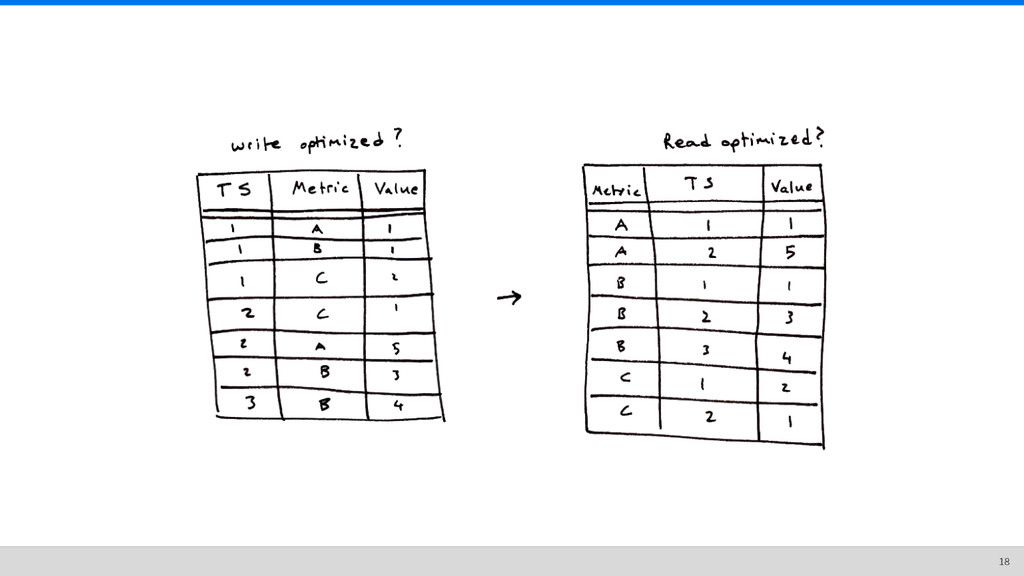
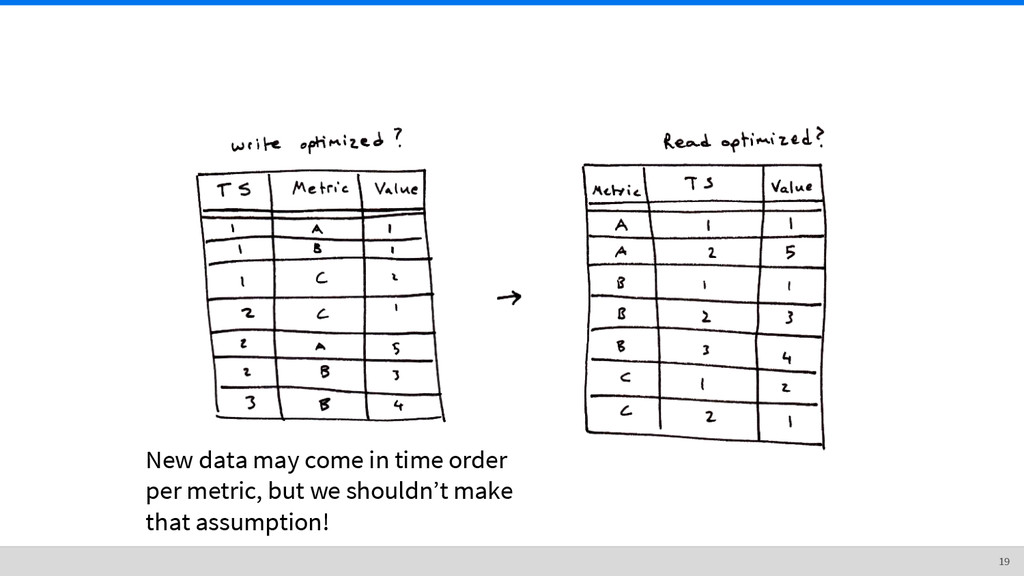
time order. • Writing to the end of a file is fast and efficient. • Data points do not change, so you only have to write once. • Reading data is fast because it’s already indexed. 6
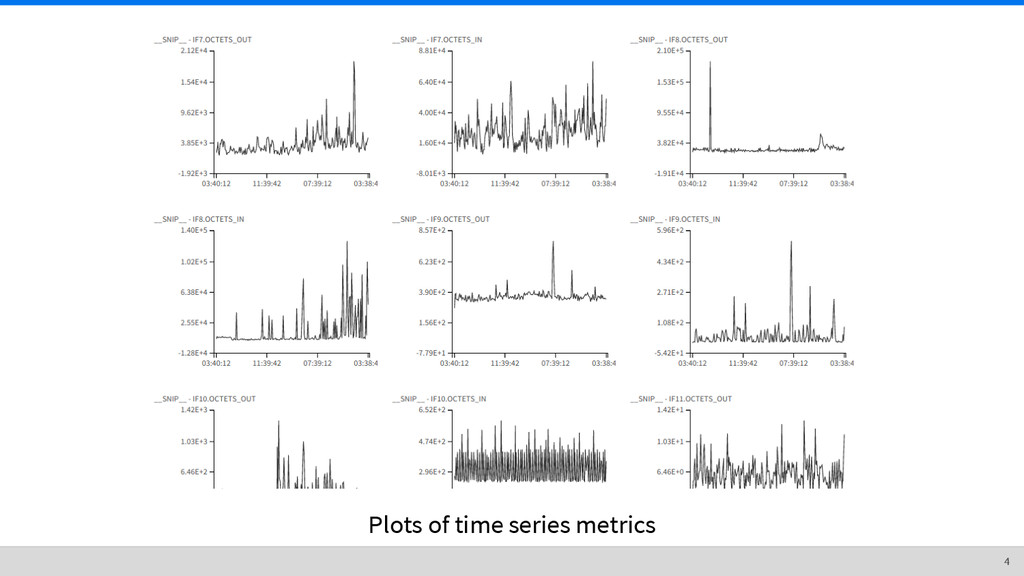
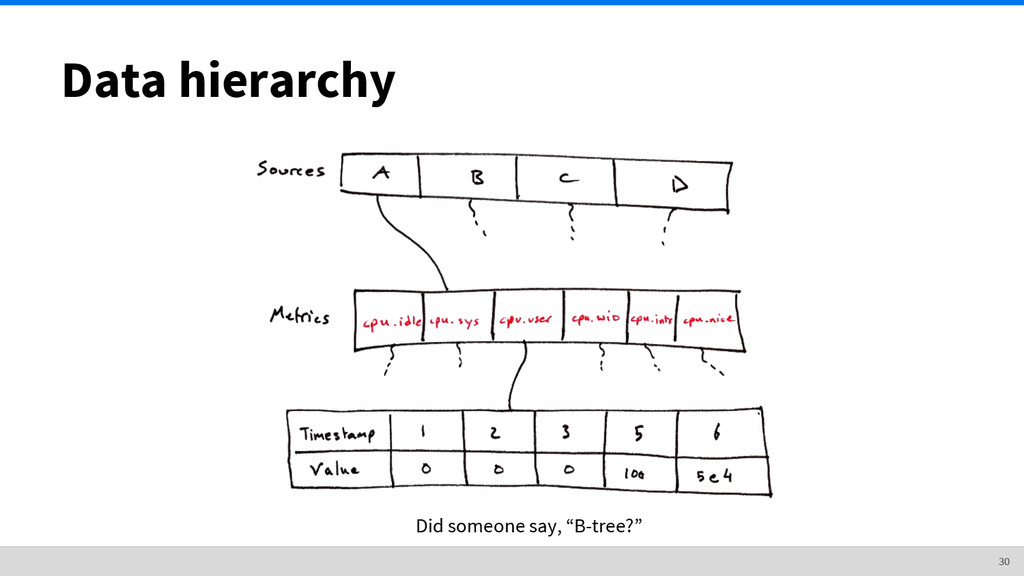
metrics These rule out solutions like RRDTool or Whisper (Graphite’s storage engine). A file per metric with 100k metrics is an operational nightmare. What else can we do? The nature of time series data 8
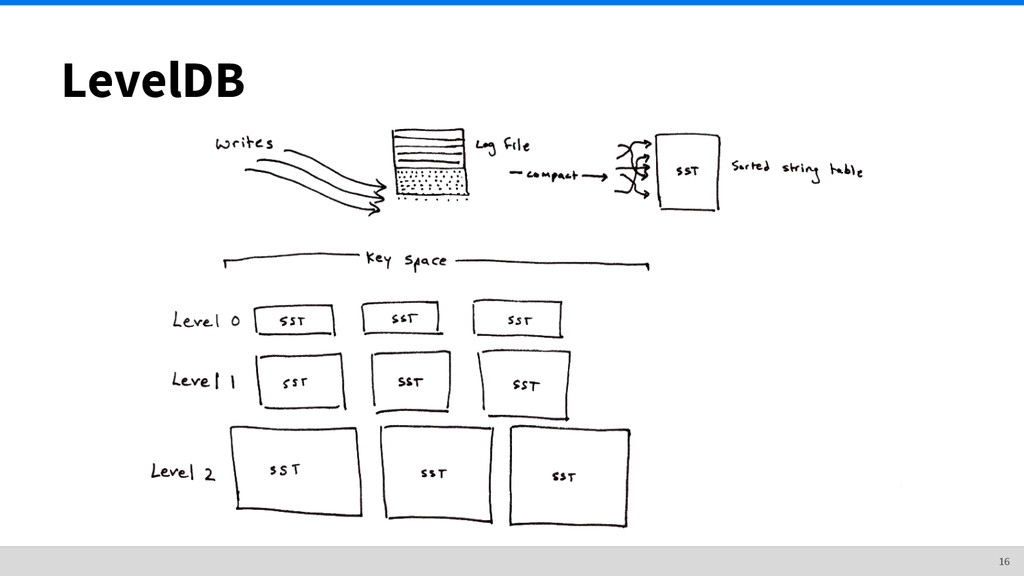
• ...Graphite? It’s made for time series! • ...{RDBMS}? They’re great for structured data! • ...Elastic(search)? Inverted indexes! • ...LevelDB? It’s fast! • ...B-trees? Everyone uses them! They don’t really fit this use case. I also don’t want external services to manage when I’m building a small utility. 11
◦ COW has great benefits • Cons: ◦ Generic, too many assumptions made ◦ Reads before writes ◦ Hard to control where data get placed ◦ Hard to implement compression on top ◦ Hard to support concurrent writers 15
• There are time series storage engines, but they’ re not good for this use case Can we design something that is both fast, and designed for time series? Of course. 25
fast, concurrent writes ◦ Sequential writes like LSM • Read optimized for indexed reads ◦ Uses something similar to a B-tree • Implemented in Go ◦ Still young. ~2 weeks of writing and coding 26
constant (4 bytes) ◦ Operation type (1 byte) ◦ Number of rows (4 bytes) ◦ Compressed buffer of rows. Each row: • Source and metric name lengths (4, 4 bytes) • Source and metric names (variable) • Timestamp and value (8 bytes, 8 bytes) 36
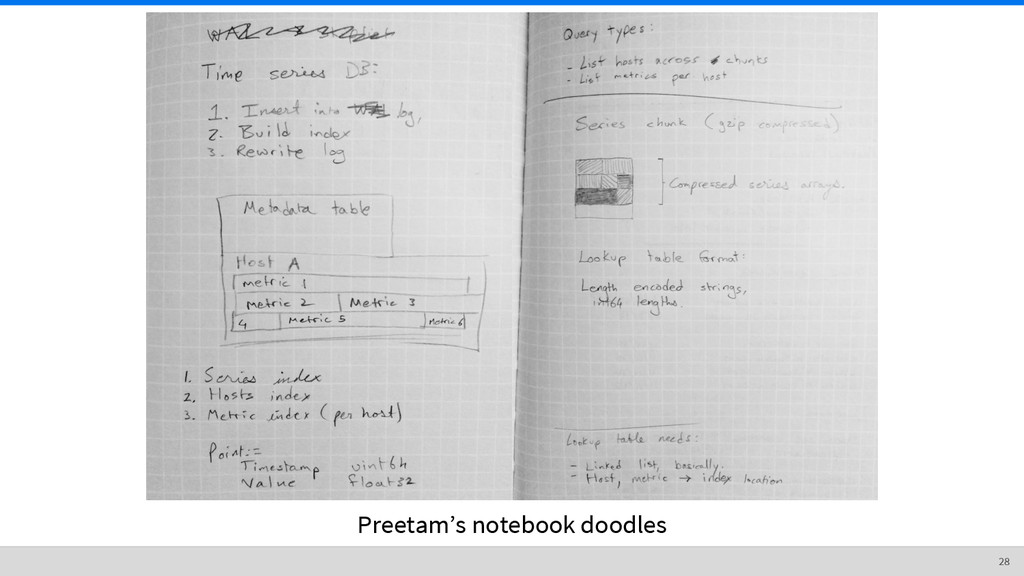
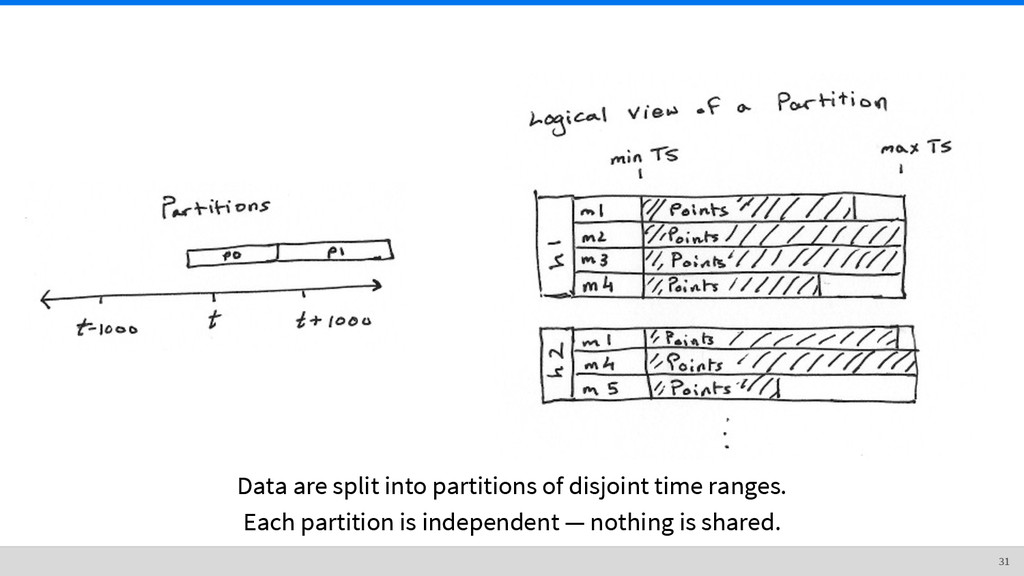
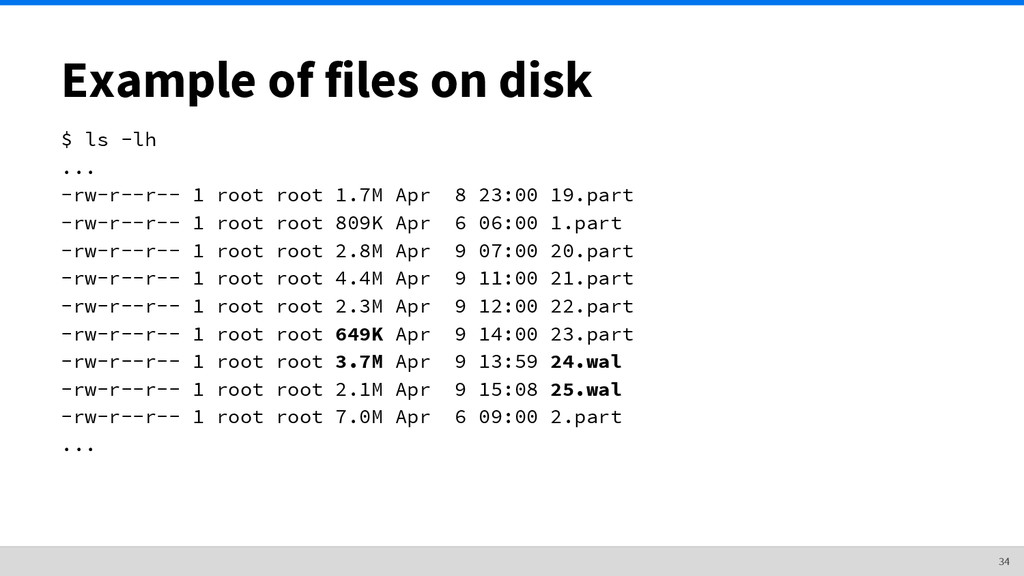
Iterate through sources ◦ Iterate through metrics • Split up points array into smaller extents • For each extent, remember its offset, compress extent, and write to file • Write metadata ◦ List of sources, metrics, extents, and offsets ◦ Also contains timestamps used for seeking, etc. 43
• Avoids overhead of locks min := atomic.LoadInt64(&db.minTimestamp) for ; min > minTimestampInRows; min = atomic.LoadInt64(&db.minTimestamp) { if atomic.CompareAndSwapInt64(&db.minTimestamp, min, minTimestampInRows) { break } } 47
• RWMutexes ◦ Multiple readers or a single writer ◦ Used for partitions: shared “holds” and exclusive “holds” ◦ Also used for maps in memory partitions to avoid readers blocking each other 48
laptop ◦ Single partition, 4 writers ◦ 10M rows total, 100K unique time series • 100 timestamps • 100 sources, 1000 metrics per source ◦ Writing in 1000-row batches with 1 timestamp, 1 source, 1000 metrics ◦ Also written to WAL (final size is ~26 MB) • Disk is not the bottleneck. Surprising? 51
[video] Building a Time Series Database on MySQL [video] Lock-Free Programming (or, Juggling Razor Blades) [video] LevelDB and Node: What is LevelDB Anyway? [article] 54
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Basic API db := catena.NewDB(...) db.InsertRows([...]) i := db.NewIterator(“source”, “metric”)](https://files.speakerdeck.com/presentations/e96cfbf391fa470cbc0d15066c7e626d/slide_26.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}