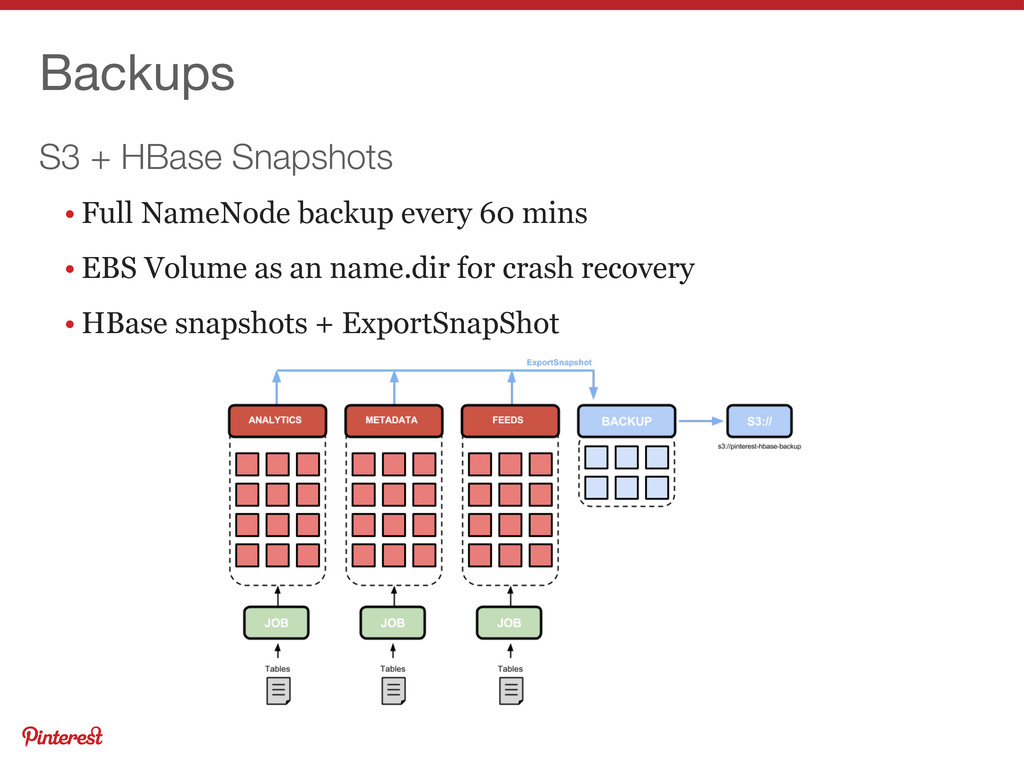
Bloom filters for pretty much everything • Manual / Rolling major compactions • Reverse DNS on EC2 • 3 ZooKeepers in quorum • 1 NameNode / Sec-NameNode / Master • 1 EBS volume for fsImage / 1 Elastic IP • 10-50 nodes per cluster
to drive config management • Repackaged modifications to HDFS / HBase • Ubuntu .deb packages created with FPM • Synced to S3, nodes configured with s3-apt plugin • Mount + format ephemerals on boot • Ext4 / nodiratime / nodealloc / lazy_itable_init
from 32k • Something a lot smaller. 8-16k • Placement groups for 10Gb networking • Increase DFSBandwidthPerSec • Kernel tuning for TCP • Compaction threads • Disk elevator to noop
writes • Allows for tuning a system before it goes live • Tuning • Schema • Hot spots • Compaction • Canary roll out to new users • 10% -> 30% -> 80% -> 100%
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
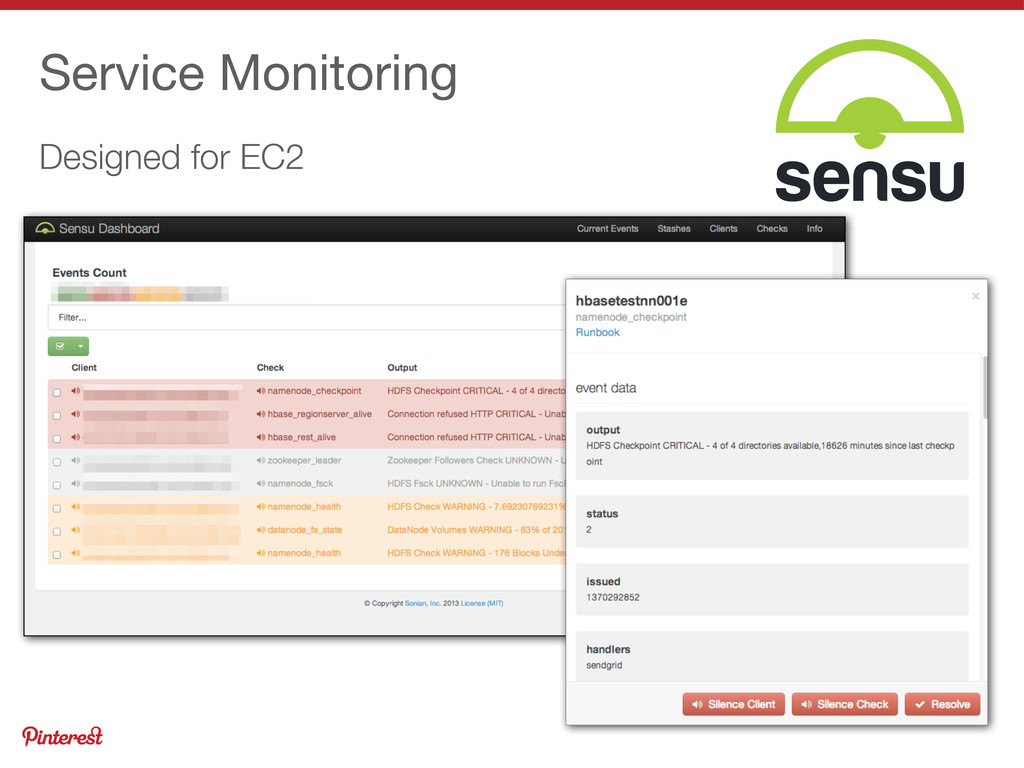{kind=link}
{kind=link}
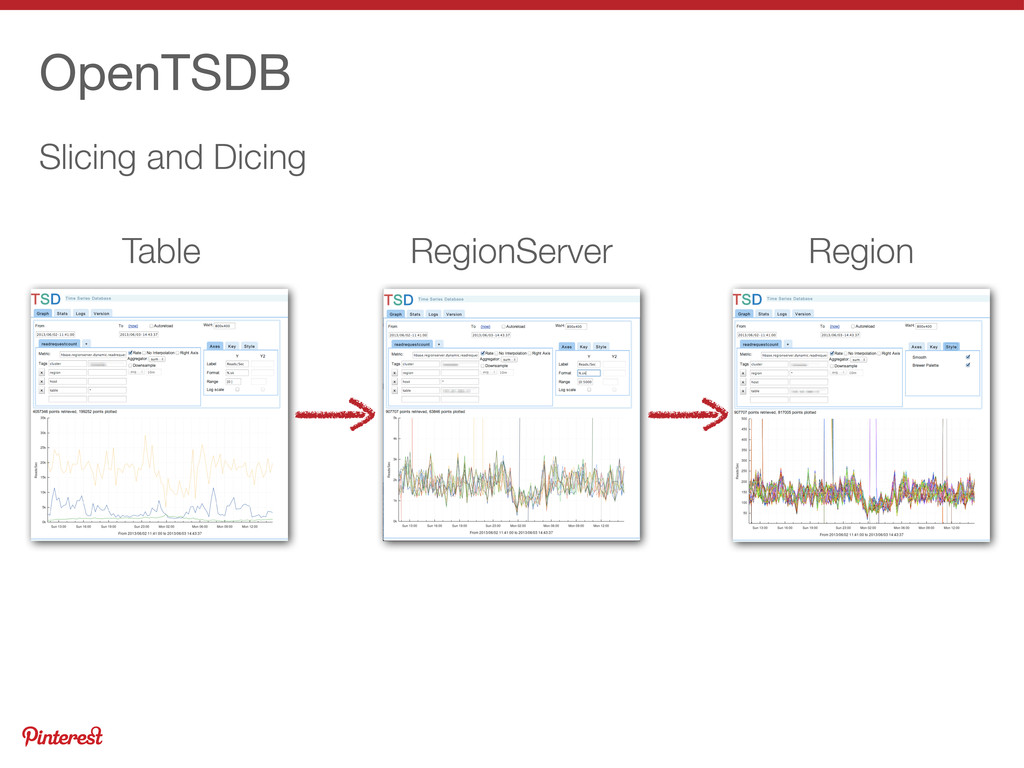{kind=link}
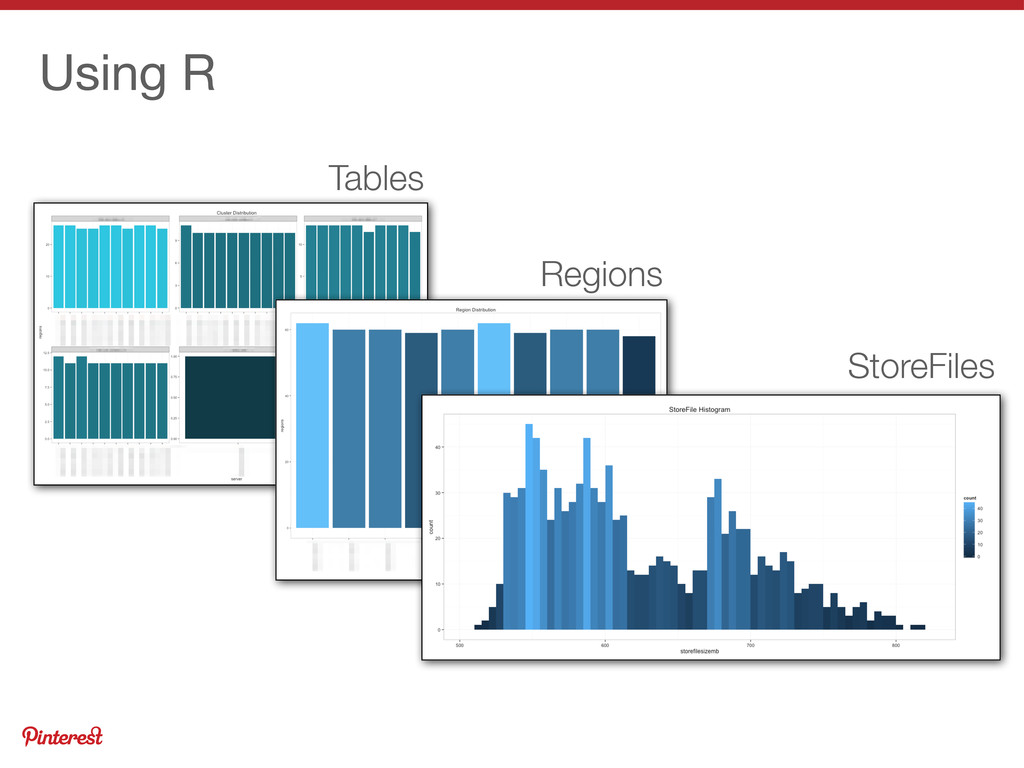{kind=link}
{kind=link}
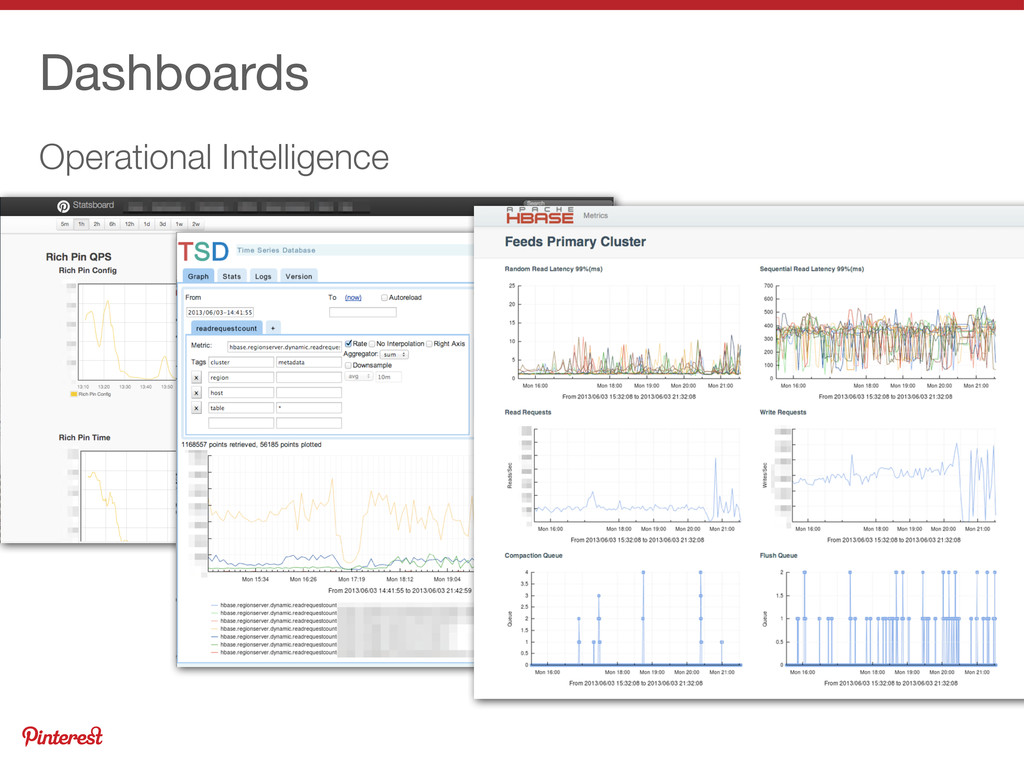{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}