We all agree that “clean code” is important — yet the moment we try to define it, opinions both converge and diverge: readable, maintainable, tested, robust, flexible… all these words hide very different meanings depending on the team and the context.
At the same time, we often notice that iteration after iteration, development speed tends to slow down. Maintaining a steady pace or estimating reliably becomes a constant struggle, even with good quality metrics and established best practices in place.
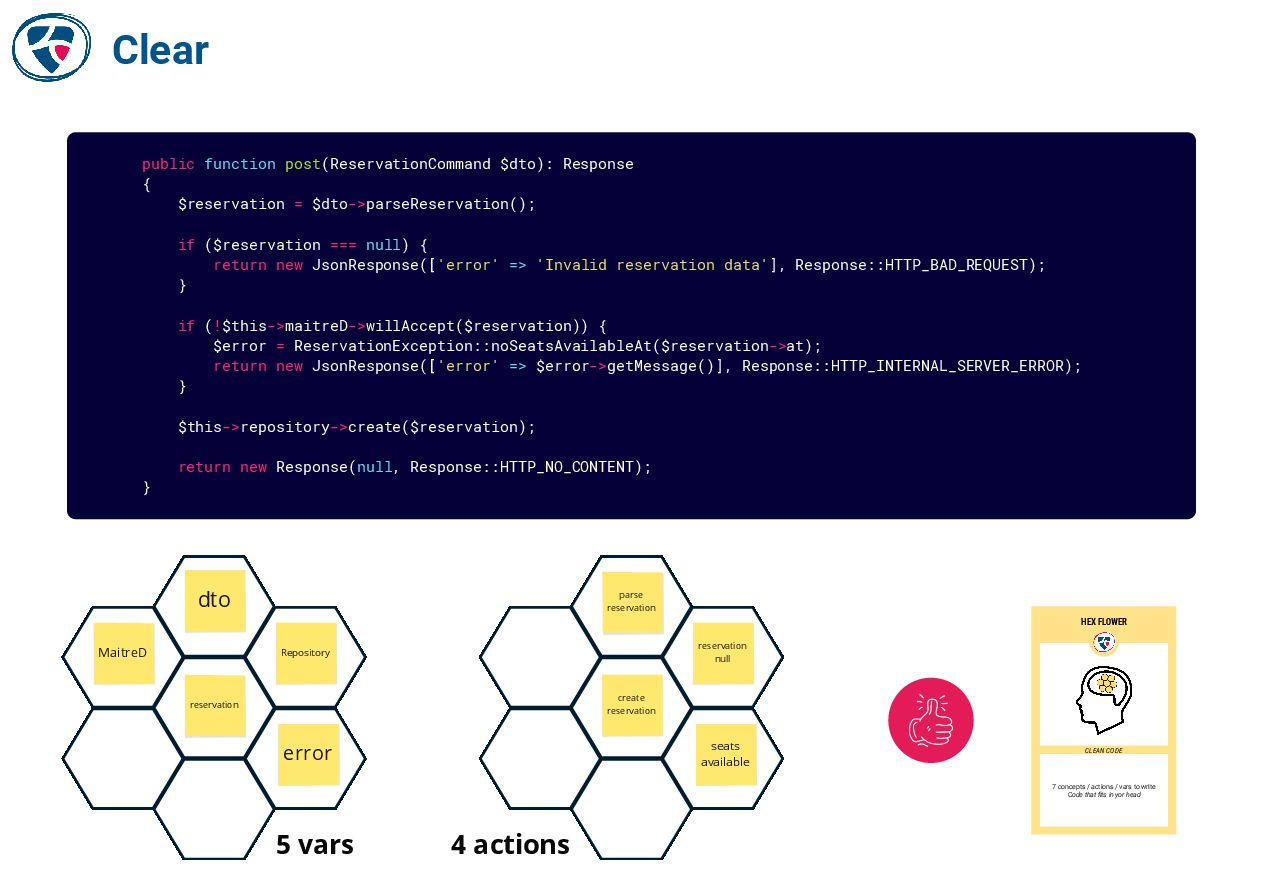
What if part of the problem didn’t come from a lack of technical skill or knowledge, but rather from a misunderstanding of our own cognitive limits?
In this talk, we’ll explore how cognitive science sheds light on the way we read, understand, and modify code. We’ll see how these insights can help us move beyond sterile debates about “quality” versus “over-engineering” — to identify factual criteria, define simple heuristics, and build development habits that support long-term collective understanding. Ultimately, we’ll learn how to write — and evolve — code that fits in our heads.
Sources :
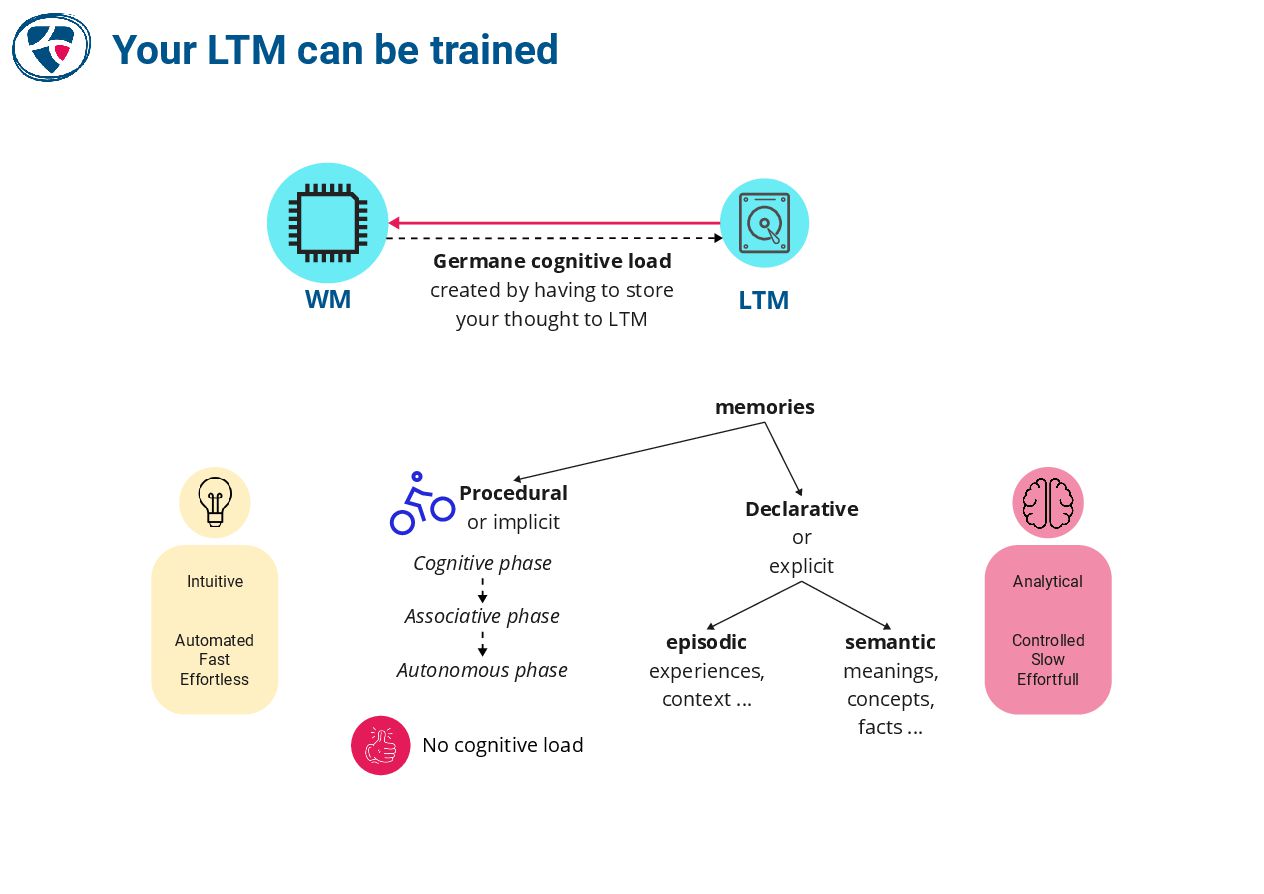
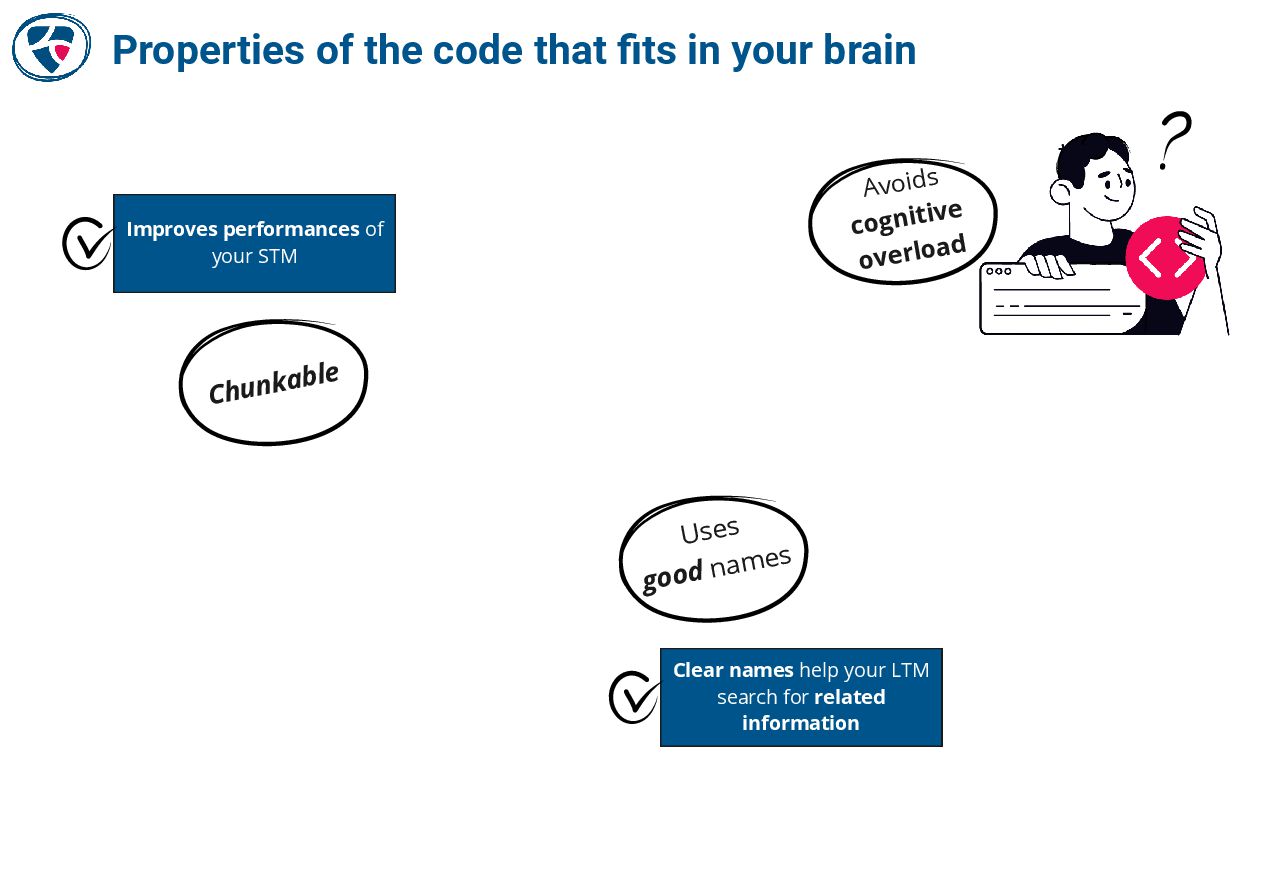
📚 The Programmer's Brain by Felienne Hermans :
https://www.felienne.com/book
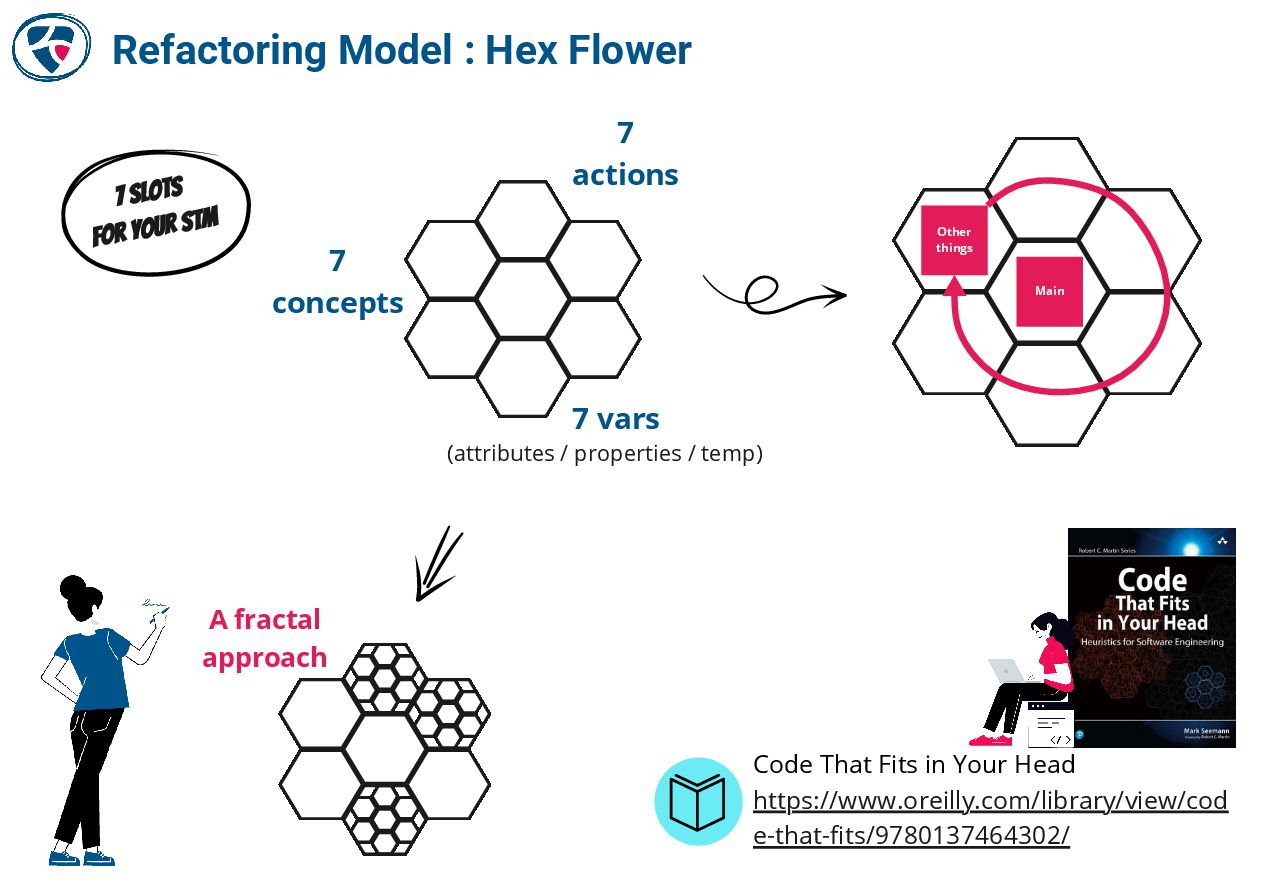
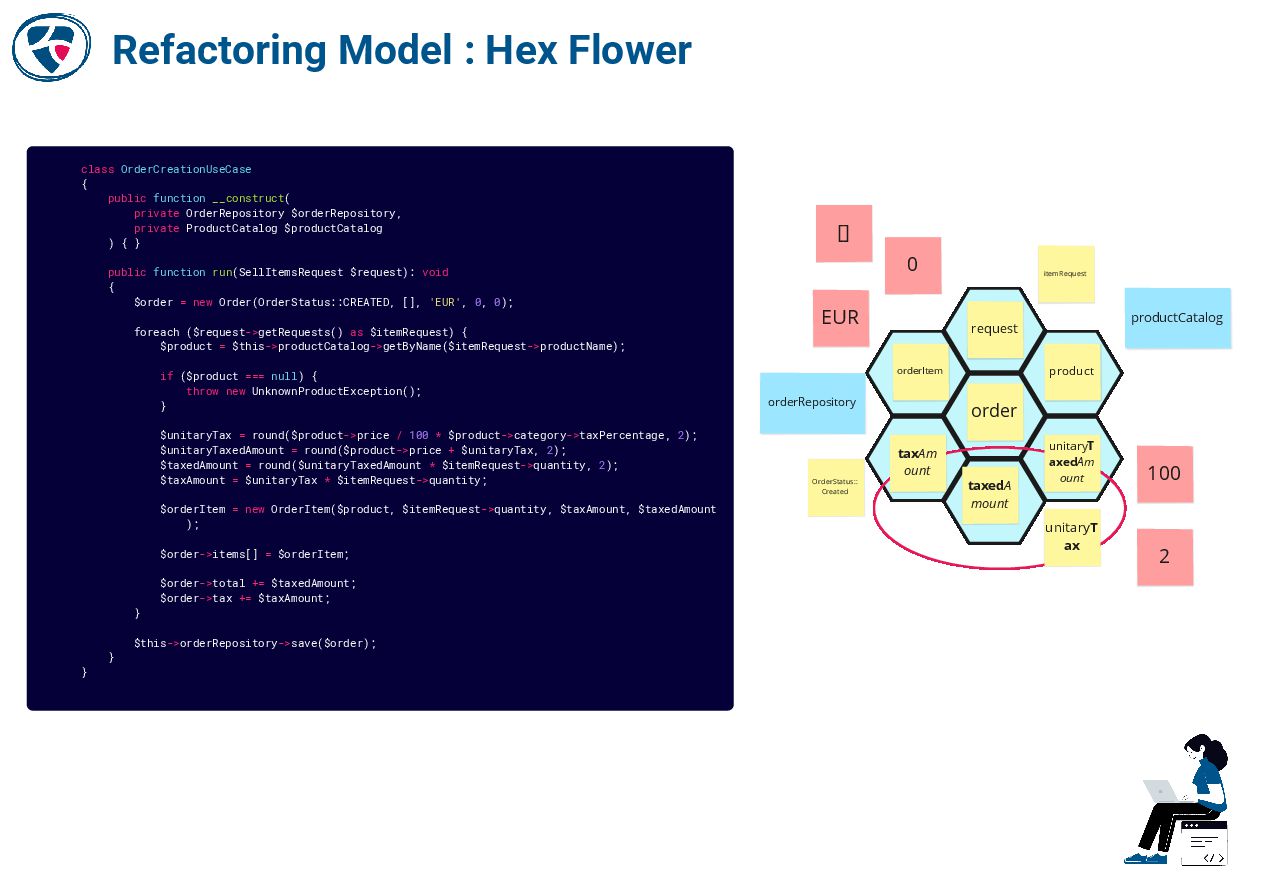
📚 Code That Fits in Your Head by Mark Seemann
https://blog.ploeh.dk/2021/06/14/new-book-code-that-fits-in-your-head/
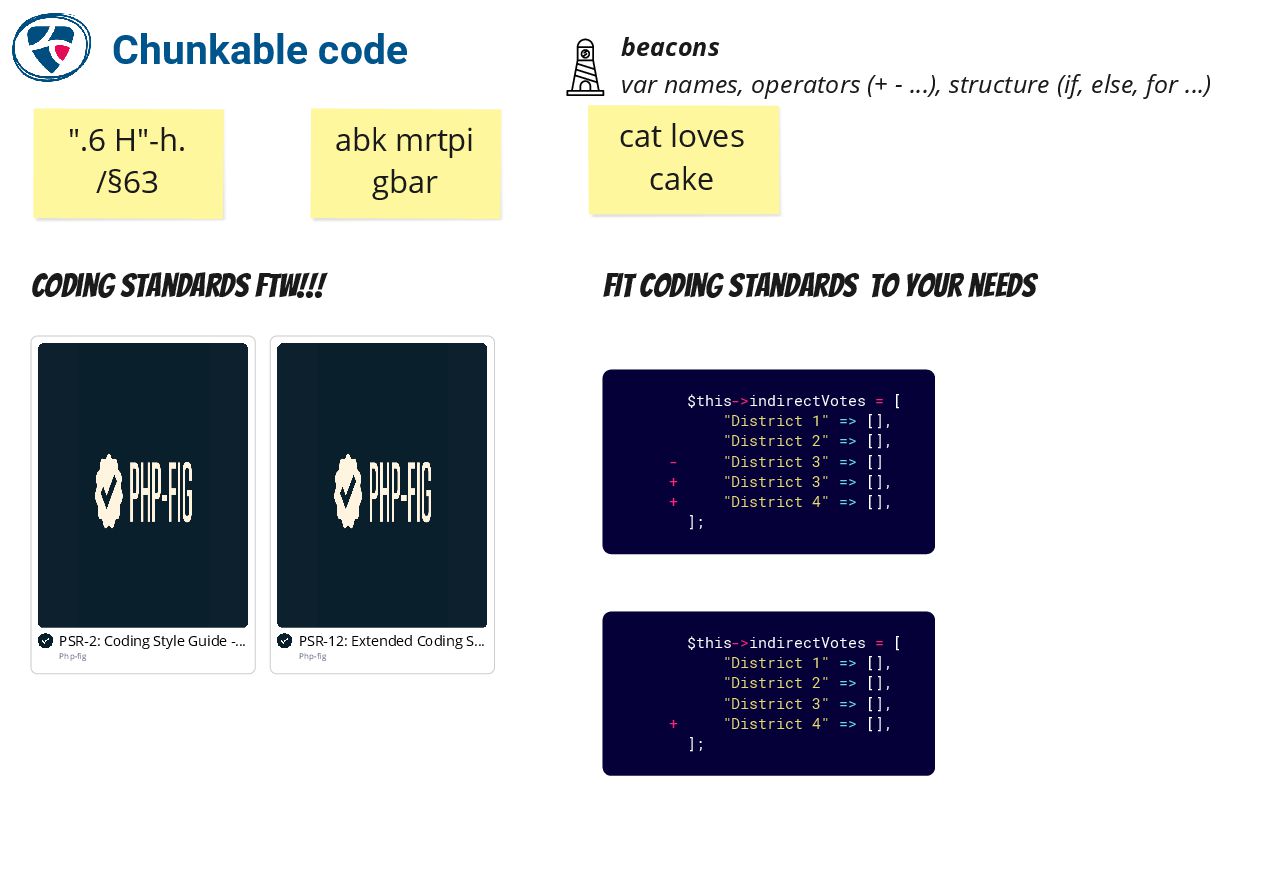
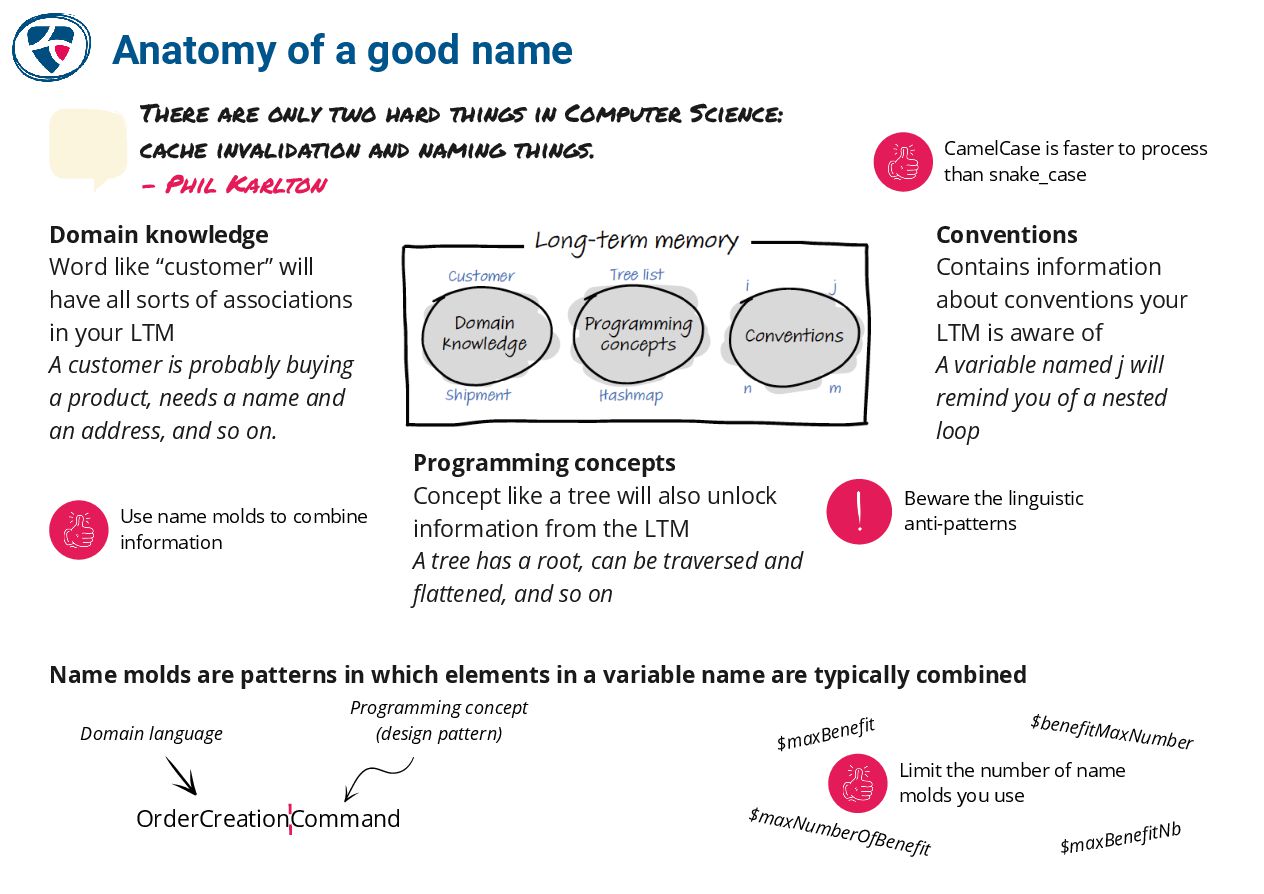
🔗 Arnaoudova's Linguistic Antipatterns
https://www.linguistic-antipatterns.com/
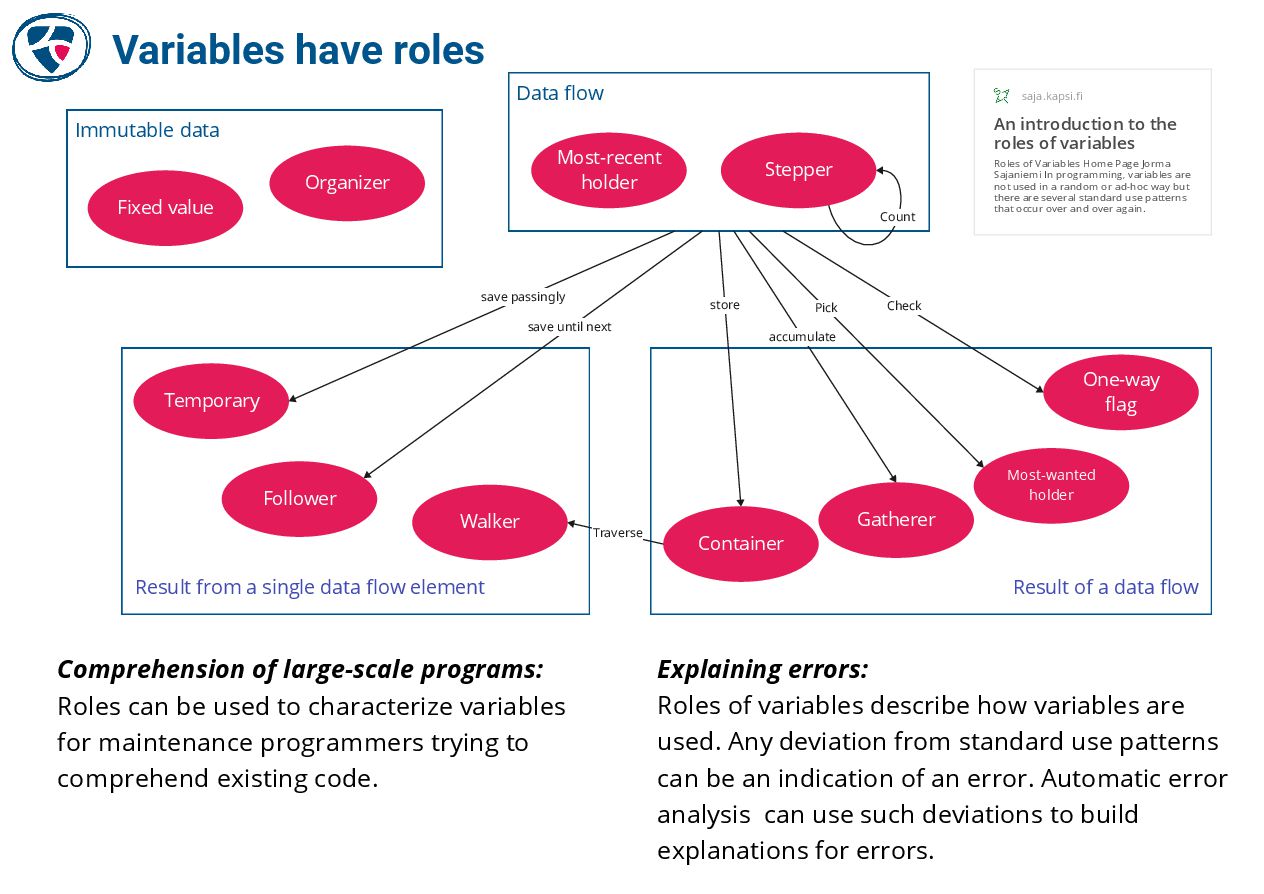
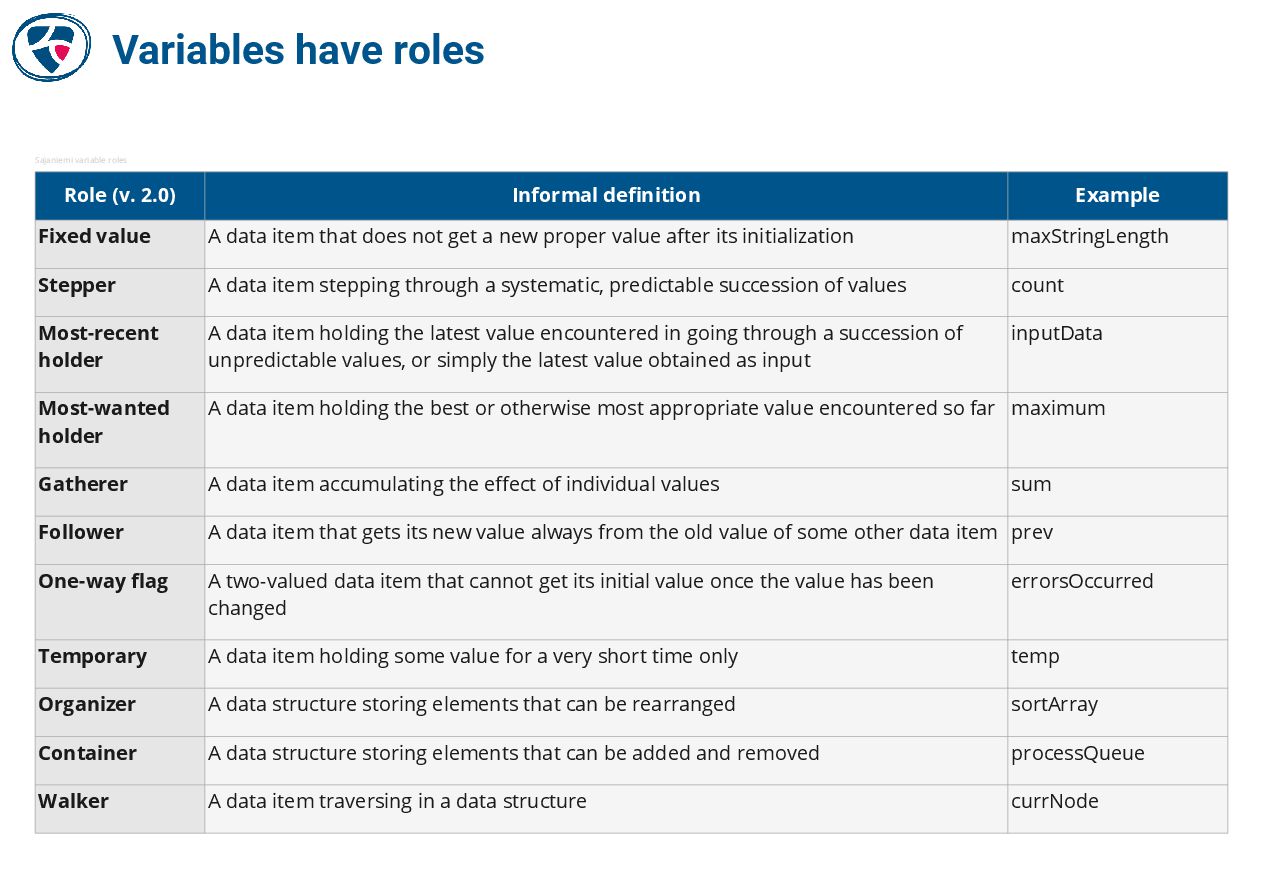
🔗 The Roles of Variables by Jorma Sajaniemi
https://saja.kapsi.fi/var_roles/index.html
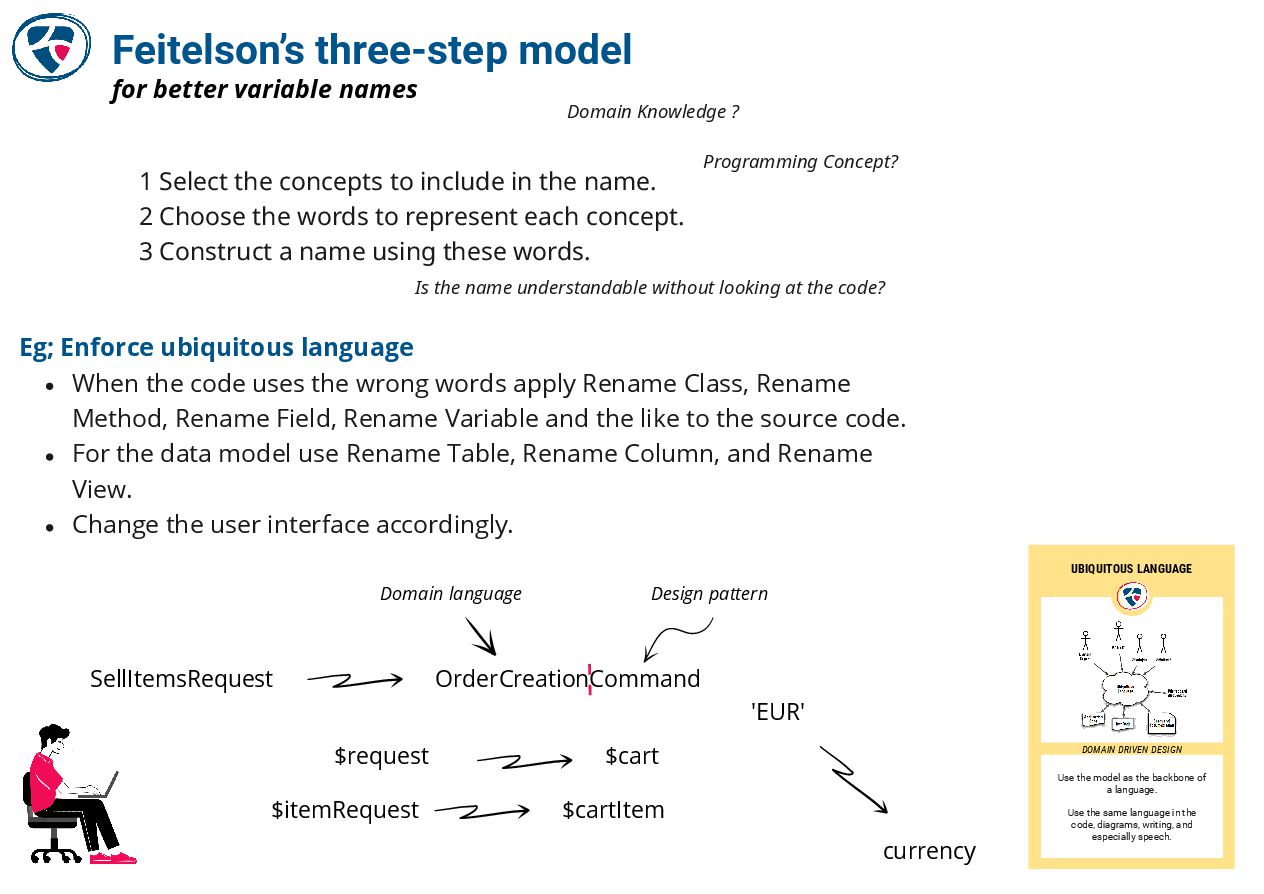
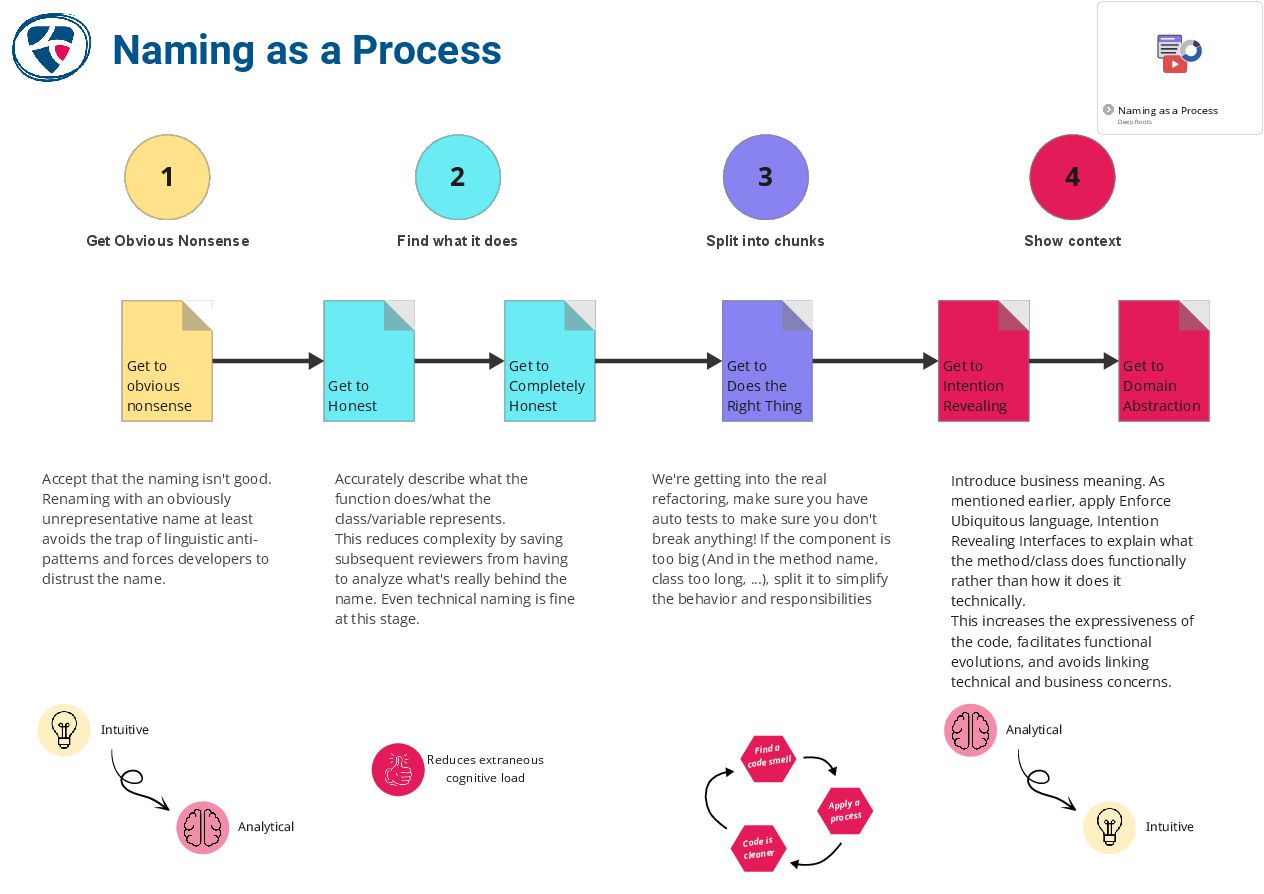
🔗 Naming as a process
https://www.digdeeproots.com/articles/naming-process/
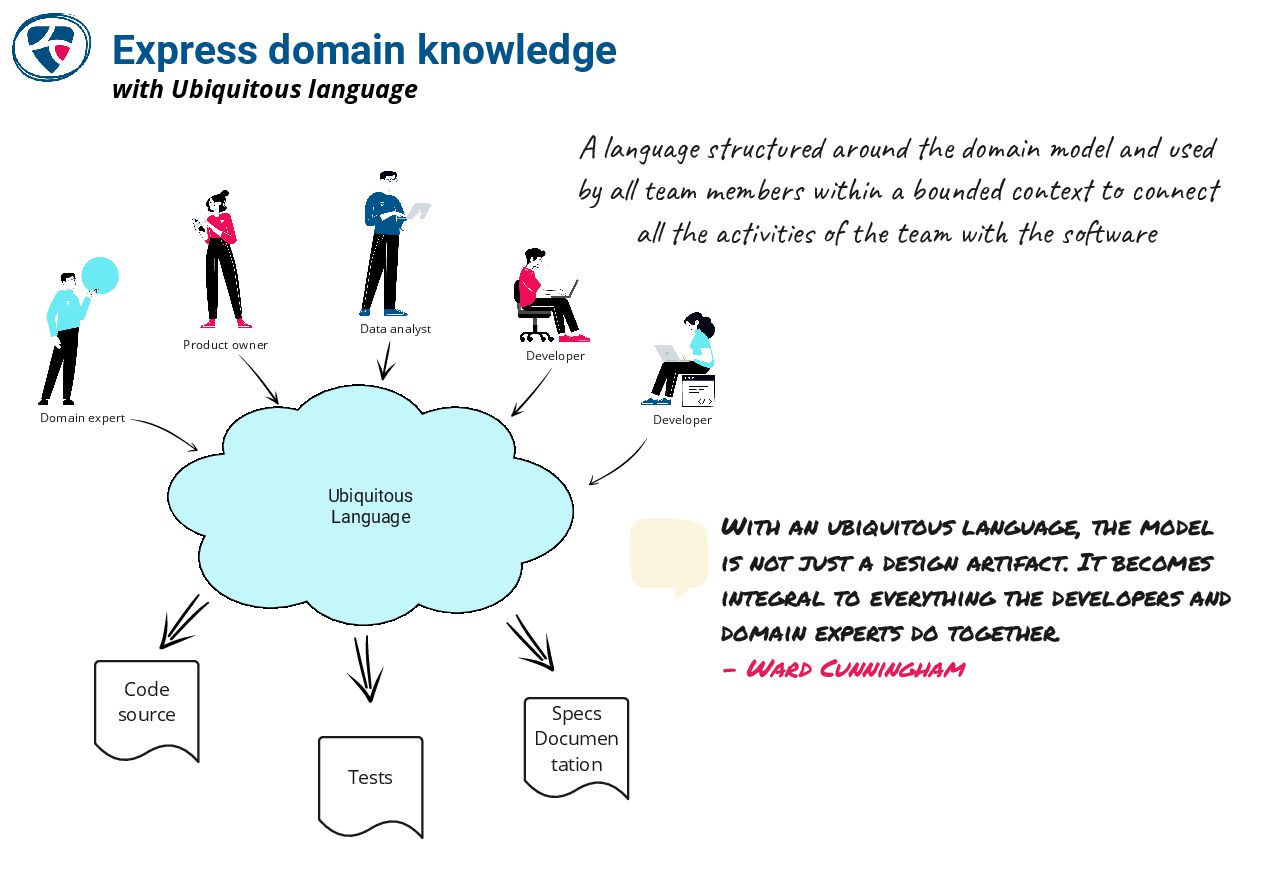
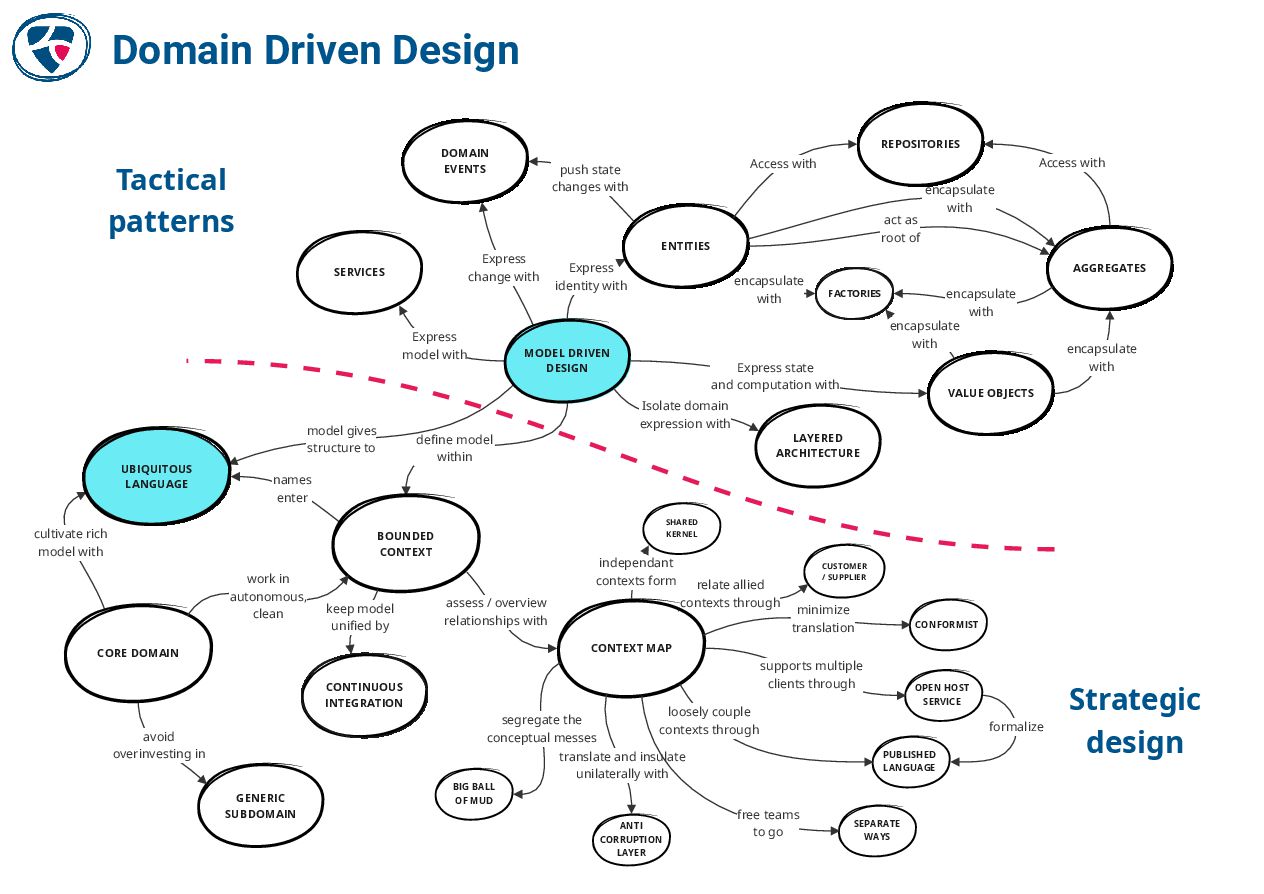
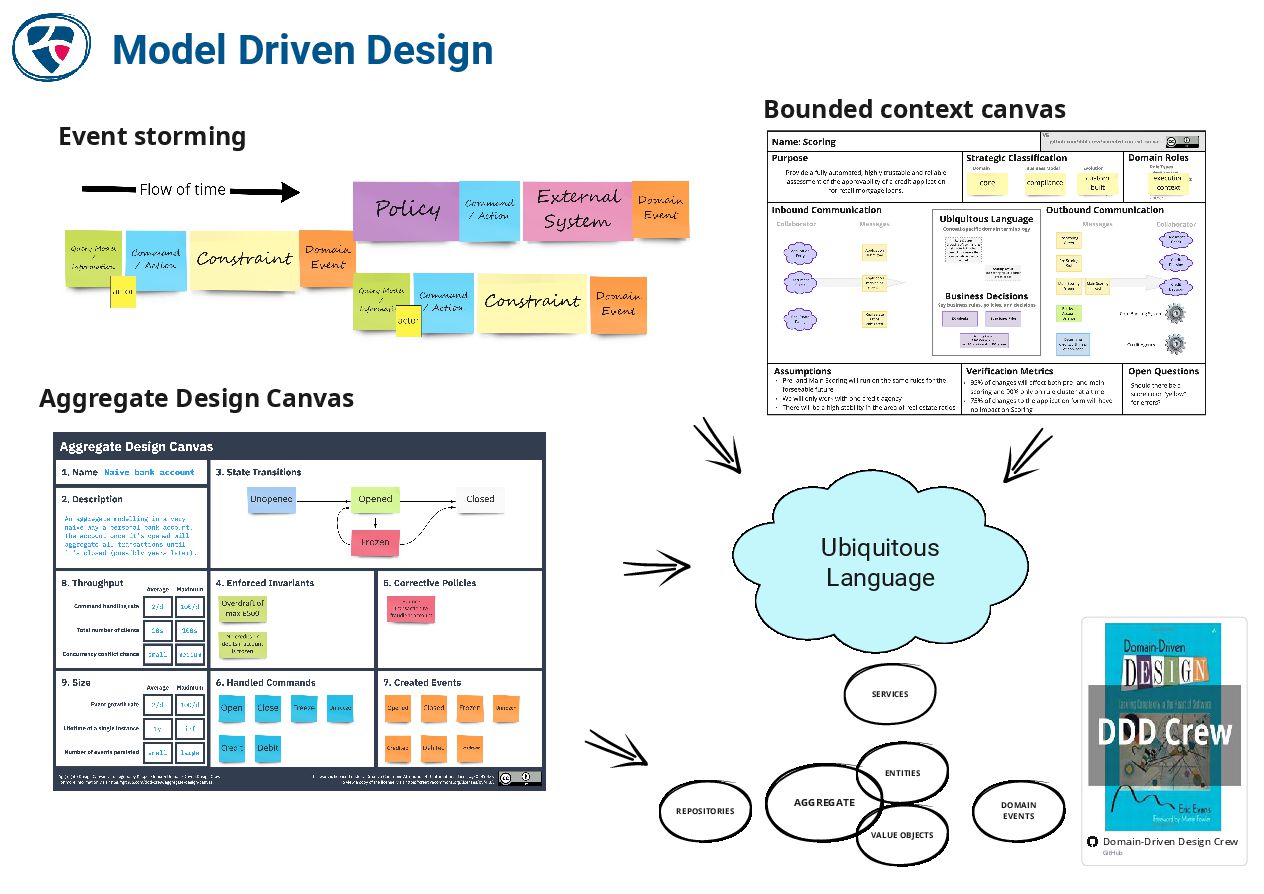
🔗 The DDD Crew
https://github.com/ddd-crew
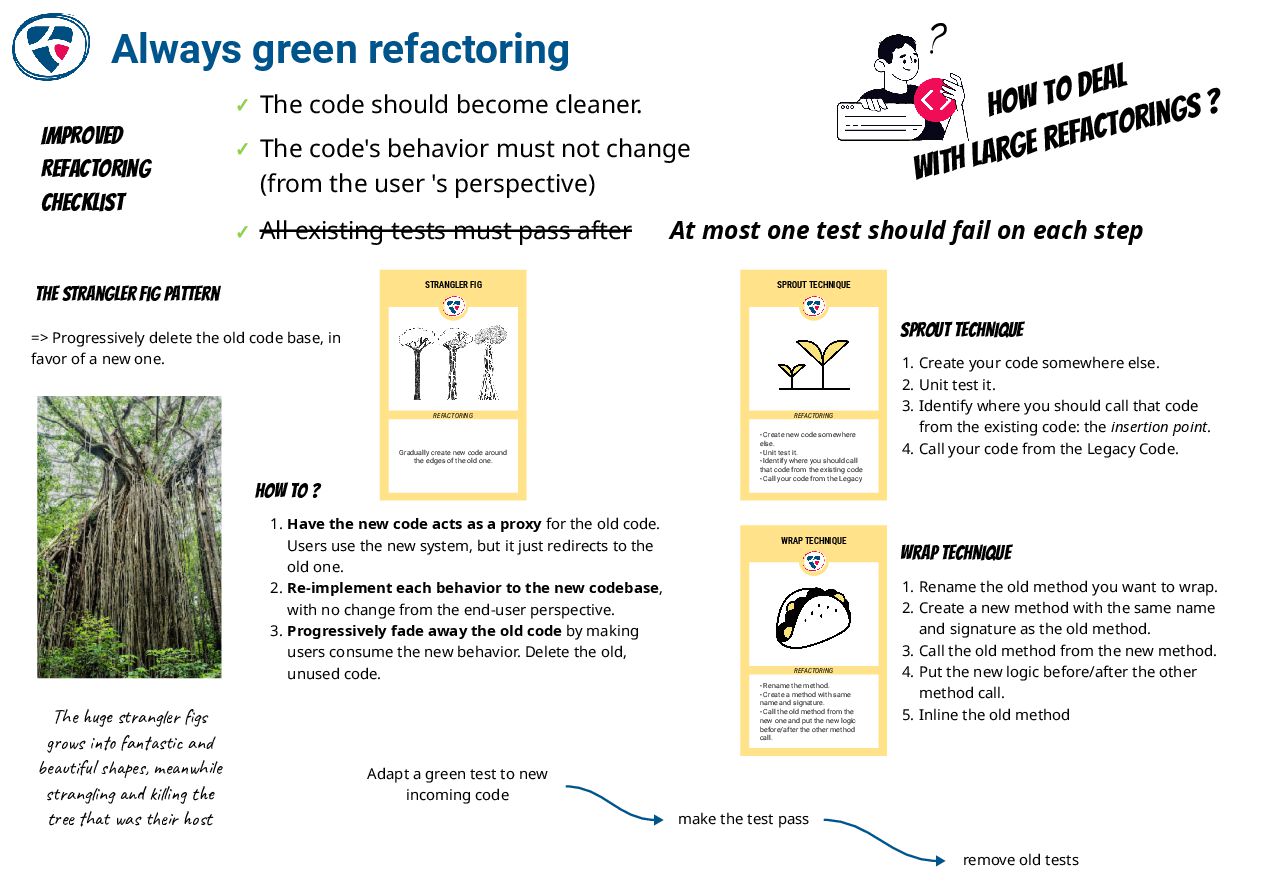
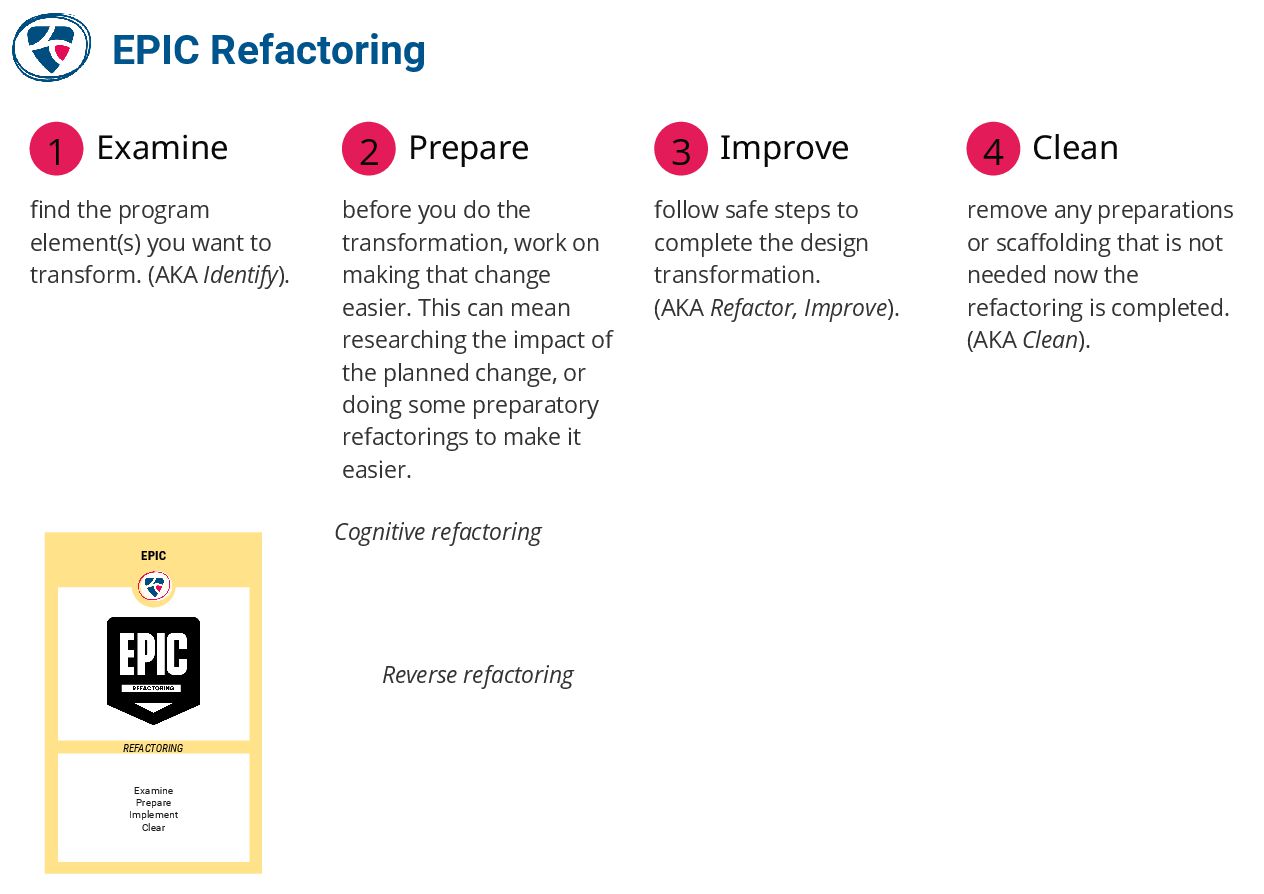
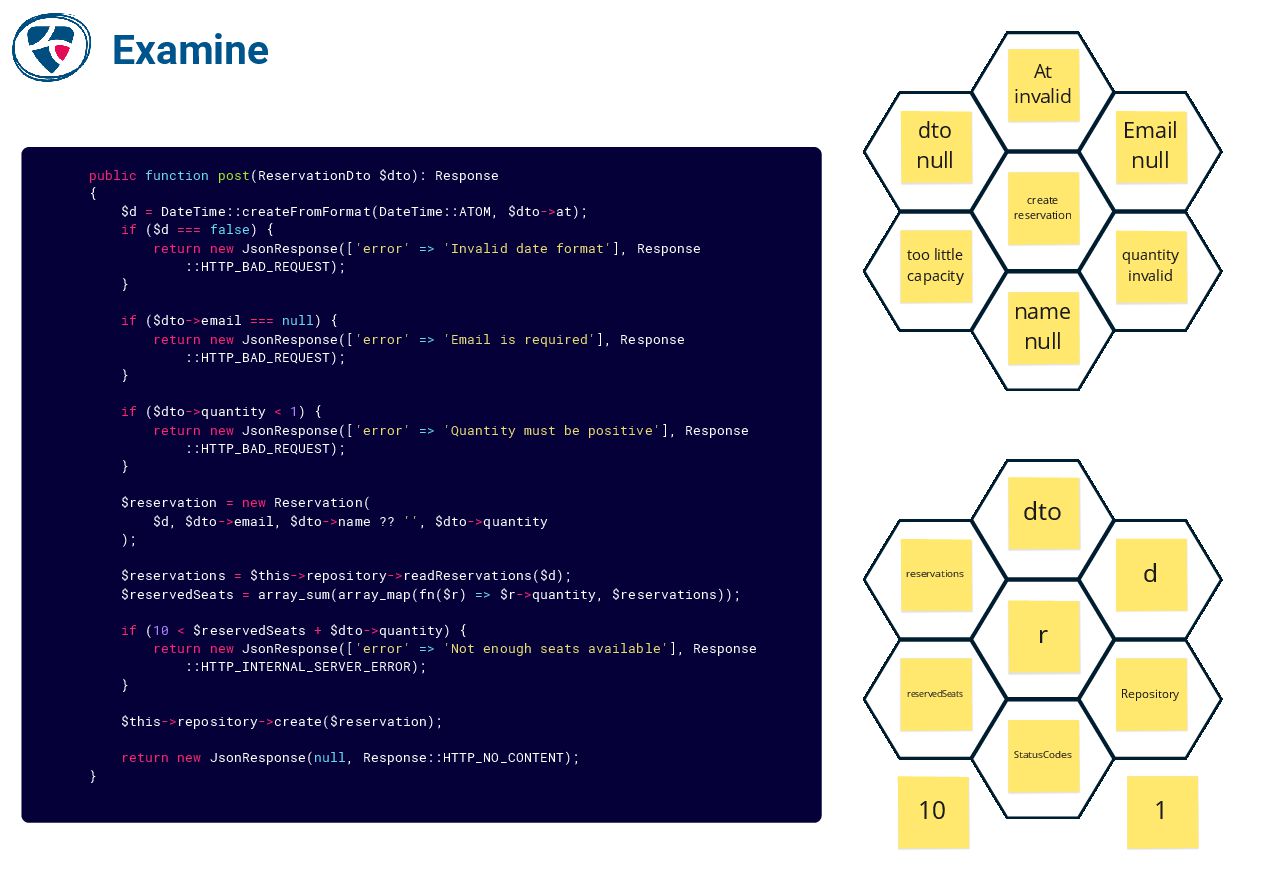
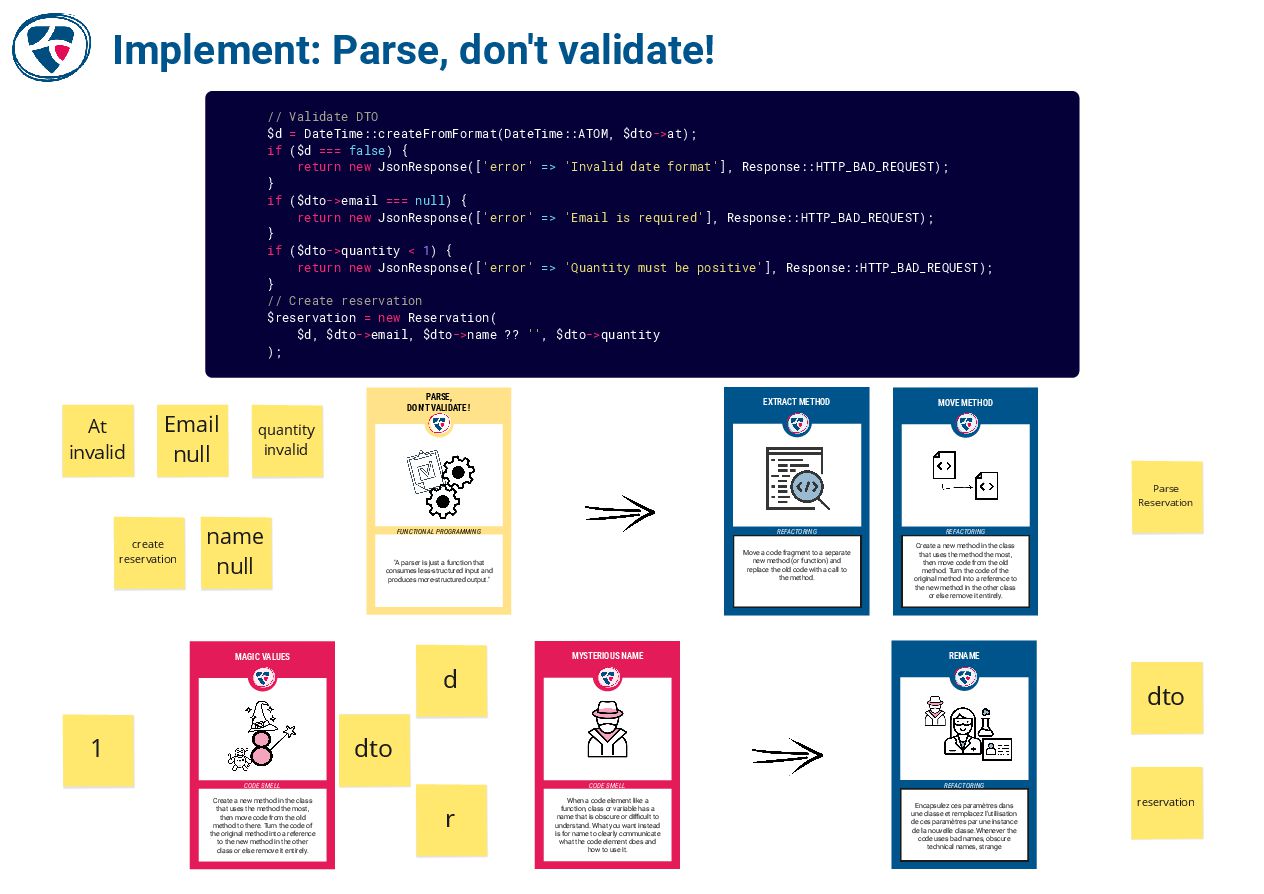
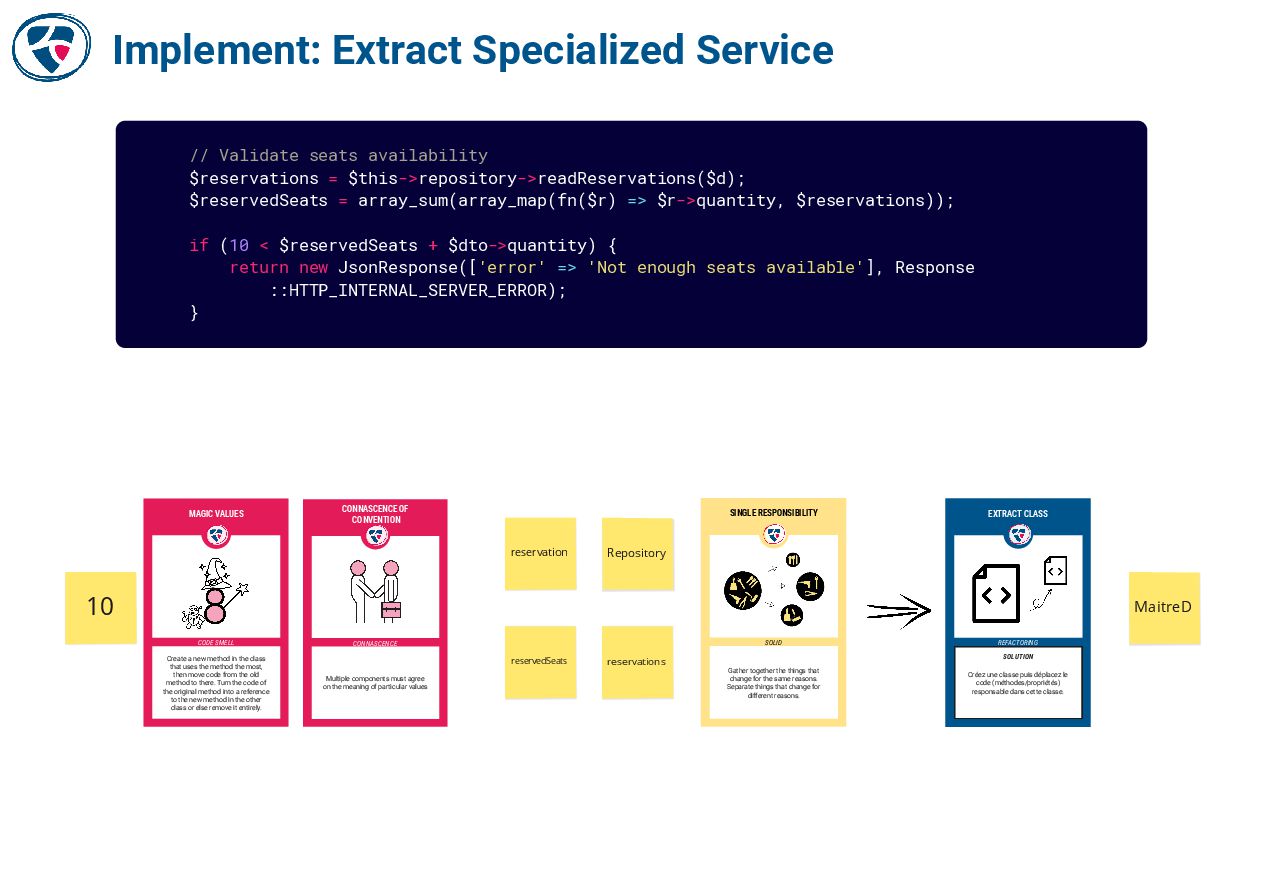
📺 EPIC refactoring by Bryan Beecham
https://agilealliance.org/resources/videos/epic-refactoring-applying-the-epic-continuous-improvement-cycle/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}