(computing): is any sequence of symbols given meaning by specific acts of interpretation. Dutch: data is the plural of datum, which is an observation of a fact
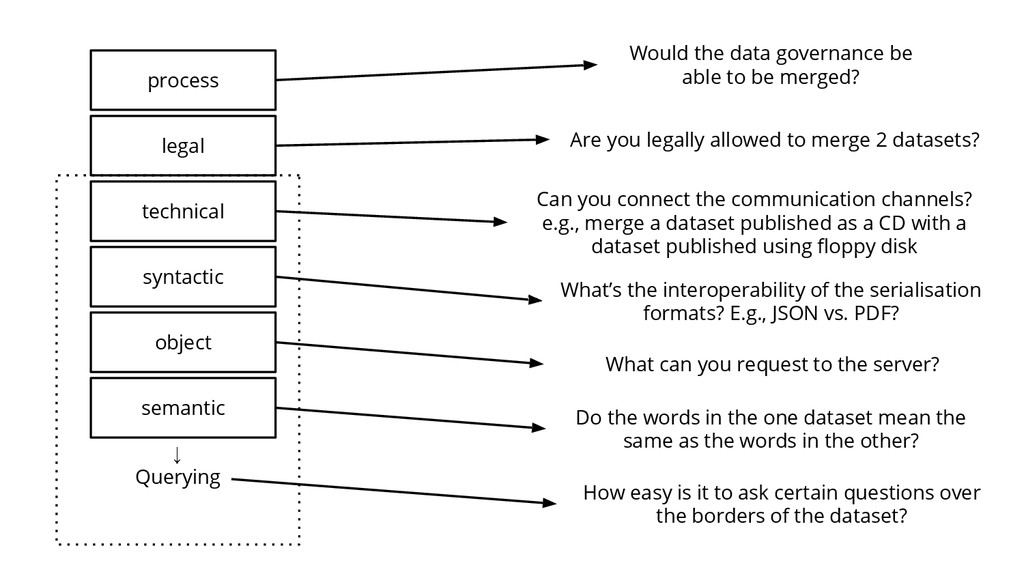
data governance be able to be merged? Are you legally allowed to merge 2 datasets? Can you connect the communication channels? e.g., merge a dataset published as a CD with a dataset published using floppy disk How easy is it to ask certain questions over the borders of the dataset? What’s the interoperability of the serialisation formats? E.g., JSON vs. PDF? What can you request to the server? Do the words in the one dataset mean the same as the words in the other?
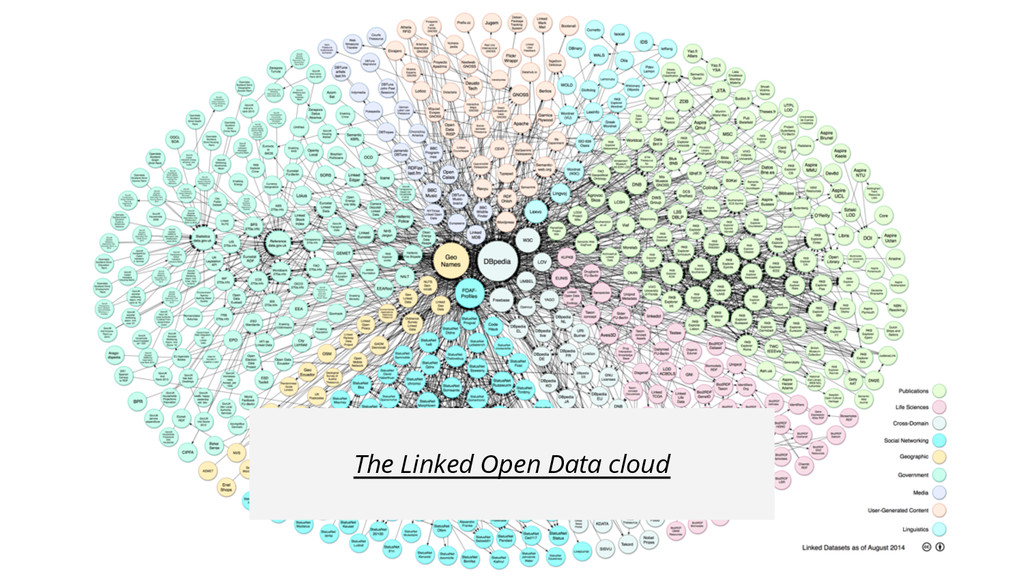
open data portals http://data.gov.uk, http://datahub.io, http://open-data.europa.eu, http://data.gent.be, … Via links in existing datasets e.g., http://dbpedia.org/resource/Ghent
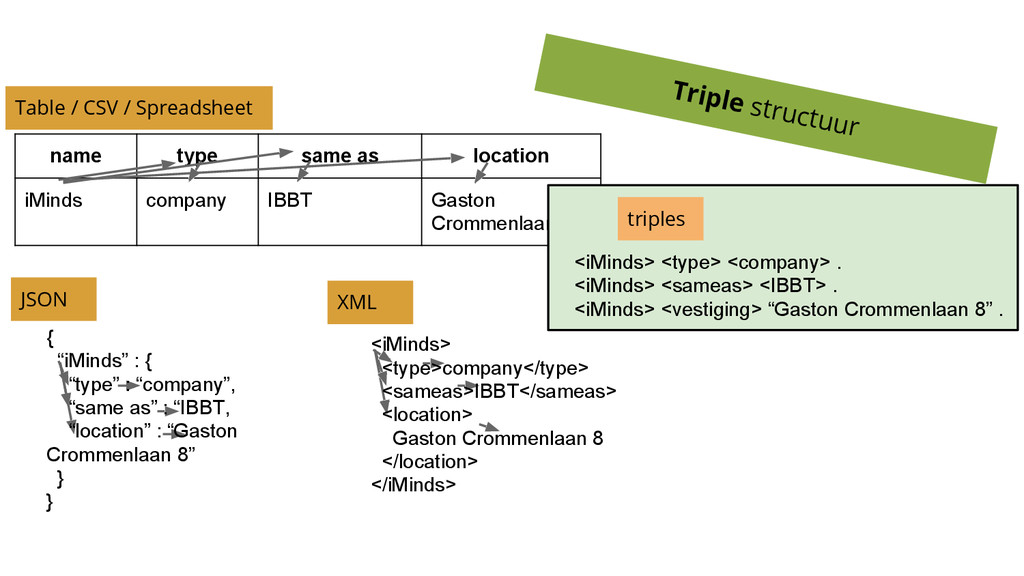
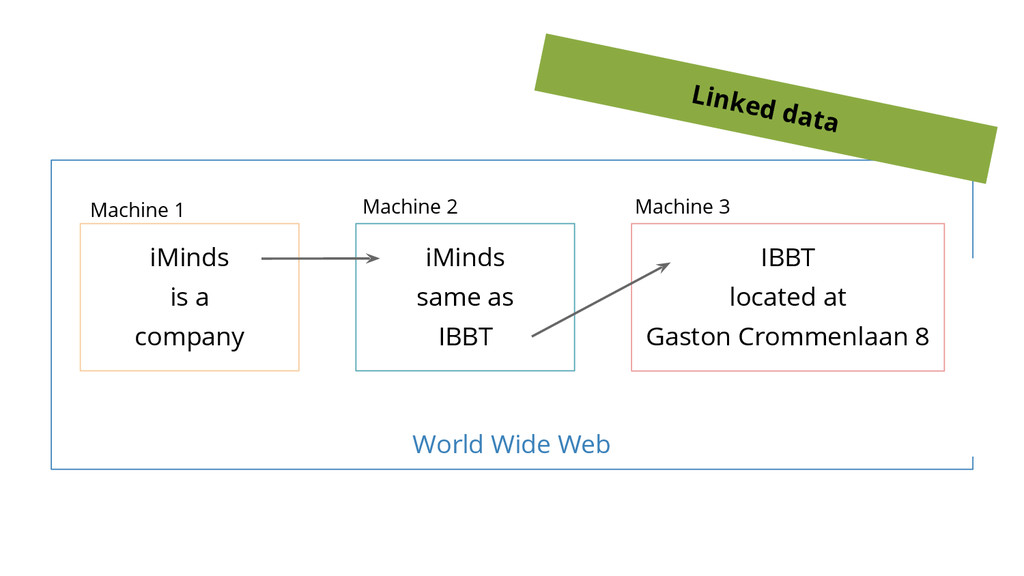
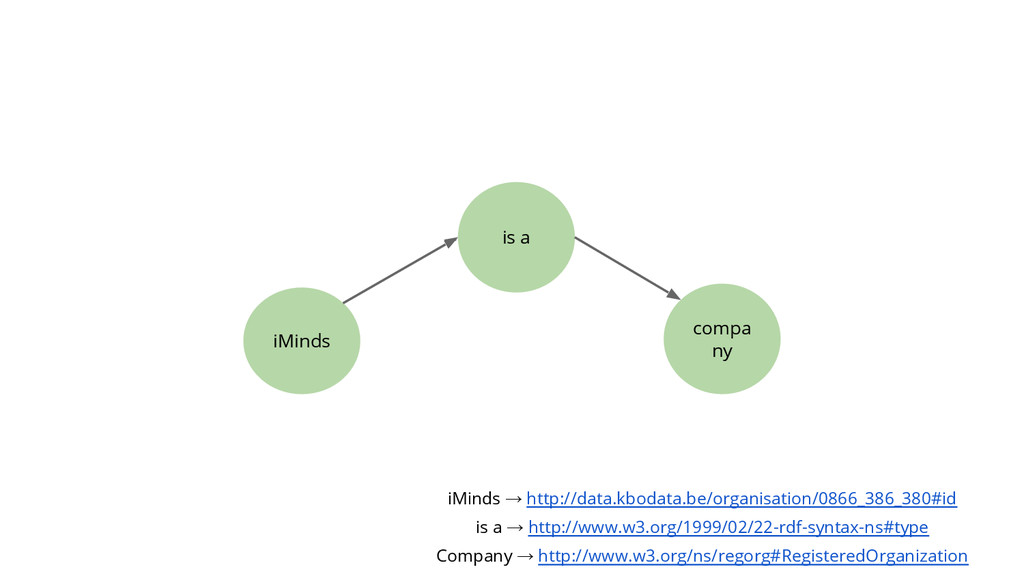
http://www.w3.org/ns/regorg#RegisteredOrganization Uniform Resource Identifiers (URI’s) een triple = is an atomary piece of data (a datum or a fact) that cannot be misunderstood on machine-level in a Web context
linked open data cloud Linked Open Data means: making your data more interoperable with other datasets on the web by using URIs as identifiers and triples as atomary building blocks
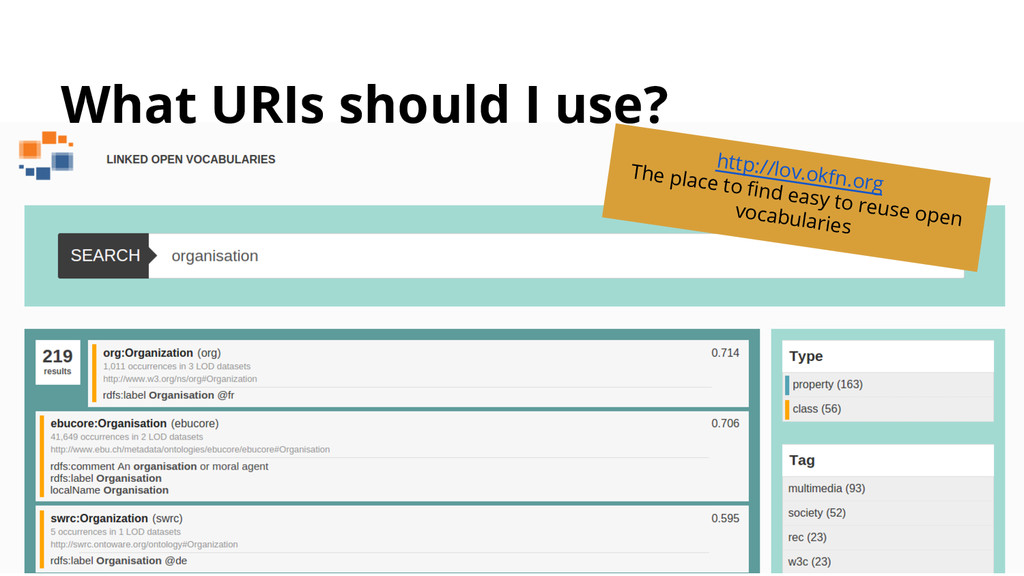
2. Use HTTP URIs so that people can look up those names 3. When looking up URIs, provide useful information 4. Include links to other URIs for discoverability Only important if you’re defining new URIs Not important if you’re publishing facts by reusing identifiers
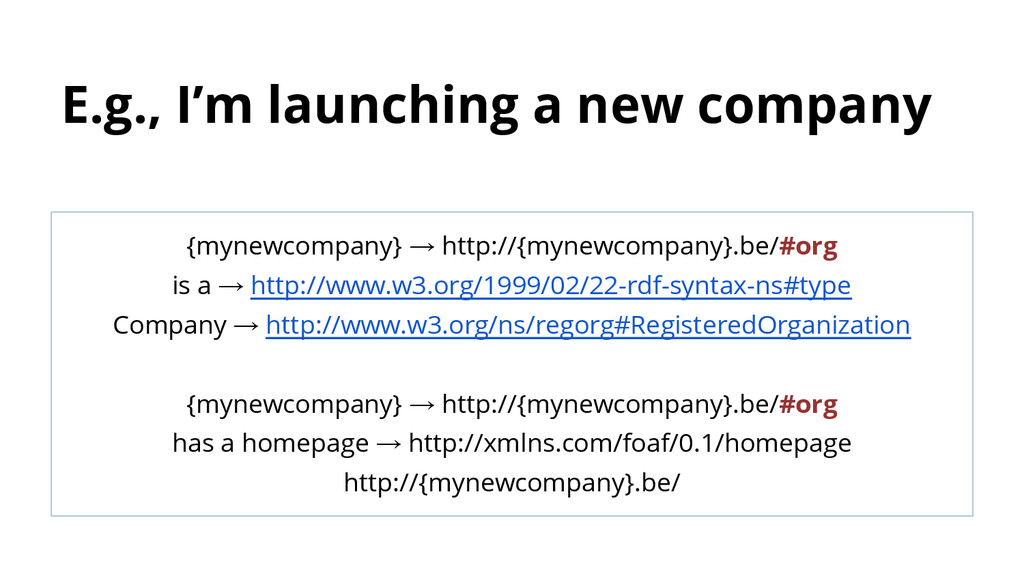
a → http://www.w3.org/1999/02/22-rdf-syntax-ns#type Company → http://www.w3.org/ns/regorg#RegisteredOrganization An identifier for your company. The semantics are controlled by you
a → http://www.w3.org/1999/02/22-rdf-syntax-ns#type Company → http://www.w3.org/ns/regorg#RegisteredOrganization {mynewcompany} → http://{mynewcompany}.be/#org has a homepage → http://xmlns.com/foaf/0.1/homepage http://{mynewcompany}.be/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}