(download for flawless quality)
Develop the correct intuitions of what fold left and fold right actually do, and how different these two functions are
Learn other important concepts about folding, thus reinforcing and expanding on the material seen in parts 1 and 2
Includes a brief introduction to (or refresher of) asymptotic analysis and 𝛩-notation
Part 3 - through the work of Tony Morris and Richard Bird
keywords: accumulator trick, asymptotic analysis, big o notation, complexity, duality theorems of fold, fold left, fold right, folding, foldleft, foldright, left fold, performance, recursion, right fold, tail-recursion, 𝛩-notation
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![reverse ∷ α → [α] reverse = = ⧺ []](https://files.speakerdeck.com/presentations/714b4dfd98d547afb69bdfd8057c1862/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def concatenate[A]: List[A] => List[A] => List[A] = { def](https://files.speakerdeck.com/presentations/714b4dfd98d547afb69bdfd8057c1862/slide_35.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![concat ∷ [ α ] → [α] concat = (⧺)](https://files.speakerdeck.com/presentations/714b4dfd98d547afb69bdfd8057c1862/slide_41.jpg){kind=link}
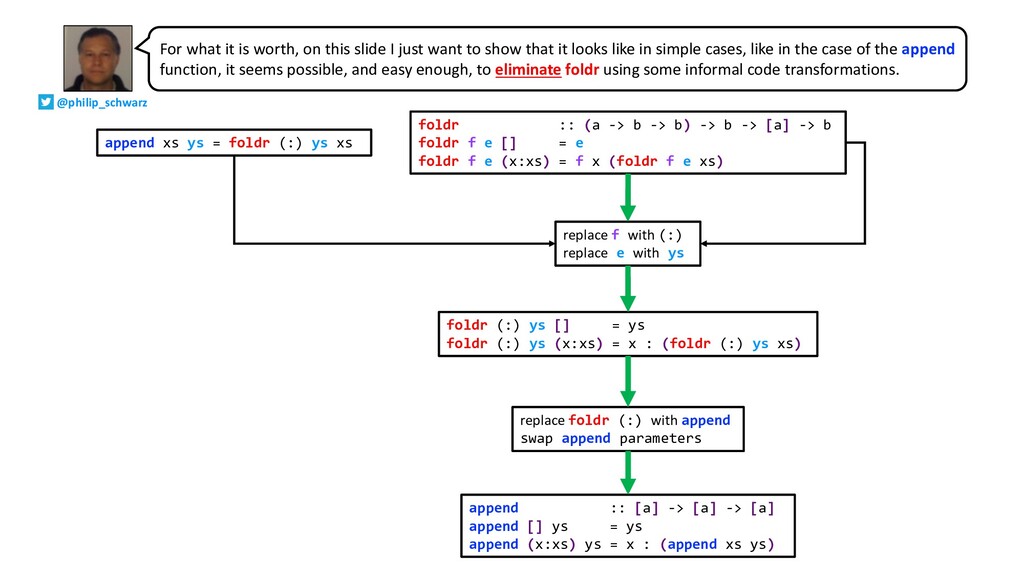{kind=link}
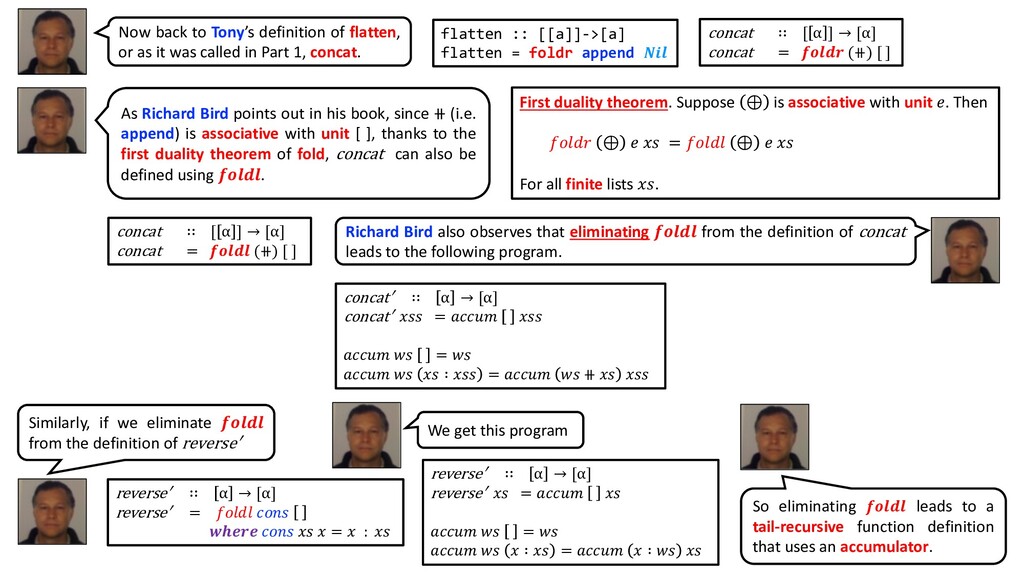{kind=link}
{kind=link}
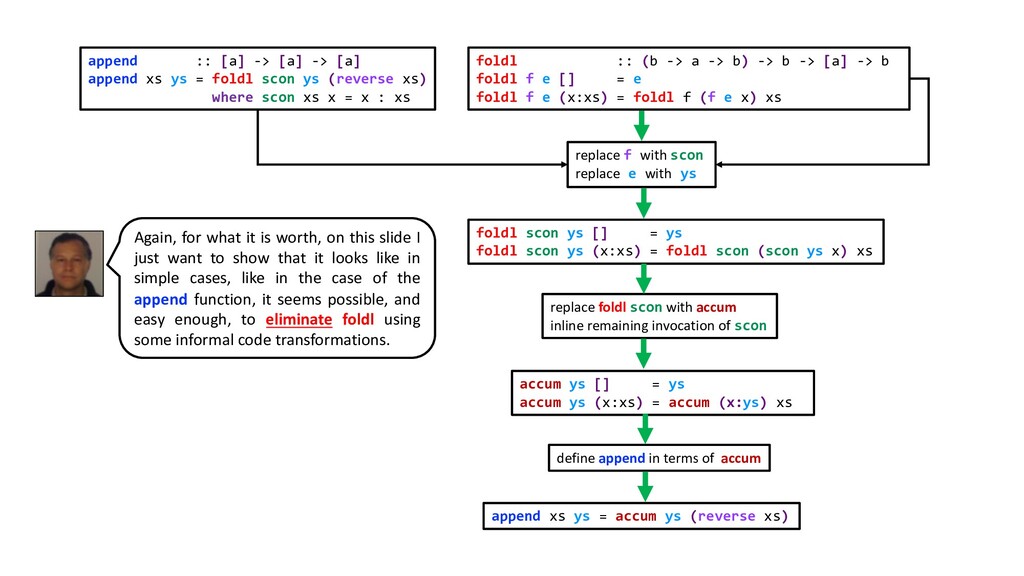{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
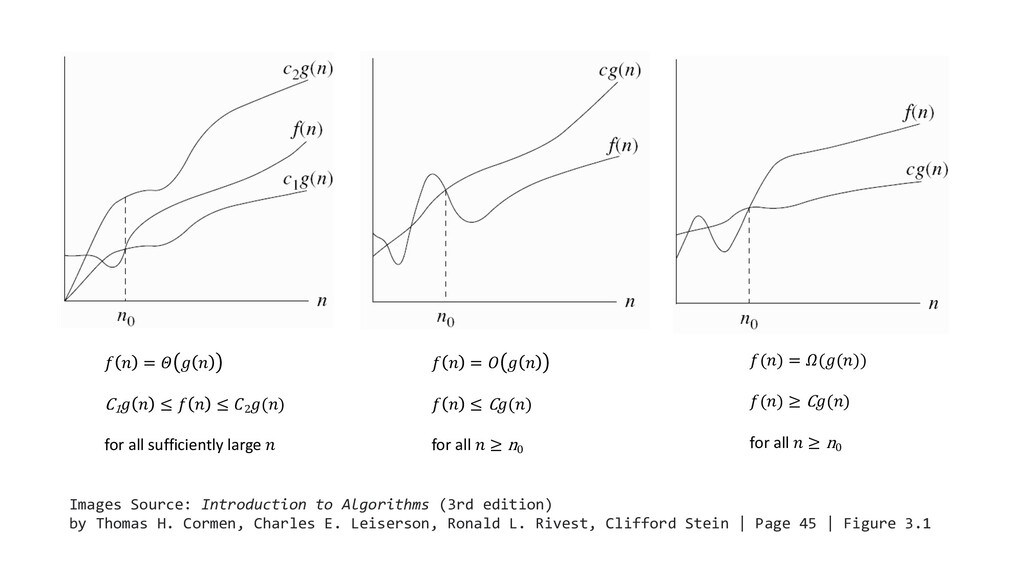{kind=link}
![reverse ∷ α → [α] reverse = = append []](https://files.speakerdeck.com/presentations/714b4dfd98d547afb69bdfd8057c1862/slide_51.jpg){kind=link}
{kind=link}