Slides from the talk given at the inaugural Hive London meetup (http://www.meetup.com/HiveLondon/events/69366482/). Covers a few odds and ends around making Hive queries faster through join optimisation etc.
(server, 5 minute time window, entity type) chunks. • HoneyMaker aggregates these together (atomically), and ensures events are in the correct time bucket. Pushes to HDFS. • Apiary polls HDFS, and loads data into Hive.
Tasks can be chained together with events propagated through an Observer model. • Events are fired when data arrives – eliminates the need for cron jobs etc. • Manages pulling data from, and pushing computations back into SQL server.
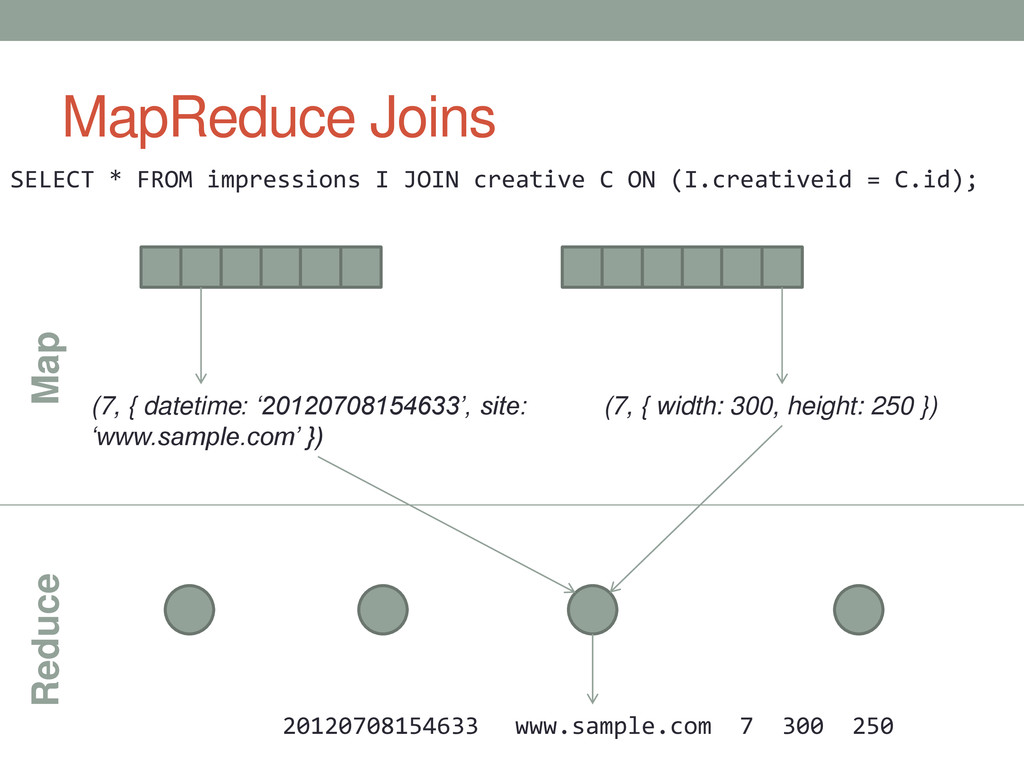
BR JOIN creative C ON (BR.creativeid = C.id); In our schema, a bid request gets assigned a creative id if we want to bid on the user. We decide not to bid on most requests, so most creative ids are NULL.
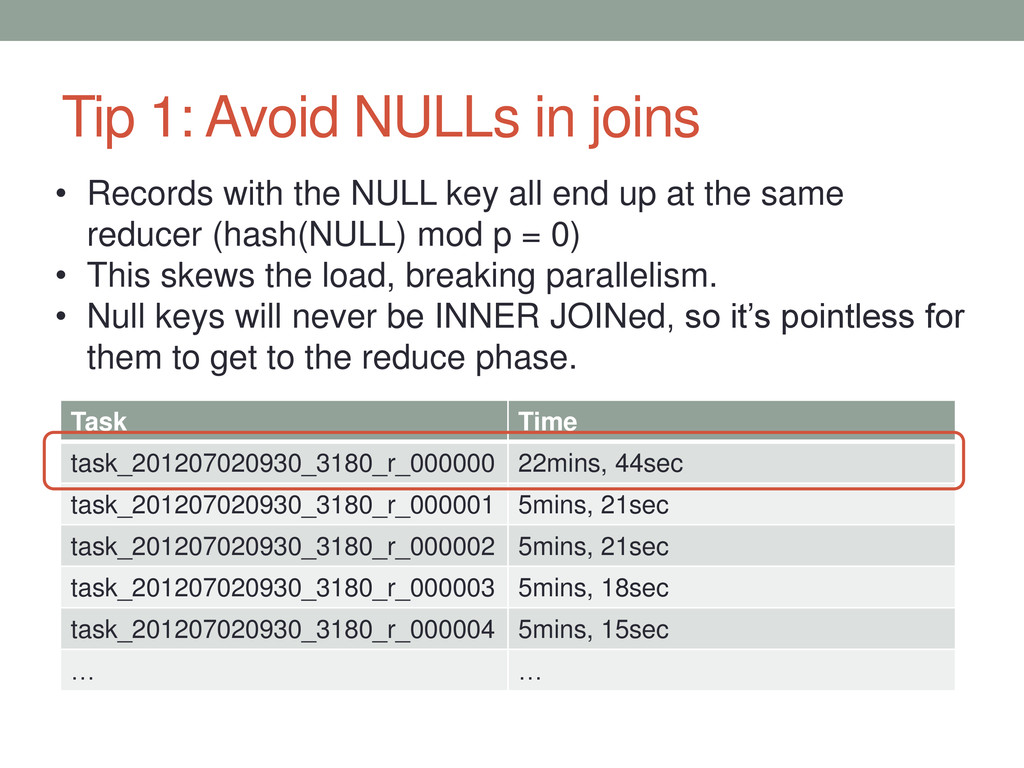
BR JOIN creative C ON (BR.creativeid = C.id); Total MapReduce CPU Time Spent: 0 days 2 hours 10 minutes 42 seconds 20 msec Task Time task_201207020930_3180_r_000000 22mins, 44sec task_201207020930_3180_r_000001 5mins, 21sec task_201207020930_3180_r_000002 5mins, 21sec task_201207020930_3180_r_000003 5mins, 18sec task_201207020930_3180_r_000004 5mins, 15sec … … • Records with the NULL key all end up at the same reducer (hash(NULL) mod p = 0) • This skews the load, breaking parallelism. • Null keys will never be INNER JOINed, so it’s pointless for them to get to the reduce phase.
BR JOIN creative C ON (BR.creativeid = C.id); Total MapReduce CPU Time Spent: 0 days 2 hours 10 minutes 42 seconds 20 msec SELECT COUNT(1) FROM bidrequest BR JOIN creative C ON (BR.creativeid = C.id AND BR.creativeid IS NOT NULL); Total MapReduce CPU Time Spent: 0 days 1 hours 9 minutes 44 seconds 660 msec Moral: Reducing is slow, avoid it if possible.
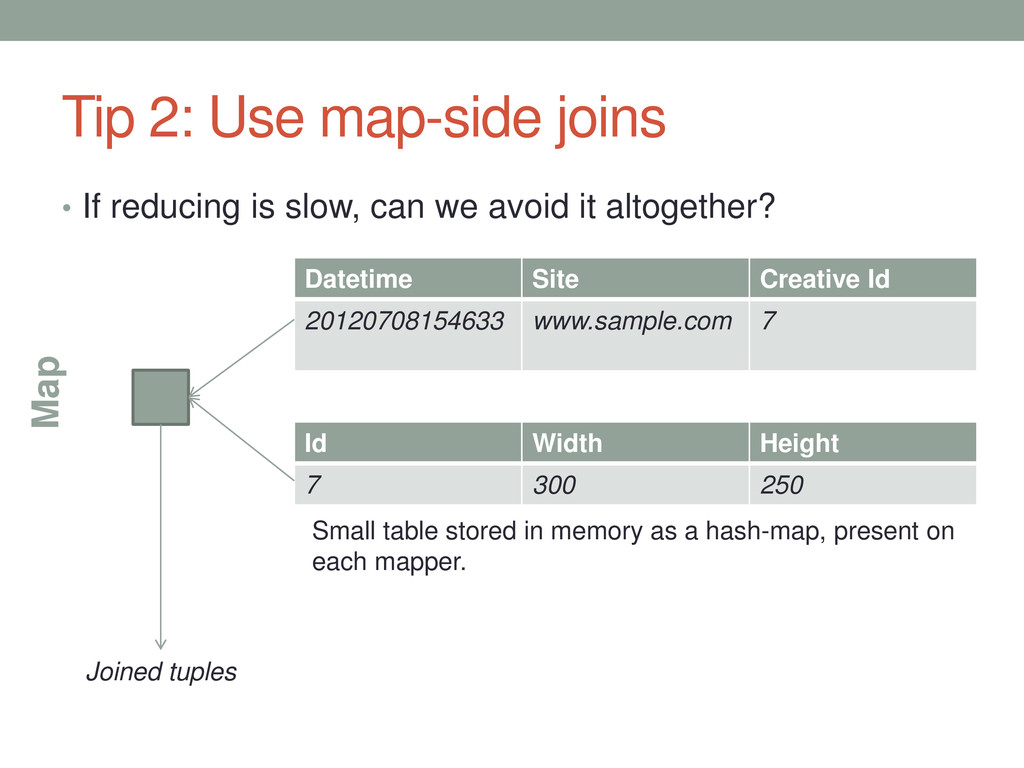
can we avoid it altogether? Datetime Site Creative Id 20120708154633 www.sample.com 7 Id Width Height 7 300 250 Map Joined tuples Small table stored in memory as a hash-map, present on each mapper.
COUNT(1) FROM bidrequest BR JOIN creative C ON (BR.creativeid = C.id AND BR.creativeid IS NOT NULL); Total MapReduce CPU Time Spent: 55 minutes 38 seconds 570 msec
out in order, one at a time, left-to-right. • Joining to a big table is expensive. SELECT COUNT(1) FROM bidrequest BR JOIN creative C ON (BR.creativeid = C.id AND BR.creativeid IS NOT NULL) JOIN adgroup A ON (C.adgroupid = A.id) Total MapReduce CPU Time Spent: 0 days 1 hours 19 minutes 10 seconds 80 msec
BR JOIN creative C ON (…) JOIN adgroup A ON (C.adgroupid = A.id) Total MapReduce CPU Time Spent: 0 days 1 hours 19 minutes 10 seconds 80 msec SELECT COUNT(1) FROM adgroup A JOIN creative C ON (C.adgroupid = A.id) JOIN bidrequest BR ON (…) Total MapReduce CPU Time Spent: 0 days 1 hours 2 minutes 57 seconds 980 msec
your joins, but you can always group them: SELECT /*+ MAPJOIN(AC) */ COUNT(1) FROM bidrequest BR JOIN ( SELECT C.id AS creativeid, A.id AS adgroupid FROM creative C JOIN adgroup A ON (C.adgroupid = A.id) ) AC ON (BR.creativeid = AC.creativeid AND BR.creativeid IS NOT NULL); Total MapReduce CPU Time Spent: 59 minutes 56 seconds 490 msec
Server allows you to write: SELECT x, y, ROW_NUMBER() OVER (PARTITION BY a, b ORDER BY c) AS rownum FROM srctable; • Often useful for picking out the first row from an arbitrary partition.
support this, but you can replicate the behaviour with a UDF and a little syntactic sugar. SELECT x, y, ROW_NUMBER() OVER (PARTITION BY a, b ORDER BY c) AS rownum FROM srctable; becomes: SELECT x, y, partitionedRowNumber(a, b) AS rownum FROM ( SELECT x, y, a, b FROM srctable DISTRIBUTE BY a, b SORT BY a, b, c ) iq;
in Hive using map-side aggregations (unless you turn it off via hive.map.aggr). • It works a little like a very aggressive combiner. • It uses a HashMap to store GROUP BY keys against values in memory. • There are obviously a few ways in which this can run out of memory…
things which you can do to stop this: • Decrease mapred.max.split.size • Decrease hive.groupby.mapaggr.checkinterval • Decrease hive.map.aggr.hash.percentmemory • Decrease hive.map.aggr.hash.force.flush.memory.threshold • There are no golden rules – it all depends on your data and queries. • Keep experimenting – the more you decrease, the slower the query.
about disk space than CPU, then this is a neat trick. INSERT OVERWRITE TABLE bigtable PARTITION(part_key=‘clustered’) SELECT … FROM bigtable WHERE part_key=‘not_clustered’ CLUSTER BY …;
about disk space than CPU, then this is a neat trick. INSERT OVERWRITE TABLE bigtable PARTITION(part_key=‘clustered’) SELECT … FROM bigtable WHERE part_key=‘not_clustered’ CLUSTER BY …; Generally 10-30% more efficiently packed. Cluster by columns which take up the most disk space, but have little entropy. URLs are a good example.
you can into the join predicate). 2. Use map-side joins. 3. Group & order joins. 4. Replicating RANK() / OVER (PARTITION BY…). 5. Optimise GROUP BYs. 6. Cluster within RCFiles.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Any Questions? • [email protected] • philiptromans.me Struq are hiring! [email protected]](https://files.speakerdeck.com/presentations/4ffd50376c4faa0001028b12/slide_26.jpg){kind=link}