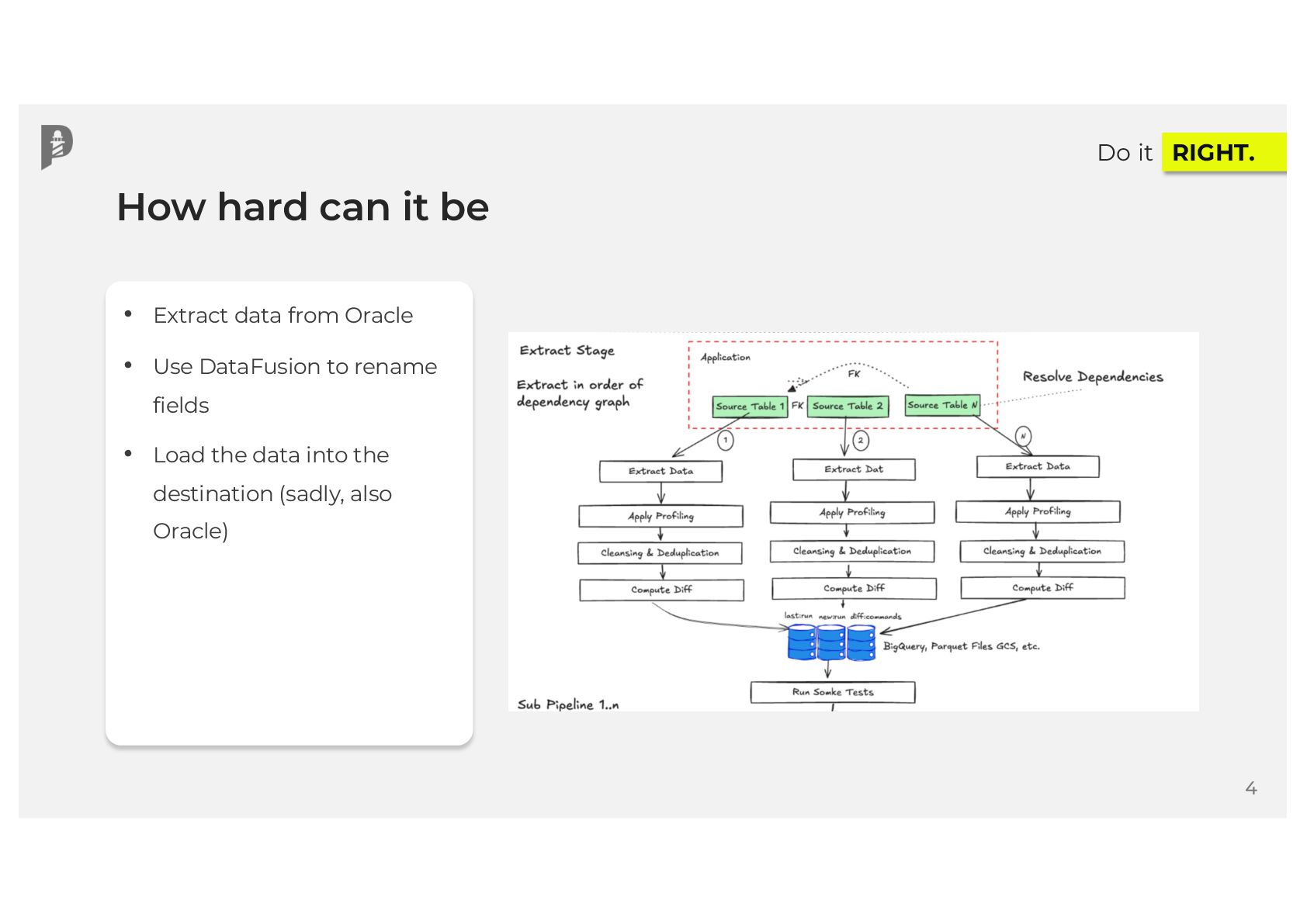
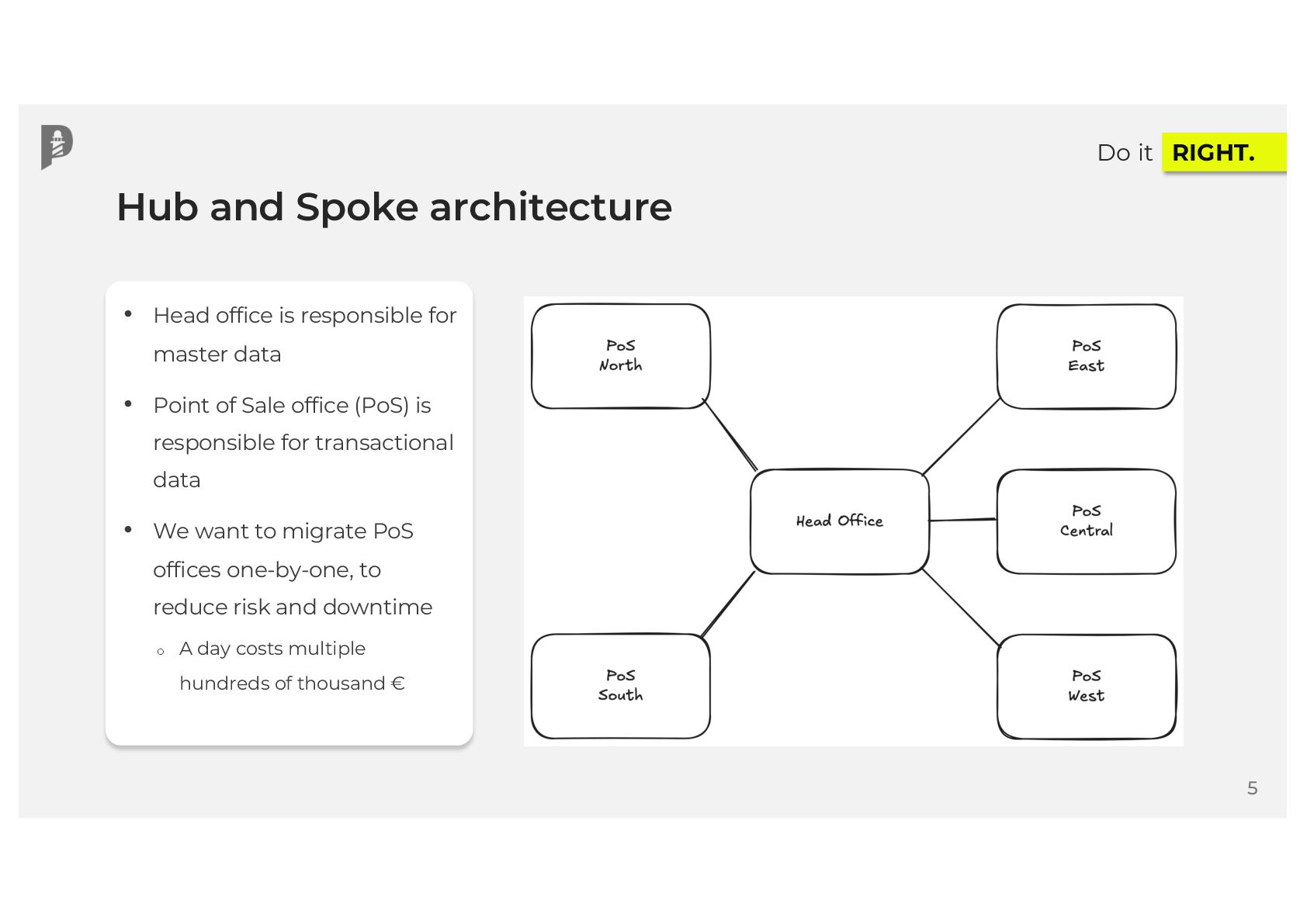
Join Damjan for a critical session on leveraging modern data platform tooling to achieve real-time bi-directional data synchronization. We'll move beyond theory to practical implementation, focusing specifically on how our platform addresses the challenges of two-way syncing between core enterprise systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}