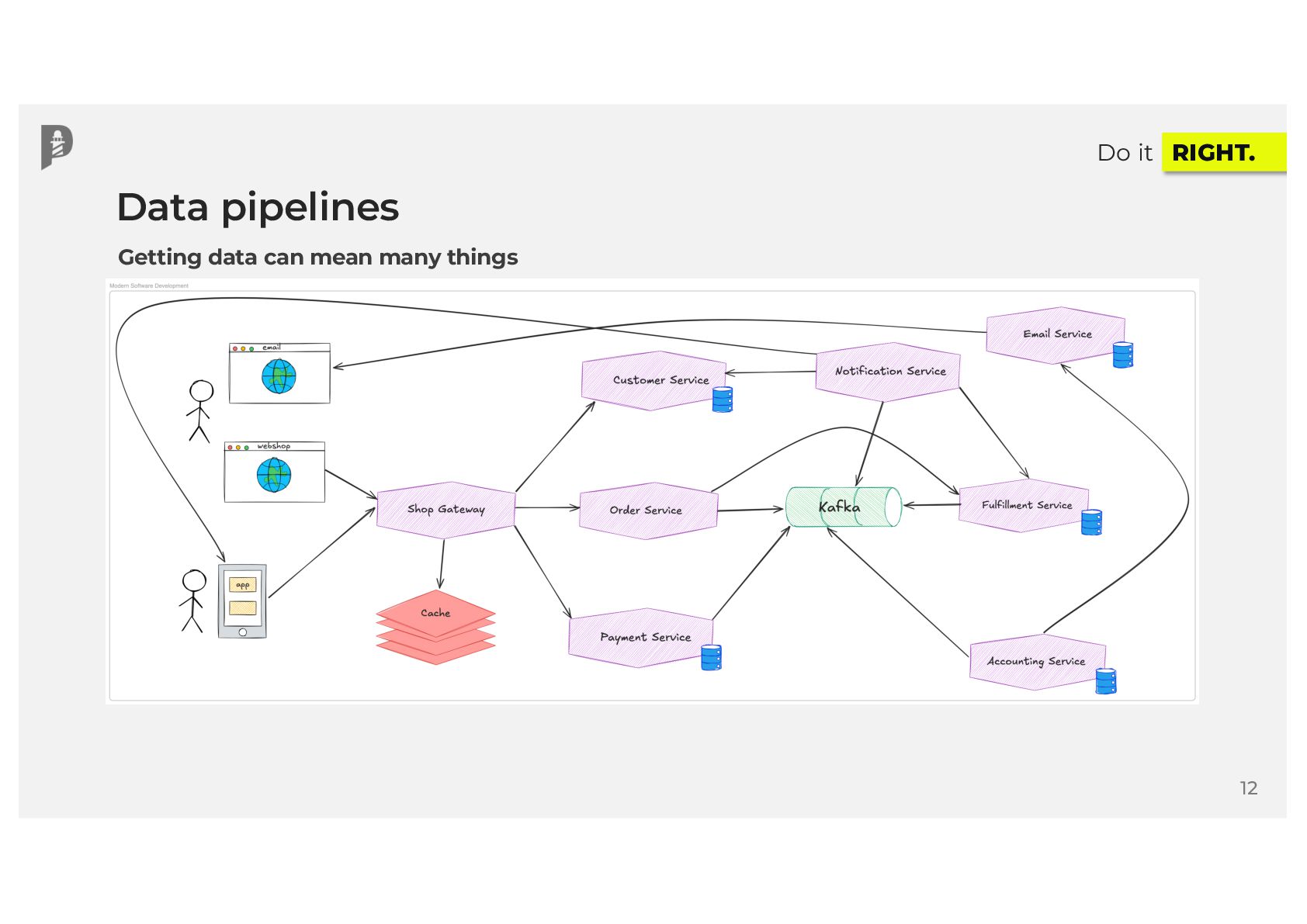
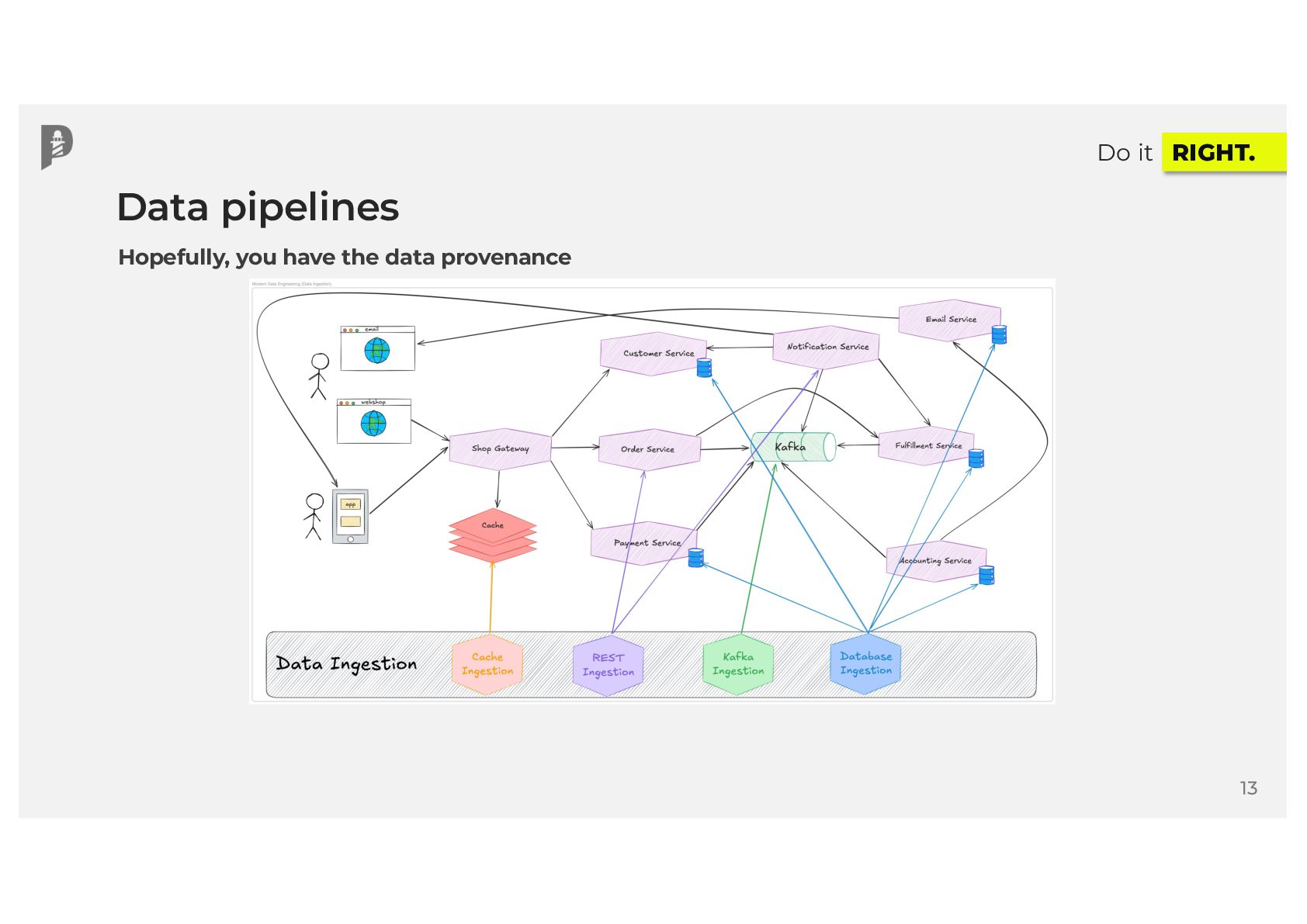
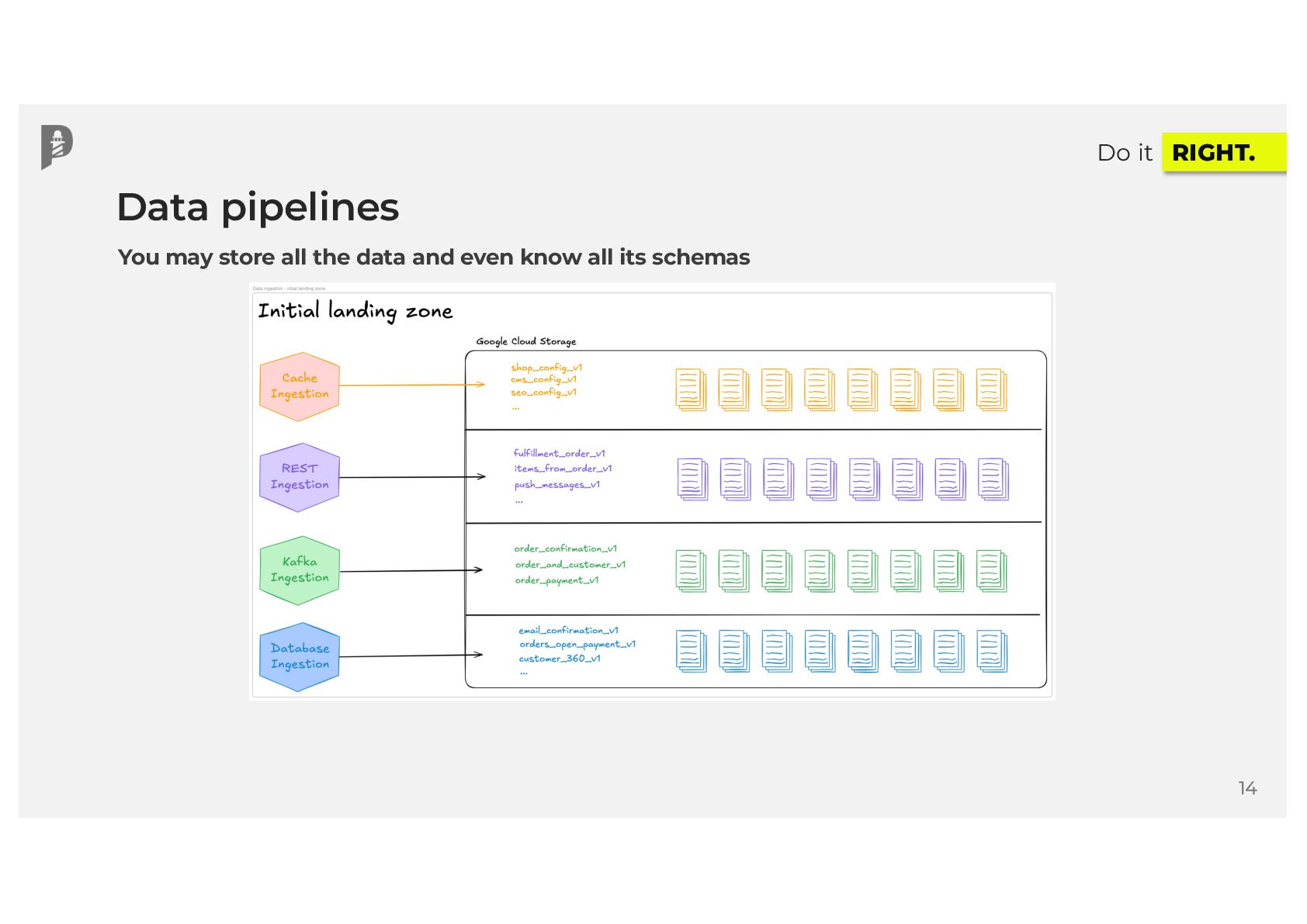
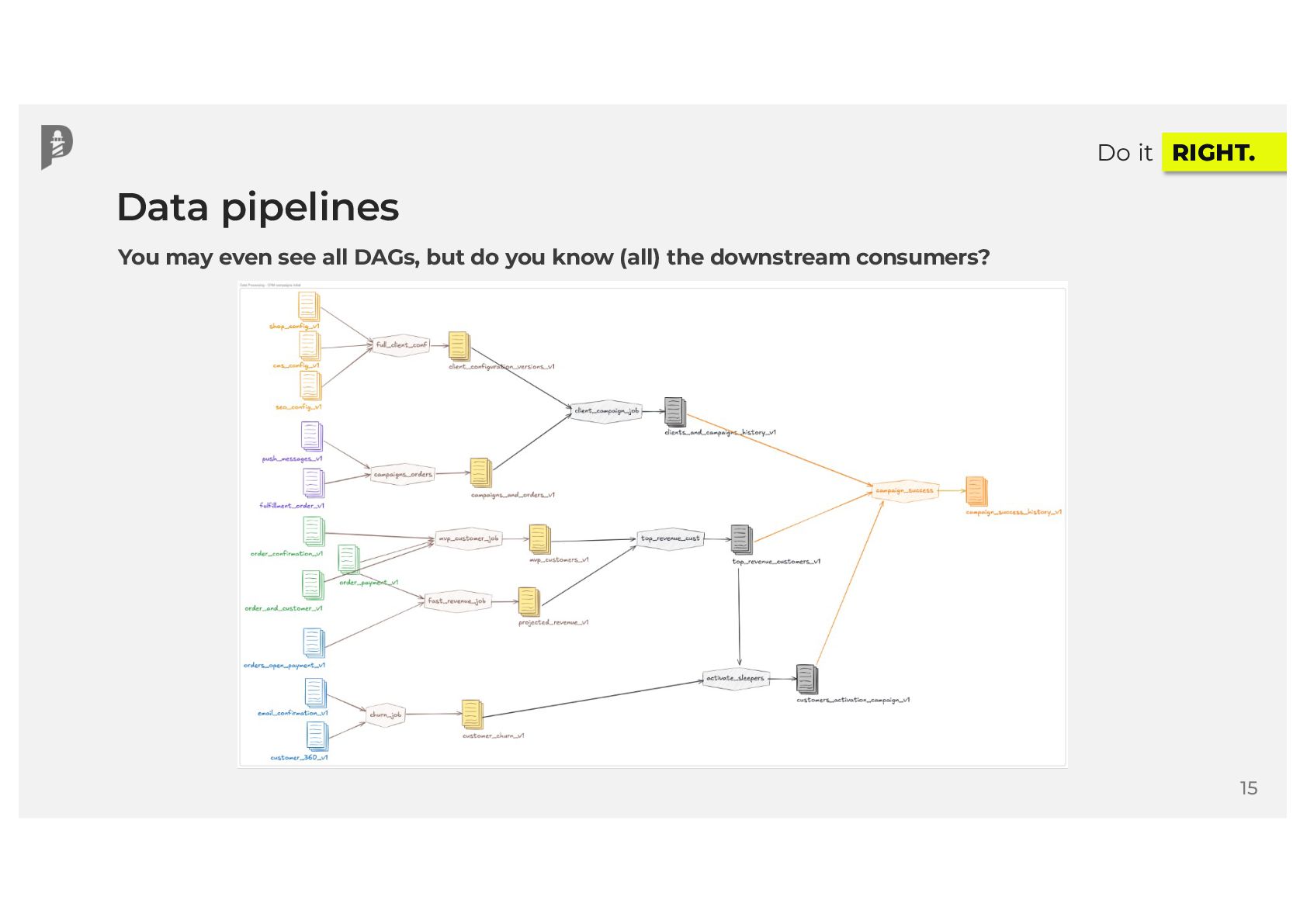
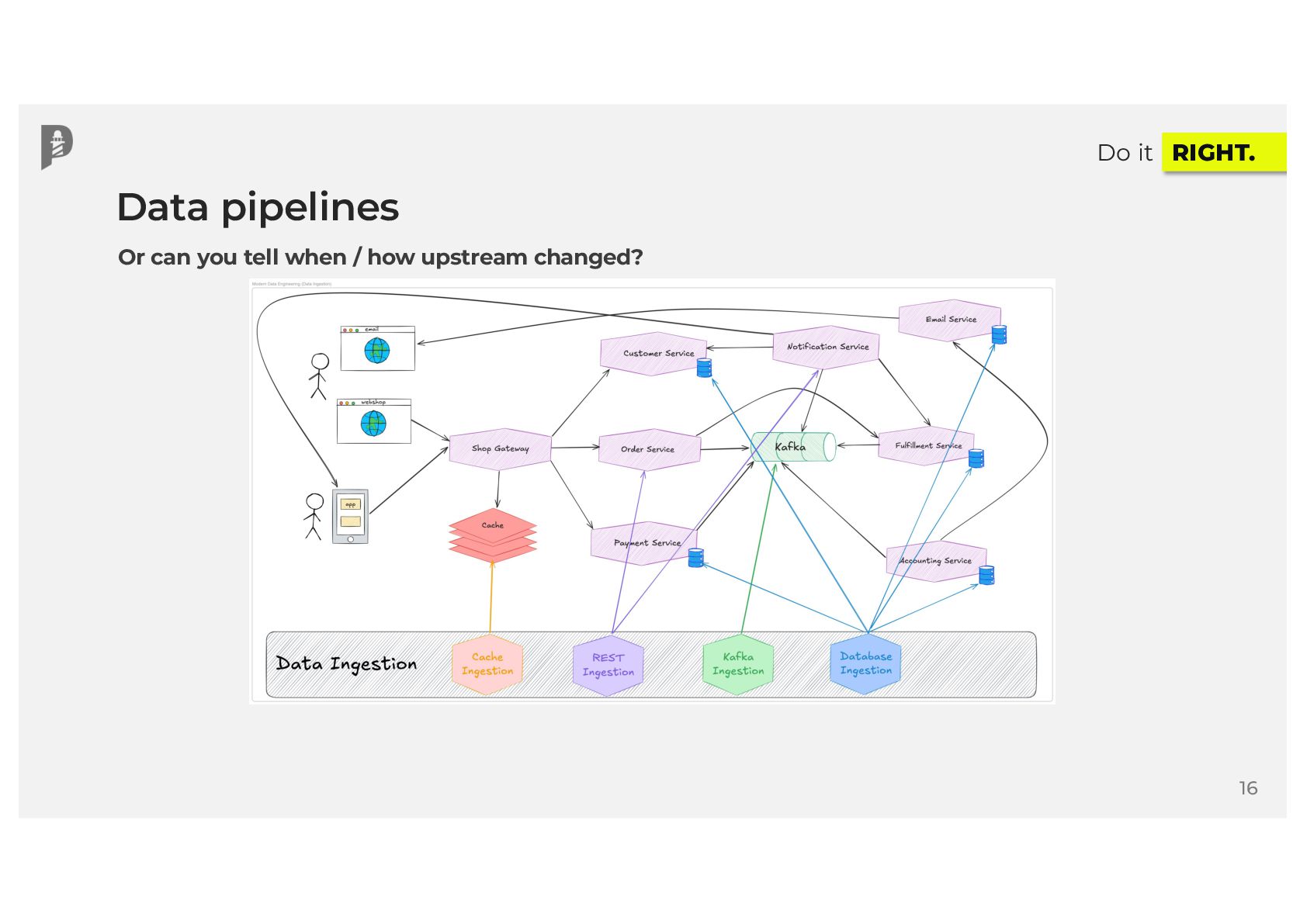
Your DAGs are running, data is flowing, and your data catalog is filling up with valuable metadata. That sounds great, right? Yet, in modern data ecosystems, many teams lack end-to-end visibility into how data moves across disparate systems. When issues surface at the end of the data pipeline, you often have no idea where data originated, how many data sources were involved, or who or what introduced the error. What if you could trace your jobs, runs, and final datasets by source to build better data products for your users?
The talk will be a deeper dive into examples and a comparison of the state of the art amongst the major providers of data engineering tools.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
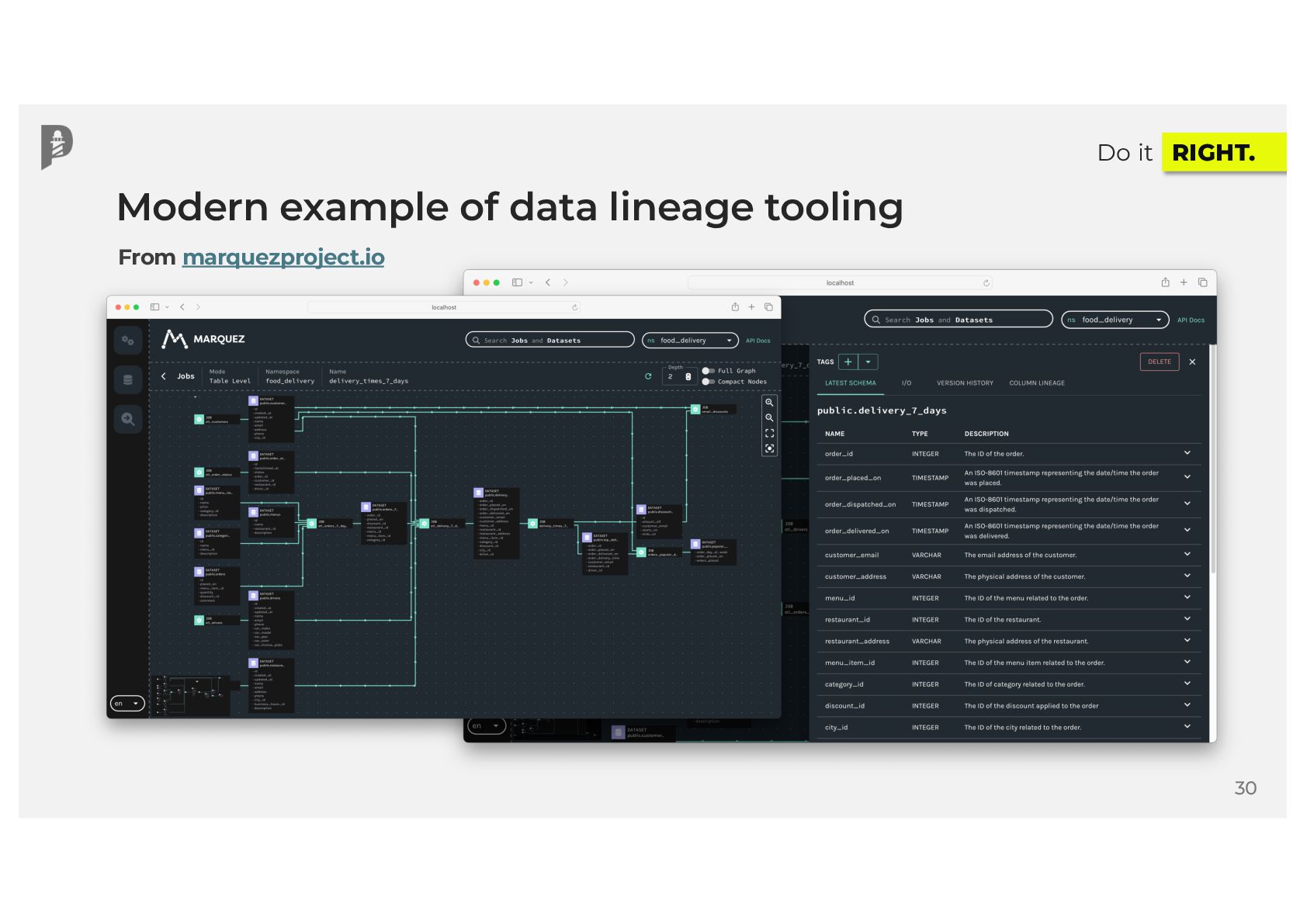{kind=link}
{kind=link}
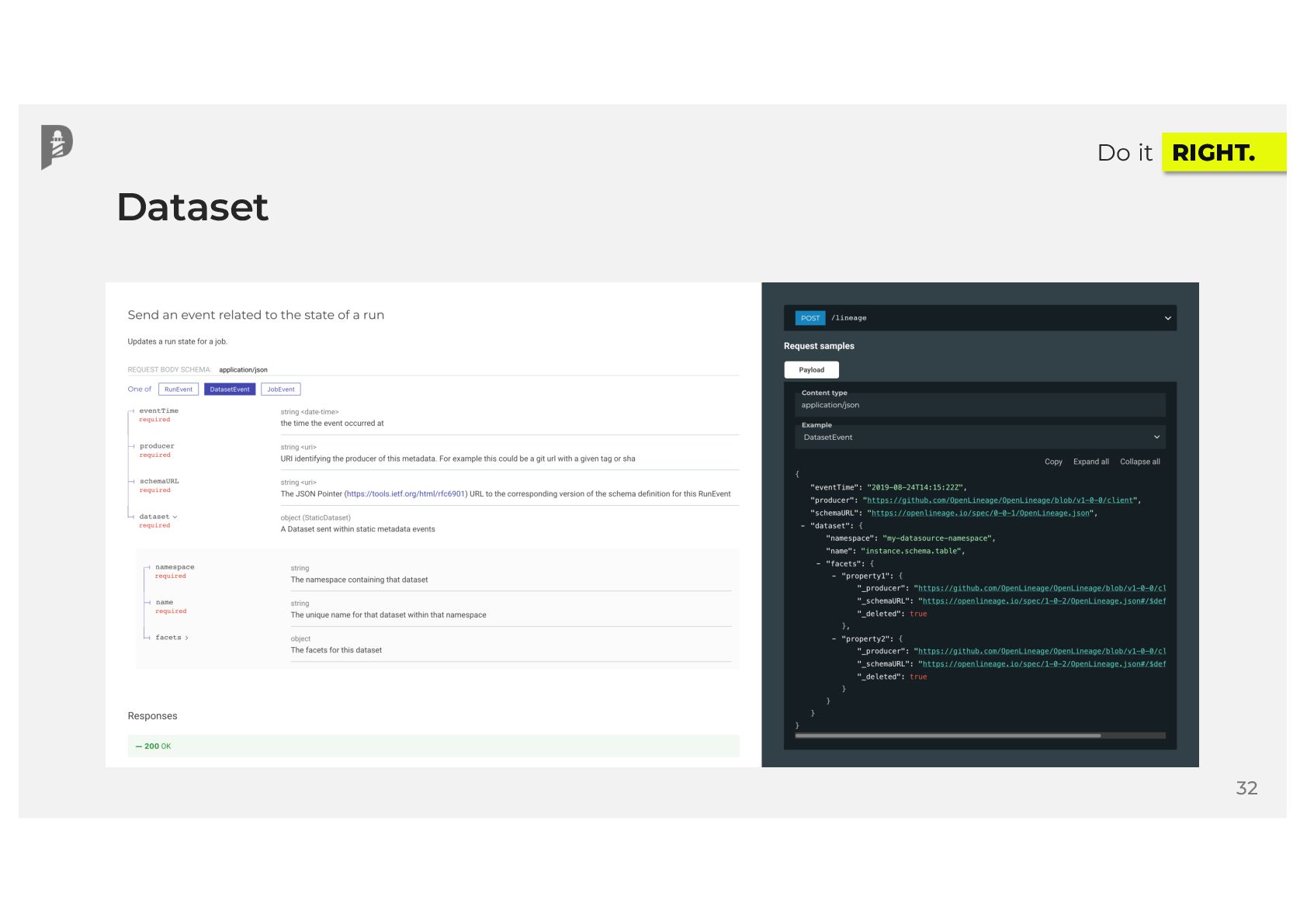{kind=link}
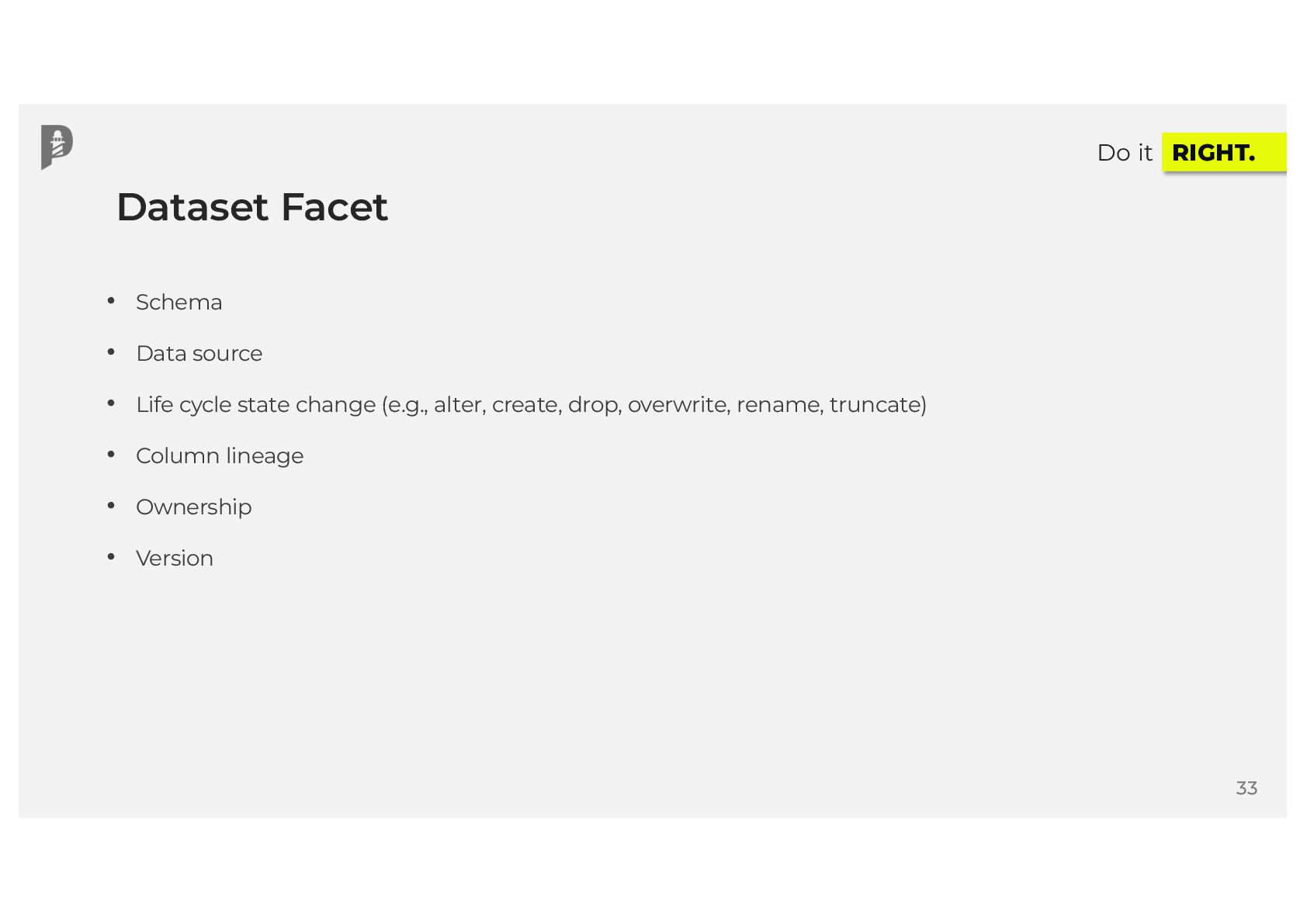{kind=link}
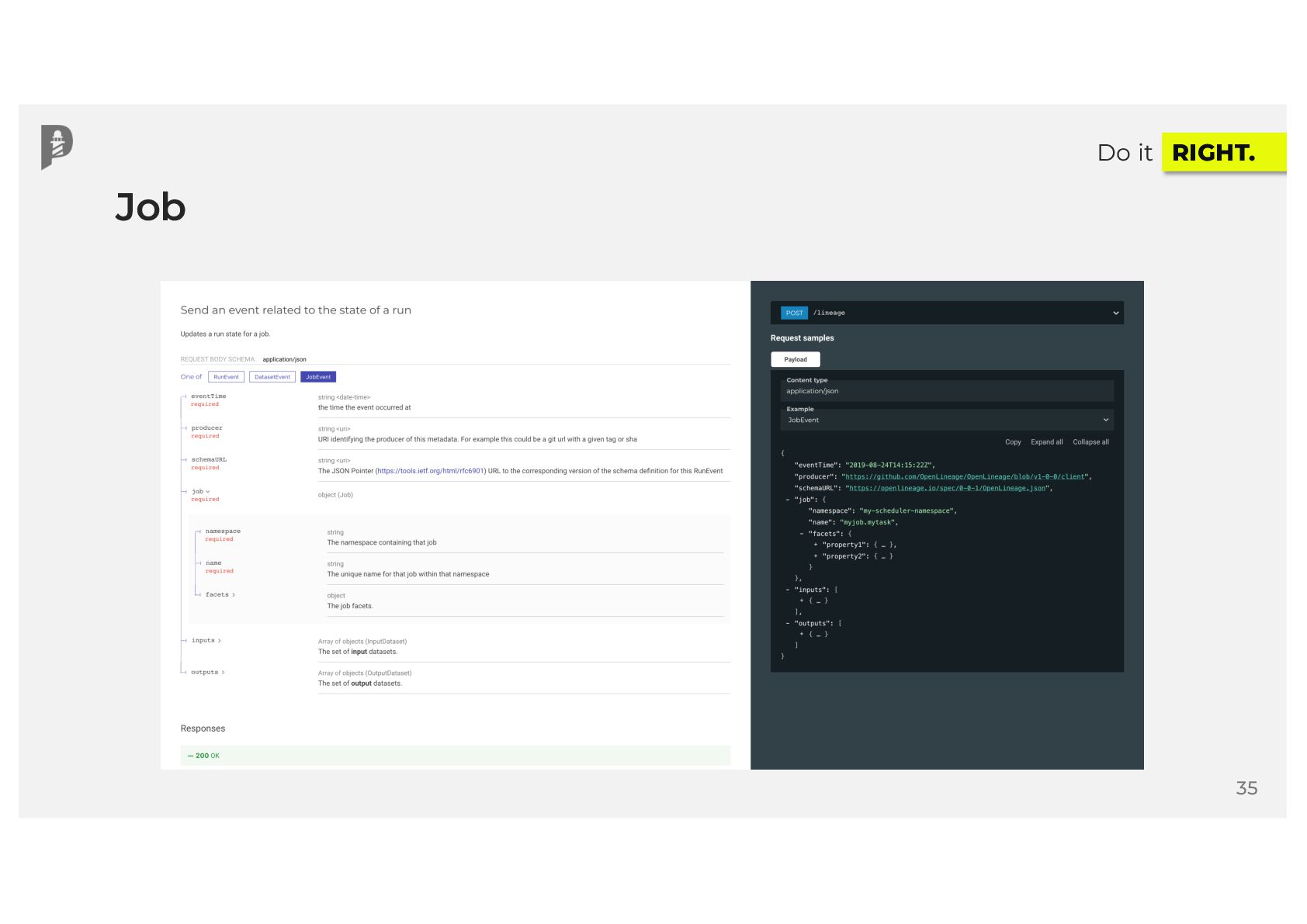{kind=link}
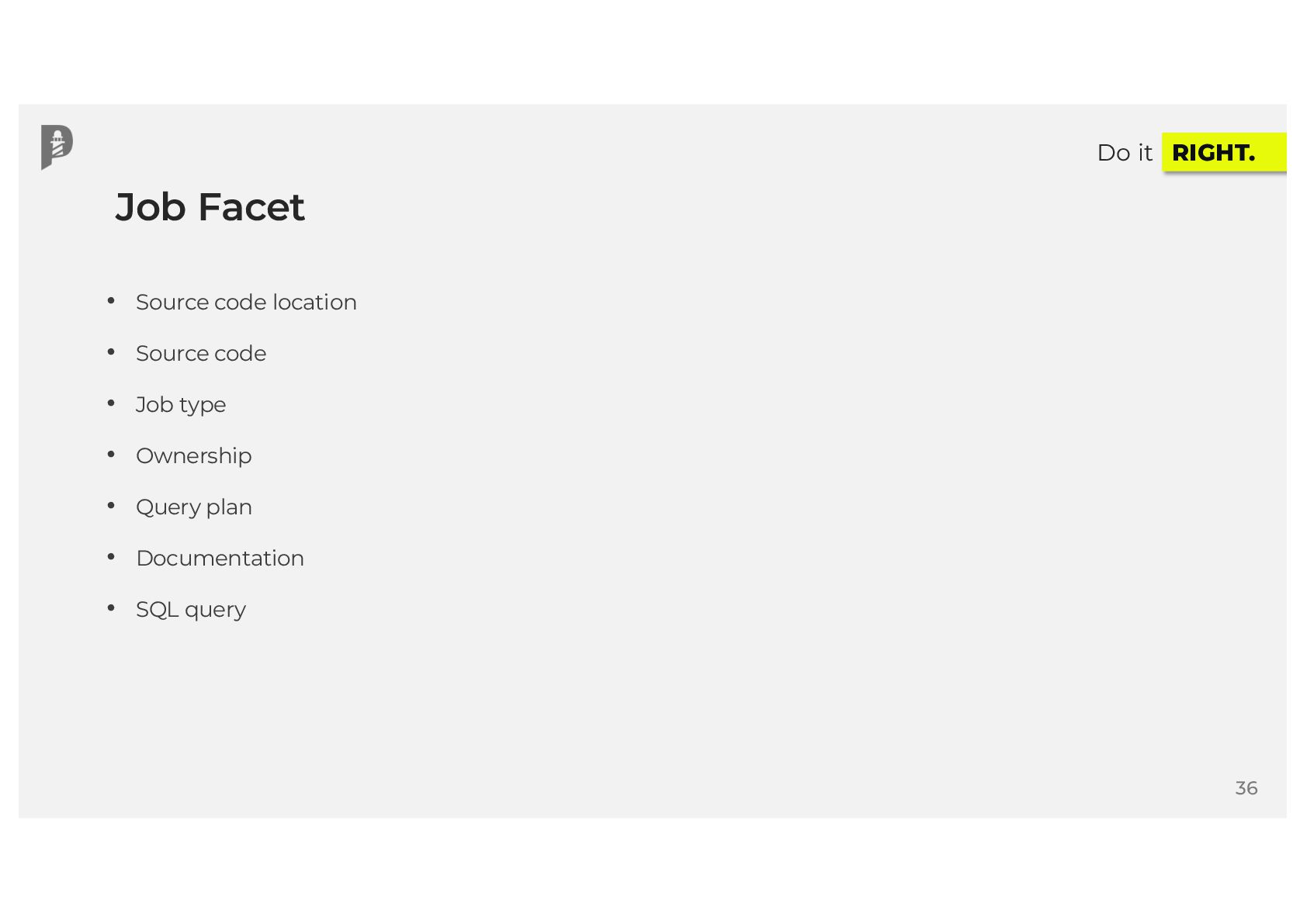{kind=link}
{kind=link}
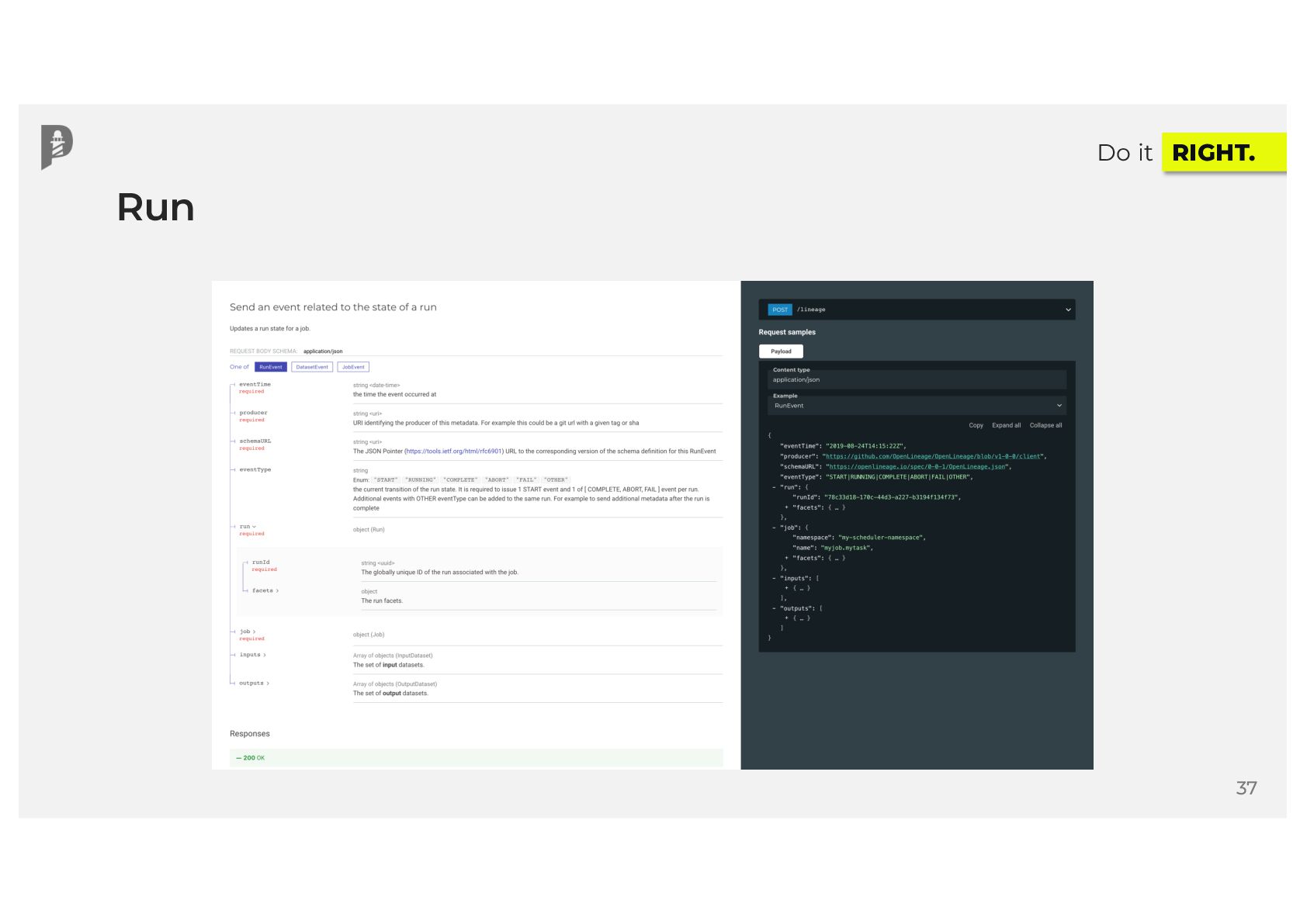
{kind=link}
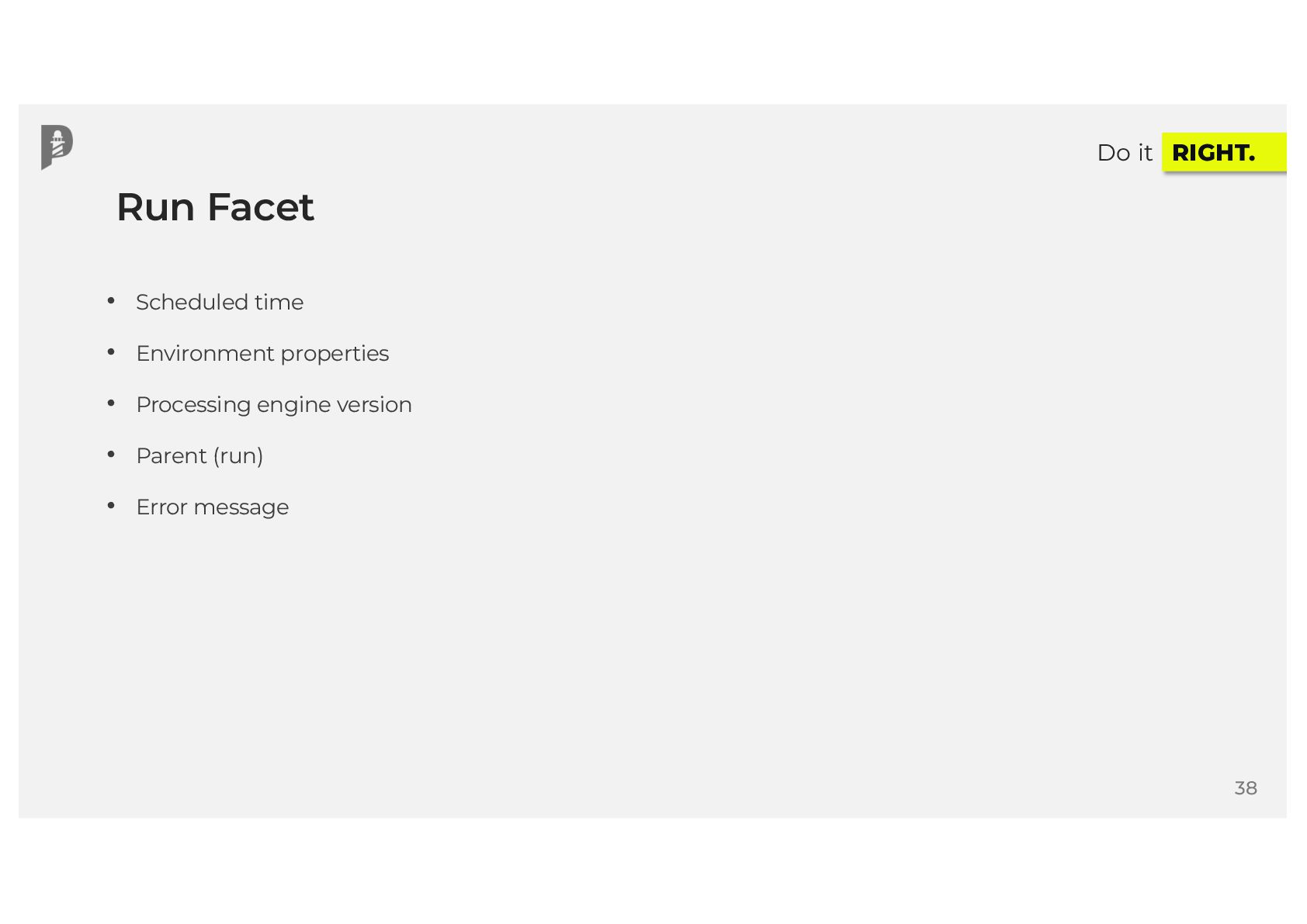
{kind=link}
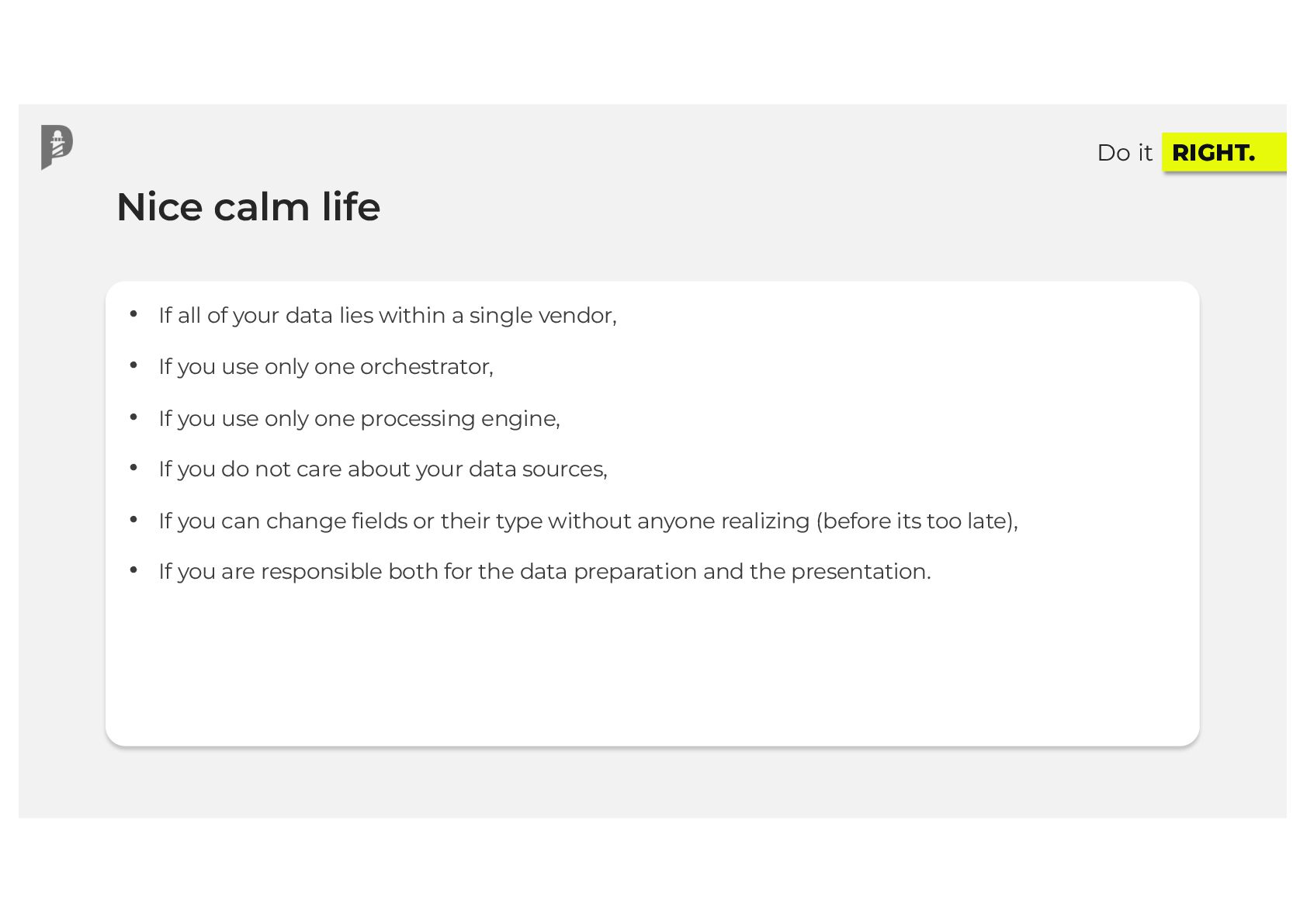{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
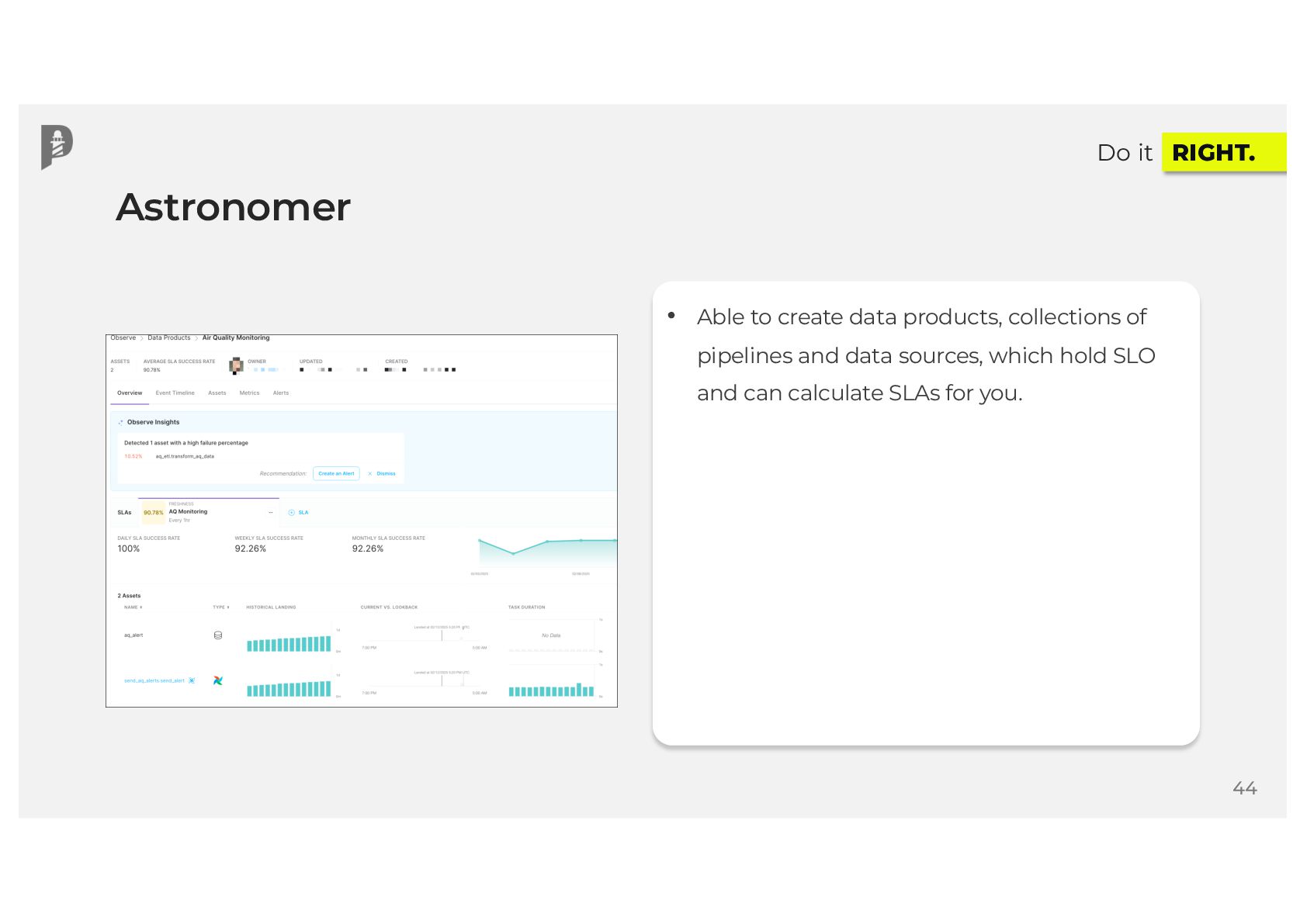
{kind=link}
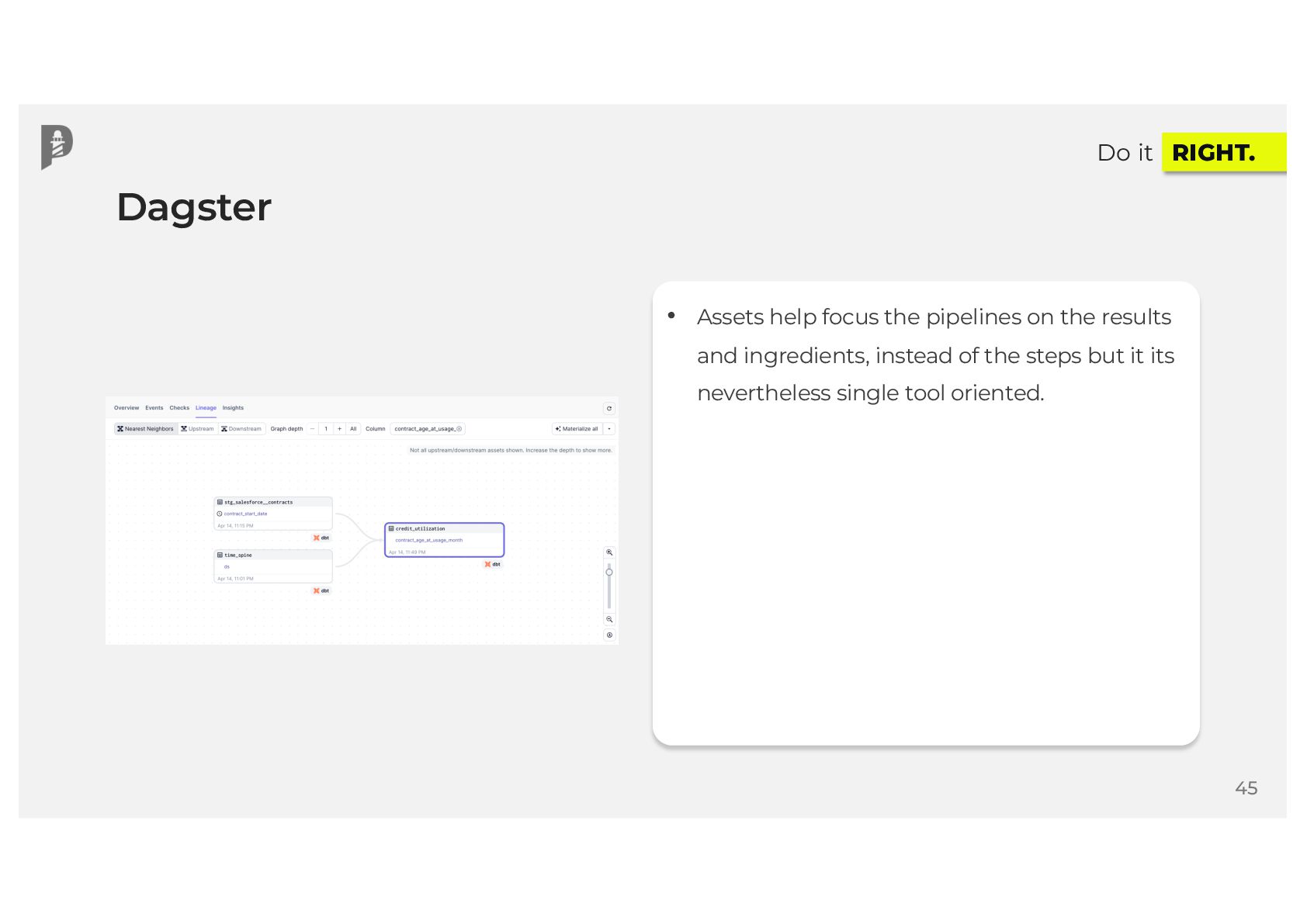
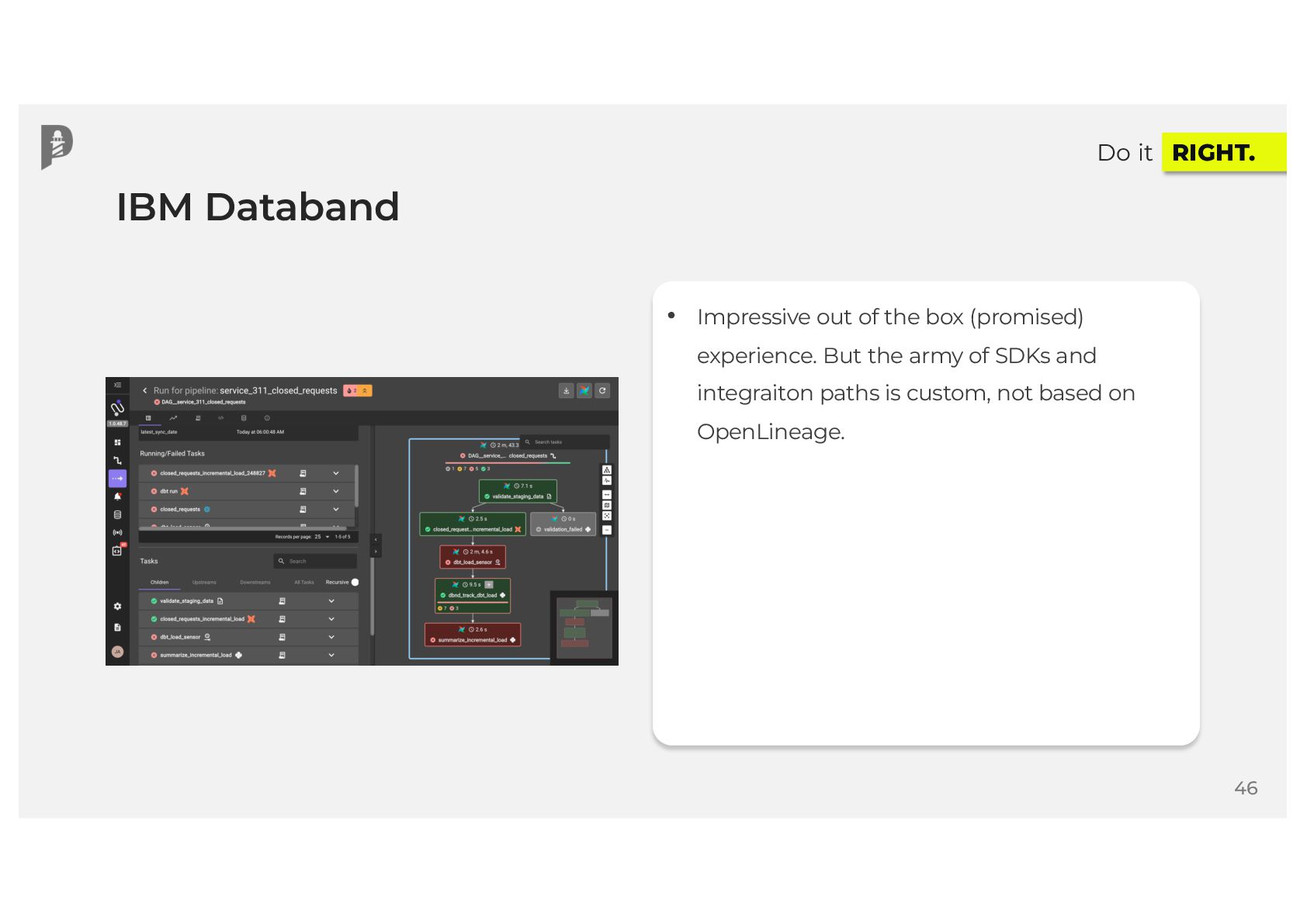{kind=link}
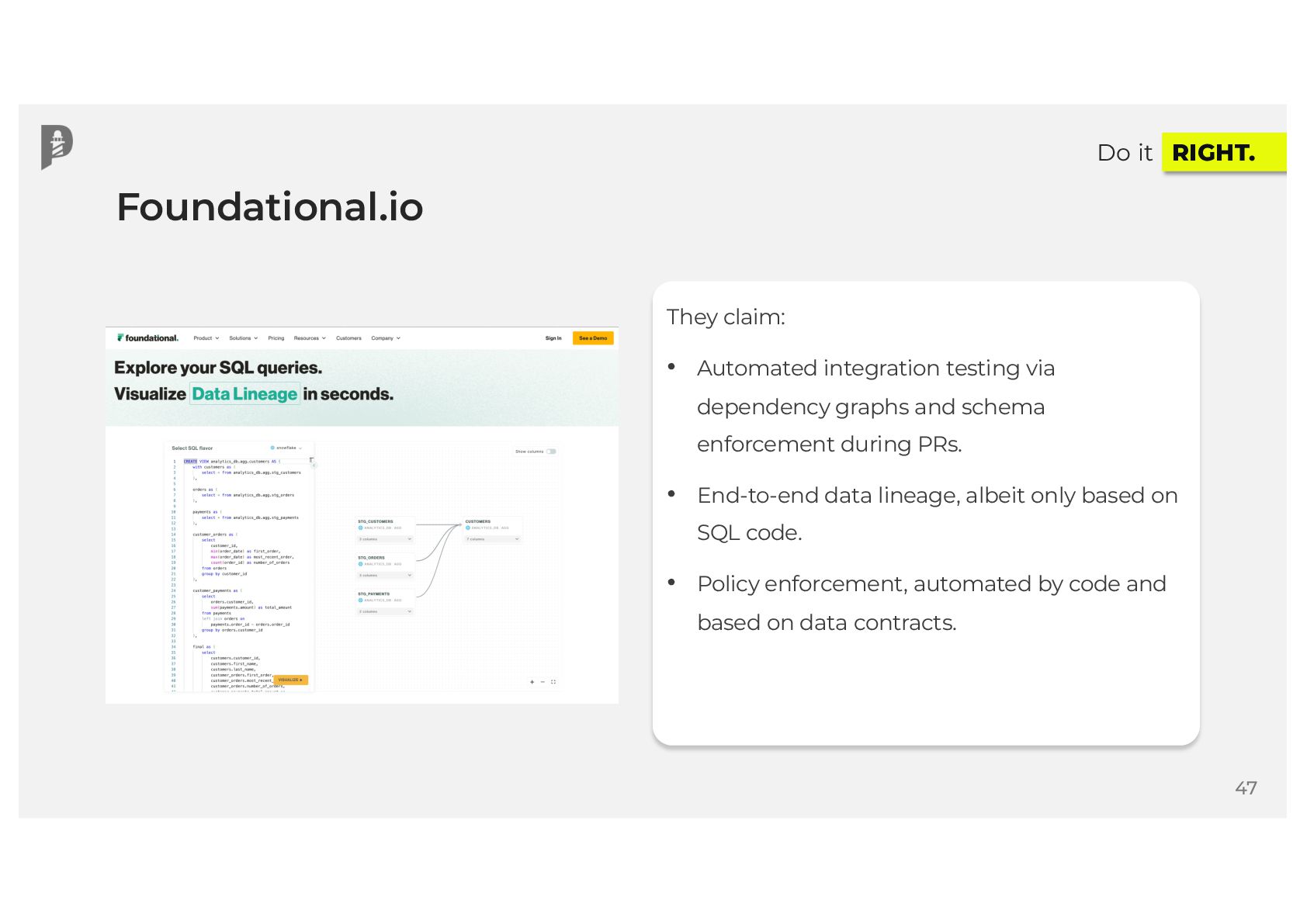{kind=link}
{kind=link}