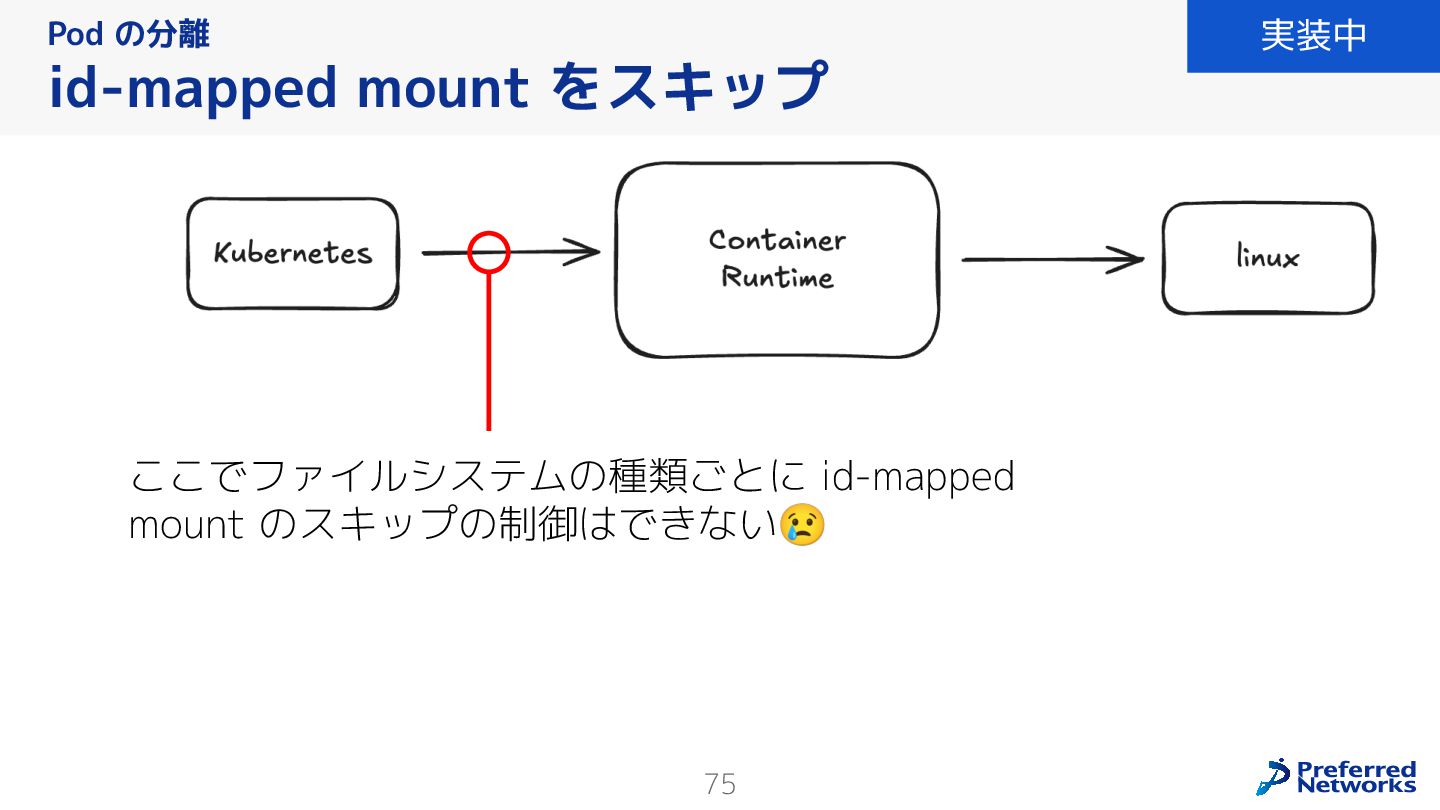{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
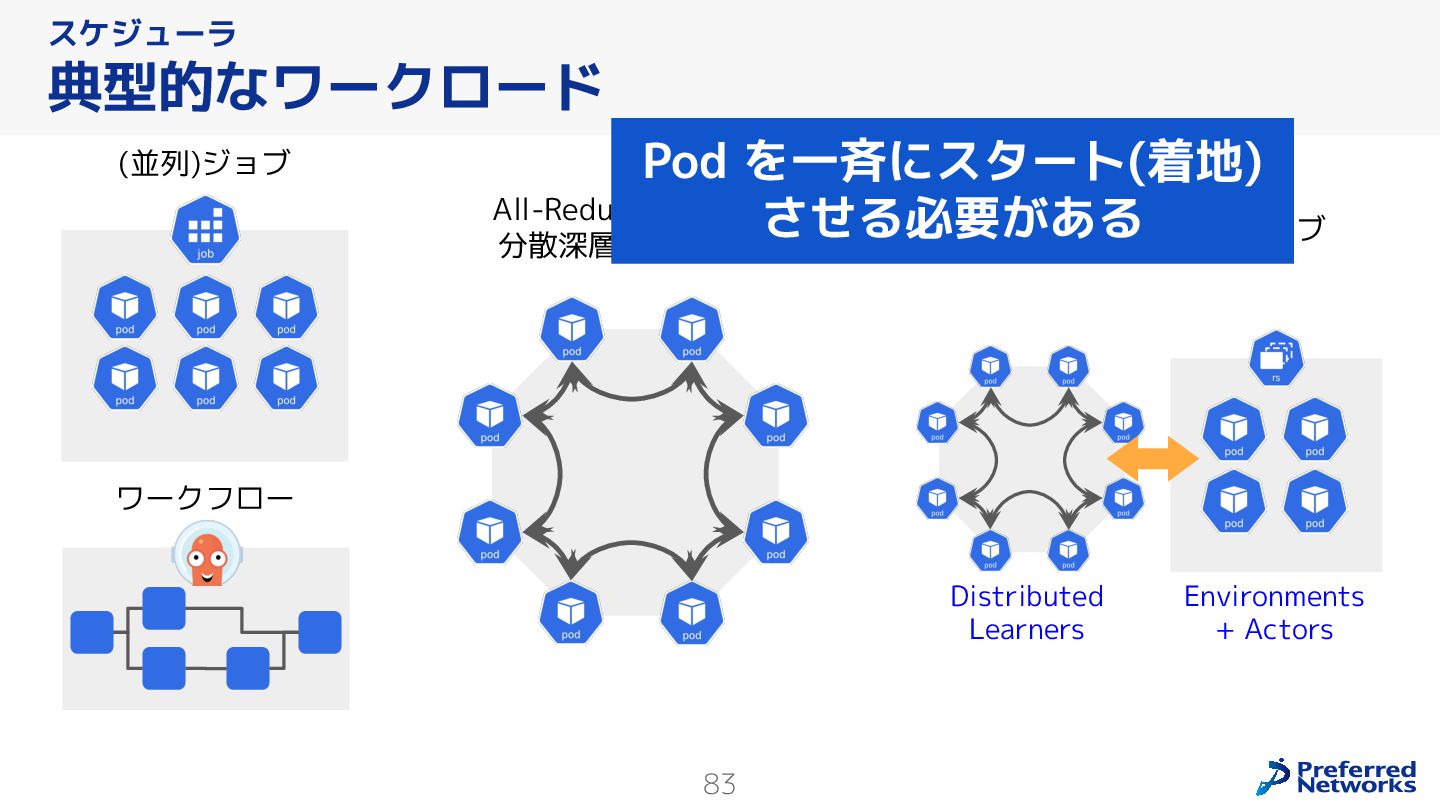{kind=link}
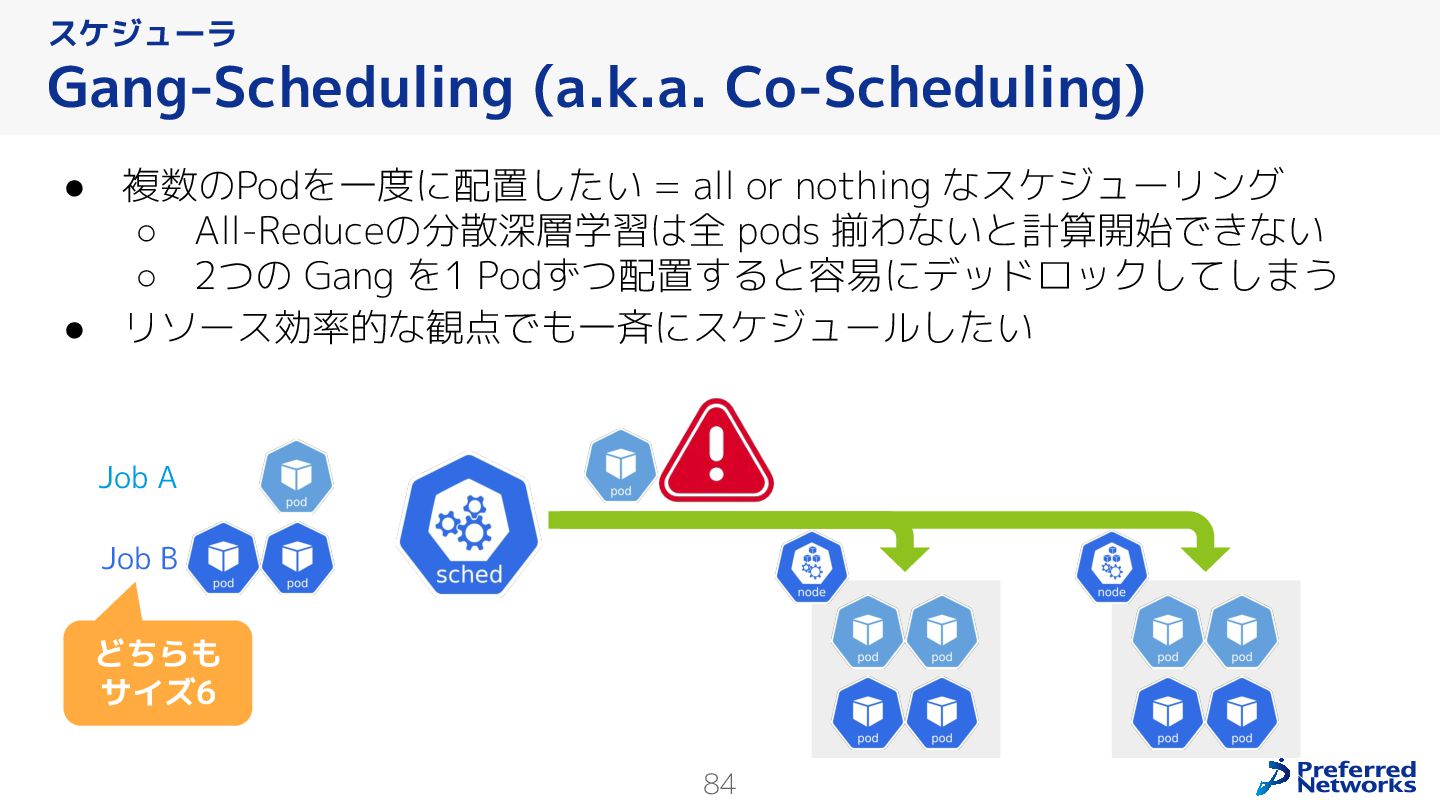{kind=link}
{kind=link}
{kind=link}
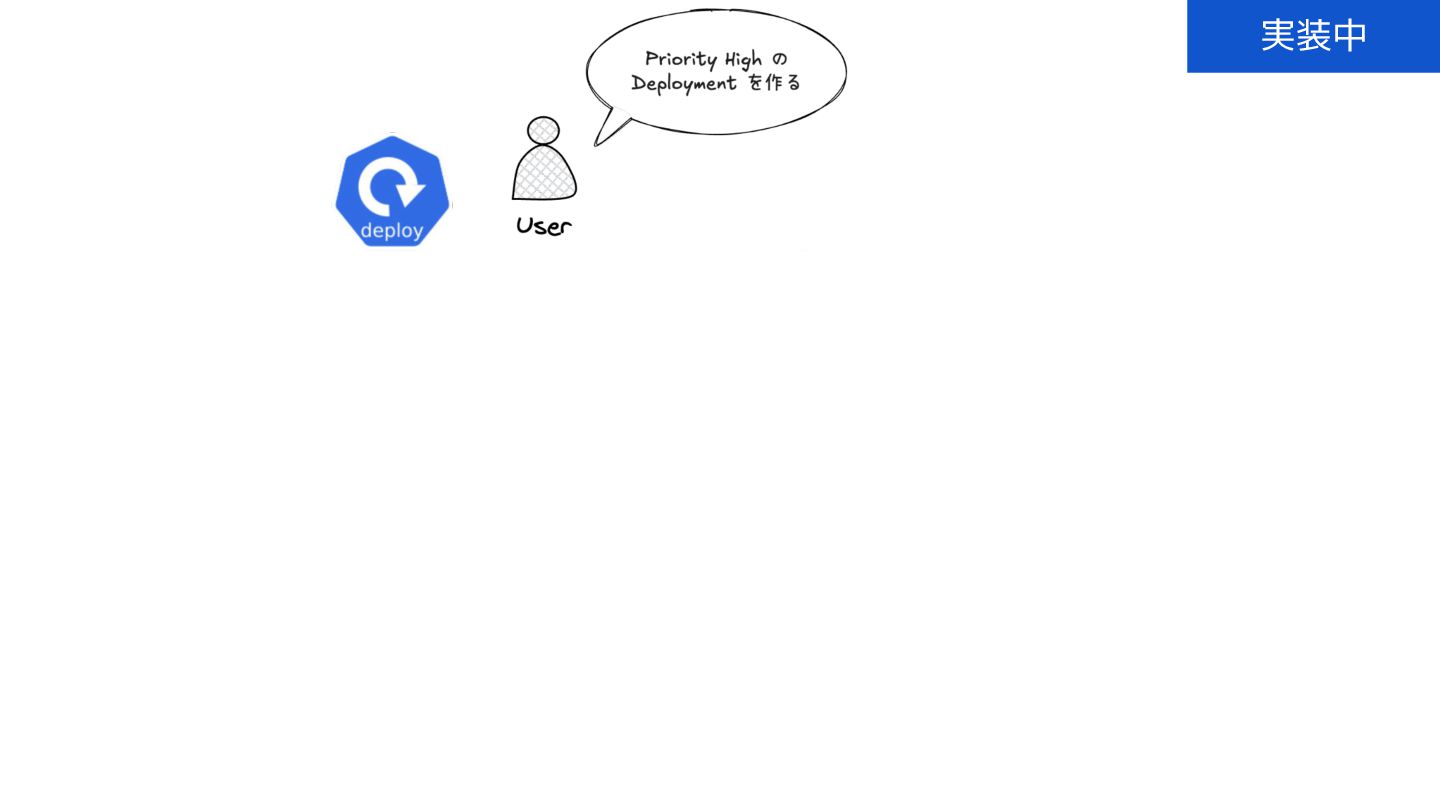{kind=link}
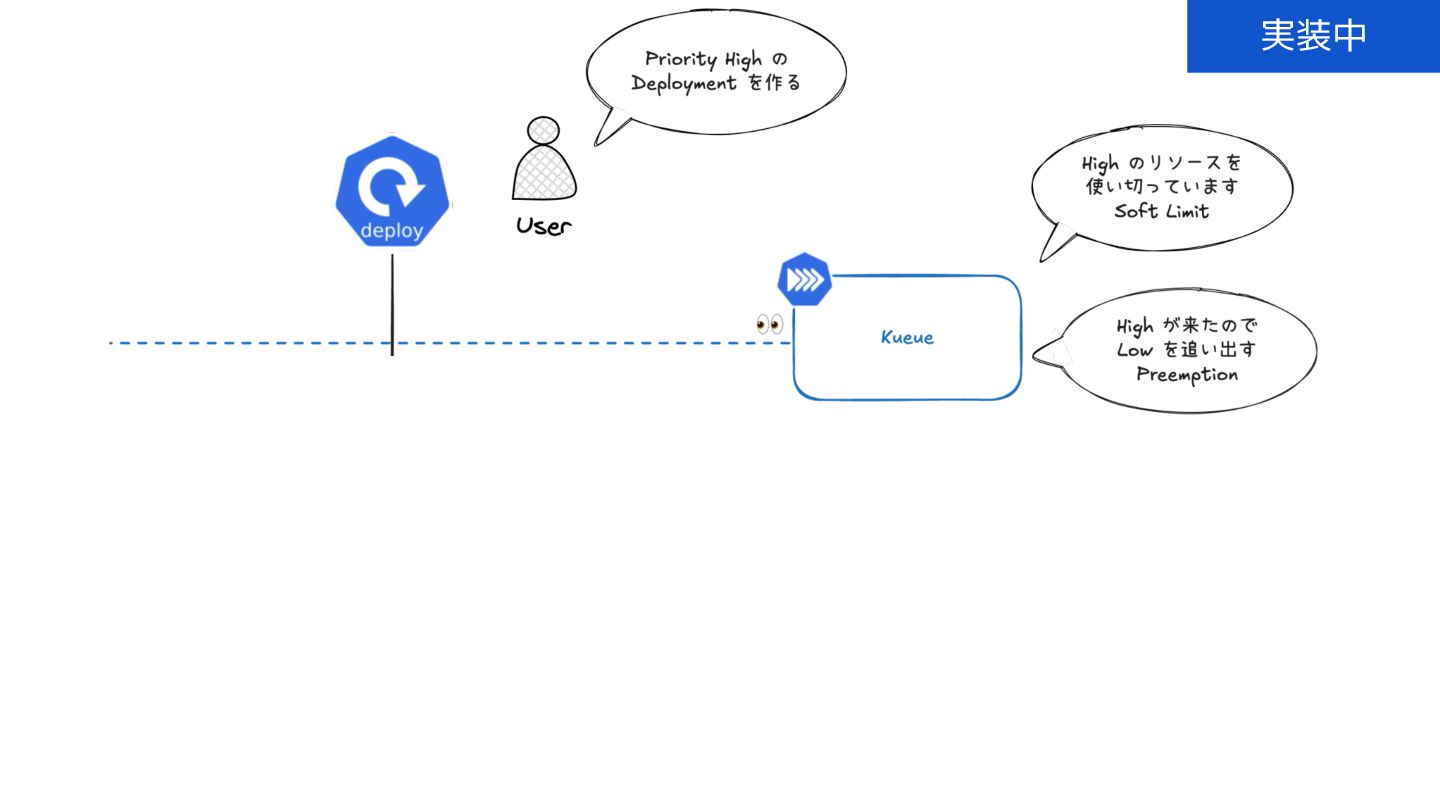{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}