Proved to handle ephemeral compute ◦ Operated securely on public net (AWS) • Focused on composability & extensibility ◦ Reusable components / building blocks
& parallelism ◦ “Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.” — Rob Pike Data Processor 59
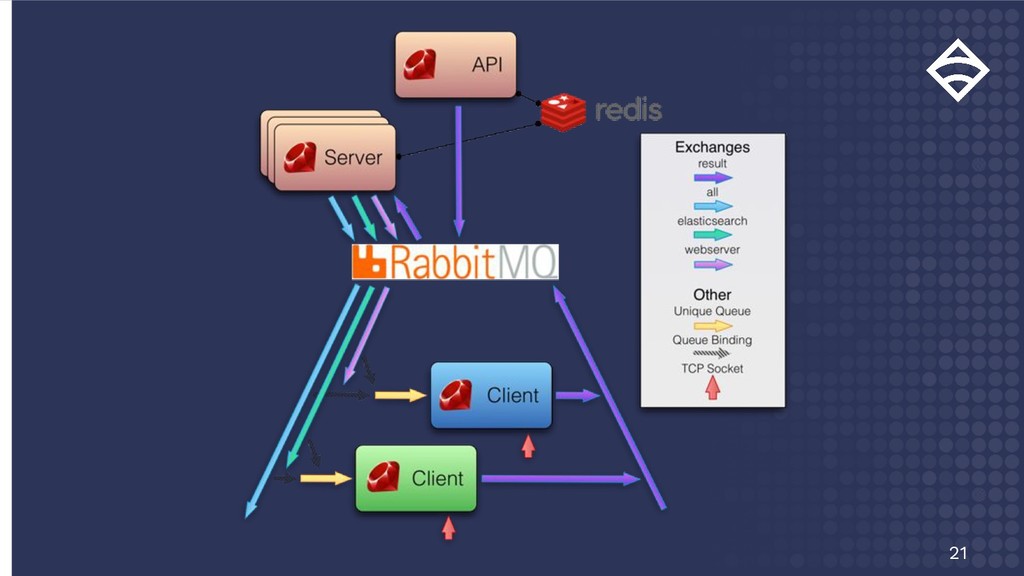
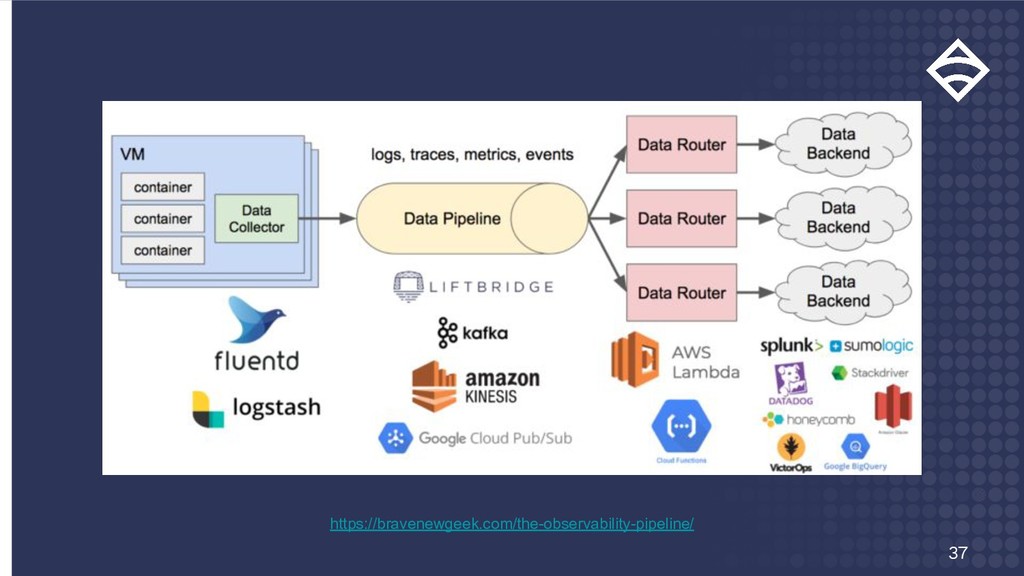
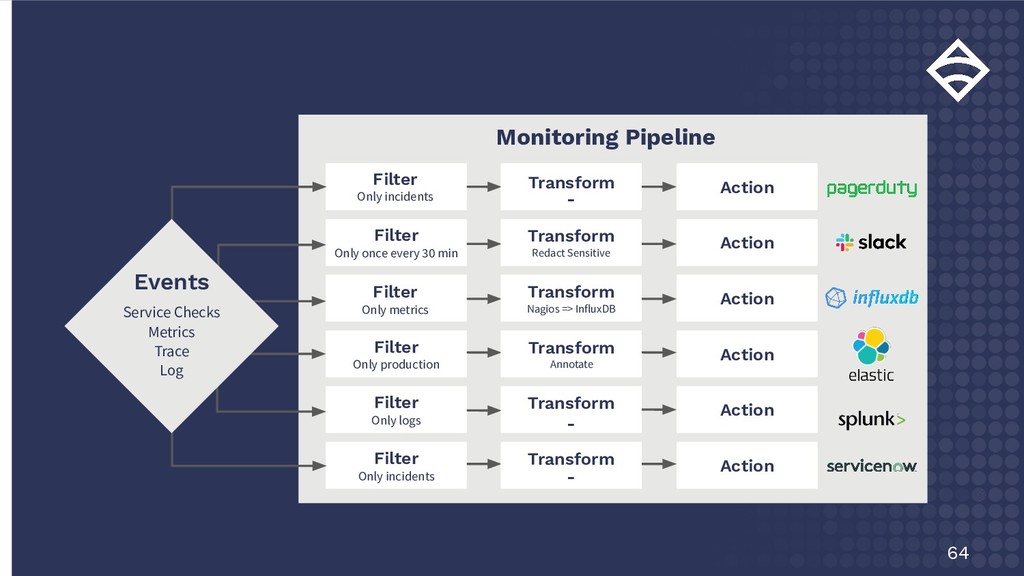
Only production Transform Transform - - Action Action Action Action Action Action Events Service Checks Metrics Trace Log Transform Redact Sensitive Transform Nagios => InfluxDB Filter Only once every 30 min Filter Only metrics Filter Only incidents Transform Annotate Transform -
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“We gotta find a way to make [this] fit into](https://files.speakerdeck.com/presentations/dd4ffaa1772e44b7b8bb9caa1e48fb9b/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
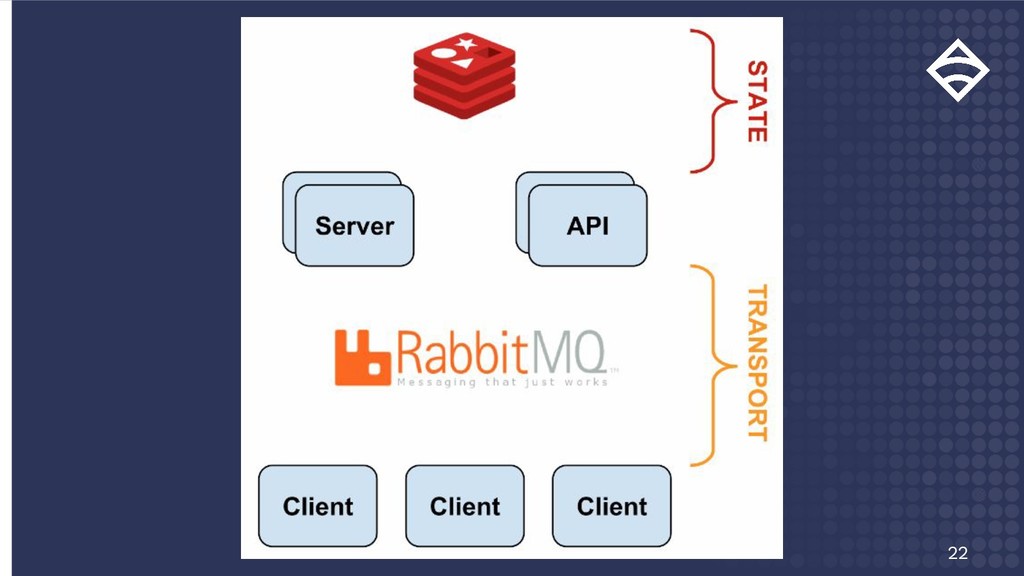{kind=link}
{kind=link}
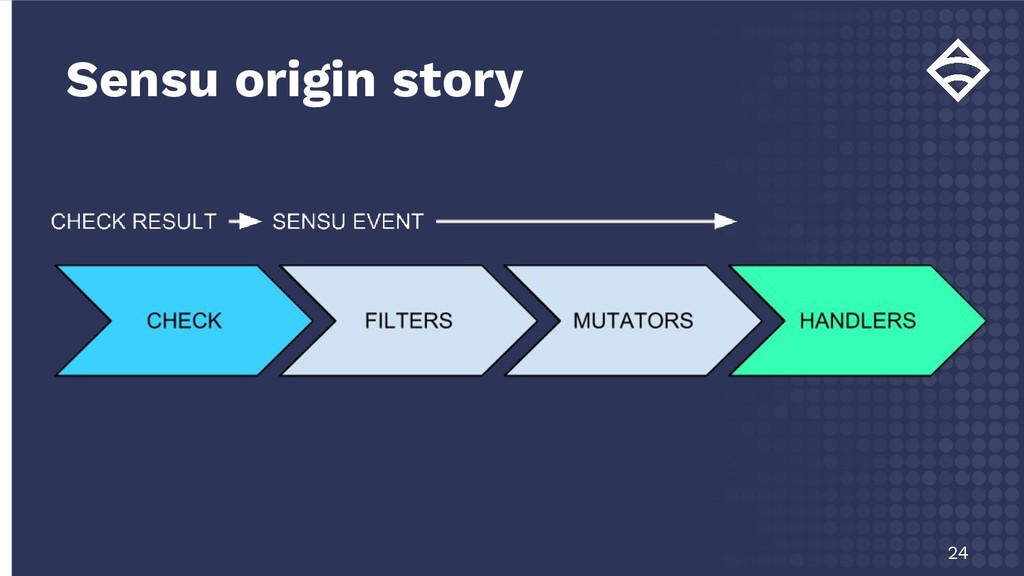{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}