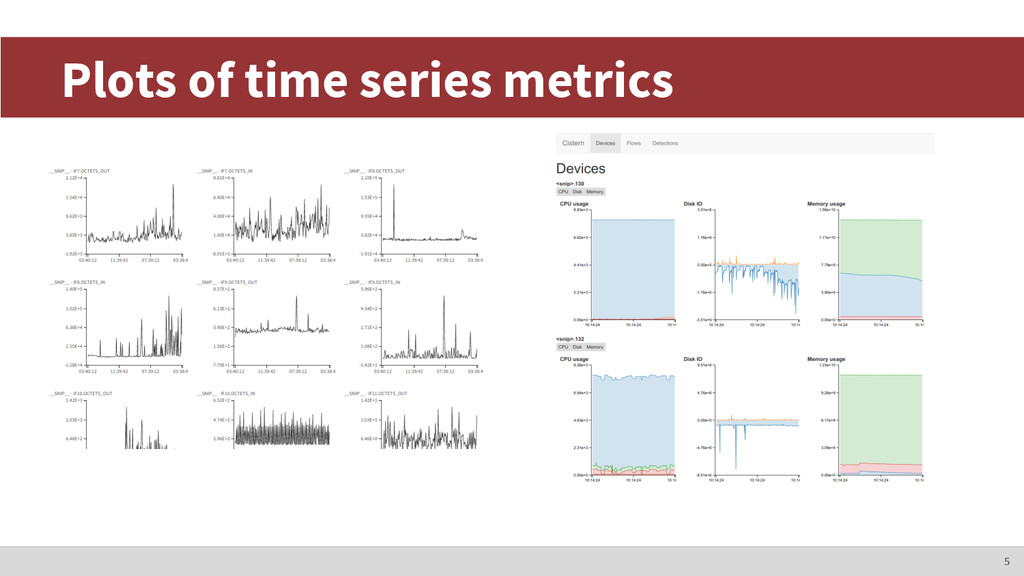
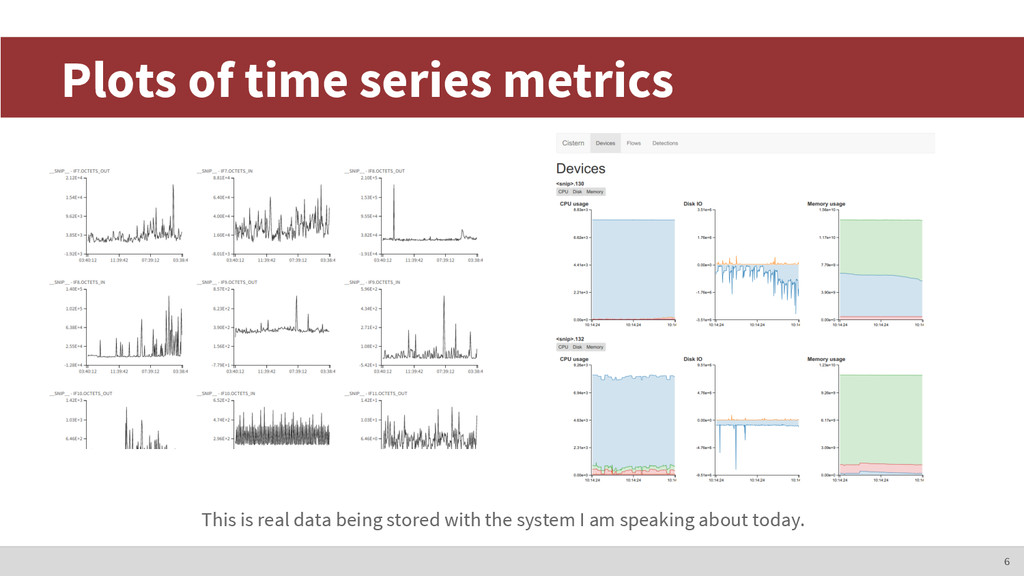
servers • Network Behavior Anomaly Detection ◦ DDoS attacks, SYN floods, MAC spoofing, etc. • Monitoring implies time series ◦ Lots of useful metrics. Data transfer rates, counters, system gauges, etc. 4 Personal project: Cistern
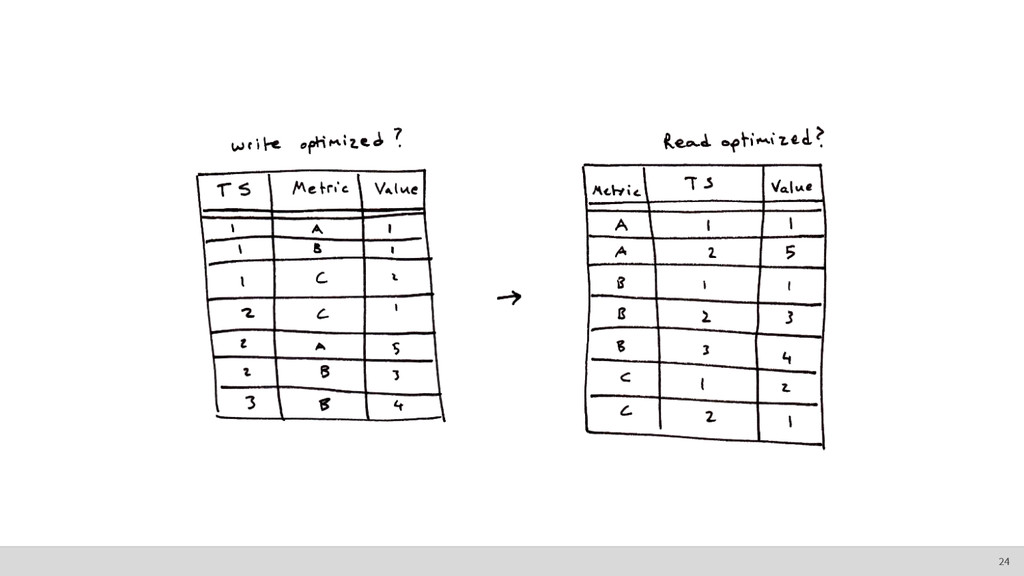
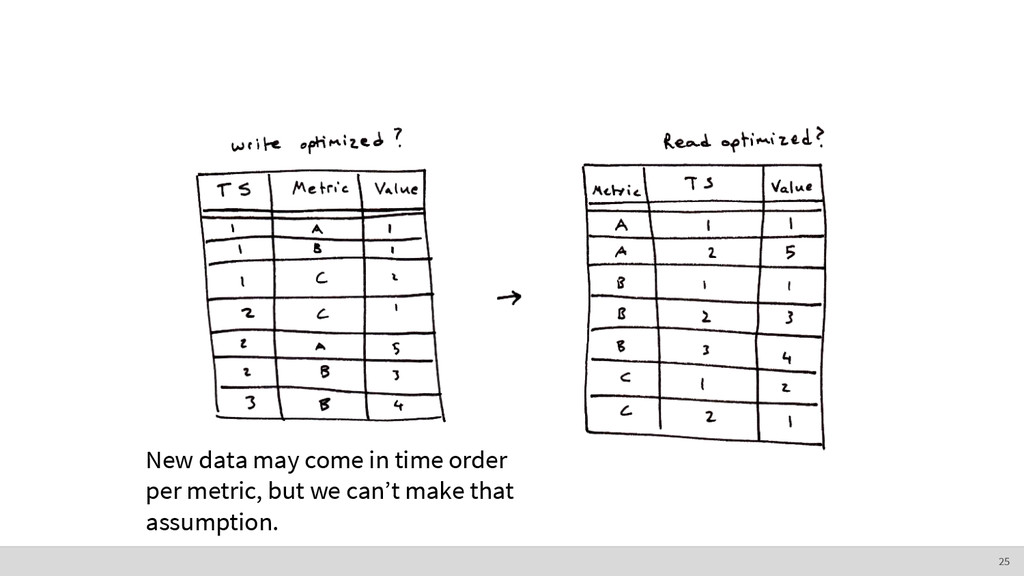
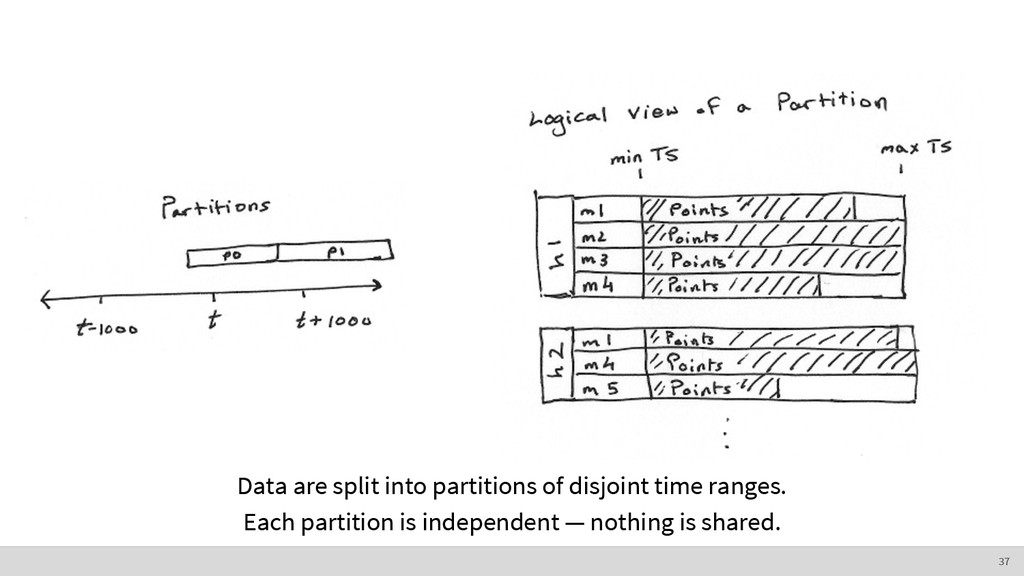
• It’s accessed in “bulk.” ◦ We generally want ranges of time series observations. • Deletions happen in “bulk.” ◦ We generally get rid of data older than a certain age. How do we store this? The nature of time series data 8
• Sequential reads and writes are fastest • Seeking (i.e. jumping around a file) is relatively slow • Writing to the end of a file is optimal Remember, writing to the beginning of a file and maintaining order means you have to rewrite the entire file. You have to shift everything over. 9
order • Make searching faster • Usually require fancy data structures (e.g. B- trees) ◦ Trade-off: faster reads can mean slower writes • We’re going to talk about indexing time series. 10
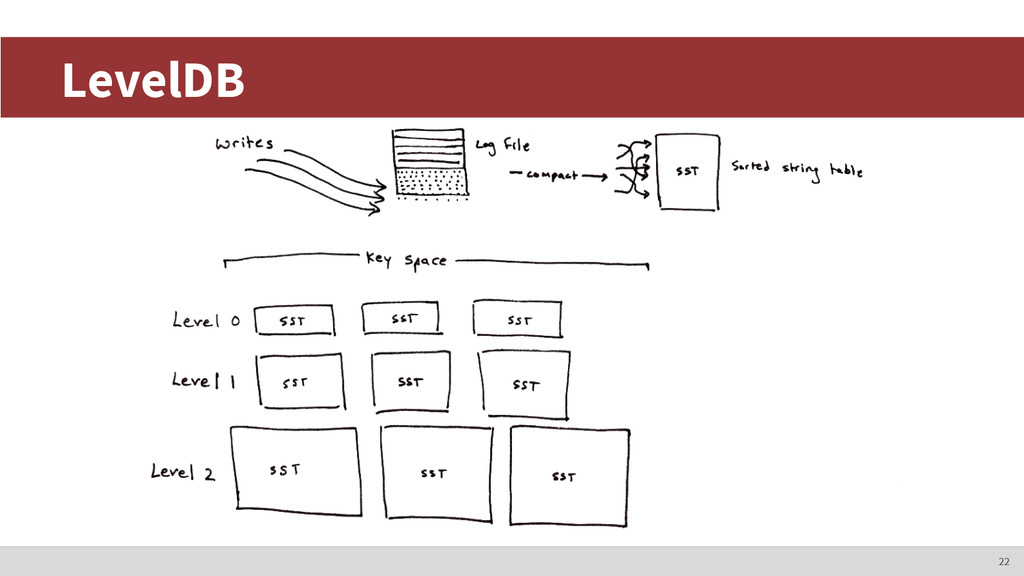
already indexed in time order. • Just use a file per metric! • Writing to the end of a file is fast and efficient. • Data points do not change, so you only have to write once. • Reading data is fast because it’s already indexed. 11
generate >250 metrics just for the interface counters. A data center might have thousands of switches. Hundreds of thousands of unique metrics, and we’re only talking about the Ethernet counters. There are still... IP addresses, TCP flags, UDP flags, VLAN data, etc. 12
can’t have a file per metric. Operational nightmare. • Potentially sparse ◦ You can’t preallocate space. These rule out solutions like RRDTool or Whisper (Graphite’s storage engine). What else can we do? The nature of time series data 13
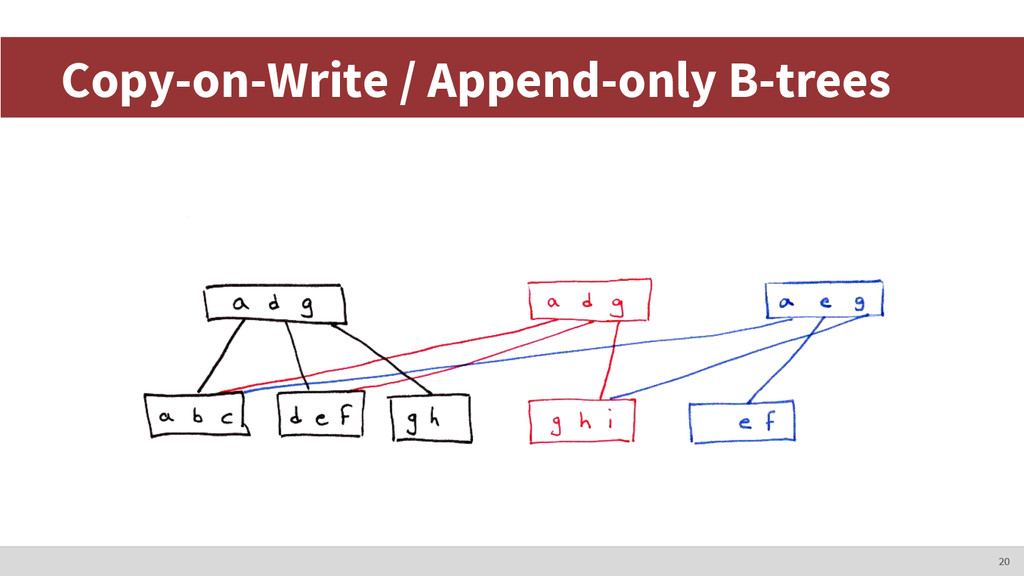
choices, etc. • We’ll stick with copy-on-write B+trees ◦ LMDB is based on this ◦ Simple, reliable, efficient ◦ Copy-on-write has interesting advantages 19
◦ COW has great benefits • Cons: ◦ Generic, offers more than what we need ◦ Reads before writes (more of an issue on HDD) ◦ Hard to control where data get placed (page allocation) ◦ Hard to implement compression on top ◦ Hard to support concurrent writers (only one root) 21
sequentially. It’s better to write without reading (blind writes). We want to avoid rewriting data that do not change. Write amplification is bad for SSDs. They wear out quicker. But doing more work in general is not preferred. 27
• There are time series storage engines, but they’ re not good for this use case Can we design something that is both fast, and designed for time series? Of course. 31
fast, concurrent writes ◦ Sequential writes like LSM • Read optimized for indexed reads ◦ Uses something similar to a B-tree with extents • Implemented in Go ◦ Still young. ~2 weeks of writing and coding 32
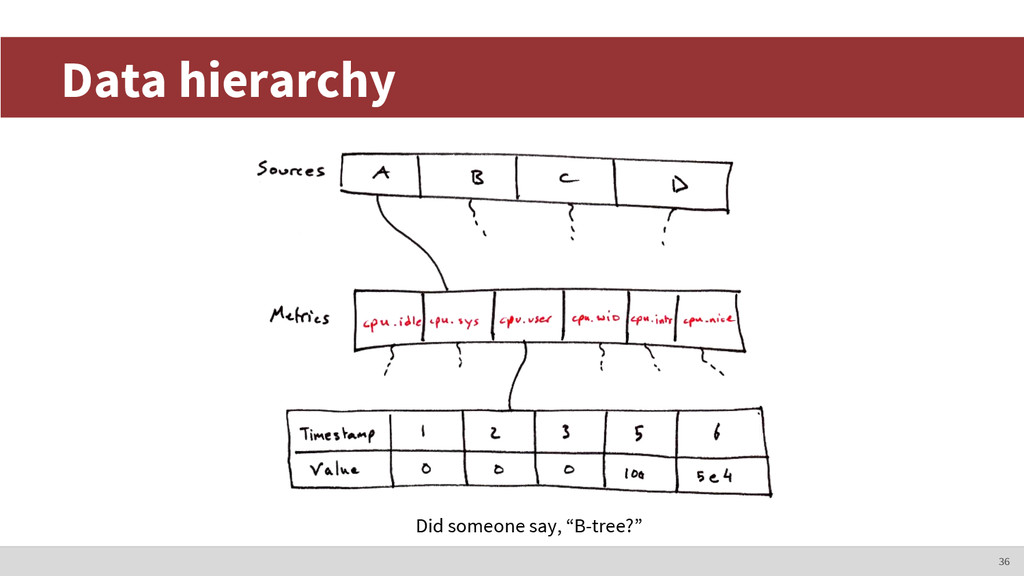
constant (4 bytes) ◦ Operation type (1 byte) ◦ Number of rows (4 bytes) ◦ Compressed buffer of rows. Each row: • Source and metric name lengths (4, 4 bytes) • Source and metric names (variable) • Timestamp and value (8 bytes, 8 bytes) 42
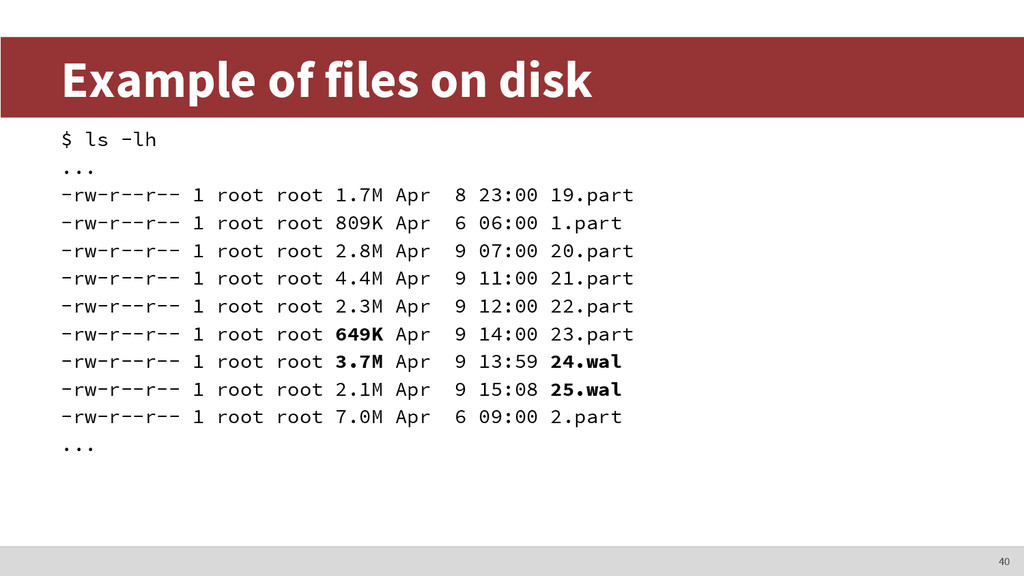
Iterate through sources ◦ Iterate through metrics • Split up points array into smaller extents • For each extent, remember its offset, compress extent, and write to file • Write metadata ◦ List of sources, metrics, extents, and offsets ◦ Also contains timestamps used for seeking, etc. 49
• Avoids overhead of locks min := atomic.LoadInt64(&db.minTimestamp) for ; min > minTimestampInRows; min = atomic.LoadInt64(&db.minTimestamp) { if atomic.CompareAndSwapInt64(&db.minTimestamp, min, minTimestampInRows) { break } } 53
• RWMutexes ◦ Multiple readers or a single writer ◦ Used for partitions: shared “holds” and exclusive “holds” ◦ Also used for maps in memory partitions to avoid readers blocking each other 54
laptop ◦ Single partition, 4 writers ◦ 10M rows total, 100K unique time series • 100 timestamps • 100 sources, 1000 metrics per source ◦ Writing in 1000-row batches with 1 timestamp, 1 source, 1000 metrics ◦ Also written to WAL (final size is ~26 MB) • Disk is not the bottleneck. Surprising? 57
[video] Building a Time Series Database on MySQL [video] Lock-Free Programming (or, Juggling Razor Blades) [video] LevelDB and Node: What is LevelDB Anyway? [article] 60
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Basic API db := catena.NewDB(...) db.InsertRows([...]) i := db.NewIterator(“source”, “metric”)](https://files.speakerdeck.com/presentations/e6b62d9cfe54446ea0b66348007579ae/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}